目录
一、官网地址
二、安装
三、 快速使用
一、官网地址
GitHub - pudo/dataset: Easy-to-use data handling for SQL data stores with support for implicit table creation, bulk loading, and transactions.
二、安装
pip install dataset
如果是mysql,则多安装一个依赖:pip install mysqlclient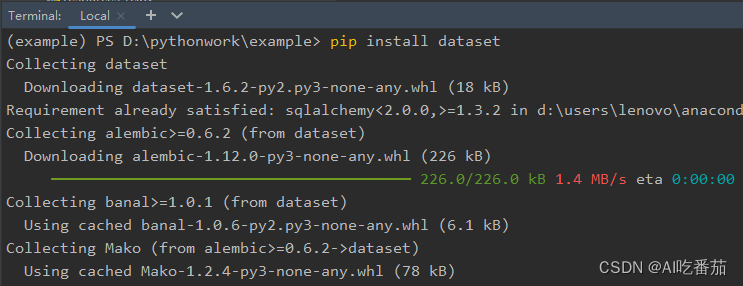
三、 快速使用
import dataset
if __name__ == '__main__':
"""
先天支持sqlite
如果是mysql,则多安装一个依赖:pip install mysqlclient
"""
db = dataset.connect('sqlite:///mydatabase.db')
# 建表,如果表,则dataset会自动创建。
table = db['user']
# 新增
table.insert(dict(name="张三丰", age=18, country='China'))
# 新增
table.insert(dict(name='Jane Doe', age=37, country='France', gender='female'))
# 修改数据
table.update(dict(name='张三丰', age=34), ['name']) # 根据name值过滤进行修改
# 快速事务,显式使用事务参考官网
with dataset.connect('sqlite:///mydatabase.db') as tx:
tx['user'].insert(dict(name='John Doe', age=46, country='China'))
# 所有表
tables = db.tables
# 表字段
columns = table.columns
# 总行数
count = len(table)
# 所有数据
users = table.all()
# 搜索
users_china = table.users_in(country='China')
# 获取特定数据
one = table.find_one(name='John Doe')
# 查找多个
users_in = table.find(id=[1, 3, 7])
# 比较查找
elderly_users1 = table.find(age={'>=': 70})
possible_customers = table.find(age={'between': [21, 80]})
elderly_users2 = table.find(table.table.columns.age >= 70)
# 自定义SQL
result = db.query('SELECT country, COUNT(*) c FROM user GROUP BY country')





![[nlp] chathome—家居装修垂类大语言模型的开发和评估](https://img-blog.csdnimg.cn/a4057241b40b4f848b375311c264d586.png)