📘End-to-End Unsupervised Deformable ImageRegistration with a Convolutional NeuralNetwork
📕《基于卷积神经的端到端无监督变形图像配准》
文章目录
- 摘要 Abstract.
- 1.导言 Introduction
- 附录 References
- 未完待续 to be continued ...
摘要 Abstract.
-
📘 In this work we propose a deep learning network for deformable image registration(DIRNet).
-
📕 本文提出了一种可变形图像配准的深度学习网络(DIRNet)
-
📘The DIRNet consists of a convolutional neural network(ConvNet) regressor, a spatial transformer, and a resampler.
-
📕 该网络由一个卷积神经网络(ConvNet)回归器、一个空间转换器和一个重放器组成。
-
📘 The ConvNet analyzes a pair of fixed and moving images and outputs parameters for the spatial transformer,
-
📕 ConvNet分析一对固定的和运动的图像,并输出空间转换器的参数,
-
📘which generates the displacement vector field that enables the resampler to warp the moving image to the fixed image.
-
📕 从而生成位移矢量场,使重放器(重新采样)能够将运动图像扭曲成固定图像。
-
📘The DIRNet is trained end-to-end by [1] unsupervised optimization of a [2] similarity metric between input image pairs.
-
📕 DIRNet是通过对输入图像对之间的==[2] 相似性度量进行[1] 无监督优化==来进行端到端训练的。
-
📘A trained DIRNet can be applied to perform registration on unseen image pairs in one pass,thus non-iteratively.
-
📕 经过训练的DIRNet可以应用于一次对看不见的图像对执行配准,因此不可迭代。
-
📘 Evaluation was performed with registration of images of handwritten digits (MNIST) and cardiac cine MR scans (Sunnybrook Cardiac Data).
-
📕 通过登记手写数字图像(MNIST)和心脏电影(片子) MR扫描(Sunnybrook心脏数据)进行评估。
-
📘The results demonstrate that registration with DIRNet is as accurate as a conventional deformable image registration method with substantially shorter execution times.
-
📕 结果表明,使用DIRNet的配准与传统的可变形图像配准方法一样准确,执行时间更短。
1.导言 Introduction
-
🌲 Image registration is a fundamental step in many clinical image analysis tasks.
-
⭐️ 图像配准是许多临床图像分析任务中的基本步骤。
-
🌲 Traditionally, image registration is performed by exploiting intensity information between pairs of fixed and moving images.
-
⭐️ 传统上,图像配准是通过利用固定图像和运动图像对之间的强度信息来执行的。
-
🌲 Since recently, deep learning approaches are used to aid image registration.
-
⭐️ 最近,深度学习方法被用来帮助图像配准。
-
🌲 Wu et al.[11] used a convolutional stacked auto-encoder (CAE) to extract features from fixed and moving images that are subsequently used in conventional deformable image registration algorithms.
-
⭐️ Wu等人[11]使用卷积堆叠自动编码器(CAE)从固定图像和运动图像中提取特征,这些特征随后用于传统的可变形图像配准算法。
-
🌲 However, the CAE is decoupled from the image registration task and hence, it does not necessarily extract the features most descriptive for image registration.
-
⭐️ 然而,CAE与图像配准任务是解耦的,因此,它不一定提取对图像配准最具描述性的特征。
-
🌲 The training of the CAE was unsupervised, but the registration task was not learned end-to-end.
-
⭐️ CAE的训练是无监督的,但注册任务不是端到端学习的。
-
🌲 On the contrary, Miao et al.[8] and Liao et al.[6]have used deep learning to learn rigid registration end-to-end.
-
⭐️ 相反,Miao等人[8]和Liao等人[6]使用深度学习来端到端地学习刚性注册。
-
🌲 Miao et al.[8] used a convolutional neural network (ConvNet)regressor to predict a transformation matrix for rigid registration of synthetic 2D to 3D images.
-
⭐️ Miao等人[8]使用卷积神经网络(ConvNet)回归器来预测用于合成2D到3D图像的刚性配准的变换矩阵。
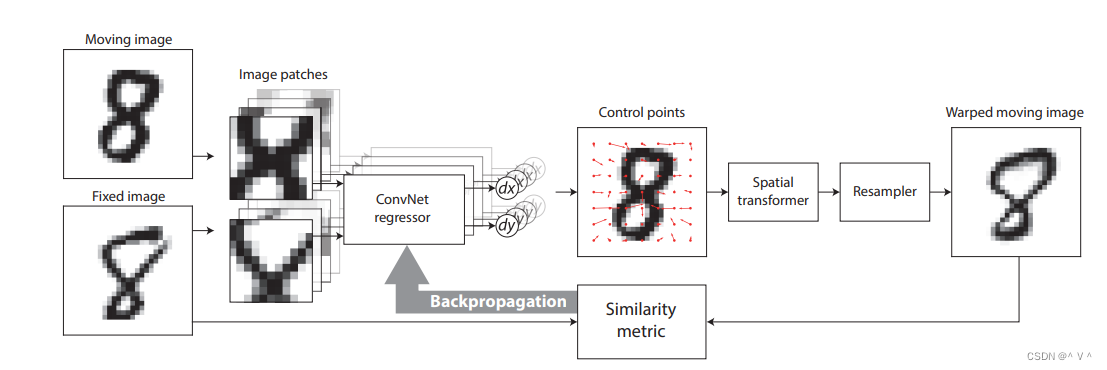
Fig. 1. Schematics of the DIRNet with two input images from the MNIST data. The DIRNet takes one or more pairs of moving and fixed images as its inputs. The fully convolutional ConvNet regressor analyzes spatially corresponding image patches from the moving and fixed images and generates a grid of control points for a B-spline transformer. The B-spline transformer generates a full displacement vector field to warp a moving image to a fixed image. Training of the DIRNet is unsupervised and end-to-end by backpropagating an image similarity metric as a loss.
图1。具有来自MNIST数据的两个输入图像的DIRNet示意图。DIRNet将一对或多对运动图像和固定图像作为其输入。全卷积ConvNet回归器分析来自运动图像和固定图像的空间上对应的图像块,并为B样条变换器生成控制点网格。B样条变换器生成一个完整的位移矢量场,将运动图像扭曲为固定图像。DIRNet的训练是无监督的和端到端的,通过将图像相似性度量作为损失进行反向传播。
附录 References
本文所有参考论文如下,如有侵权联系删除:
End-to-End Unsupervised Deformable Image Registration with a Convolutional Neural Network
*
Bob D. de Vos, Floris F. Berendsen, Max A. Viergever, Marius Staring and Ivana Iˇsgum
*
Image Sciences Institute, University Medical Center Utrecht, the Netherlands
2Division of Image Processing, Leiden University Medical Center, the Netherlands