初赛之特征构造
- 写在前面
- 一、安装paddleOCR
- 二、代码部分
- 三、模型优缺点
- 四、写在最后
写在前面
通过前面两篇文章的介绍,我们可以大致的知道模型用到的特征分为四块:qCap,qImg,captions,imgs。根据这些特征,我们得到的模型效果在0.7左右。是否能加入更多的特征,进一步提升模型的效果呢?
通过数据分析,我们发现了部分图片中存在文字且具有判断文本类别的作用。所以,本文采用paddleocr模型来提取图像中的文字特征。
一、安装paddleOCR
在安装paddleOCR前,需要安装依赖组件Shapely
pip install Shapely
接下来,就可以安装paddleOCR了,也是一行代码就完成安装
pip install --user paddleocr -i https://mirror.baidu.com/pypi/simple
接下来我们就可以进行测试了
from paddleocr import PaddleOCR
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
captions_list = []
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
caption = []
img_path = '0.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
print(res)
for line in res:
if line[1][1]>0.9: # line[1][1]是提取文本的置信度
print(line[1][0]) # line[1][0]是提取文本
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
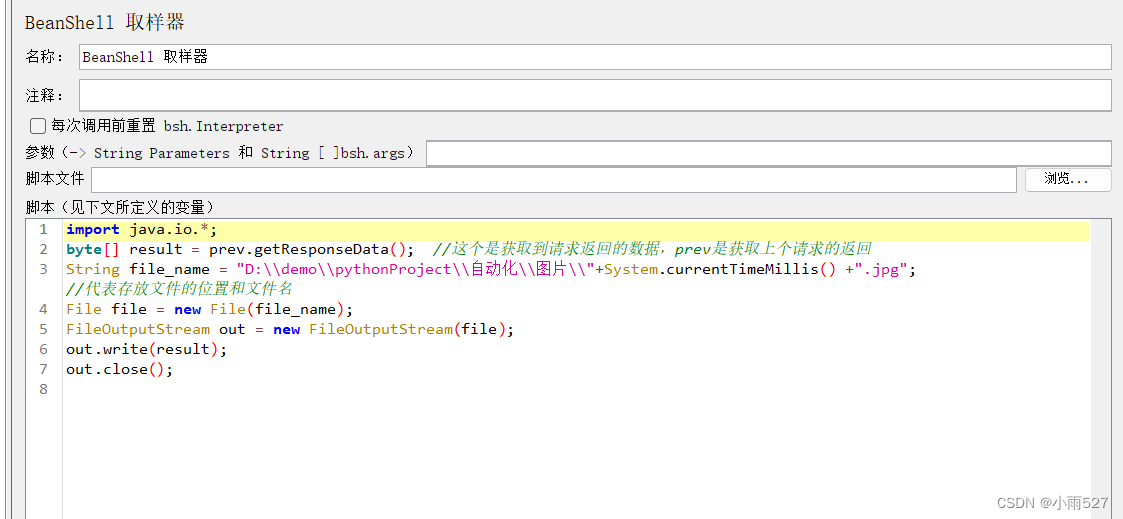
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
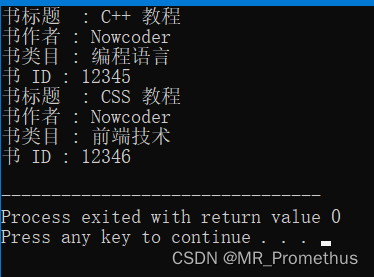
测试结果如下

可以发现,识别效果还是不错的。
paddleOCR以ppocr轻量级模型作为默认模型,如果你想尝试更多,可以参考以下链接的第3节自定义模型进行自定义更换。
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/whl.md
二、代码部分
运行该部分代码,可以得到train、test、val各个img文件夹中图片中的文字,一行文字代表一张图片。
#读取数据
import json
from paddleocr import PaddleOCR
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
data_items_train = json.load(open("queries_dataset_merge/dataset_items_train.json",'r',encoding='UTF8'))
data_items_val = json.load(open("queries_dataset_merge/dataset_items_val.json",'r',encoding='UTF8'))
data_items_test = json.load(open("queries_dataset_merge/dataset_items_test.json",'r',encoding='UTF8'))
# 写入txt文件
def load_ocr_captions(context_data_items_dict,queries_root_dir,split):
if split == 'train':
fname = 'ocr/ocr_qimg_train.txt'
if split == 'val':
fname = 'ocr/ocr_qimg_val.txt'
if split == 'test':
fname = 'ocr/ocr_qimg_test.txt'
# image_path = os.path.join(queries_root_dir,fname)
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
with open(fname, 'w', encoding="UTF8") as f:
for key in range(len(context_data_items_dict)):
print(key)
captions_list = []
image_path = os.path.join(queries_root_dir, context_data_items_dict[str(key)]['image_path'])
ocr = PaddleOCR(use_angle_cls=True, lang="ch",show_log=False) # need to run only once to download and load model into memory
result = ocr.ocr(image_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
if line[1][1] >= 0.8: # 置信度
captions_list.append(line[1][0])
captions = ",".join(captions_list)
f.write(captions+'\n')
#### load Datasets ####
train_dump_ocr_captions= load_ocr_captions(data_items_train, 'queries_dataset_merge','train')
val_dump_ocr_captions = load_ocr_captions(data_items_val,'queries_dataset_merge','val')
test_dump_ocr_captions = load_ocr_captions(data_items_test,'queries_dataset_merge','test')
三、模型优缺点
优点是模型识别的准确率较高,缺点是模型不能多线程跑,读完整个数据集耗时1day。建议在入模前就通过ocr采集存储每个图片的文字,后续调用,直接通过图片id匹配即可。
四、写在最后
文本主要展现用什么方法来做数据特征加工,对baseline改动的代码就不贴了,想要的uu们可以私信我。
本次记录主要还是以学习为主,抽了工作之余来进行OCR特征加工。探索了一个带大家最快上手的路径,降低大家的入门难度。
看完觉得有用的话,记得点个赞,不做白嫖党~