调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node上的 Pod。调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是集群控制面的一部分如果你真的希望或者有这方面的需求,kube-scheduler 在设计上是允许你自己写个调度组件并替换原有的 kube-scheduler。
在做调度决定时需要考虑的因素包括: 单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等。
默认策略可以参考: https://kubernetes.io/docs/reference/scheduling/policies/
调度框架: https://kubernetes.io/zh/docs/concepts/scheduling-eviction/schedulingframework/
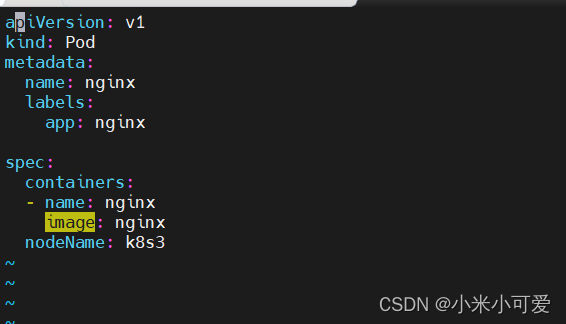
nodeName 是节点选择约束的最简单方法,但一般不推荐。如果 nodeName 在PodSpec 中指定了,则它优先于其他的节点选择方法。
使用 nodeName 来选择节点的一些限制:如果指定的节点不存在。
如果指定的节点没有资源来容纳 pod,则pod 调度失败云环境中的节点名称并非总是可预测或稳定的。
示例:
apiVersion: V1
kind: Pod
metadata
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: server3
===============
nodename

回收

#找不到节点pod会出现pending,优先级最高
==============
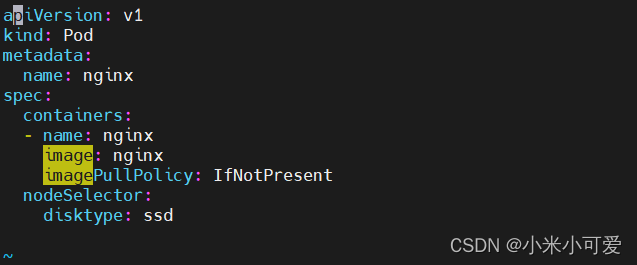
nodeselector
nodeSelector 是节点选择约束的最简单推荐形式。
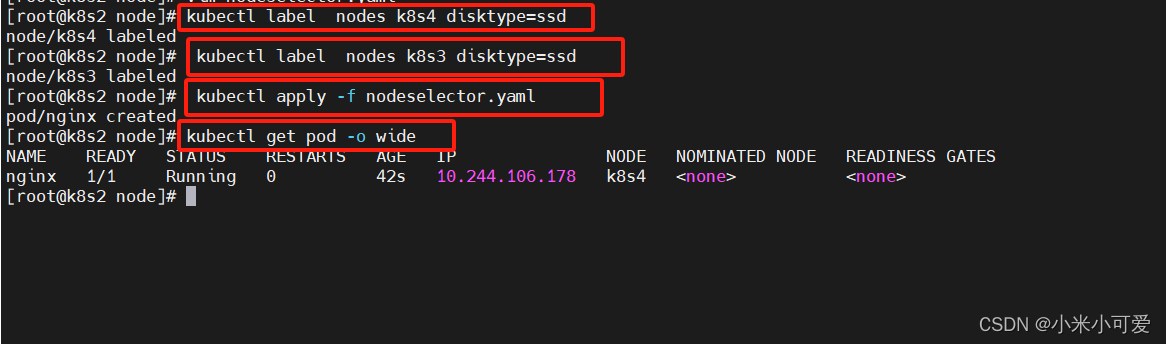
给选择的节点添加标签:kubectl label nodes server2 disktype=ssd

回收

亲和与反亲和
nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。你可以发现规则是“软”/“偏好”,而不是硬性要求,因此,如果调度器无法满足该要求,仍然调度该 pod你可以使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起
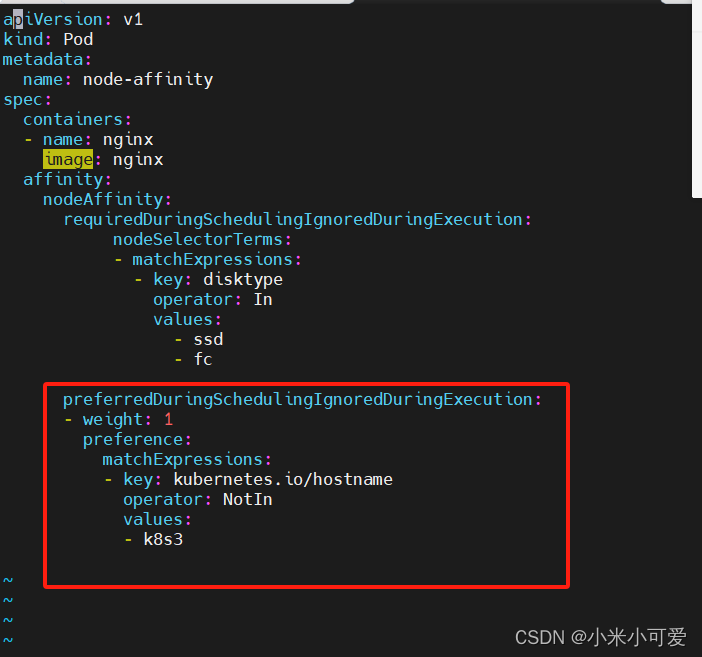
节点亲和
必须满足requiredDuringSchedulinglgnoredDuringExecutionpreferredDuringSchedulinglgnoredDuringExecution倾向满足
IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
参考:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign.pod-node/
倾向满足的意思:可以不满足 最好满足
nodeaffinity
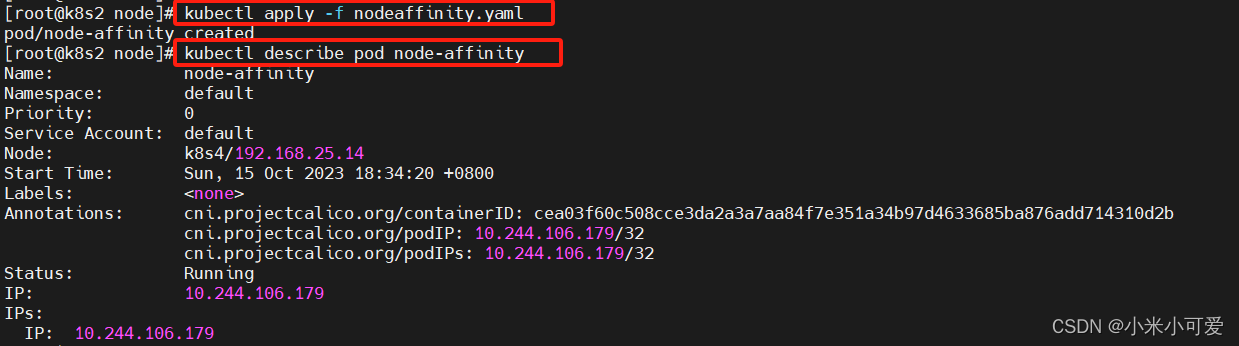

回收

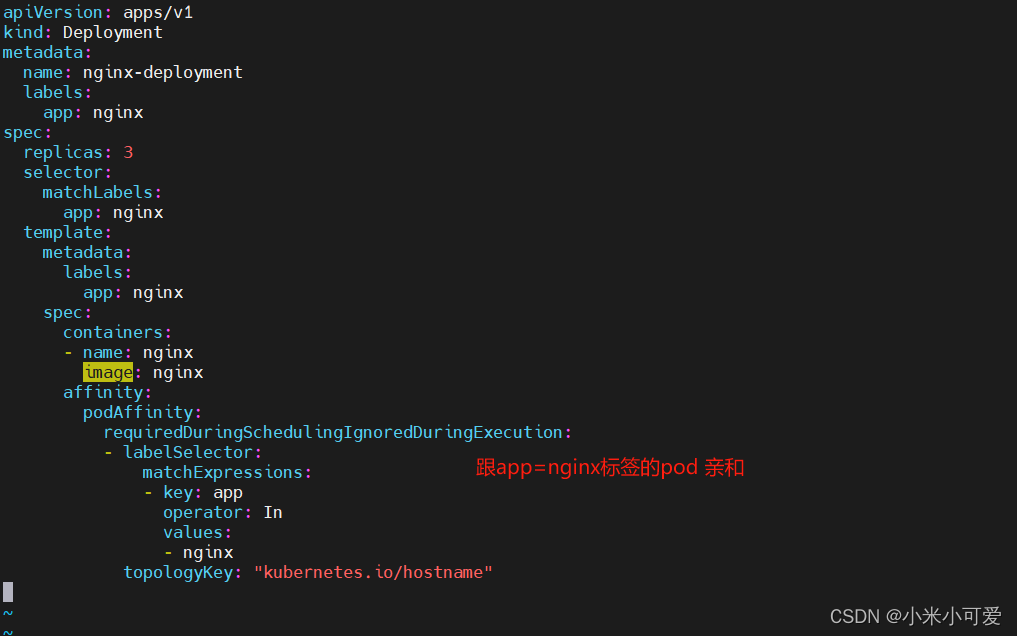
podaffinity

以上 是节点亲和性 主要是应该往哪个节点上调度
===========================
pod 亲和性讲的是 pod 与pod之间的关系
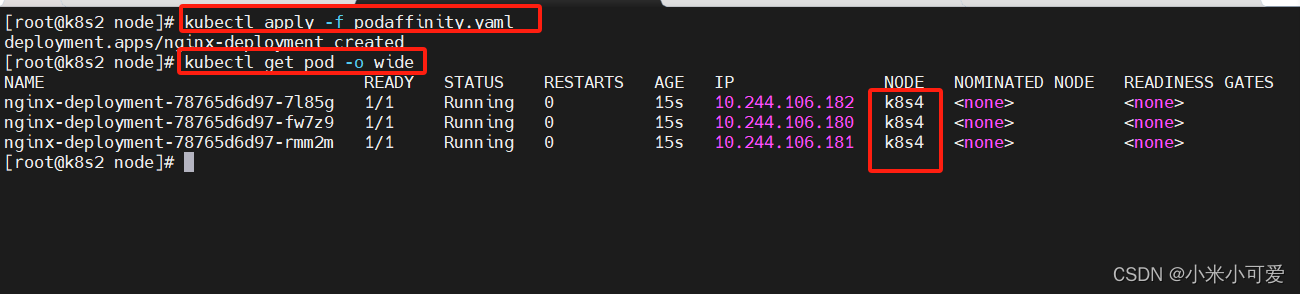
反亲和
podantiaffinity


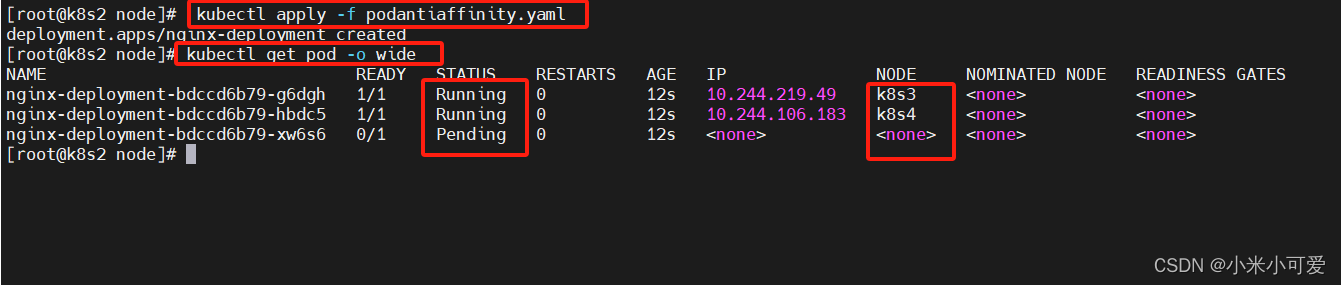
回收

Taints污点
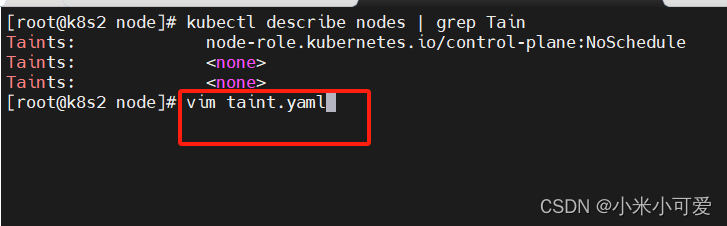


设置taint(污点)

如果这个节点已经被调度了 不会受影响

回收
=======================
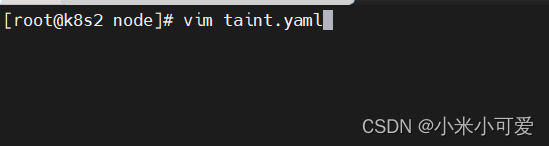
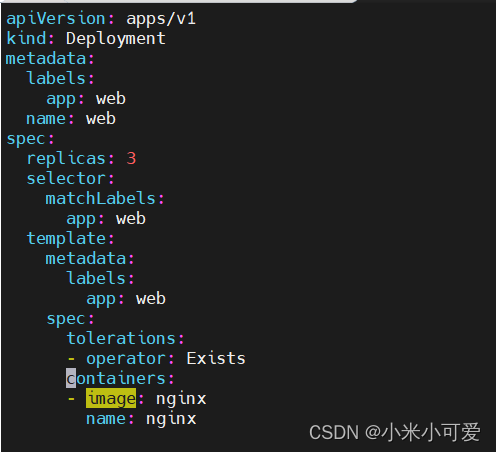
容忍
设置 tolerations


回收

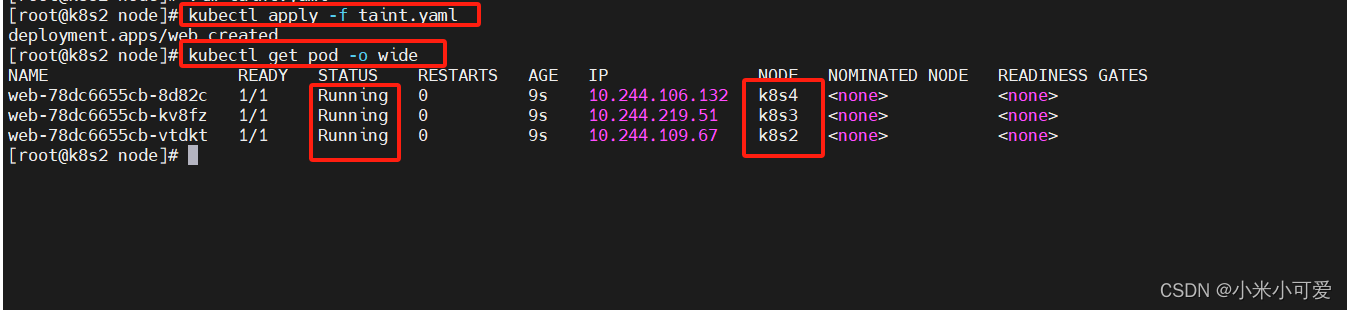
容忍所有taints

去除污点

cordon、drain、delete


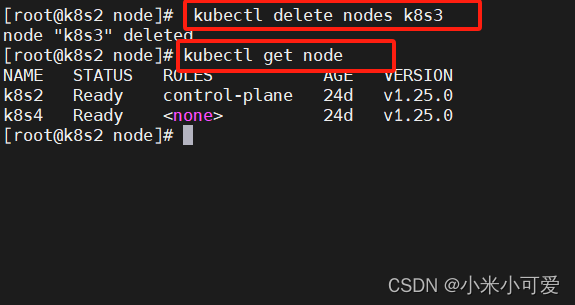
k8s3节点重启kubelet服务重新加入集群