💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

文章目录
- 🥦引言
- 🥦前期的准备
- 🥦基本的步骤说明
- 🥦代码讲解+实现
🥦引言
在机器学习和深度学习中,数据集的加载和处理是一个至关重要的步骤。PyTorch是一种流行的深度学习框架,它提供了强大的工具来加载、转换和管理数据集。在本篇博客中,我们将探讨如何使用PyTorch加载数据集,以便于后续的模型训练和评估。
🥦前期的准备
在实战前,我们需要了解三个名词,Epoch、Batch-Size、Iteration
下面针对上面,我展开进行说明
-
Epoch(周期):
定义:Epoch是指整个训练数据集被完整地前向传播和反向传播通过神经网络的一次循环。在一个Epoch内,模型将看到训练集中的每个样本一次,无论是一次完整的前向传播和反向传播,还是批量的。
作用:一个Epoch代表了一次完整的训练周期。在每个Epoch结束后,模型参数都会被更新一次。Epoch的数量通常是一个超参数,可以控制模型的训练时间和效果。 -
Batch Size(批大小):
定义:Batch Size是指每次迭代时用于训练模型的样本数量。在每个迭代中,模型将根据批大小从训练数据中选择一小批样本来执行前向传播和反向传播,然后更新模型参数。
作用:Batch Size控制了每次参数更新的规模。较大的批大小可以加速训练,但可能需要更多内存。较小的批大小可以增加模型的泛化能力,但训练时间可能更长。 -
Iterations(迭代):
定义:Iteration是指一次完整的前向传播、反向传播和参数更新。一个Iteration中,模型会处理一个Batch Size的样本。
联系:Iterations通常用于描述在一个Epoch内,模型参数更新的次数。一个Epoch内的Iterations数量等于训练数据集的大小除以Batch Size。例如,如果你有1000个训练样本,批大小为100,那么一个Epoch包含10个Iterations(1000 / 100 = 10)。
总结一下: 一个Epoch包含多个Iterations,每个Iteration包含一个Batch Size的样本。
Batch Size决定了每次参数更新的规模,而Epoch表示整个数据集的一个完整训练周期。
训练时通常迭代多个Epochs,其中每个Epoch由多个Iterations组成,以逐渐优化模型的参数。
超参数的选择,如Epoch数量和Batch Size,会影响训练的速度和模型的性能,需要根据具体问题进行调整和优化。
在DataLoader中有一个参数是shuffle,这个参数是一个bool值的参数,如果设置为TRUE的话,表示打乱数据集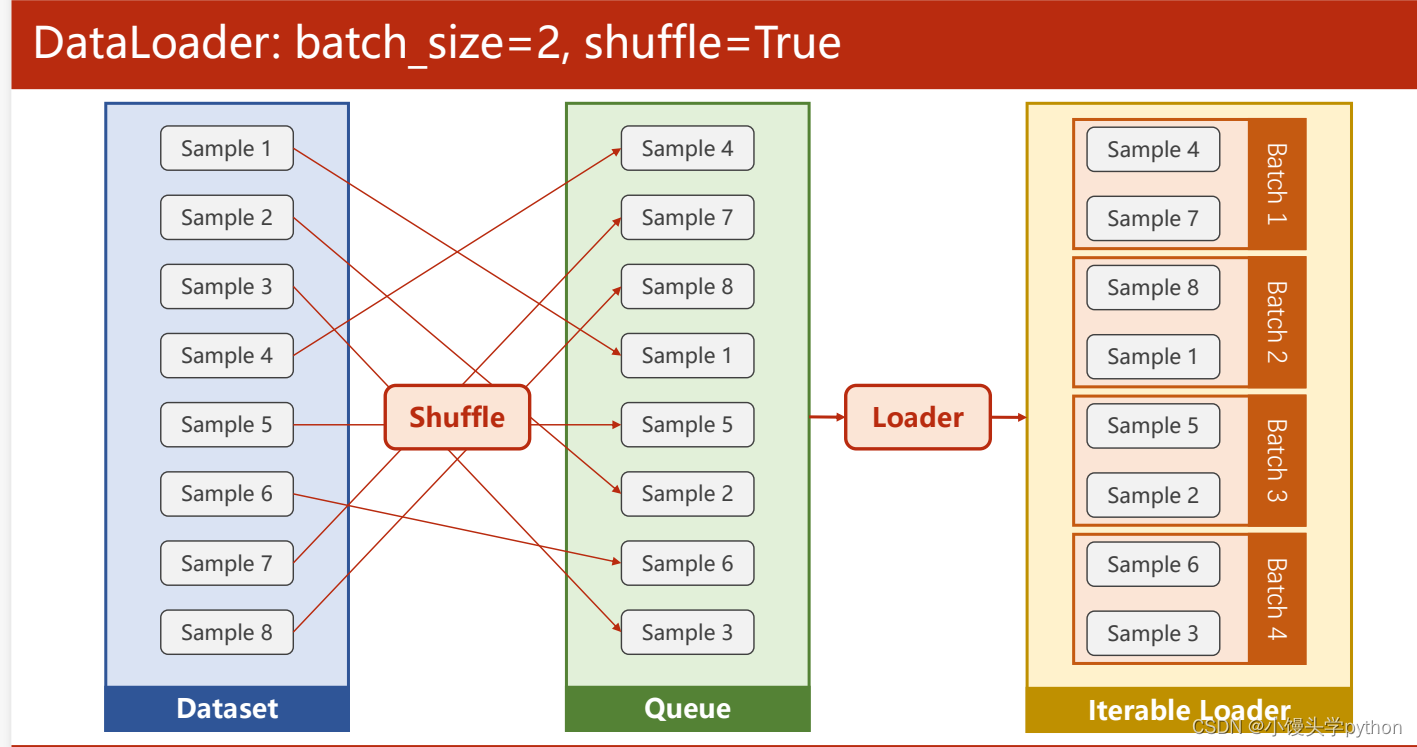
🥦基本的步骤说明
- 导入必要的库
- 定义数据预处理转换
- 下载和准备数据集
- 创建数据加载器
- 数据迭代
这里介绍一下DataLoader的参数
-
dataset:这是你要加载的数据集的实例,通常是继承自torch.utils.data.Dataset的自定义数据集类或内置数据集类(如MNIST)。
-
batch_size:指定每个批次(batch)中包含的样本数。这是一个重要参数,影响了训练和推理过程中的计算效率和模型的性能。通常,你需要根据你的硬件资源和数据集大小来选择适当的批大小。
-
shuffle:布尔值,控制是否在每个Epoch开始时打乱数据集的顺序。通常,设置为True可以帮助模型更好地学习,因为它增加了数据的随机性,避免模型对数据的顺序产生过度依赖。在训练时,通常建议将其设置为True。
-
num_workers:指定用于数据加载的子进程数量。这允许在数据加载过程中并行加载数据,以提高数据加载的效率。通常,设置为大于0的值可以加速数据加载。但要注意,过高的值可能会占用过多系统资源,因此需要权衡。
-
pin_memory:如果为True,则数据加载器会将批次数据置于GPU的锁页内存中,以提高数据传输的效率。通常,在GPU上训练时,建议将其设置为True。
-
drop_last:如果为True,当数据集的大小不能被批大小整除时,将丢弃最后一个批次。通常,将其设置为True以确保每个批次都具有相同大小,这在某些情况下有助于训练的稳定性。
-
timeout:指定数据加载超时的时间(单位秒)。如果数据加载器无法在指定时间内加载数据,它将引发超时异常。这可用于避免数据加载过程中的死锁。
🥦代码讲解+实现
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
-
首先,导入所需的库,包括NumPy和PyTorch。这些库用于处理数据和创建深度学习模型。
-
创建一个自定义的数据集类DiabetesDataset,用于加载和处理数据。该类继承自torch.utils.data.Dataset类,并包含以下方法:
init:加载数据文件(假定是CSV格式),将数据分为特征(x_data)和标签(y_data),并存储数据集的长度(len)。
getitem:用于获取数据集中特定索引位置的样本。
len:返回数据集的总长度。 -
创建数据集实例dataset,并使用DataLoader创建数据加载器train_loader。数据加载器用于批量加载数据,batch_size参数设置每个批次的样本数,shuffle参数表示是否随机打乱数据集顺序,num_workers参数表示并行加载数据的进程数。
-
定义神经网络模型Model,该模型继承自torch.nn.Module。模型包含三个线性层和Sigmoid激活函数。在__init__方法中,定义了模型的层结构,而forward方法描述了数据在模型中的传递过程。
-
创建模型实例model。
-
定义损失函数criterion和优化器optimizer。在这里,使用了二元交叉熵损失函数(torch.nn.BCELoss)和随机梯度下降优化器(torch.optim.SGD)。
-
进行训练循环,循环次数为100次(由for epoch in range(100)控制)。
在内部循环中,使用enumerate(train_loader, 0)来迭代数据加载器。
准备数据:获取输入数据和标签。
前向传播:将输入数据传递给模型,获得预测值。
计算损失:使用损失函数计算预测值与实际标签之间的损失。
打印损失值:输出当前训练批次的损失值。
反向传播:通过优化器的backward()方法计算梯度。
参数更新:使用优化器的step()方法来更新模型参数。
这段代码演示了一个基本的二分类问题的训练过程,其中神经网络模型用于预测糖尿病患者的标签(0表示非糖尿病,1表示糖尿病)。模型的训练是通过反向传播算法来更新模型参数以减小损失。在训练循环中,你可以观察损失值的变化,以了解模型的训练进展。

挑战与创造都是很痛苦的,但是很充实。