开始之前的简介:这篇论文是王林蓉师姐推荐给我看的第一篇入门级别的cv领域的论文,也算是我入手研究生阶段的第一篇论文.我是打算先看看这一领域的论文,然后写的自己一点随笔.若有错误欢迎指正.
一. 专有词汇
非饱和神经元
dropout
饱和非线性,非饱和非线性
二. 论文结构
三. 核心框架
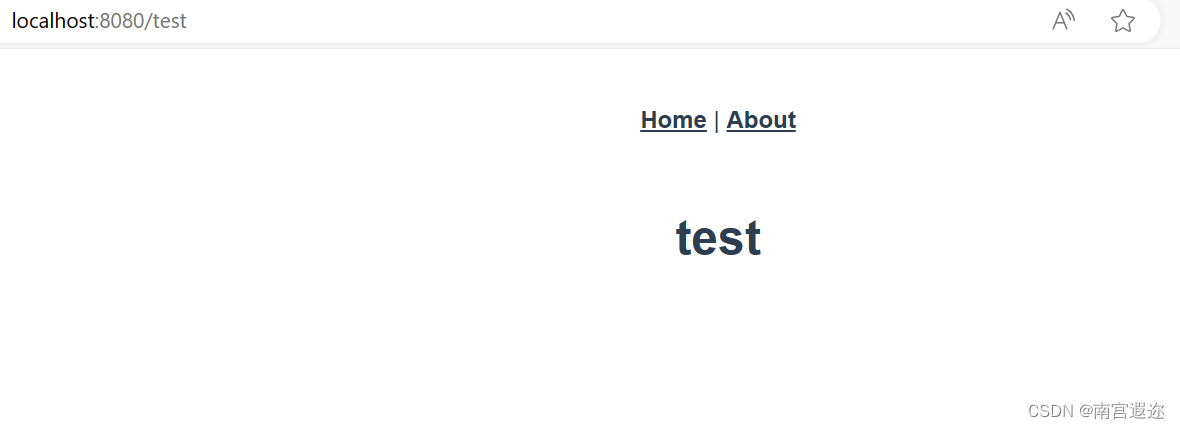
这张图片是这个论文的网络架构,它由八个学习层——五个卷积层,三个全全连接层组成
四.本篇论文的创新方法
4.1激活函数
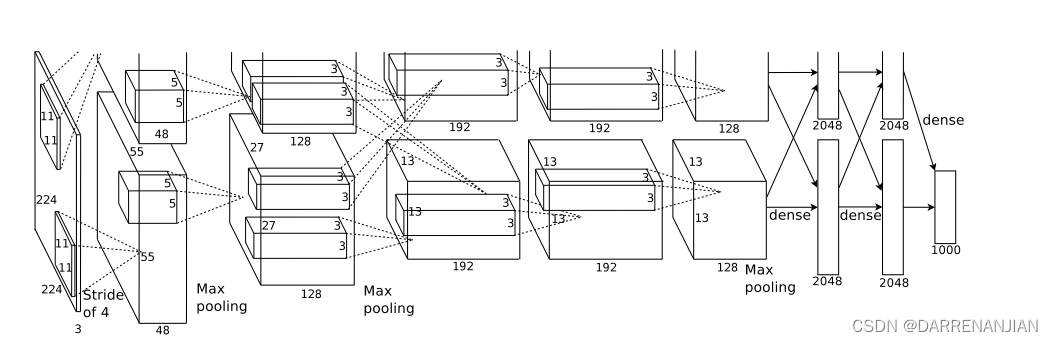
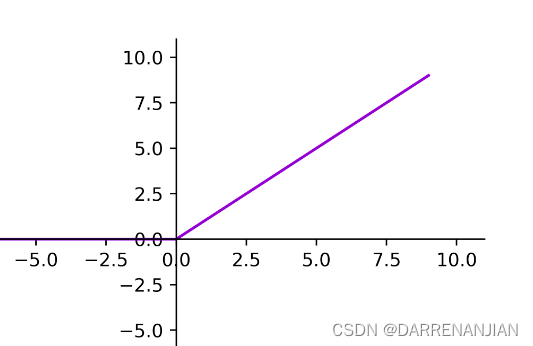
以往在CNN卷积神经网络里面见到的最多的激活函数是sigmoid 函数,但是出于对收敛速度的考虑,在这里作者却用的是ReLU函数.因为这些非饱和函数的收敛速度比饱和函数的收敛速度快得多.对于下图2,它显示了针对特定四层卷积网络,在CIFAR-10数据集上达到25%训练误差所需的迭代次数。这张图表明,如果我们使用传统的饱和神经元模型,我们将无法对如此大的神经网络进行实验。
具有ReLU的四层卷积神经网络(实线)在CIFAR-10上达到25%的训练错误率,比具有tanh神经元的等效网络(虚线)快六倍。每个网络的学习率都是独立选择的,以使训练尽可能快。
4.2 多GPU训练
这里考虑到单个图片对于单个GPU太大,必将超出内存限制.所以将其拆分为两部分,图片上半部分由一个GPU训练,下半部分由一个GPU训练,并且只在某些网络层考虑他们俩的交互(通信).这里给我们提供了一个思路,当某张图片太大时,可以考虑并行训练用以弥补硬件不足,但是需要调整他们的交互.
4.3 局部响应归一化
首先讲一下归一化:归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]或者[-1, 1]区间内,是一种线性变换,是对向量X按照比例压缩再进行平移。
ReLU具有期望的性质,即它们不需要输入归一化来防止它们饱和。这里举一个反例,如:sigmoid函数当x1=100和x2=100000时,明明两者已经相差很大了,但是对应的y却相差不大,这里就是饱和现象。但是对于ReLU函数来讲x1=100,x2=100000时对应的y也有很大差距,故在此不需要进行归一化处理
局部响应归一化
定义为(x,y)处的
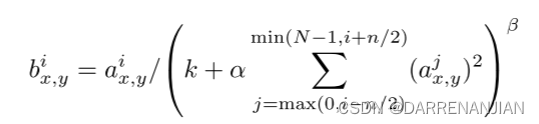





![[Halcon检测] 划痕检测之高斯导数提取](https://img-blog.csdnimg.cn/4d0156d04f164272b6faeda15a5ca8f5.png#pic_center)