0.前言
在调试深度神经网络工程时,常会在前向计算过程中将网络的中间层信息返回,便于打印或者可视化网络中间结果。实现该功能的一个常用方法是在构建model类时,在forward返回要保留的中间信息。
这里跟大家分享一个更优雅、便捷的方法,利用torchvision提供的IntermediateLayerGetter类,在网络前向计算时返回指定的特征。
1.使用方法
IntermediateLayerGetter类在torchvision/models/_utils.py中实现。
一个简单的使用案例如下:
import torch
import torchvision.models as models
original_model = models.resnet18(pretrained=True)
wrapped_model = models._utils.IntermediateLayerGetter(original_model, {'layer1': 'feat1', 'layer3': 'feat2'})
out = wrapped_model(torch.rand(1, 3, 224, 224))
print(out['feat1'].shape)
print(out['feat2'].shape)
IntermediateLayerGetter类在实例化时,对原来的模型类进行了一层封装,且需要传入字典来指示想返回的中间特征名和访问特征时使用的name。
构造IntermediateLayerGetter时需要传入字典,字典的key来源于dict(original_model.named_children()).keys(),对于上例,key来源于:
dict_keys(['conv1', 'bn1', 'relu', 'maxpool', 'layer1', 'layer2', 'layer3', 'layer4', 'avgpool', 'fc'])
传入字典的值是自己定义的字符串,在前向推理结束后的返回结果中,将自定义的字符串作为key来访问对应的中间变量。比如上例传入的字典是{'layer1': 'feat1', 'layer3': 'feat2'},则得到前向推理输出结果out后,通过out['feat1']访问layer1的输出,通过out['feat2']访问layer3的输出。
2.原理
IntermediateLayerGetter类的源码比较简单,如下:
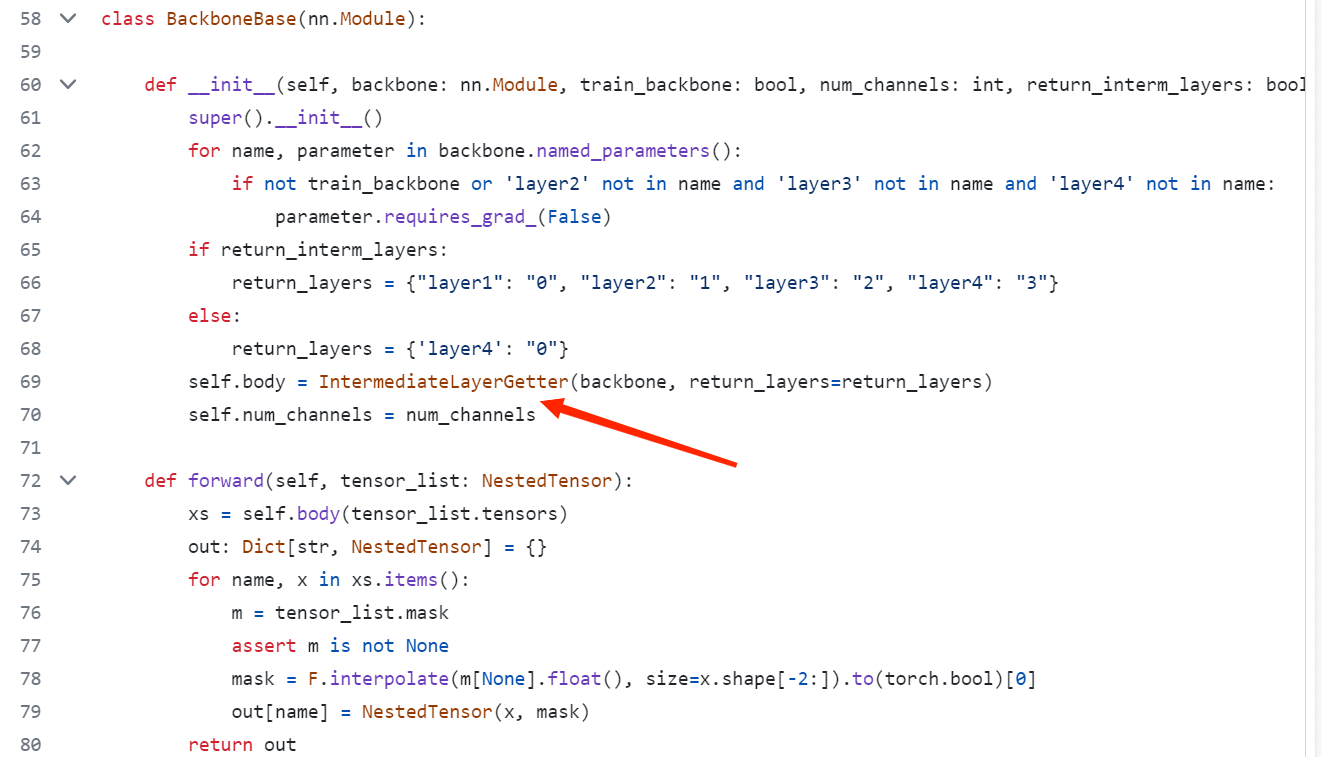
class IntermediateLayerGetter(nn.ModuleDict):
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()}
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super().__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x):
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
本质上来讲,IntermediateLayerGetter的实例在初始化时,使用model.named_children()构造一个OrderDict,再用得到的OrderDict去初始化容器nn.ModuleDict()。
在前向计算时按照nn.ModuleDict()容器的内容,顺序执行里面的模块;只是在执行时,会判断容器中模块的名字【即model.named_children()的key】是否在指定的返回值名字列表中,若在列表中,则保存该中间结果到返回值字典中。
这就是在实例化IntermediateLayerGetter时传入字典的key来源于dict(original_model.named_children()).keys()的原因。
3.局限性
根据前文IntermediateLayerGetter的实现方法以及原理,可以很容易发现使用IntermediateLayerGetter获取网络推理中间结果的局限性:
(1)只能获取model.named_children()级别的模块的输出特征,对于更细分模块的输出特征则无法获取;
(2)模型的顶层必须是可以顺序执行的,因为只有这样才能将model.named_children()获取的模块存到OrderDict中并封装为nn.ModuleDict()。
4.开源工程使用案例
在DETR官方的开源代码中(链接:https://github.com/facebookresearch/detr),在文件models/backbone.py的BackboneBase类中使用了该方法获取其中model的中间结果。
推荐阅读
港科大提出适用于夜间场景语义分割的无监督域自适应新方法
EViT:借鉴鹰眼视觉结构,南开大学等提出ViT新骨干架构,在多个任务上涨点
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
CV计算机视觉每日开源代码Paper with code速览-2023.10.13
CV计算机视觉每日开源代码Paper with code速览-2023.10.12
CV计算机视觉每日开源代码Paper with code速览-2023.10.10






![2023年中国氯丁橡胶产量、需求量及进出口现状分析[图]](https://img-blog.csdnimg.cn/img_convert/3b00590f0e73db1b5da8b4a62654a445.png)
![[正式学习java①]——java项目结构,定义类和创建对象,一个标准javabean的书写](https://img-blog.csdnimg.cn/ecd3a19b96fa453fb66bbe827e3458cf.png)