夕小瑶科技说 原创
作者 | 卖萌酱
大家好,我是卖萌酱。
相信不少小伙伴这几天都听到了消息,在期待下周即将发布的文心大模型4.0。我们的几个读者群里也发生了相关的讨论:
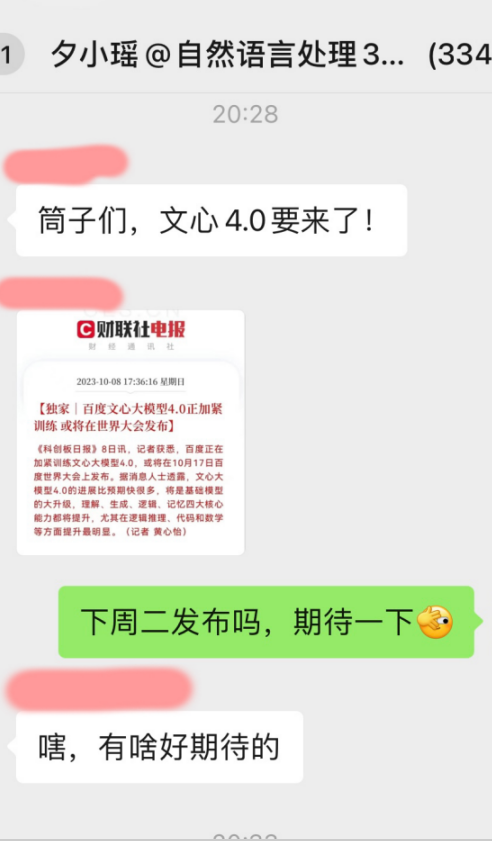
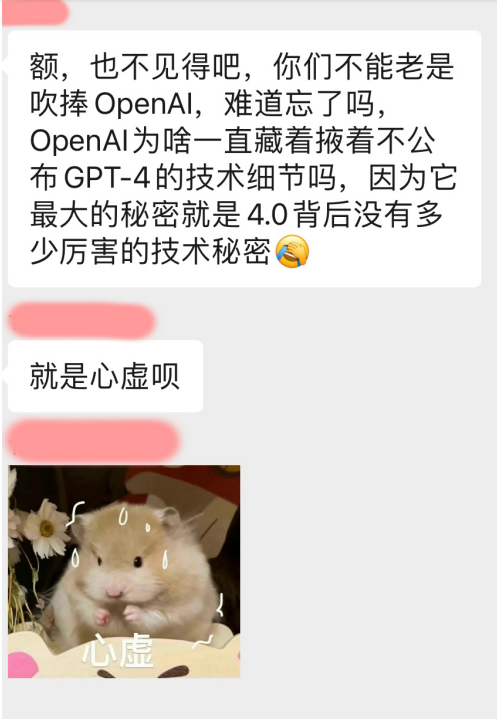

讨论的核心主要围绕以下两个话题展开:
-
文心4.0能不能打过GPT-4
-
文心4.0会不会收费
作为AI从业者,卖萌酱将基于目前得到的一些有限的消息,来展开一些分析和猜想,供读者们参考。
猜想一:文心4.0很可能成为首个能力真正对标GPT-4的国产大模型
在近期卖萌酱得到的众多消息中,“文心4.0的推理成本比文心3.5增加了8~10倍”这条消息是较为可靠的。众所周知,推理成本主要来自GPU机器的开销和运维成本等。
推理成本增加10倍,意味着GPU机器大概要翻10倍才能抗住相同的访问量。
而为啥要用10倍的GPU机器呢?显然,要么是GPU计算复杂度提升了10倍,要么是GPU空间复杂度提升了10倍。
而我们知道,当下Transformer已经成为业界事实上的模型结构了,在当下的时间节点,百度没有太多理由在模型规模还未达到性能上限的情况下就去魔改模型结构,而且专业的AI从业者也都了解数据&模型规模往往比模型结构更重要。
因此,模型结构不变,就意味着计算复杂度不会有太大变化,因此一定是GPU空间复杂度提升了10倍,也就是模型参数量大了10倍。
ps:在专业的AI从业者看来,以上推理显得有些多余
而坊间不少评测以及笔者自己的使用体验都能感知到,文心3.5的综合能力是在GPT-3.5之上的,预估有1750亿参数量。也就是说,文心4.0的参数量预计将达到1.75万亿规模,与坊间传闻1.8万亿参数量的GPT-4极为接近。
根据卖萌酱对百度上线标准的认知,既然文心3.5的发版超越了GPT-3.5,那么文心4.0的发版大概率也将至少打平GPT-4。
如果真的做到了,那可谓说是国产大模型技术自研的重要里程碑。要知道,GPT-4在语言理解、生成、推理、代码、准确性等方面目前都是业界公认的第一,国内还没有哪个大模型的体验能真正匹敌GPT-4,无论是开源还是闭源模型。
猜想二:文心4.0会成为Pro付费版本,但距离商业化还很远
卖萌酱从推理成本、行业规律、用户体验提升这三个维度做了分析,猜测文心4.0大概率会收费。如果免费开放文心4.0,表面上看是好事,但实际上,这对百度、行业还是用户来说,都不是一个好选择。
根据国外的一项研究"The Economics of Large Language Models",大模型初始的推理成本大约相当于训练成本的三分之一,但随着用户量的激增,推理成本可以轻松变成训练成本的9倍甚至更高。
另外,从行业规律来说,OpenAI的GPT-4、Anthropic的Claude2 Pro面向公众时均选择了收费(20美元/月)。Pro级别的LLM面向C端收费来覆盖高昂的推理成本,已成为了AI行业约定俗成的做法。
除了这两点外,大模型的付费还有助于构建起更高质量的数据飞轮,进而带动大模型效果的深入改善,有效提升用户体验,既造福用户,也有助于构建数据壁垒。这点怎么理解呢?
业内有个基本的共识——大模型训练的不能一味的追求数据量,还要注重数据质量。
大量的互联网公有数据和用户使用数据可以为大模型构建起来类人的“通用”能力。然而,大模型若想在长尾话题和复杂话题上获得进一步提升,就要想办法拿到更多稀缺、高质量的用户交互数据。
这些稀缺、高质量的数据从哪里来呢?
逻辑很简单:难以通过免费版文心一言满足的用户需求往往更难、更专业,例如写复杂代码、做复杂决策、做复杂数据分析、写专业文档、咨询专业问题等。而有这些高阶使用需求的人往往具备更高的学历,有更良好的语言表达和思维逻辑,能贡献更高质量的训练样本。
而更牛的用户与更牛的模型产出的更牛的对话,就是稀缺、高质量的数据。
这些更高质量的数据,会让文心4.0变得更牛,满足更多更牛的人的更难的对话需求,进而形成一个“牛模型->牛人->牛对话->更牛模型”的良性循环,大幅加快文心大模型能力的进化速度。
因此,从构建高质量数据飞轮的角度来说,文心4.0作为Pro版本收费也是一个合理的选择,既能覆盖夸张的推理成本,实现良性经营;又能更好的提升模型效果,带来更好的用户体验。
猜想三:引发行业格局巨变,“百模大战”将难以为继
据中国科学技术信息研究所发布的《中国人工智能大模型地图研究报告》显示,截至5月28日,国内10亿级参数规模以上基础大模型至少已发布79个。
这都10月份了,国内的大模型早已超过“一百”之数了。
ps:每天早上醒来打开手机看到“某某公司”发布了“某某大模型”,内心已经麻了
已经有很多业界人士注意到了“百模大战”这种现象似乎热闹过头了,每家公司要是都来搞个大模型只会带来社会资源的浪费 。其实国内根本不需要这么多的底层大模型,如果没有很深的技术壁垒,只是一味地跟风模仿来训练大模型,迟早会因性能差距过大被淘汰。
知乎上有位网友梳理一下近些年互联网发展的历史,借鉴一下其实不难预测,对于国内的底层大模型而言,最终必将是赢家通吃、几家巨头独大的局面。

在猜想二的结尾,笔者提到了在C端构建起高质量的数据飞轮将有效拉动模型效果的提升,大模型在这一点上跟搜索引擎的特点非常像。
而百度作为第一个即将同时构建起“普适数据飞轮”和“专业数据飞轮”的企业,有望将大模型的进化速度做到远远甩开行业竞品。
最终,行业的第一名拿到大头的高质量数据,第二名拿到少量数据,第三名拿到极少数据。而绝大部分的大模型厂商将因为没有可靠的数据飞轮而陷入“闭门造车”、“原地打转”的困境,最终效果远远的落后于头部,甚至打不过头部厂商随手开源的“小模型”,进而死掉。
百模大战,离谢幕不远了。