sentinel是一个流量控制、熔断降级的组件,可以替换第一代中的hystrix。 hystrix用起来没有那么方便:
1、要在调用方引入hystrix,没有ui界面进行配置,需要在代码中进行配置,侵入了业务代码。
2、还要自己搭建监控平台dashboard。
而sentinel就很方便,在微服务引入依赖就可以。 对于控制台,下载jar包启动运行即可。
下载地址:https://github.com/alibaba/Sentinel/releases
启动:jar -jar sentinel-dashboard-1.7.1.jar &
访问:ip:端口/#/dashboard/home
基本使用:
微服务引入sentinel依赖:
<!-- Sentinel支持采用 Nacos 作为规则配置数据源,引入该适配依赖 --> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency>yml配置:
server: port: 8098 spring: application: name: lagou-service-autodeliver cloud: nacos: discovery: server-addr: 127.0.0.1:8848,127.0.0.1:8849,127.0.0.1:8850 sentinel: transport: dashboard: 127.0.0.1:8080 # sentinel dashboard/console 地址 port: 8719 # sentinel会在该端口启动http server,那么这样的话,控制台定义的一些限流等规则才能发送传递过来, #如果8719端口被占用,那么会依次+1 management: endpoints: web: exposure: include: "*" # 暴露健康接口的细节 endpoint: health: show-details: always #针对的被调用方微服务名称,不加就是全局生效 lagou-service-resume: ribbon: #请求连接超时时间 ConnectTimeout: 2000 #请求处理超时时间 ##########################################Feign超时时长设置 ReadTimeout: 3000 #对所有操作都进行重试 OkToRetryOnAllOperations: true ####根据如上配置,当访问到故障请求的时候,它会再尝试访问一次当前实例(次数由MaxAutoRetries配置), ####如果不行,就换一个实例进行访问,如果还不行,再换一次实例访问(更换次数由MaxAutoRetriesNextServer配置), ####如果依然不行,返回失败信息。 MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第一次调用 MaxAutoRetriesNextServer: 0 #切换实例的重试次数 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整 logging: level: # Feign日志只会对日志级别为debug的做出响应 com.lagou.edu.controller.service.ResumeServiceFeignClient: debug微服务启动后,就可以在控制台查看监控情况。
sentinel流量控制:
在sentinel后台进行配置。
- 资源名:默认请求路径
- 针对来源:填写微服务名称,默认default(不区分来源)
- 阈值类型/单机阈值:
- QPS:每秒钟请求数量。
- 线程数:线程处理请求的时候, 如果说业务逻辑执⾏时间很⻓,流量洪峰来临时,会耗费很多线程资源,最终可能服务雪崩。
- 是否集群:是否集群限流
- 流控模式:
- 直接:资源调⽤达到限流条件时,直接限流
- 关联:关联的资源调⽤达到阈值时候限流⾃⼰ 。⽐如⽤户注册接⼝,需要调⽤身份证校验接⼝,如果身份证校验接⼝请求达到阈值,可以对⽤户注册接⼝进⾏限流。
- 链路:只记录指定链路上的流量。 比如两条链路都调用了nodeA,可以配置只限制某条链路的请求。
- 流控效果:
- 快速失败:直接失败,抛出异常
- Warm Up:根据冷加载因⼦(默认3)的值,从阈值/冷加载因⼦,经过预热时⻓, 才达到设置的QPS阈值。 这样可以防止突然暴增导致服务不可用,比如秒杀。
- 排队等待:匀速排队,让请求匀速通过,阈值类型必须设置为QPS,否则⽆效。
例如, QPS 配置为 5 ,则代表请求每 200 ms 才能通过⼀个,多出的请求将排队等待通过。超时时间代表最⼤排队时间,超出最⼤排队时间的请求将会直接被拒绝。排队等待模式下, QPS 设置值不要超过 1000 (请求间隔 1 ms )。

sentinel服务降级:
Sentinel 降级在调用某个资源出现不稳定状态时(例如调⽤超时或异常⽐例升⾼),对这个资源的调⽤进⾏限制,让请求快速失败,避免影响到其它的资源⽽导致级联错误。当资源被降级后,在接下来的降级时间窗⼝之内,对该资源的调⽤都⾃动熔断。
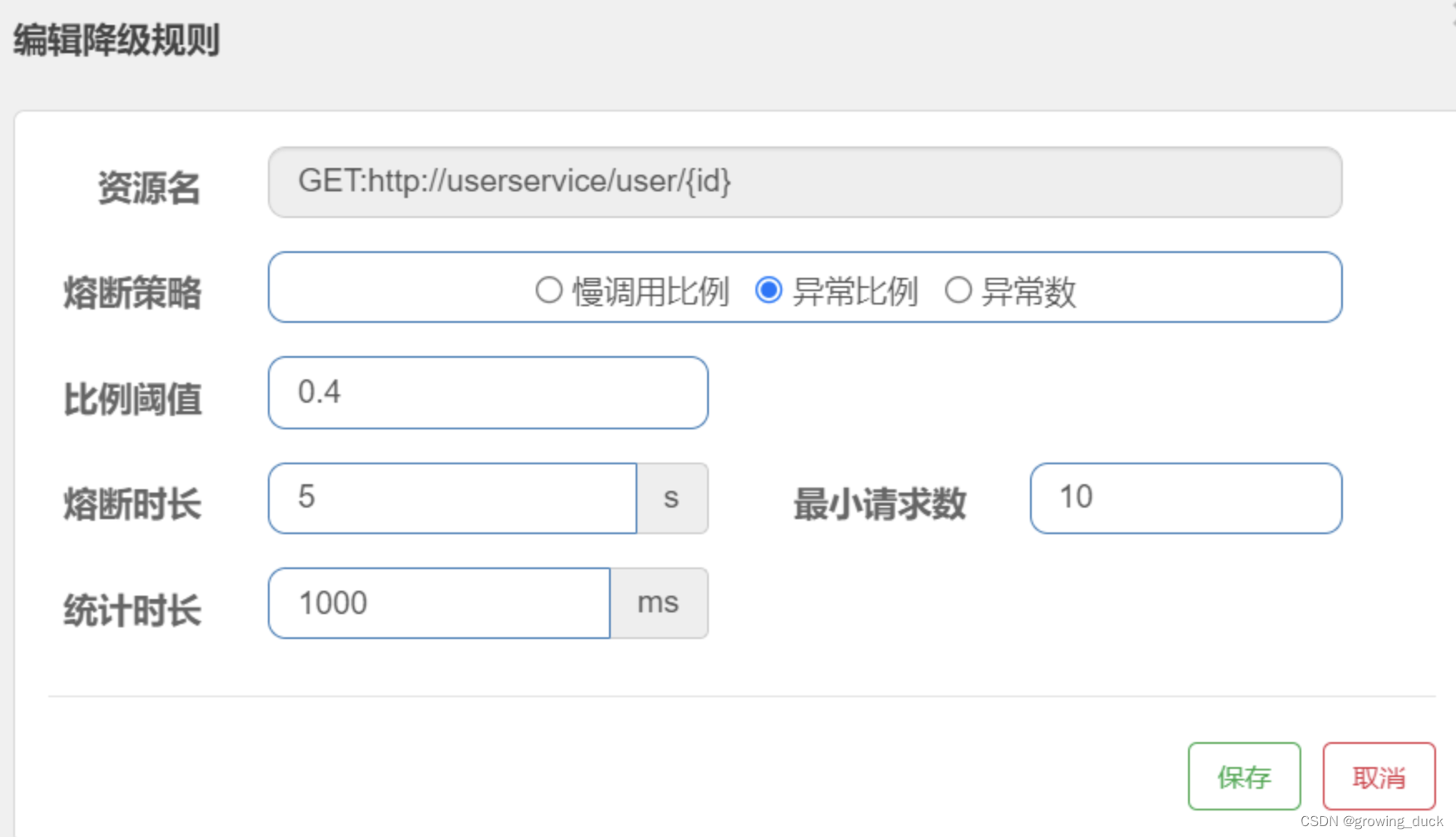
另外,sentinel不会像hystrix,在时间窗内对每一次请求都尝试自我修复,而是明确在时间窗后才恢复。 它的熔断策略是:
- RT(平均响应时间):
- RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,且慢调用比例>=0.5,则触发熔断,熔断时长为5秒。
- 异常比例:
- 异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断

自定义兜底逻辑:
以上的配置,发生降级后,会抛出降级的相关异常。 可以自定义兜底逻辑。
@GetMapping("/checkState/{userId}") @SentinelResource(value = "findResumeOpenState",blockHandlerClass = SentinelHandlersClass.class, blockHandler = "handleException",fallbackClass = SentinelHandlersClass.class,fallback = "handleError") public Integer findResumeOpenState(@PathVariable Long userId) { return resumeService.findDefaultResumeByUserId(userId); }如上,使用@SentinelResource来指定。
value:指定资源,用方法名。 blockHandlerClass:指定sentinel规则异常后,兜底逻辑所在的类。 blockHandler:指定sentinel规则异常后,兜底逻辑所在的方法。以上的配置是针对抛出sentinel异常,可能在代码中还会抛出java异常,所以还可以定义异常的降级方法。
fallbackClass:指定java异常后,兜底逻辑所在的类。 fallback:指定java异常后,兜底逻辑所在的方法。兜底方法:
public class SentinelHandlersClass { // 整体要求和当时Hystrix一样,这里还需要在形参最后添加BlockException参数,用于接收异常 // 注意:方法是静态的 public static Integer handleException(Long userId, BlockException blockException) { return -100; } public static Integer handleError(Long userId) { return -500; } }
基于 Nacos 实现 Sentinel 规则持久化:
在dashboard后台配置的规则,都是在内存中。 如果微服务停掉就会消失,所以,生产环境下,可以持久化到nacos配置中心,让微服务从nacos获取规则。
- 微服务引入依赖:
<!-- Sentinel支持采用 Nacos 作为规则配置数据源,引入该适配依赖 --> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency>
- 在yml中配置nacos数据源(sentinel下的datasource)
server: port: 8098 spring: application: name: lagou-service-autodeliver cloud: nacos: discovery: server-addr: 127.0.0.1:8848,127.0.0.1:8849,127.0.0.1:8850 sentinel: transport: dashboard: 127.0.0.1:8080 # sentinel dashboard/console 地址 port: 8719 # sentinel会在该端口启动http server,那么这样的话,控制台定义的一些限流等规则才能发送传递过来, #如果8719端口被占用,那么会依次+1 # Sentinel Nacos数据源配置,Nacos中的规则会自动同步到sentinel流控规则中 datasource: # 数据源自己取名,这里定义了两个:flow和degrade,代表流控和降级 # 自定义的流控规则数据源名称 flow: nacos: #类型要指定为nacos,因为sentinel还可以持久化到其他类型中 server-addr: ${spring.cloud.nacos.discovery.server-addr} data-id: ${spring.application.name}-flow-rules groupId: DEFAULT_GROUP data-type: json rule-type: flow # 类型来自RuleType类 # 自定义的降级规则数据源名称 degrade: nacos: server-addr: ${spring.cloud.nacos.discovery.server-addr} data-id: ${spring.application.name}-degrade-rules groupId: DEFAULT_GROUP data-type: json rule-type: degrade # 类型来自RuleType类 management: endpoints: web: exposure: include: "*" # 暴露健康接口的细节 endpoint: health: show-details: always #针对的被调用方微服务名称,不加就是全局生效 lagou-service-resume: ribbon: #请求连接超时时间 ConnectTimeout: 2000 #请求处理超时时间 ##########################################Feign超时时长设置 ReadTimeout: 3000 #对所有操作都进行重试 OkToRetryOnAllOperations: true ####根据如上配置,当访问到故障请求的时候,它会再尝试访问一次当前实例(次数由MaxAutoRetries配置), ####如果不行,就换一个实例进行访问,如果还不行,再换一次实例访问(更换次数由MaxAutoRetriesNextServer配置), ####如果依然不行,返回失败信息。 MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第一次调用 MaxAutoRetriesNextServer: 0 #切换实例的重试次数 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #负载策略调整 logging: level: # Feign日志只会对日志级别为debug的做出响应 com.lagou.edu.controller.service.ResumeServiceFeignClient: debug- 配置文件中指定好dataid后,就需要去nacos配置管理中配置了(注意:命名空间,分组,dataid等要和yml中对应上),
- 流控规则:
[ { "resource":"findResumeOpenState", "limitApp":"default", "grade":1, "count":1, "strategy":0, "controlBehavior":0, "clusterMode":false } ]所有属性来⾃源码FlowRule类
- resource:资源名称
- limitApp:来源应⽤
- grade:阈值类型 0 线程数 1 QPS
- count:单机阈值
- strategy:流控模式,0 直接 1 关联 2 链路
- controlBehavior:流控效果,0 快速失败 1 Warm Up 2 排队等待
- clusterMode:true/false 是否集群
- 降级规则
[ { "resource":"findResumeOpenState", "grade":2, "count":1, "timeWindow":5 } ]