import numpy as np
a=np.eye(10,dtype=int)print(a)[[1000000000][0100000000][0010000000][0001000000][0000100000][0000010000][0000001000][0000000100][0000000010][0000000001]]
创建一个10*9的对角1的矩阵
import numpy as np
a=np.eye(M=10,N=9,dtype=int)print(a)[[1000000000][0100000000][0010000000][0001000000][0000100000][0000010000][0000001000][0000000100][0000000010]]
import numpy as np
x=b"I Like study and I like learn python"//这里用到python3在所给定的字符串前面加b
a=np.frombuffer(x,dtype='S1')print(a)[b'I'b' 'b'L'b'i'b'k'b'e'b' 'b's'b't'b'u'b'd'b'y'b' 'b' 'b'a'b'n'b'd'b' 'b'I'b' 'b'l'b'i'b'k'b'e'b' 'b'l'b'e'b'a'b'r'b'n'b' 'b'p'b'y'b't'b'h'b'o'b'n']
eg:读取三个元素
import numpy as np
x=b"I Like study and I like learn python"
a=np.frombuffer(x,dtype='S1',count=3)print(a)[b'I'b' 'b'L']
eg:从位置4读取元素
import numpy as np
x=b"I Like study and I like learn python"
a=np.frombuffer(x,dtype='S1',offset=4)
print(a)
[b'k' b'e' b' ' b's' b't' b'u' b'd' b'y' b' ' b' ' b'a' b'n' b'd' b' '
b'I' b' ' b'l' b'i' b'k' b'e' b' ' b'l' b'e' b'a' b'r' b'n' b' ' b'p'
b'y' b't' b'h' b'o' b'n']
import numpy as np
x=np.logspace(1,2,10,dtype='f4')print(x)[10.12.91549716.68100521.54434827.82559435.93813746.4158959.94842577.42637100.]
3.随机数创建数组
法一:使用random.rand()创建数组
①生成一个随机数
语法规则:
numpy.random.rand()
作用:生成一个[0,1)的随机数,用字符型表示。
实例:
import numpy as np
x=np.random.rand()print(x)0.03294766604498356
②生成含有三个元素的一维数组
语法规则:
numpy.random.rand(num)
*num为一维数组中元素的个数
实例
import numpy as np
x=np.random.rand(3)print(x)[0.401746550.008978110.55320899]
③生成含有N行M列的二维数组
语法规则:
numpy.random.rand(N,M)
*N代表行数,M代表列数
实例
import numpy as np
x=np.random.rand(3,2)print(x)[[0.652874520.92300411][0.145176320.29018207][0.129893970.44906311]]
④生成含有N行M列的S维的数组
语法规则:
numpy.random.rand(N,M,S)
*S=维数-1
实例
import numpy as np
x=np.random.rand(3,2,2)print(x)[[[0.00331950.42253443][0.368752340.29957679]][[0.610872820.9155903][0.577998050.16467769]][[0.473334210.19336464][0.625332590.31438229]]]
法二:利用random.random()创建一维数组
①创建一个随机数
import numpy as np
x=np.random.random()print(x)0.3192154894500221
②创建一维随机数组
import numpy as np
x=np.random.random(6)print(x)[0.371452770.386384170.920332790.607773450.693407990.49806382]
*此方法只能创建一维数组!
法三:创建一顶范围内的随机数组
①语法规则:
numpy.random.randint(low,high,size)
参数
含义
low
下边界值
high
上边界值(不包含)
size
元素个数
实例:构建一个[5,8)含有6个元素的一维随机数组
import numpy as np
x=np.random.randint(5,8,6)print(x)[676577]
法四:创建一组符合标准正态分布的一维数组
*标准正态分布:又称u分布,以0为均值,以1为标准差的正态分布,N(0,1)
语法规则:
numpy.random.randn()
eg.建立一个符合正态分布的随机数组
import numpy as np
x=np.random.randn(2,4)print(x)[[-0.257292270.096707480.775414190.55263664][0.25588823-0.239290830.693562510.33543219]]
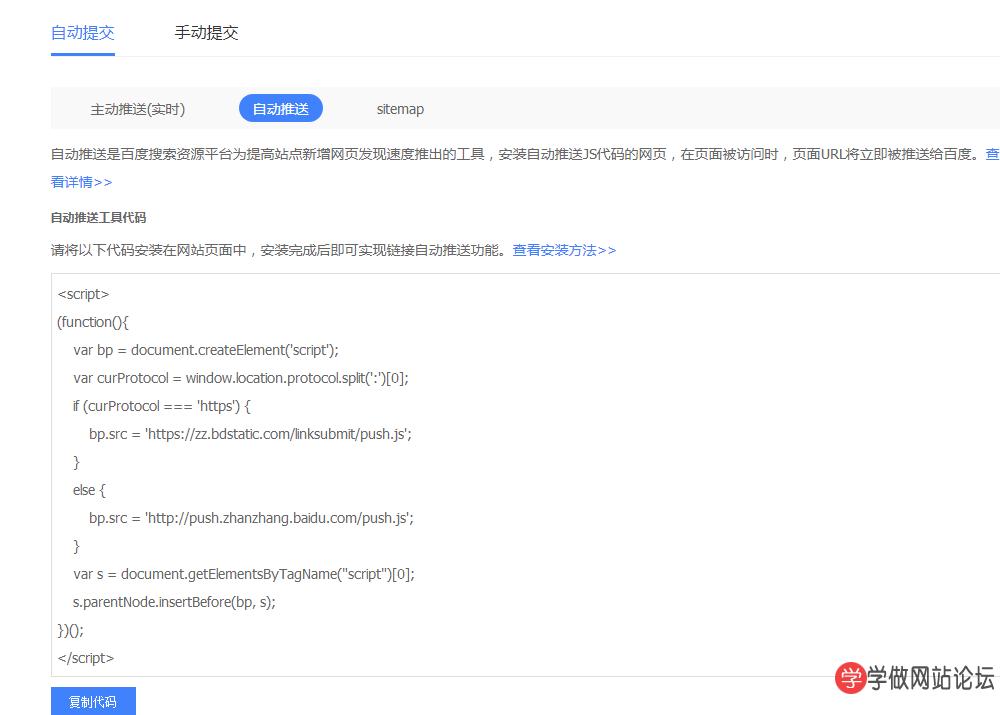
百度站长工具
在百度站长工具中点击“自动推送”,如下截图: 推送代码放网站的底部
将百度平台提交的主动推送代码放在自己的网站的底部模板中;
<script> (function(){ var bp document.createElement(script); var curProtocol window.locati…
4.1.4 大厂面试题中断机制考点
如何停止中断运行中的线程?
通过一个volatile变量实现
package com.nanjing.gulimall.zhouyimo.test;import java.util.concurrent.TimeUnit;/*** author zhou* version 1.0* date 2023/10/15 2:34 下午*/
public class InterruptD…
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 10 Oct 2023 (showing first 100 of 172 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Few-Shot Spoken Language Understanding via Joint Speech-Text Model…