文章目录
- 零、学习目标
- 一、导入新课
- 二、新课讲解
- (一)Hadoop的前世今生
- 1、Google处理大数据三大技术
- 2、Hadoop如何诞生
- 3、Hadoop主要发展历程
- (二)Hadoop的优势
- 1、扩容能力强
- 2、成本低
- 3、高效率
- 4、可靠性
- 5、高容错性
- (三)Hadoop的生态体系
- 1、HDFS分布式文件系统
- 2、MapReduce分布式计算框架
- 3、Yarn资源管理框架
- 4、Sqoop数据迁移工具
- 5、Mahout数据挖掘算法库
- 6、HBase分布式存储系统
- 7、ZooKeeper分布式协作服务
- 8、Hive数据仓库
- 9、Flume日志收集工具
- 10、Spark内存计算框架
- 11、Tez计算框架
- 12、Ambari管理工具
- 13、Avro™序列化系统
- 14、Cassandra数据库系统
- 15、Chukwa数据收集系统
- 16、Pig数据流系统
- 17、Kafka消息系统
- 18、Oozie作业流调度引擎
- 19、Storm流处理框架
- 20、Flink实时处理框架
- 21、Apache Phoenix
- 22、Apache Drill
- 23、Apache Hudi
- 24、Apache Kylin
- 25、Apache Presto
- 26、ClickHouse
- 27、Apache Druid
- 28、TensorFlow
- 29、PyTorch
- 30、Apache Superset
- 31、Elasticsearch
- 32、Jupyter Notebook
- 33、Apache Zeppelin
- (四)Hadoop的版本情况
- 1、Hadoop发行版
- (1)Apache Hadoop
- (2)Cloudera Hadoop
- (3)Hortonworks Hadoop
- 2、Hadoop版本升级
- (1)Hadoop1.x
- (2)Hadoop2.x
- (3)Hadoop3.x
- 三、归纳总结
- 四、上机操作
零、学习目标
- 了解Hadoop的发展历史
- 了解Hadoop的版本情况
- 掌握Hadoop的生态体系
一、导入新课
- 上次课,主要讲解了大数据的应用场景,大数据应用在各个行业。Hadoop作为一个能够对大量数据进行分布式处理的框架,用户可以利用Hadoop开发和处理海量数据。本次课将针对Hadoop的基本概念、优势与生态体系进行详细讲解。
二、新课讲解

(一)Hadoop的前世今生
1、Google处理大数据三大技术
- 大数据技术首先需要解决的问题是如何高效、安全地存储;其次是如何高效、及时地处理海量的数据,并返回有价值的信息;最后是如何通过机器学习算法,从海量数据中挖掘出潜在的价值,并构建模型,以用于预测预警。
- 随着数据的快速增长,数据的存储和分析都变的越来越困难。例如存储容量、读写速度、计算效率等都无法满足用户的需求。可以说,当今大数据的基石,来源于谷歌公司的三篇论文,这三篇论文主要阐述了谷歌公司对于大数据问题的解决方案。
| 论文 | 解决问题 |
|---|---|
| Google File System | 主要解决大数据分布式存储的问题 |
| Google MapReduce | 主要解决大数据分布式计算的问题 |
| Google BigTable | 主要解决大数据分布式查询的问题 |
- 三大革命性技术的优点
| 编号 | 优点 |
|---|---|
| 1 | 成本降低、能用PC机,就不用大型机和高端存储 |
| 2 | 软件容错硬件故障视为常态,通过软件保证可靠性 |
| 3 | 简化并行分布式计算,无须控制节点同步和数据交换 |
- 当前大数据工具的蓬勃发展,或多或少都受到上述论文的启发,不少社区根据论文的相关原理,实现了最早一批的开源大数据工具,如Hadoop和HBase。但值得注意的是,当前每个大数据工具都专注于解决大数据领域的特定问题,很少有一种大数据工具可以一站式解决所有的大数据问题。因此,一般来说,大数据应用需要多种大数据工具相互配合,才能解决大数据相关的业务问题。大数据工具非常多,据不完全统计,大约有一百多种,但常用的只有10多种,这些大数据工具重点解决的大数据领域各不相同。
| 大数据领域 | 常用工具 |
|---|---|
| 分布式存储 | 主要包含Hadoop HDFS和Kafka等 |
| 分布式计算 | 包括批处理和流计算,主要包含Hadoop MapReduce、Spark和Flink等 |
| 分布式查询 | 主要包括Hive、HBase、Kylin、Impala等 |
| 分布式挖掘 | 主要包括Spark ML和Alink等 |
- 据中国信通院企业采购大数据软件调研报告来看,86.6%的企业选择基于开源软件构建自己的大数据处理业务,因此学习和掌握几种常用的开源大数据工具,对于大数据开发人员来说至关重要。
2、Hadoop如何诞生
- 在2003至2004年,Google陆续公布了部分GFS和MapReduce思想的细节,Nutch的创始人Doug Cutting受到启发,用了若干年时间实现了DFS和MapReduce机制,使Nutch性能飙升。

- 2005年,Hadoop作为Lucene子项目Nutch的一部分正式被引入Apache基金会,随后又从Nutch中剥离,成为一套完整独立的软件,起名为Hadoop。据说,Hadoop这个名字来源于创始人Doug Cutting儿子的毛绒玩具大象,因此,Hadoop的Logo形象如下图。

- Hadoop是一个由Apache基金会开发的分布式系统基础架构,源于论文Google File System。Hadoop工具可以让用户在不了解分布式底层细节的情况下,开发分布式程序,从而大大降低大数据程序的开发难度。它可以充分利用计算机集群构建的大容量、高计算能力来对大数据进行存储和运算。
- 在大数据刚兴起之时,Hadoop可能是最早的大数据工具,它也是早期大数据技术的代名词。时至今日,虽然大数据工具种类繁多,但是不少工具的底层分布式文件系统还是基于Hadoop的HDFS(Hadoop Distributed File System)。
- Hadoop框架前期最核心的组件有两个,即HDFS和MapReduce。后期又加入了YARN组件,用于资源调度。其中HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了分布式计算能力。
- HDFS有高容错性的特点,且支持在低廉的硬件上进行部署,而且Hadoop访问数据的时候,具有很高的吞吐量,适合那些有着超大数据集的应用程序。
- 可以说,Hadoop工具是专为离线和大规模数据分析而设计的,但它并不适合对几个记录随机读写的在线事务处理模式。
- 目前来说,Hadoop工具不支持数据的部分update操作,因此不能像关系型数据库那样,可以用SQL来更新部分数据。
3、Hadoop主要发展历程
- 随着开源社区的不断发展,越来越多的优秀项目被开源,以处理各种大数据场景下的问题和挑战。作为目前大数据生态系统内的早期开源项目,Hadoop在廉价机器上实现了分布式数据存储和高性能分布式计算,大大降低了数据存储和计算成本。Hadoop提供的分布式存储系统HDFS、大数据集并行计算编程模型MapReduce、资源调度框架YARN已经被广泛应用,为大数据生态系统的发展奠定了坚实的基础。如今,Hadoop大数据生态圈发展已经非常全面,涉及领域众多,在大数据处理系统中常用的技术框架包括数据采集、数据存储、数据分析、数据挖掘、批处理、实时流计算、数据可视化、监控预警、信息安全等。
- 下面我们回顾一下近10年来Hadoop的主要发展历程。

| 时间 | 事件 |
|---|---|
| 2008年1月 | Hadoop成为Apache顶级项目。 |
| 2008年6月 | Hadoop的第一个SQL框架——Hive成为了Hadoop的子项目。 |
| 2009年7月 | MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。 |
| 2009年7月 | Avro 和 Chukwa 成为Hadoop新的子项目。 |
| 2010年5月 | Avro脱离Hadoop项目,成为Apache顶级项目。 |
| 2010年5月 | HBase脱离Hadoop项目,成为Apache顶级项目。 |
| 2010年9月 | Hive脱离Hadoop,成为Apache顶级项目。 |
| 2010年9月 | Pig脱离Hadoop,成为Apache顶级项目。 |
| 2010年-2011年 | 扩大的Hadoop社区忙于建立大量的新组件(Crunch,Sqoop,Flume,Oozie等)来扩展Hadoop的使用场景和可用性。 |
| 2011年1月 | ZooKeeper 脱离Hadoop,成为Apache顶级项目。 |
| 2011年12月 | Hadoop1.0.0版本发布,标志着Hadoop已经初具生产规模。 |
| 2012年5月 | Hadoop 2.0.0-alpha版本发布,这是Hadoop-2.x系列中第一个(alpha)版本。与之前的Hadoop-1.x系列相比,Hadoop-2.x版本中加入了YARN,YARN成为了Hadoop的子项目。 |
| 2012年10月 | Impala加入Hadoop生态圈。 |
| 2013年10月 | Hadoop2.0.0版本发布,标志着Hadoop正式进入MapReduce v2.0时代。 |
| 2014年2月 | Spark开始代替MapReduce成为Hadoop的默认执行引擎,并成为Apache顶级项目。 |
| 2017年12月 | 继Hadoop3.0.0的四个Alpha版本和一个Beta版本后,第一个可用的Hadoop 3.0.0版本发布。 |
(二)Hadoop的优势
- Hadoop作为大数据中常见的分布式计算平台,能够处理海量数据,并对数据进行分析。经过十几年的发展,Hadoop已经形成了以下几点优势。

1、扩容能力强
- Hadoop是一个高度可扩展的存储平台,它可以存储和分发跨越数百个并行操作的廉价的服务器数据集群。不同于传统的关系型数据库不能扩展到处理大量的数据,Hadoop是能给企业提供涉及成百上千TB的数据节点上运行的应用程序。
2、成本低
- Hadoop为企业用户提供了极具缩减成本的存储解决方案。通过普通廉价的机器组成服务器集群来分发处理数据,成本比较低,普通用户也很容易在自己的PC机上搭建Hadoop运行环境。
3、高效率
- Hadoop能够并发处理数据,并且能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理数据的速度是非常快的。
4、可靠性
- Hadoop自动维护多份数据副本,假设计算任务失败,Hadoop能够针对失败的节点重新分布处理。
5、高容错性
- Hadoop的一个关键优势就是容错能力强,当数据被发送到一个单独的节点,该数据也被复制到集群的其他节点上,这意味着故障发生时,存在另一个副本可供使用。
(三)Hadoop的生态体系
- 随着Hadoop的不断发展,Hadoop生态体系越来越完善,现如今已经发展成一个庞大的生态体系。

1、HDFS分布式文件系统
- HDFS是Hadoop的分布式文件系统。是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
2、MapReduce分布式计算框架
- MapReduce是一种分布式计算框架,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行归约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
3、Yarn资源管理框架
- YARN(Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
4、Sqoop数据迁移工具
- 数据同步工具Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
5、Mahout数据挖掘算法库
- 数据挖掘算法库Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
6、HBase分布式存储系统
- HBase工具是一个分布式的、面向列的开源数据库,该技术来源于Google BigTable 的论文。它在Hadoop之上提供了类似于Google BigTable的能力。HBase不同于一般的关系数据库,它是一个适合存储非结构化数据的数据库,且采用了基于列而不是基于行的数据存储模式。
- HBase在很多大型互联网公司得到应用,如阿里、京东、小米和Facebook等。Facebook用HBase存储在线消息,每天数据量近百亿;小米公司的米聊历史数据和消息推送等多个重要应用系统都建立在HBase之上。
| 场景 | 说明 |
|---|---|
| 密集型写应用 | 写入量巨大,而相对读数量较小的应用,比如消息系统的历史消息,游戏的日志等。 |
| 查询逻辑简单的应用 | HBase只支持基于rowkey的查询,而像SQL中的join等查询语句,它并不支持。 |
| 对性能和可靠性要求非常高的应用 | 由于HBase本身没有单点故障,可用性非常高。它支持在线扩展节点,即使应用系统的数据在一段时间内呈井喷式增长,也可以通过横向扩展来满足功能要求。 |
- HBase读取速度快得益于内部使用了LSM树型结构,而不是B或B+树。一般来说,磁盘的顺序读取速度很快,但相对而言,寻找磁道的速度就要慢很多。HBase的存储结构决定了读取任意数量的记录不会引发额外的寻道开销。
- 目前来说,HBase不能基于SQL来查询数据,需要使用API。
- 官网地址:http://hbase.apache.org
7、ZooKeeper分布式协作服务
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和HBase的重要组件。
8、Hive数据仓库
- 对于数据的查询和操作,一般开发人员熟悉的是SQL语句,但是Hadoop不支持SQL对数据的操作,而是需要用API来进行操作,这个对于很多开发人员来说并不友好。因此,很多开发人员期盼能用SQL语句来查询Hadoop中的分布式数据。
- Hive工具基于Hadoop组件,可以看作是一个数据仓库分析系统,Hive提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据。
- Hive可以将结构化的数据文件映射为一张数据表,这样就可以利用SQL来查询数据。本质上,Hive是一个翻译器,可以将SQL语句翻译为MapReduce任务运行。
- Hive SQL使不熟悉MapReduce的开发人员可以很方便地利用SQL语言进行数据的查询、汇总和统计分析。但是Hive SQL与关系型数据库的SQL略有不同,虽然它能支持绝大多数的语句,如DDL、DML以及常见的聚合函数、连接查询和条件查询等。
- Hive还支持UDF(User-Defined Function,用户定义函数),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。Hive不适合用于联机事务处理,也不适合实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
- Hive的特点包括:可伸缩、可扩展、容错、输入格式的松散耦合。Hive最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
- 目前来说,Hive中的SQL支持度有限,只支持部分常用的SQL语句,且不适合update操作去更新部分数据,即不适合基于行级的数据更新操作。
- 官网地址:http://hive.apache.org
9、Flume日志收集工具
- Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
10、Spark内存计算框架
- Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。它是加州大学伯克利分校的AMP实验室开源的通用并行框架。它不同于Hadoop MapReduce,计算任务中间输出结果可以保存在内存中,而不再需要读写HDFS,因此Spark计算速度更快,也能更好地适用于机器学习等需要迭代的算法。
- Apache Spark是由Scala语言开发的,可以与Java程序一起使用。它能够像操作本地集合对象一样轻松地操作分布式数据集。它具有运行速度快、易用性好、通用性强和随处运行等特点。
- Apache Spark提供了Java、Scala、Python以及R语言的API。还支持更高级的工具,如Spark SQL、Spark Streaming、Spark MLlib和Spark GraphX等。
| 优点 | 说明 |
|---|---|
| 非常快的计算速度 | 它主要在内存中计算,因此在需要反复迭代的算法上,优势非常明显,比Hadoop快100倍。 |
| 易用性 | 它大概提供了80多个高级运算符,包括各种转换、聚合等操作。这相对于Hadoop组件中提供的map和reduce两大类操作来说,丰富了很多,因此可以更好地适应复杂数据的逻辑处理。 |
| 通用性 | 它除了自身不带数据存储外,其他大数据常见的业务需求,比如批处理、流计算、图计算和机器学习等都有对应的组件。因此,开发者通过Spark提供的各类组件,如Spark SQL、SparkStreaming、Spark MLlib和Spark GraphX等,可以在同一个应用程序中无缝组合使用这些库。 |
| 支持多种资源管理器 | 它支持Hadoop YARN、Apache Mesos,以及Spark自带的Standalone集群管理器。 |
- Spark的官网地址:http://spark.apache.org
11、Tez计算框架
- Tez 是 Apache 最新的支持 DAG 作业的开源计算框架。它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。
12、Ambari管理工具
- Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeepr、Sqoop和Hcatalog等的集中管理,它也是5个顶级Hadoop管理工具之一。
13、Avro™序列化系统
- 数据序列化工具Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点:支持二进制序列化方式,可以便捷快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
14、Cassandra数据库系统
- Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身,Facebook于2008将 Cassandra 开源。
15、Chukwa数据收集系统
- Chukwa 是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在 Hadoop 的 HDFS 和MapReduce框架之上的,继承了Hadoop 的可伸缩性和健壮性。Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
16、Pig数据流系统
- Pig是基于Hadoop的数据流系统,由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具。定义了一种数据流语言—Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
17、Kafka消息系统
- Apache Kafka是一个开源流处理平台,它的目标是为处理实时数据提供一个统一、高通量、低等待的平台。Apache Kafka最初由LinkedIn开发,并于2011年初开源。2012年10月从ApacheIncubator毕业。在非常多的实时大数据项目中,都能见到Apache Kafka的身影。
| 应用场景 | 简单说明 |
|---|---|
| 发布和订阅 | 类似一个消息系统,可以读写流式数据 |
| 流数据处理 | 编写可扩展的流处理应用程序,可用于实时事件响应的场景 |
| 数据存储 | 安全地将流式的数据存储在一个分布式、有副本备份且容错的集群 |
- Kafka的一个重要特点是可以作为连接各个子系统的数据管道,从而构建实时的数据管道和流式应用。它支持水平扩展,且具有高可用、速度快的优点,已经运行在成千上万家公司的生产环境中。
- Apache Kafka的官网地址:http://kafka.apache.org
18、Oozie作业流调度引擎
- 作业流调度引擎Oozie是一个基于工作流引擎的服务器,可以在上面运行Hadoop的Map Reduce和Pig任务。它其实就是一个运行在Java Servlet容器(比如Tomcat)中的Javas Web应用。
19、Storm流处理框架
- Apache Storm是开源的分布式实时计算系统,擅长处理海量数据,适用于数据实时处理而非批处理。Hadoop或者Hive是大数据中进行批处理使用较为广泛的工具,这也是Hadoop或者Hive的强项。但是Hadoop MapReduce并不擅长实时计算,这也是业界一致的共识。当前很多业务对于实时计算的需求越来越强烈,这也是Storm推出的一个重要原因。
- Apache Storm的官网地址:http://storm.apache.org
- 注意:随着Spark和Flink对于流数据的处理能力的增强,目前不少实时大数据处理分析都从Storm迁移到Spark和Flink上,从而降低了维护成本。
20、Flink实时处理框架
- Apache Flink是一个计算框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算,该框架完全由Java语言开发,也是国内阿里巴巴主推的一款大数据工具。其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API,以便用户编写分布式任务。
| API | 作用 |
|---|---|
| DataSet API | 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符,对分布式数据集进行处理。 |
| DataStream API | 对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作。 |
| Table API | 对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的语句对关系表进行各种查询操作。 |
- Apache Flink的官网地址:http://flink.apache.org
21、Apache Phoenix
- Hive是构建在Hadoop之上,可以用SQL对Hadoop中的数据进行查询和统计分析。同样地,HBase原生也不支持用SQL进行数据查询,因此使用起来不方便,比较费力。
- Apache Phoenix是构建在HBase数据库之上的一个SQL翻译层。它本身用Java语言开发,可作为HBase内嵌的JDBC驱动。Apache Phoenix引擎会将SQL语句翻译为一个或多个HBase扫描任务,并编排执行以生成标准的JDBC结果集。
- Apache Phoenix提供了用SQL对HBase数据库进行查询操作的能力,并支持标准SQL中大部分特性,其中包括条件运算、分组、分页等语法,因此降低了开发人员操作HBase当中的数据的难度,提高了开发效率。
- 官网地址:http://phoenix.apache.org
22、Apache Drill
- Apache Drill是一个开源的、低延迟的分布式海量数据查询引擎,使用ANSI SQL兼容语法,支持本地文件、HDFS、HBase、MongoDB等后端存储,支持Parquet、JSON和CSV等数据格式。本质上Apache Drill是一个分布式的大规模并行处理查询层。
- 它是Google Dremel工具的开源实现,而Dremel是Google的交互式数据分析系统,性能非常强悍,可以处理PB级别的数据。
- Google开发的Dremel工具,在处理PB级数据时,可将处理时间缩短到秒级,从而作为MapReduce的有力补充。它作为Google BigQuery的报表引擎,获得了很大的成功。
- Apache Drill的官网地址:https://drill.apache.org
23、Apache Hudi
- Apache Hudi代表Hadoop Upserts and Incrementals,由Uber开发并开源。它基于HDFS数据存储系统之上,提供了两种流原语:插入更新和增量拉取。它可以很好地弥补Hadoop和Hive对部分数据更新的不足。
- Apache Hudi工具提供两个核心功能:首先支持行级别的数据更新,这样可以迅速地更新历史数据;其次是仅对增量数据的查询。Apache Hudi提供了对Hive、Presto和Spark的支持,可以直接使用这些组件对Hudi管理的数据进行查询。
- Hudi的主要目的是高效减少数据摄取过程中的延迟;HDFS上的分析数据集通过两种类型的表提供服务
| 服务 | 说明 |
|---|---|
| 读优化表(Read Optimized Table) | 通过列式存储提高查询性能 |
| 近实时表(Near-Real-Time Table) | 基于行的存储和列式存储的组合提供近实时查询 |
- Hudi的官网地址:https://hudi.apache.org
24、Apache Kylin
- Apache Kylin是数据平台上的一个开源OLAP引擎。它采用多维立方体预计算技术,可以将某些场景下的大数据SQL查询速度提升到亚秒级别。值得一提的是,Apache Kylin是国人主导的第一个Apache顶级开源项目,在开源社区有较大的影响力。
- 它的查询速度如此之快,是基于预先计算尽量多的聚合结果,在查询时应该尽量利用预先计算的结果得出查询结果,从而避免直接扫描超大的原始记录。
- 使用Apache Kylin主要分为三步
| 步骤 | 工作 |
|---|---|
| 1 | 定义数据集上的一个星形或雪花形模型 |
| 2 | 在定义的数据表上构建多维立方 |
| 3 | 使用SQL进行查询 |
- Apache Kylin的官网地址:http://kylin.apache.org
25、Apache Presto
- Apache Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。它的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
- Presto支持多种数据存储系统,包括Hive、Cassandra和各类关系数据库。Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
- 国内的京东和国外的Facebook都使用Presto进行交互式查询。
- Apache Presto的官网地址:https://prestodb.io
26、ClickHouse
- Yandex在2016年6月15日开源了一个用于数据分析的数据库,名字叫作ClickHouse,这个列式存储数据库的性能要超过很多流行的商业MPP数据库软件,例如Vertica。目前国内社区火热,各个大厂纷纷使用。
- 今日头条用ClickHouse做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。腾讯用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程从2018年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。快手也在使用ClickHouse,每天新增200TB,90%查询低于3秒。
- ClickHouse的官网地址:https://clickhouse.tech
27、Apache Druid
- Apache Druid是一个分布式的、支持实时多维OLAP分析的数据处理系统。它既支持高速的数据实时摄入处理,也支持实时且灵活的多维数据分析查询。因此它最常用的大数据场景就是灵活快速的多维OLAP分析。
- 另外,它支持根据时间戳对数据进行预聚合摄入和聚合分析,因此也经常用于对时序数据进行处理分析。
| 编号 | 特性 |
|---|---|
| 1 | 亚秒响应的交互式查询,支持较高并发 |
| 2 | 支持实时导入,导入即可被查询,支持高并发导入 |
| 3 | 采用分布式shared-nothing的架构,可以扩展到PB级 |
| 4 | 数据查询支持SQL |
- Apache Druid的官网地址:http://druid.apache.org
- 注意:目前Apache Druid不支持精确去重,不支持Join和根据主键进行单条记录更新。同时,需要与阿里开源的Druid数据库连接池区别开来。
28、TensorFlow
- TensorFlow最初由谷歌公司开发,用于机器学习和深度神经网络方面的研究,它是一个端到端开源机器学习平台。它拥有一个全面而灵活的生态系统,包含各种工具、库和社区资源,可助力研究人员推动先进的机器学习技术的发展,并使开发者能够轻松地构建和部署由机器学习提供支持的应用。
| 特征 | 说明 |
|---|---|
| 轻松地构建模型 | 它可以使用API轻松地构建和训练机器学习模型,这使得我们能够快速迭代模型并轻松地调试模型。 |
| 随时随地进行可靠的机器学习生产 | 它可以在CPU和GPU上运行,可以运行在台式机、服务器和手机移动端等设备上。无论使用哪种语言,都可以在云端、本地、浏览器中或设备上轻松地训练和部署模型。 |
| 强大的研究实验 | 现在科学家可以用它尝试新的算法,产品团队则用它来训练和使用计算模型,并直接提供给在线用户。 |
- TensorFlow的官网地址:https://tensorflow.google.cn
29、PyTorch
- PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且还提供了Python接口。
- 它是一个以Python优先的深度学习框架,能够实现强大的GPU加速,同时还支持动态神经网络,这是很多主流深度学习框架比如TensorFlow等都不支持的。
- PyTorch是相当简洁且高效的框架,从操作上来说,非常符合我们的使用习惯,这能让用户尽可能地专注于实现自己的想法,而不是算法本身。PyTorch是基于Python的,因此入门也更加简单。
- PyTorch的官网地址:https://pytorch.org
30、Apache Superset
- 前面介绍的大数据工具,主要涉及大数据的存储、计算和查询,也涉及大数据的机器学习。但是这些数据的查询和挖掘结果如何直观地通过图表展现到UI上,以辅助更多的业务人员进行决策使用,这也是一个非常重要的课题。
- 没有可视化工具,再好的数据分析也不完美,可以说,数据可视化是大数据的最后一公里,因此至关重要。
- Apache Superset是由Airbnb开源的数据可视化工具,目前属于Apache孵化器项目,主要用于数据可视化工作。分析人员可以不用直接写SQL语句,而是通过选择指标、分组条件和过滤条件,即可绘制图表,这无疑降低了它的使用难度。它在可视化方面做得很出色,是开源领域中的佼佼者,即使与很多商用的数据分析工具相比,也毫不逊色。
- Apache Superset的官网地址:http://superset.apache.org
31、Elasticsearch
- Elasticsearch是一个开源的、分布式的、提供Restful API的搜索和数据分析引擎,它的底层是开源库Apache Lucene。它使用Java编写,内部采用Lucene做索引与搜索。它的目标是使全文检索变得更加简单。
- Elasticsearch具有如下特征:一个分布式的实时文档存储;一个分布式实时分析搜索引擎;能横向扩展,支持PB级别的数据。
- 由于Elasticsearch的功能强大和使用简单,维基百科、卫报、Stack Overflow、GitHub等都纷纷采用它来做搜索。现在,Elasticsearch已成为全文搜索领域的主流软件之一。
- Elasticsearch的官网地址:https://www.elastic.co/cn
32、Jupyter Notebook
- Jupyter Notebook是一个功能非常强大的Web工具,不仅仅用于大数据分析。它的前身是IPython Notebook,是一个基于Web的交互式笔记本,支持40多种编程语言。
- 它的本质是一个Web应用程序,便于创建和共享程序文档,支持实时代码、数学方程、可视化和Markdown。它主要用于数据清理和转换、数值模拟、统计建模、机器学习等。
- JupyterNotebook的官网地址:https://jupyter.org

33、Apache Zeppelin
- Apache Zeppelin和Jupyter Notebook类似,是一个提供交互式数据分析且基于Web的笔记本。它基于Web的开源框架,使交互式数据分析变得可行的。Zeppelin提供了数据分析、数据可视化等功能。
- 借助Apache Zeppelin,开发人员可以构建数据驱动的、可交互且可协作的精美的在线文档,并且支持多种语言,包括Apache Spark、PySpark、Spark SQL、Hive、Markdown、Shell等。
- Apache Zeppelin主要功能有:数据提取、数据挖掘、数据分析、数据可视化展示
- Apache Zeppelin的官网地址:http://zeppelin.apache.org
- 大数据工具发展非常快,有很多工具可能都没有听说过。就当前的行情来看,Apache Spark基本上已经成为批处理领域的佼佼者,且最新版本在流处理上也做得不错,是实现流批一体化数据处理很好的框架。
- 需要大数据分析与处理的公司,应该根据自身的人员技能结构和业务需求,选择合适的大数据工具。虽然大数据工具非常之多,但是Hadoop、HBase、Kafka、Spark或Flink几乎是必备的大数据工具。
(四)Hadoop的版本情况
1、Hadoop发行版
- Hadoop发行版本分为开源社区版和商业版。社区版是指由Apache软件基金会维护的版本,是官方维护的版本体系。商业版Hadoop是指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本。

(1)Apache Hadoop
- 官网链接:https://hadoop.apache.org

(2)Cloudera Hadoop
- 官网链接:https://www.cloudera.com/downloads/cdh

(3)Hortonworks Hadoop
- 2018年10月,均为开源平台的Cloudera与Hortonworks公司宣布他们以52亿美元的价格合并。如今就没有Hortonworks Hadoop的官网链接了。
2、Hadoop版本升级
- Hadoop自诞生以来,主要分为Hadoop1、Hadoop2、Hadoop3三个系列的多个版本,目前市场上最主流的是Hadoop2.x版本。Hadoop2.x版本指的是第2代Hadoop,它是从Hadoop1.x发展而来的,并且相对于Hadoop1.x来说,有很多改进。Hadoop1.x内核主要由分布式存储系统HDFS和分布式计算框架MapReduce两个系统组成,而Hadoop2.x版本主要新增了资源管理框架Yarn以及其他工作机制的改变。
(1)Hadoop1.x
- Hadoop1.x时期架构

(2)Hadoop2.x
- Hadoop2.x时期架构
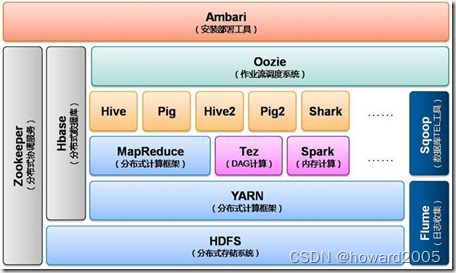
(3)Hadoop3.x
- Hadoop3.x是基于JDK1.8开发的,较其他两个版本而言,在功能和优化方面发生了很大的变化,其中包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化等。
- 据Apache hadoop 的最新消息,Hadoop3.x将会调整方案架构,将Mapreduce 基于内存+IO+磁盘,共同处理数据。其中,在Hadoop3.x中改变最大的是HDFS,它通过最近Block块进行计算,根据最近计算原则,将本地Block块加入到内存,先计算,然后通过IO,共享内存计算区域,最后快速形成计算结果,其计算速度比Spark快10倍。
三、归纳总结
- 回顾本节课所讲的内容,并通过提问的方式引导学生解答问题并给予指导。
四、上机操作
- 形式:单独完成
- 题目:掌握Hadoop的生态体系与版本情况
- 要求:根据讲课笔记给出的提纲,上网收集资料,对于Hadoop的前世今生与生态体系有更深入的了解,并利用XMind绘制思维导图。