超多目标优化的分类
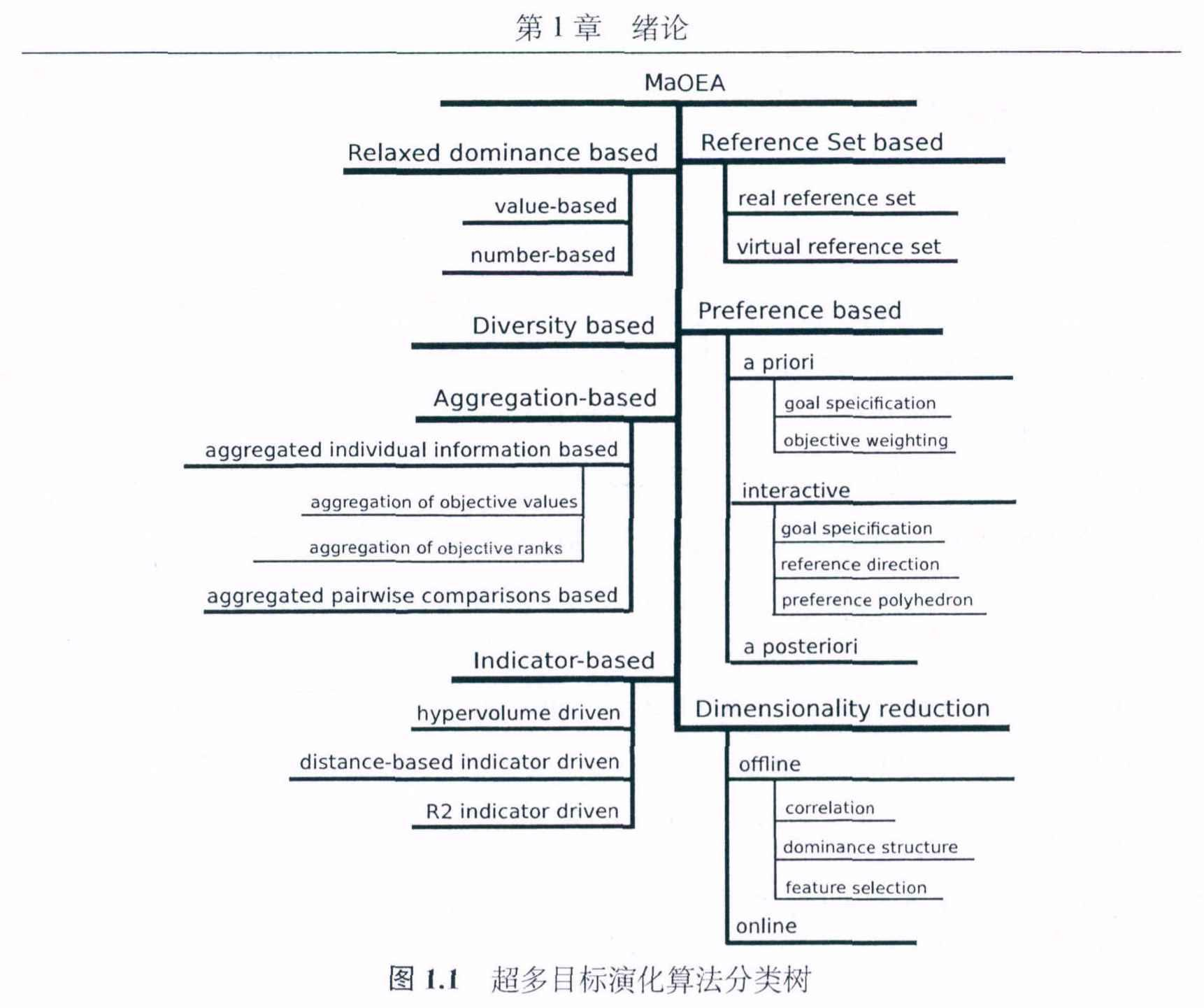
基于算法的核心思想,我们将超多目标演化方法分为以下几类:
基于松弛的支配定义的方法(Relaxed domainance )、试图通过放松传统的支配定义来提升算法的选择压力
基于多样性的方法(Diversity )、试图通过降低多样性维持机制的副作用来提升算法的性能
基于聚集的方法(Aggregation)、
基于评价指标的方法(Indicator)、 通过评价指标的数值来引导搜素过程,因为更好的指标数值通常意味着解集合是帕累托前沿的更好的逼近
基于参照点集的方法(Reference Set)、使用了一组参照点来评估非支配解的质量
基于偏好的方法(Perference):通过引入用户的偏好信息来引导算法的搜索方向
基于降维的方法(Dimensionality):试图减少超多目标演化算法的日标数量, 从而将原问题转化为另一个难度更低、目标数更少的问题。
超多目标优化的主要困难
当目标数量增加时,算法设计者不得不处理下面几个困难:
- 支配阻抗现象 (Dominance resistance (DR)phenomenon): 由于解集合中非支配解的占比急剧增加导致的解之间不可比较的情况【找到一个解在所有目标上都比另一个解好的可能性减小,因此解之间变得更加“不可比较”】。
- 有限的解集合大小:在非退化的情况下, 一个 m 目标问题的帕累托前沿是 一个(m- 1)- 维流形。然而,描述这一流形需要的解的个数随着目标数 m 指数型增长。
- 解集合在目标空间的可视化需要设计专门的技术:如映射到低维度空间, 平行坐标表示法等
传统的帕累托方法在处理超多目标优化问题时性能会急剧下降
已有研究结果显示,基于帕累托的方法,如第二代非支配排序遗传算法(Non- dominated Sorting Genetic Algorithm II, NSGA-II) 和改进版强度帕累托演化算法(the improved Strength Pareto Evolutionary Algorithm, SPEA2),在处理超多目标优化问题时性能会急剧下降。
产生这种结果的主要原因是支配阻抗问题和主动多样性提升机制 (Active Diversity Promotion(ADP) mechanisms):主动多样性提升机制指的是当基于支配关系的主要标准不能比较解的优劣时,基于多样性的次要标准将决定哪些解可以存活到下一轮。
因此,算法最终可能很难收敛到帕累托前沿,而分散于整个解空间。
解决方法:
直观上说,提升基于帕累托支配关系的算法在超多目标优化问题上的可扩展性有两种方法:基于松弛的支配关系的方法和基于多样性的方法。这两类方法分别针对支配阻抗现象和主动多样性提升机制对于算法进行改进。 一方面,为了减弱支配阻抗现象带来的负面影响,研究者们提出了一些帕累托支配的变种, 以提升朝向帕累托前沿的选择压力[47,48]。与传统的帕累托支配相比,这些变种能够区分超多目标优化问题的解的优劣。另一方面,有些学者针对主动多样性提升机制设计了更好的多样性评估策略.总的来说,这两类方法都会提升算法对于收敛性的重视程度。
由于并不依赖帕累托支配关系将解集合向帕累托前沿推进,非帕累托支配的方法(例如基于评价指标的方法和基于聚集的方法)并不会受限于选择压力的问题。但是,它们依然受限于维数诅咒(curse of dimensionality)问题,即需要同时搜索数量随着维度而指数增加的方向。因为权重向量在保持种群的分布方面 起到至关重要的作用,所以。对于基于聚集的方法,很关键的一点在于权重向量 的设置1501.对于基于超体积的多目标演化算法而言, 一个很大的困难在于评价指 标的计算代价太高1511.除了上述儿种方法,基于参照点集的方法为处理超多目标 优化问题提供了一个新的方案:利用给一个参照点集来评价和选择解[521.为了将 用户的偏好嵌入搜索过程,学者们设计了基于偏好的方法来搜索帕累托前沿的 特定领域。与其余的方法不同,降维的方法试图通过分析目标之间的关系或者使 用特征选择的方法达到减少目标数量、降低问题难度的目的153].
第 2 章 超多目标演化算法综述
2.1 基于松弛支配的方法
为了将超多目标优化问题中的非支配解区分开来、提升朝向帕累托前沿的选择压力,学者们提出了很多帕累托支配关系的变种。作者将这类技术分为两类:基于数值的支配和基于数量的支配。
2.1.1 基于数值的支配
顾名思义,这类方法通过改变解的目标函数值来改进帕累托支配关系。总的来说,这些改动的目的在于增大非支配解的支配区域、以期提升解之间的存在支配-被支配关系的可能性。
2.1.2 基于数量的支配【相关文献较少】
基于数值的方法试图通过比较互相优劣的目标计数来比较两个解
2.2 基于多样性的方法
尽管现阶段的很多研究工作集中在改进帕累托支配定义上,但是仍有部分工作研究通过使用专用的多样性评估方法来改进超多目标演化算法。总的来说,这类方法试图通过多样性提升的副作用来改进算法性能。
2.3 基于聚集函数的方法(类似于多个损失相加求最优的过程)
使用聚集函数是区分超多目标问题解的另一途径。根据聚集的信息,这类方法可以被分为两类:聚集个体信息的方法和聚集成对比较结果的方法。
2.3.1 聚集个体信息的方法
这种方法通常使用聚集个体的信息来比较解。它们又可以细分为两个子类:聚集目标函数值和聚集目标的排名,
2.3.2 聚集成对比较结果的方法
除了个体信息,与种群中其他个体的成对的比较结果也可以用来聚合。这类 方法汇总在表2.6中。对于一个解x,它的适应度函数定义为x 和种群中其他解的比较结果的聚合。
2.3.3 讨论
尽管基于聚集的方法不依赖帕累托支配将种群向帕累托前沿推进,但这类方法在处理超多目标优化问题也有着自己的困难。而这些困难也正是未来潜在的科研方向。
- 权重向量的设置:对于聚集个体信息的方法,权重向量对于多样性有着巨大的影响。但是如何处理有限的计算资源和指数型增长的权重向量之间的冲突,仍未有一个广泛认可的答案。
- 聚集函数的选择:论文[16]的实验结果显示 MOEA/D 的解集合在某些测试 样例上收敛性很好但是对于整个帕累托前沿的覆盖较差。切比雪夫函数可能会对于多样性保持造成影响[16.52.116],因为有些权重向量可能对应到了同一个帕累托最优解[52.16]。另一方面,加权和的方法对于非凸帕累托前沿的问题处理的并不好,未来也需要进行改进
2.4 基于评价指标的方法
因为最终解集合的优劣是按照评估指标来比较的,所以使用评价指标的数值来指导搜索过程也是个直觉上比较直接的方法。根据算法使用的评价指标,我 们将算法分为以下三类:基于超体积的、基于距离指标的、基于R2 指标的方法。
2.4.1 基于超体积的方法
超体积评估指标是唯一一个已知可以和帕累托支配关系一致的方法。它的这一性质催生了一系列的基于超体积的演化算法,如表2.7所示。
2.4.2 基于距离指标的函数
由于计算超体积的计算代价过大,有些学者提出了基于距离指标的算法(表 2.8).
2.4.3 基于 R2 指标的方法
R2-MOGA and R2MODE 使用了R2 指标来嵌入了改进版的Goldberg 提出的非支配排序方法(non-dominated sorting method) |124]。 最多10目标的 DTLZ 问 题集上的实验结果表明,算法相比较 SMS-EMOA 时间开销大大较少。另一个基于R2 指标的算法 Many Objective Metaheuristic Based on R2 indicator (MOMBI),也能取得很好的性能 |125]。
2.4.4 讨论
由于这类算法不依赖于帕累托支配来提升选择压力,所以,基于指标的算法在处理超多目标优化问题时的困难也与基于帕累托的算法有所不同。这些困难主要集中在以下几个方面:
首先,超体积的计算代价过大。实验结果显示,算法 SMS-EMOA 的运行时间严重影响其在超多8个目标的超多目标优化问题上的性能33]。其他指标虽然计算开销较小,但是却没有与帕累托支配的严格协同关系,可能会导致性能退化。近年来有很多工作研究如何快速的计算超体积。例如,算法 Hypervolume byslicing objectives (HSO)最差时间复杂度为O(NM-1)²6],the WFG 算法的最差时间复杂度为O(2N-1)[127],ctc⁴.
第二,如果用户期望得到一个均匀一致分布的解集合,超体积指标可能并不 适用。以最优化超体积数值的 SMS-EMOA, 为例,算法对于拐点附近的解更加偏 好,因此只有对线性的帕累托前沿会返回分布均匀的解集合l30.尽管这些结果是 基于2目标问题上的实验结果,但是我们仍然可以推测出 SMS-EMOA 在处理超 多目标优化问题时会出现类似的情况。额外的档案方法或者小生境方法可能会 提升种群的分布。
第三,计算超体积和R2 指标数值,需要参照点。而其他的指标如IGD,GD, and△,,则需要一组帕累托最优解集合的子集。然而,先验地得到这些信息并非 易事。
2.5 基于参照点集合的方法
近年来出现了一类基于参照点集的超多目标演化算法。这类方法使用一个参照点集合来评价解的优劣。因此,搜索的过程由选中的参照点集合来指导方向。
2.5.1 基于真实参照点集合的算法
2.5.2 基于虚拟参照点集合的方法
2.5.3 讨论
尽管距离TAA 算法首次提出已经很多年,但是基于参照点集合的方法还在 初生阶段。很多方面都值得深入的研究。首先,真实参照点集合和虚拟参照点集合孰优孰劣,目前尚无定论。真实参照点似乎包含更多的搜索过程的信息,而 虚拟参照点集合看起来分布更加有规律。其次, TAA, NSGA-III,and TC-SEA 分 别使用了欧式距离、垂线距离和出租车距离来关联种群个体和参照点。不同的距离度量对于关联的影响以及对最终搜索算法性能的影响尚无深入研究。最后, NSGA-III and TC-SEA 都遵循先收敛性-后多样性的模式,而 TAA 使用了两个集合同时考虑收敛性和多样性。正如很多其他演化算法一样,收敛性和多样性的平衡对于基于参照点的算法来说也是一个很重要的研究方向。
2.6 基于偏好的方法
为了逼近超多目标优化问题的整个帕累托前沿,我们需要根据目标数目指数型地增加种群大小。但是,在处理很多现实问题时,种群大小相对于整个目标空间而言太小,以至于无法给出一个有意义的逼近。 因此,根据用户的偏好,瞄准帕累托前沿的一个子集进行逼近看起来是个很好的想法。
2.6.1 先验型基于偏好的方法
先验算法(先选择后搜素):偏好信息在搜索之前定义好,并影响搜索的方向
2.6.2 交互型的基于偏好的方法
交互型算法(边搜素边选择):优化算法与决策者进行交互,根据决策者的反馈不断修正搜素方向,使得最终种群朝向用户感兴趣的领域 (region ofinterest) 演进
在交互型算法中,决策者需要交互式地为算法提供偏好信息这些 算法可以降低计算开销,并逐步引入偏好信息。常见的偏好模型包括目标导向、参照方向、和偏好多面体。
2.6.3 后验型的基于偏好的方法
后验型算法(先搜索后选择):偏好信息在搜索过程结束之后引入,在搜索产出的种群中再选择一个子集作为整体的输出
后验型的基于偏好的方法(先搜素再选择)试图避免决策者介入搜索过程。 用户直到搜索结束得到非支配解集合之后才需要参与决策。
2.6.4 讨论
由于搜索方向受到了用户感兴趣的区域的影响,先验型的和交互式的算法可以在降低搜索过程的计算代价,将更多的搜索开销集中在用户偏好的区域。
相比较而言,后验型的方法在这方面有着先天的不足:它们得到的较大的解集合很有可能包含大量的用户不感兴趣的解。交互式的方法的一个问题在于算法需要决策者经常进行交互,而决策者很有可能疲劳、进而影响算法结果。在某些情景下,偏好信息也可能会误导搜索的方向。
2.7 降维的方法
尽管很多算法试图直接处理超多目标优化问题的困难, 一系列降维的方法 则从另一角度入手处理问题:绕过超多日标优化问题的困难。降维方法致力于处理目标有冗余的超多目标优化问题。 Ishibuchi 等人1161]指出,如果新增加 的目标之间高度相关或者依赖,算法NSGA-IⅡI的性能并不会大幅退化。当一个高维的超多目标优化问题和另一个目标数较少的问题有相似的帕累托前沿时,我 们可以尝试优化目标数较少的问题。根据降维技术的使用时机,这类算法可以分为以下两类:离线型方法和在线型方法。
2.7.1 离线降维方法
对于离线方法,降维技术在得到了一组非支配解之后应用。
2.7.2 在线型降维方法
通过迭代式的获得解集合、调用降维模块,目标的个数随着搜索的进行而逐渐减少。
2.7.3 讨论
降维方法有三个主要优点:
- 首先,它可以减少超多目标演化算法的计算开销;
- 第二,它可以帮助决策制找到冗余的目标;
- 第三,它和其他算法可以很容易的融合在一起。例如, Sinha 等人[176]提出了一个 PI-EMO-VF 框架。该框架将交互式的搜索算法和基于目标降维的问题简化程序相结合,取得了很好的效果。 Brockhoff和Zitzlerl²5]将目标降维嵌入到基于超体积的算法来节省超体积计算带来的时间开销。
降维方法假设算法要处理的超多目标优化问题含有冗余的目标。但是,这 一假设可能会是这类算法的一个限制:当处理的超多目标优化问题没有冗余目标时,算法可能无法减少目标的数量或者无法返回一个合适的解集合[62]。而且,时间开销的节省是在牺牲了原始问题的支配信息的代价上得到的[165]。这种信息损失对问题有多大的影响,目前学术界尚无定论。
2.9 超多目标优化算法小结
在本小节中,作者逐类对于不同的超多目标演化算法进行了充分的讨论:这些算法被分为七类:基于松弛支配的方法、基于多样性的方法、基于聚集的方法、 基于性能指标的方法、基于参照点集的方法、基于偏好的方法以及基于降维的方法。
基于松弛函数的方法试图通过放松传统的支配定义来提升算法的选择压力。 为了达到这一 目的,研究者们提出了一系列的方法,包括基于数值的支配改进 (如 c-dominance,CDAS.grid dominance),和基于目标数的方法(1-k 支配, L 支 配等等)。但是,需要注意的是,如果过度提升选择压力,很可能会影响超多目标演化算法的多样性的性能。
基于多样性的方法试图通过降低多样性维持机制的副作用来提升算法的性 能。由这一思路出发,很多学者提出了适用于超多目标演化算法的多样性维持策 略:如多样性提升的启动或终止、网格邻域小生境方法、基于平移的密度估计以及禁忌搜索等等。算法在实验问题上显示了较好的性能。
基于聚集的方法使用一系列的聚集函数来将个体衡量信息进行聚合,然后使用聚合后的值比较超多目标优化问题的解。这一方式越过的非支配解不可比 较的困难,与指数型增长的目标空间相比,权重变量的数量通常十分有限。这一 情况可能会影响解集合的多样性分布。
基于性能指标的方法通过评价指标的数值来引导搜索过程。因为更好的指 标数值通常意味着解集合是帕累托前沿的更好的逼近。由于和帕累托支配的一 致性,基于超体积的评价指标吸引了学者们的广泛关注。但是,过高的计算代价 一定程度上限制了超体积的方法。因此、有些学者试图使用计算代价更小的评价 指标来指引搜索的过程。
基于参照点集合的方法使用了一组参照点来评估非支配解的质量。这类方 法有两个关键之处:参照点集合的构建和种群个体的评估方式。对于设计新的算 法而言,这两点都需要进行更加深入的研究。
基于偏好的方法通过引入用户的偏好信息来引导算法的搜索方向。根据引 入偏好的时机不同,这类方法可以分为先验型偏好方法、交互式偏好方法和后验 型偏好方法。这三个子类分别再搜索前、搜索中和搜索后引入用户的偏好信息。
与前述方法略有不同,基于降维的方法试图减少超多目标演化算法的目标 数量,从而将原问题转化为另一个难度更低、目标数更少、但是帕累托前沿类 似的问题。根据使用的降维技术,这类方法可以分为以下三个子类:基于相关性 的、基于支配结构的和基于特征选择的方法。这类方法可以降低算法的计算开 销,但是随之而来的是删除的目标的信息损失。
除了上如方法,超多目标优化还有其他高度相关的研究热点,例如使用较大 的种群大小18,191,设计专用的交叉、变异算子120],提出新的非支配排序的方法121, 更好的拥塞距离度量122.23],等等等等。
尽管近年来出现了很多超多目标演化算法,这一领域还有很多研究问题需 要更加深入的探索。 一方面,根据算法的行为来设计更好的机制、处理算法的弱 点、提升现有的算法。例如,对于基于松弛的支配定义的方法,自适应性、适用 性和鲁棒性更强的算法需要研究。对于基于指标的方法,将计算代价大的超体 积指标和其他指标(如时代距离等)相结合,看起来也值得研究。对于基于参照 点集合的方法,参照点集合的更新策略需要设计。另一方面,将不同类的算法相 结合也是很有意思的研究方向。杂交型的算法可能显示出更好的优化性能124.251。 例如,可以将基于松弛的支配定义的方法和基于降维的方法结合,进一步提升算 法的选择压力。
超多目标演化算法及应用研究_大规模多目标演化计算的应用领域_小怪兽会微笑的博客-CSDN博客