【深度学习】【Opencv】【GPU】python/C++调用onnx模型【基础】
提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论
文章目录
- 【深度学习】【Opencv】【GPU】python/C++调用onnx模型【基础】
- 前言
- Python版本OpenCV
- Windows平台安装OpenCV
- opencv调用onnx模型
- C++版本OpenCV_GPU
- Windows平台编译安装OpenCV
- opencv调用onnx模型
- 总结
前言
OpenCV是一个基于BSD许可发行的跨平台计算机视觉和机器学习软件库(开源),可以运行在Linux、Windows、Android和Mac OS操作系统上。可以将pytorch中训练好的模型使用ONNX导出,再使用opencv中的dnn模块直接进行加载使用。
系列学习目录:
【CPU】Pytorch模型转ONNX模型流程详解
【GPU】Pytorch模型转ONNX格式流程详解
【ONNX模型】快速部署
【ONNX模型】多线程快速部署
【ONNX模型】opencv_cpu调用onnx
【ONNX模型】opencv_gpu调用onnx
Python版本OpenCV
Windows平台安装OpenCV
博主在win10环境下装anaconda环境,而后搭建onnx模型运行所需的openCV环境。
# 搭建opencv环境
conda create -n opencv_onnx_gpu python=3.10.9 -y
# 激活环境
activate opencv_onnx_gpu
博主使用opencv-4.8.0版本,GPU版本不能直接通过pip下载安装进行使用,必须要在本地进行编译。编译过程具体参考博主的博文windows10下opencv4.8.0-cuda Python版本源码编译教程。
import cv2
cv2.__version__

opencv调用onnx模型
随便拷贝一组数据用来测试数据GPU版本相比于CPU版本在速度上的提升。在项目路径下博主拷贝了CAMO数据集。
将PFNet.onnx也拷贝到项目路径下。
使用opencv并调用gpu完成了整个推理流程。
import cv2
import numpy as np
import glob
import os
import time
def readImagesInFolder(folderPath,images):
fileNames = glob.glob(os.path.join(folderPath, '*.jpg'))
for fileName in fileNames:
bgrImage = cv2.imread(fileName, cv2.IMREAD_COLOR)
if bgrImage is not None:
rgbImage = cv2.cvtColor(bgrImage, cv2.COLOR_BGR2RGB)
images.append(rgbImage)
def transformation(image, targetSize, mean, std):
resizedImage = cv2.resize(image, targetSize, interpolation=cv2.INTER_AREA)
normalized = resizedImage.astype(np.float32)
normalized /= 255.0
normalized -= mean
normalized /= std
return normalized
def loadModel(onnx_path):
net = cv2.dnn.readNetFromONNX(onnx_path)
return net
def main():
# 图片存放文件路径
folderPath = "D:/deeplean_demo/opencv_onnx_gpu/CAMO/c"
rgbImages = []
readImagesInFolder(folderPath, rgbImages)
# 加载ONNX模型
onnx_path = "D:/deeplean_demo/opencv_onnx_gpu/PFNet.onnx"
net = loadModel(onnx_path)
# 设置CUDA为后端
# net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
# net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
output_probs = []
output_layer_names = net.getUnconnectedOutLayersNames()
# 定义目标图像大小
target_size = (416, 416)
# 定义每个通道的归一化参数
mean = (0.485, 0.456, 0.406) # 均值
std = (0.229, 0.224, 0.225) # 标准差
# 开始计时
start = time.time()
for rgb_image in rgbImages:
# 获取图像的大小
original_size = (rgb_image.shape[1], rgb_image.shape[0])
# 图片归一化
normalized = transformation(rgb_image, target_size, mean, std)
print(normalized.shape[:2])
blob = cv2.dnn.blobFromImage(normalized)
# 将Blob设置为模型的输入
net.setInput(blob)
# 运行前向传播
output_probs = net.forward(output_layer_names)
# 获取最完整的预测
prediction = output_probs[3]
# 预测图变mask
mask = cv2.resize(np.squeeze(prediction)* 255.0, original_size, interpolation=cv2.INTER_AREA)
end = time.time()
# 计算耗时
elapsed_time = end - start
# 打印耗时
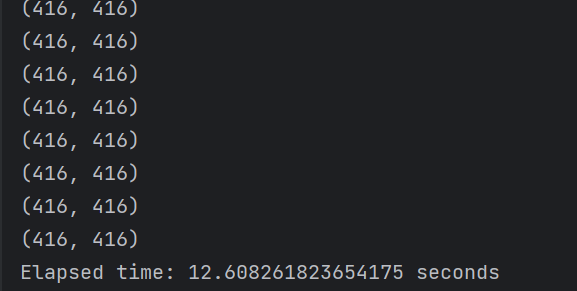
print("Elapsed time:", elapsed_time, "seconds")
if __name__ == "__main__":
main()
gpu模式下250张图片只用了大约13秒。
假设注释掉与gou相关的代码
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
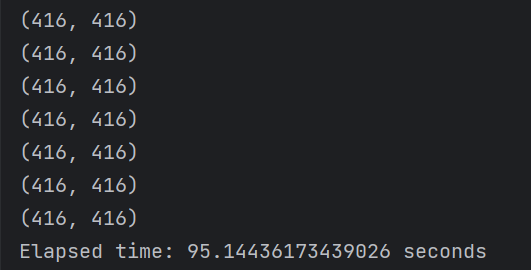
cpu模式下250张图片就用了大约95秒。
C++版本OpenCV_GPU
Windows平台编译安装OpenCV
博主使用opencv-4.8.0版本,GPU版本不能直接通过官网下载exe进行使用,必须要在本地进行编译。编译过程具体参考博主的博文【windows10下opencv4.8.0-cuda C++版本源码编译教程】。
编译完成后,在输出的文件夹内找到install文件,将其拷贝合适的位置。
博主新建了一个名为opencv_gpu的文件夹,并将install重命名位build放在其中。
打开VS 2019:新建新项目---->空项目---->配置项目---->项目路径以及勾选“将解决方案和项目放在同一目录中---->点击创建。
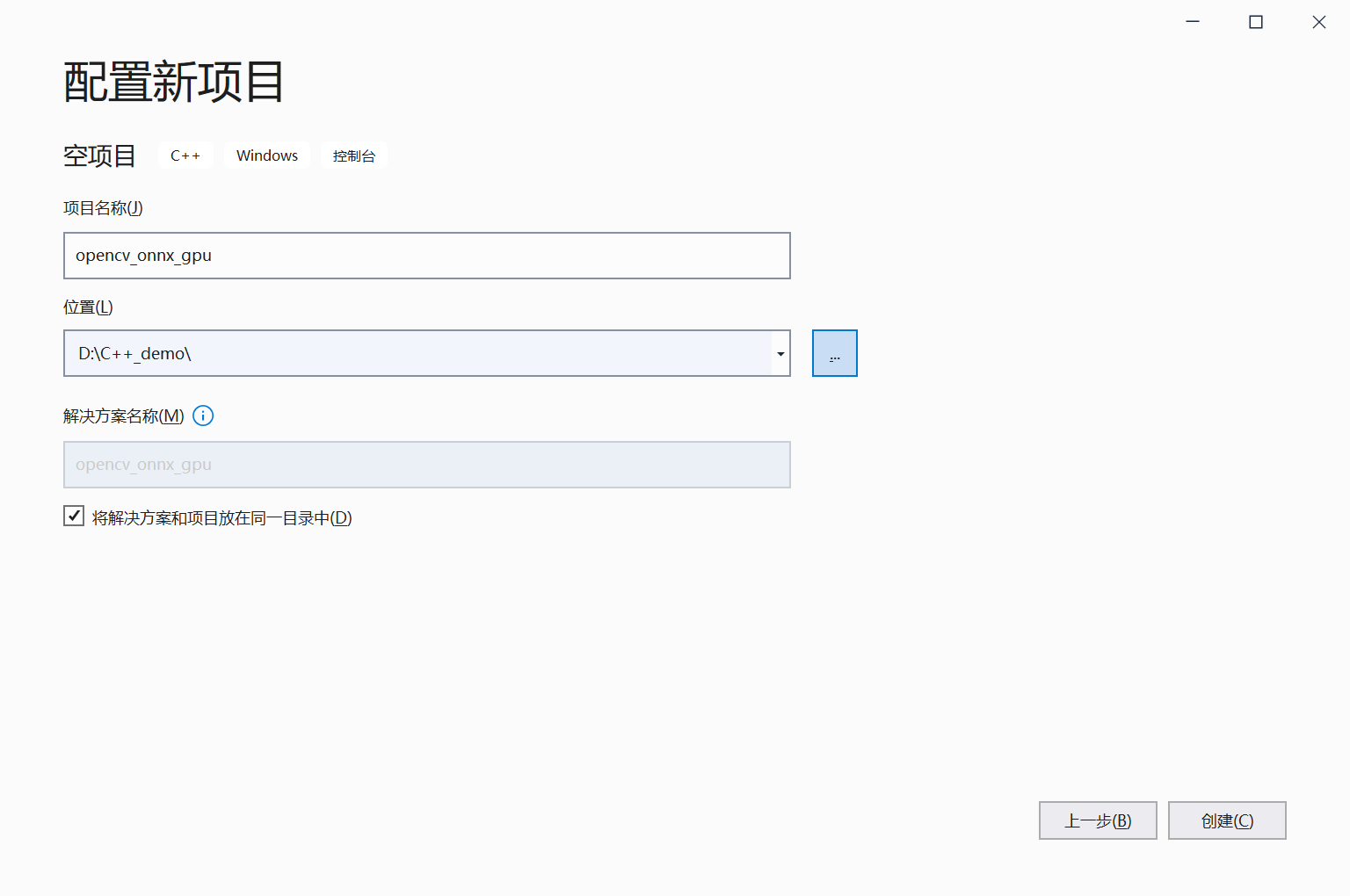
在解决方案–>源文件–>右键添加新建项。这里暂时可以默认空着不做处理。
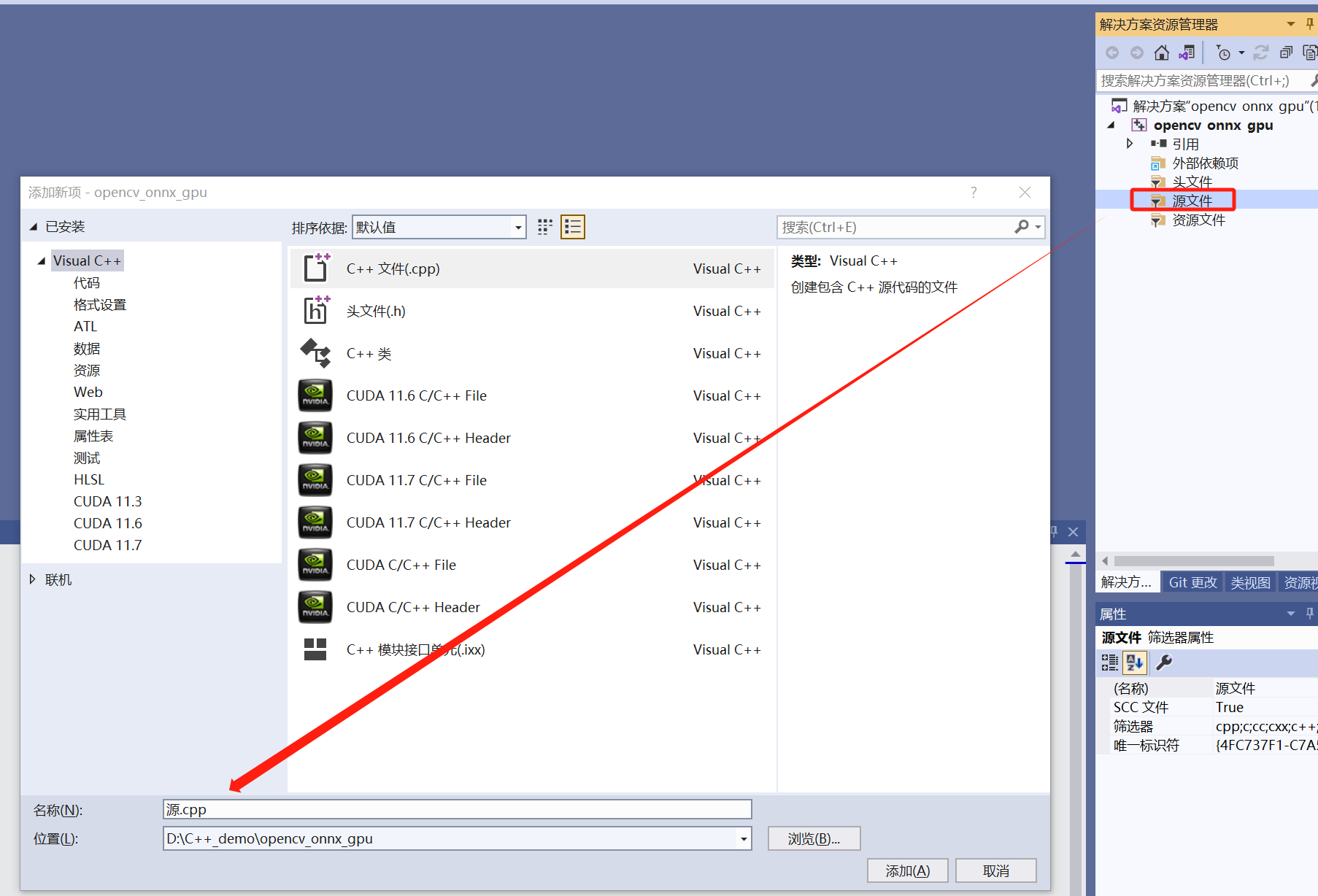
设置OpenCV路径:项目---->属性。假设没有新建cpp文件,空项目的属性页就不会存在C/C++这一项目。
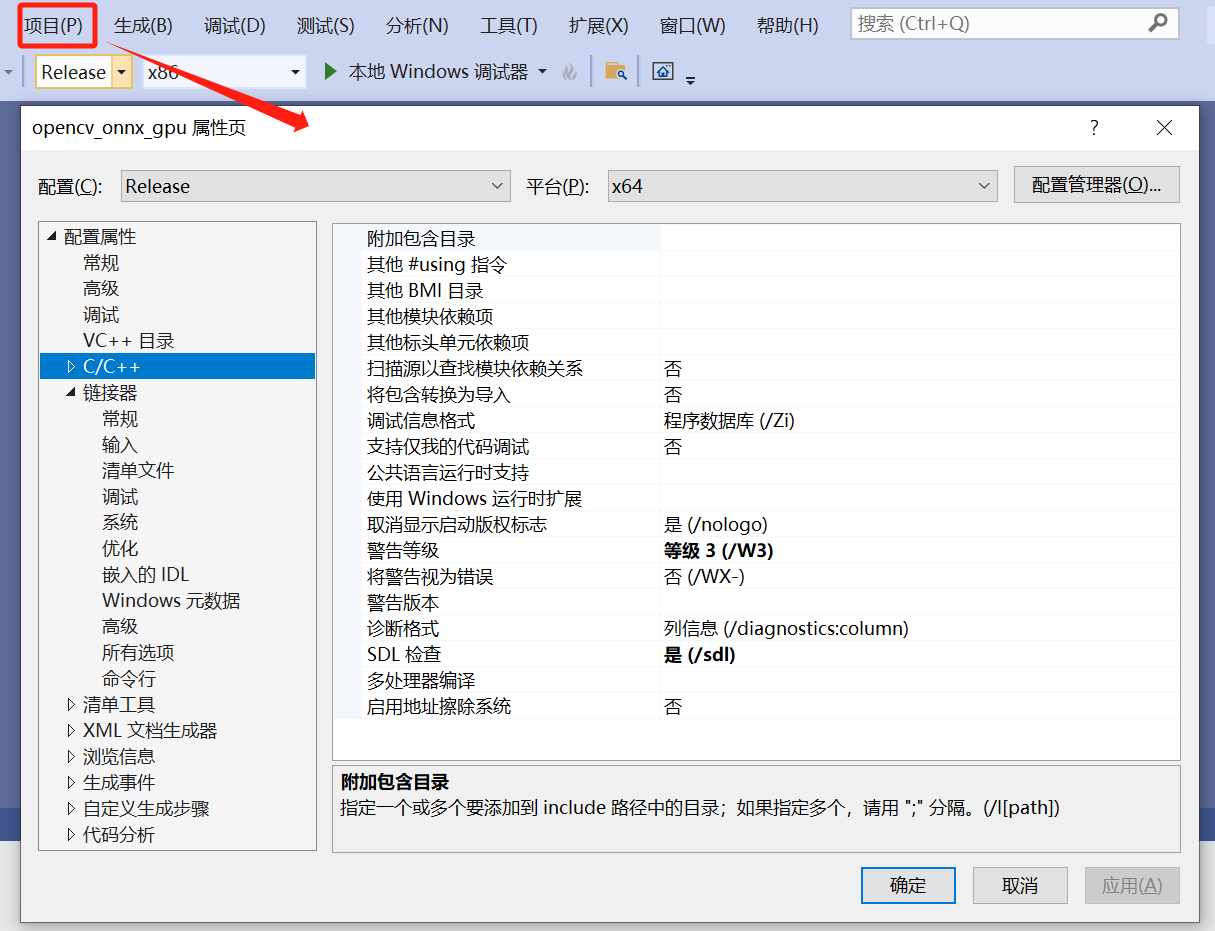
添加附加包含目录:Release | x64---->C/C+±—>常规---->附加包含目录。
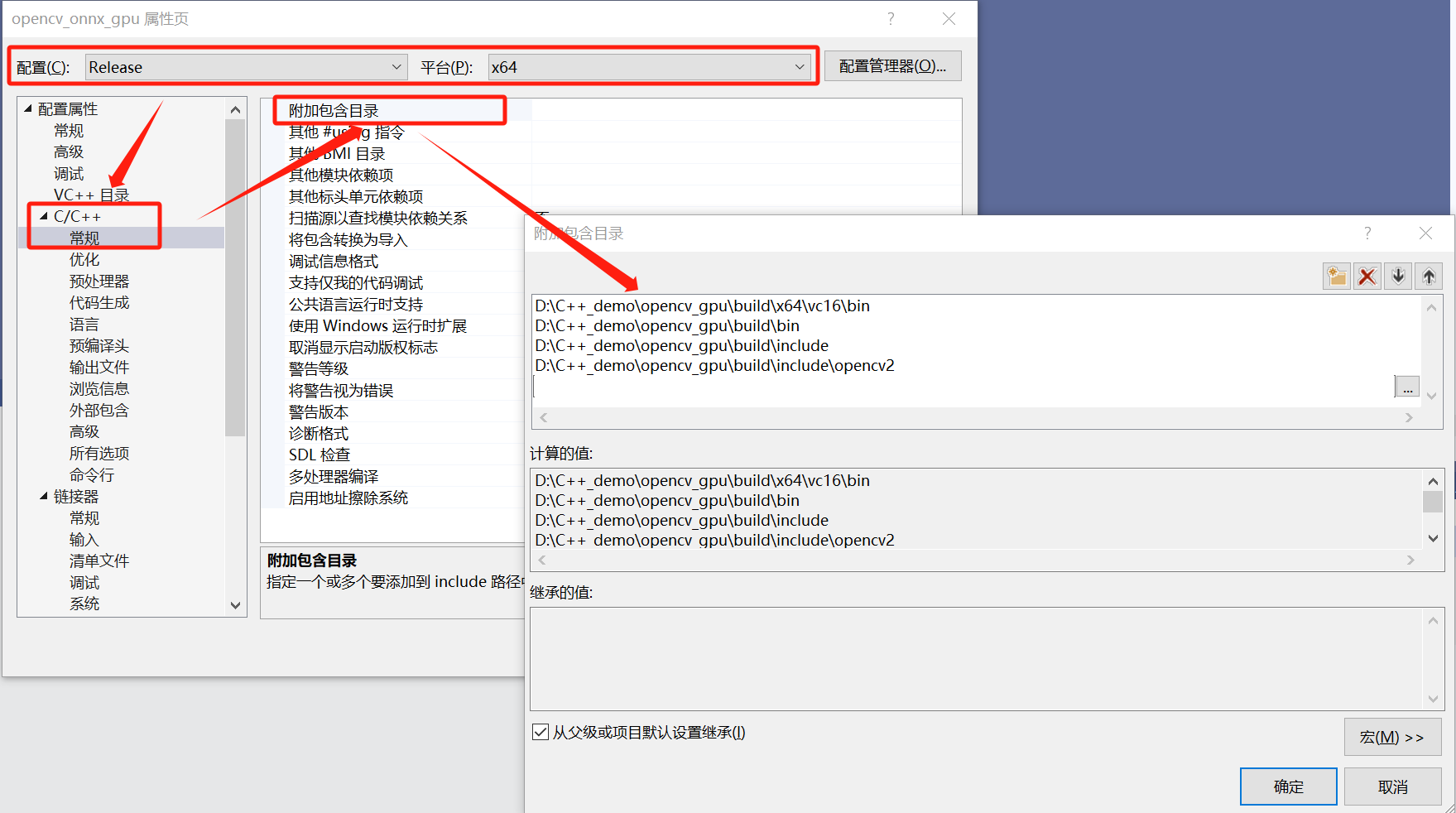
D:\C++_demo\opencv_gpu\build\x64\vc16\bin
D:\C++_demo\opencv_gpu\build\bin
D:\C++_demo\opencv_gpu\build\include
D:\C++_demo\opencv_gpu\build\include\opencv2
链接器:Release | x64---->链接器---->常规---->附加包含目录。
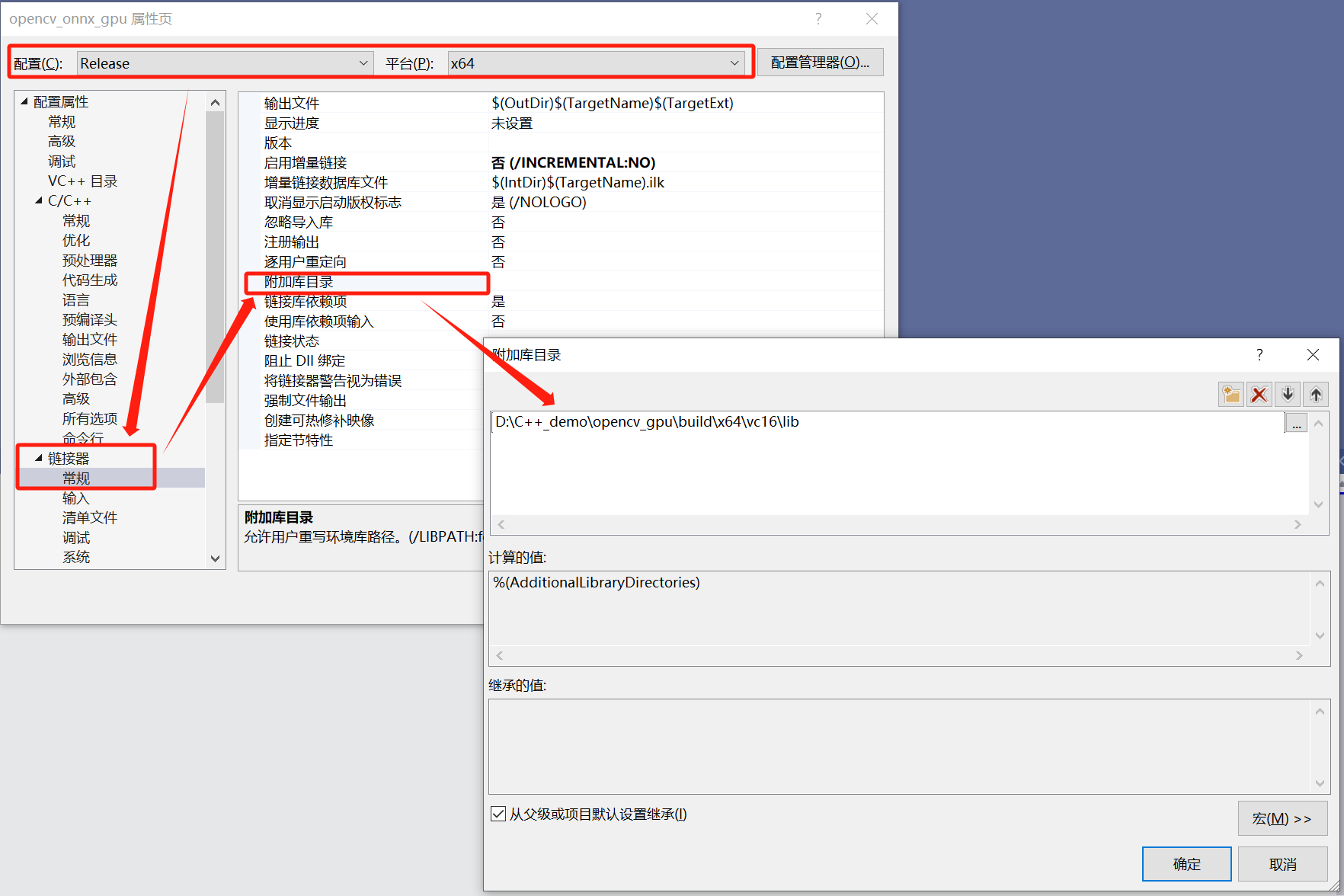
D:\C++_demo\opencv_gpu\build\x64\vc16\lib
链接器:Release | x64---->链接器---->输入---->附加依赖项。
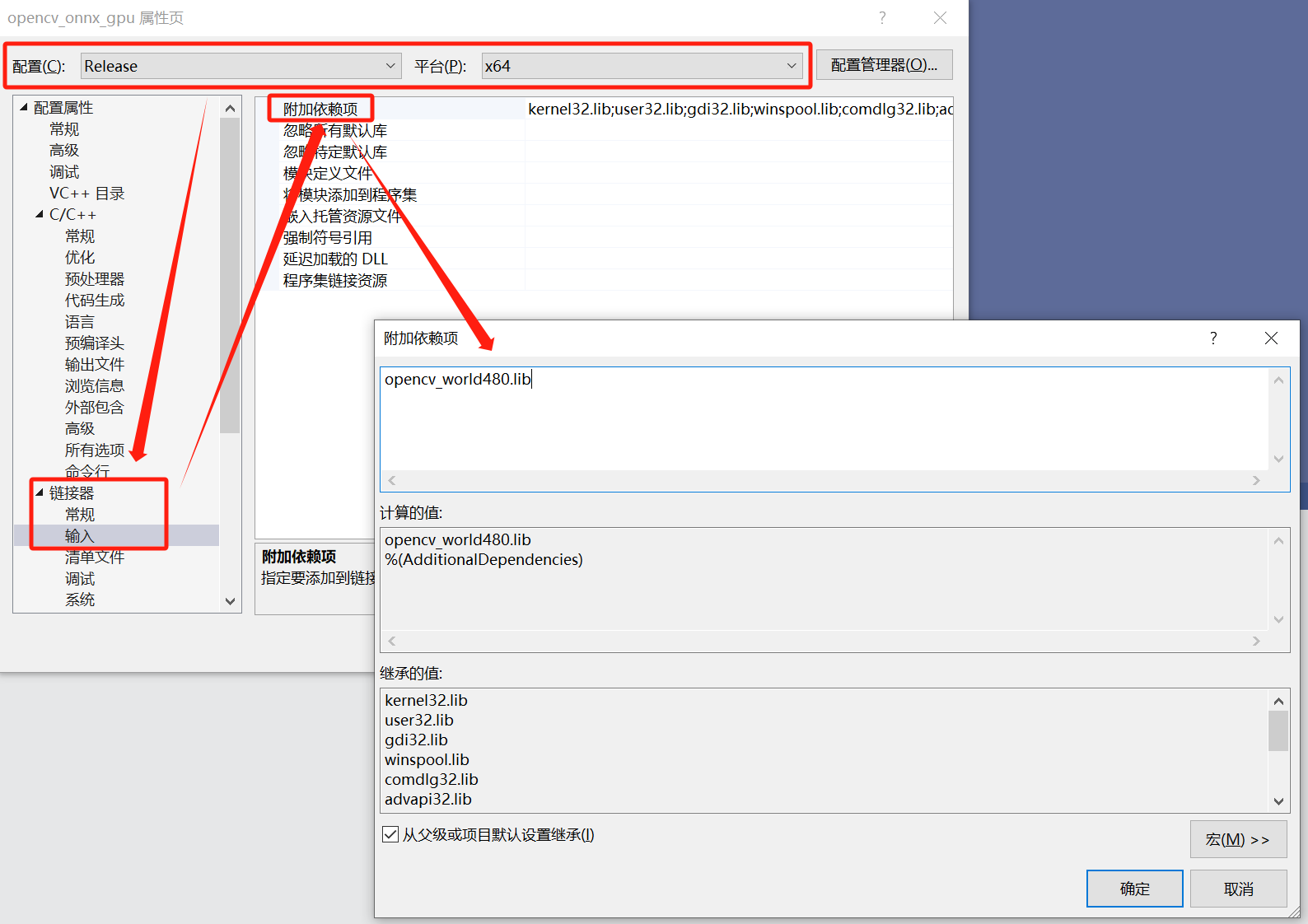
在D:\C++_demo\opencv_gpu\build\x64\vc16\lib下找到附加依赖项的文件。
opencv_world480.lib
在Release x64模式下测试,将opencv_world480.dll文件复制到自己项目的Release下。
没有Release目录时,需要在Release | x64模式下运行一遍代码,代码部分在下一节提供,读者可以先行新建文件复制代码。
D:\C++_demo\opencv_gpu\build\x64\vc16\bin
===>
D:\C++_demo\opencv_onnx_gpu\x64\Releas
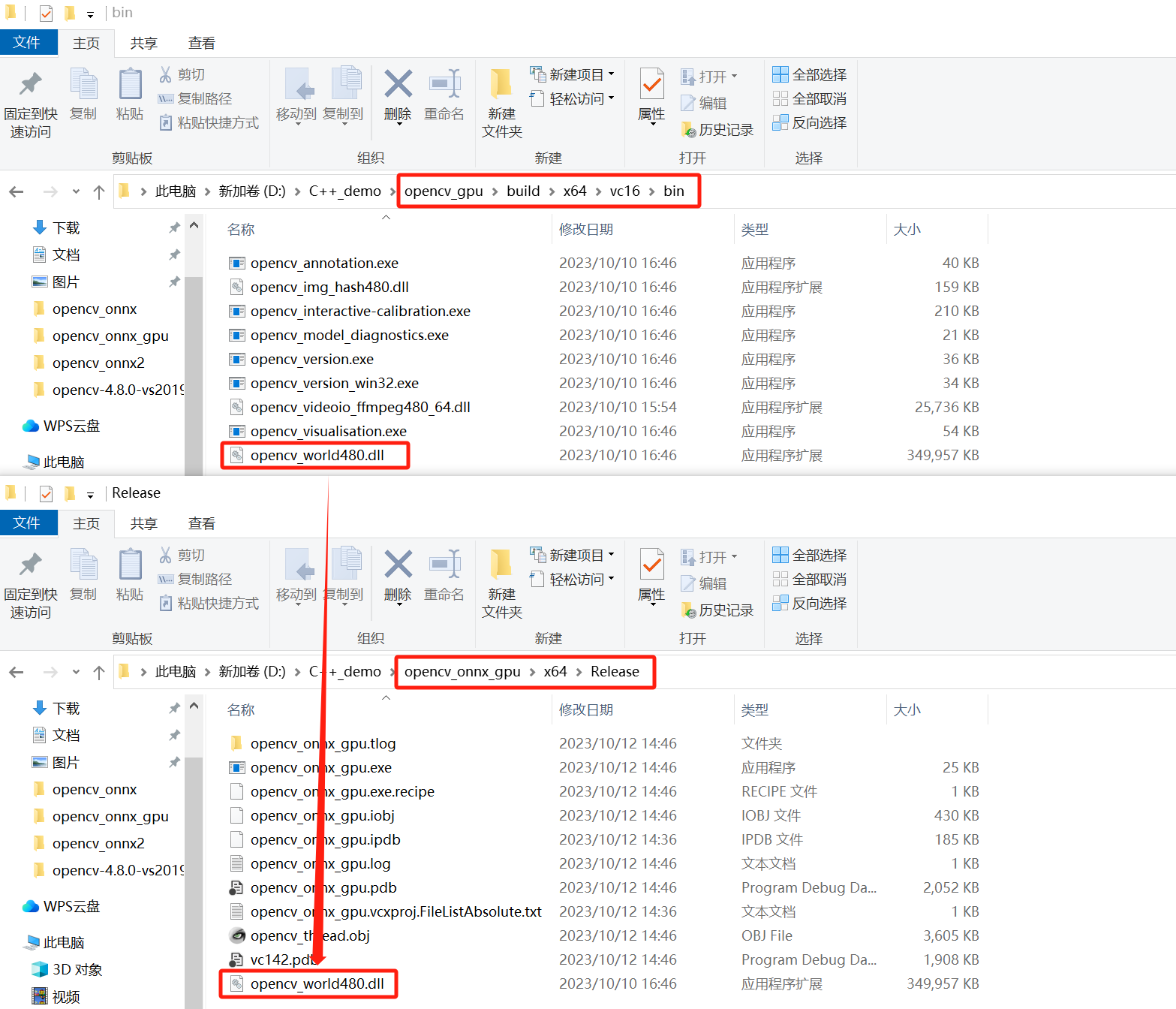
这里博主为了方便安装的是release版本的,读者可以安装debug版本的,流程基本一致,只需要将属性的Release | x64变成Debug | x64,然后附加依赖项由opencv_world480.lib变成opencv_world480d.lib,再将opencv_world480d.dll文件复制到自己项目的Release下。前提是你编译了debug版本oepncv。
opencv调用onnx模型
随便拷贝一组数据用来测试数据GPU版本相比于CPU版本在速度上的提升。在项目路径下博主拷贝了CAMO数据集。
将PFNet.onnx也拷贝到项目路径下。
将python版本的opencv转化成对应的c++版本的,发现输出的效果完全一致,onnx模型可以作为c++的接口来供其他应用调用。
#include <iostream>
#include <string>
#include <vector>
#include<opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
using namespace std;
void readImagesInFolder(const std::string& folderPath, std::vector<cv::Mat>& images)
{
cv::String path(folderPath + "/*.jpg"); // 这里假设你的图片格式是.jpg,如果是其他格式请相应修改
std::vector<cv::String> fileNames;
cv::glob(path, fileNames, true); // 通过glob函数获取文件夹内所有符合格式的文件名
cv::Mat rgbImage;
for (const auto& fileName : fileNames)
{ // 使用imread函数读取图片
cv::Mat bgrImage = cv::imread(fileName, cv::IMREAD_COLOR);
// 图片格式转化bgr-->rgb
if (!bgrImage.empty())
{
cv::cvtColor(bgrImage, rgbImage, cv::COLOR_BGR2RGB);
images.push_back(rgbImage);
}
}
}
cv::Mat transformation(const cv::Mat& image, const cv::Size & targetSize, const cv::Scalar& mean, const cv::Scalar& std) {
cv::Mat resizedImage;
//图片尺寸缩放
cv::resize(image, resizedImage, targetSize, 0, 0, cv::INTER_AREA);
cv::Mat normalized;
resizedImage.convertTo(normalized, CV_32F);
cv::subtract(normalized / 255.0, mean, normalized);
cv::divide(normalized, std, normalized);
return normalized;
}
cv::dnn::Net loadModel(const string& onnx_path) {
cv::dnn::Net net = cv::dnn::readNetFromONNX(onnx_path);
return net;
}
int main()
{ // 图片存放文件路径
string folderPath = "D:/C++_demo/opencv_onnx_gpu/CAMO/c";
std::vector<cv::Mat> rgbImages;
readImagesInFolder(folderPath, rgbImages);
// string image_path = "./animal-1.jpg";
// 加载ONNX模型
string onnx_path = "D:/C++_demo/opencv_onnx_gpu/PFNet.onnx";
cv::dnn::Net net = loadModel(onnx_path);
// 设置CUDA为后端
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
cv::Mat output_prob;
std::vector<cv::Mat> output_probs;
std::vector<cv::String> output_layer_names = net.getUnconnectedOutLayersNames();
// 定义目标图像大小
cv::Size targetSize(416, 416);
// 定义每个通道的归一化参数
cv::Scalar mean(0.485, 0.456, 0.406); // 均值
cv::Scalar std(0.229, 0.224, 0.225); // 标准差
// 开始计时
auto start = chrono::high_resolution_clock::now();
for (const auto& rgbImage : rgbImages) {
// 获取图像的大小
cv::Size originalSize(rgbImage.cols, rgbImage.rows);
//cv::imshow("输入窗口", rgbImage);
//cv::waitKey(0);
//cv::destroyAllWindows();
// 图片归一化
cv::Mat normalized = transformation(rgbImage, targetSize, mean, std);
std::cout << normalized.size() << std::endl;
cv::Mat blob = cv::dnn::blobFromImage(normalized);
// 将Blob设置为模型的输入
net.setInput(blob);
// 运行前向传播
net.forward(output_probs, output_layer_names);
// 获取最完整的预测
cv::Mat prediction = output_probs[3];
// 预测图变mask
cv::Mat mask;
cv::resize(prediction.reshape(1, 416) * 255.0, mask, originalSize, 0, 0, cv::INTER_AREA);
}
auto end = std::chrono::high_resolution_clock::now();
// 计算耗时
std::chrono::duration<double> elapsed = end - start;
double elapsedTime = elapsed.count();
// 打印耗时
std::cout << "Elapsed time: " << elapsedTime << " seconds" << std::endl;
return 0;
}
gpu模式下250张图片只用了大约16秒。
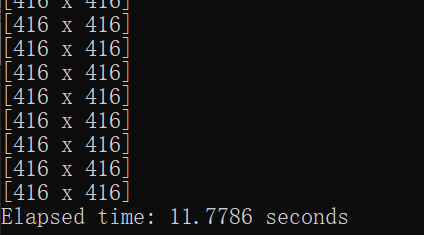
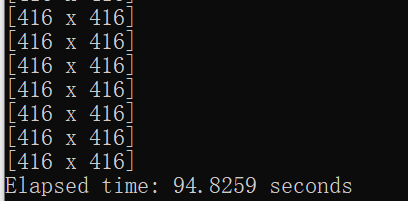
假设注释掉与gou相关的代码
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
cpu模式下250张图片就用了大约95秒。
总结
尽可能简单、详细的介绍Python和C++下Opencv_GPU调用ONNX模型的流程。