文章目录
- 0、demo数据
- 1、源算子Source
- 2、从集合中读取数据
- 3、从文件中读取
- 4、从Socket读取
- 5、从Kafka读取
- 6、从数据生成器读取数据
- 7、Flink支持的数据类型
- 8、Flink的类型提示(Type Hints)
0、demo数据
准备一个实体类WaterSensor:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class WaterSensor{
private String id; //水位传感器类型
private Long ts; //传感器记录时间戳
private Integer vc; //水位记录
}
//注意所有属性的类型都是可序列化的,如果属性类型是自定义类,那要实现Serializable接口
模块下准备个文件words.txt,内容:
hello flink
hello world
hello java
1、源算子Source
Flink可以从各种来源获取数据,然后构建DataStream进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。

Flink1.12以前,添加数据源的方式是,调用执行环境对象的addSource方法
DataStream<String> stream = env.addSource(...);
//方法传入的参数是一个“源函数”(source function),需要实现SourceFunction接口
Flink1.12开始的流批统一的Source框架下,则是:
DataStreamSource<String> stream = env.fromSource(…)
2、从集合中读取数据
调用执行环境对象的fromCollection方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用,一般用于测试
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
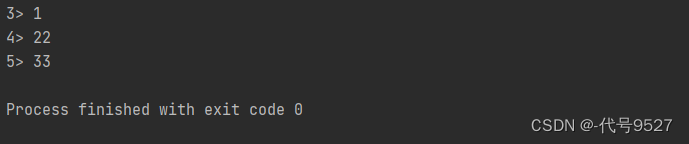
List<Integer> data = Arrays.asList(1, 22, 33);
DataStreamSource<Integer> ds = env.fromCollection(data);
stream.print(); //直接打印
env.execute();
}
还可以直接fromElements方法:
DataStreamSource<Integer> ds = env.fromElements(1,22,33);
3、从文件中读取
从文件中读是批处理中最常见的读取方式,比如读取某个日志文件。首先需要引入文件连接器依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//第三个参数为自定义的sourceName
FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("input/word.txt")).build();
env.fromSource(fileSource,WatermarkStrategy.noWatermarks(),"file")
.print();
env.execute();
}
- FileSource数据源对象的创建,传参可以是目录,也可以是文件,可以相对、绝对路径,也可从HDFS目录下读,开头格式hdfs://…
- 相对路径是从系统属性user.dir获取路径:idea下是project的根目录,standalone模式下是集群节点根目录
- 之前的env.readTextFile方法被标记为过时是因为底层调用了addSource
4、从Socket读取
前面的文件和集合,都是有界流,而Socket常用于调试阶段模拟无界流:
DataStream<String> stream = env.socketTextStream("localhost", 9527);
# 对应的主机执行
nc -lk 9527
5、从Kafka读取
数据源是外部系统,常需要导入对应的连接器的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
实例:
public class SourceKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("hadoop01:9092,hadoop02:9092,hadoop03:9092") //指定Kafka节点的端口和地址
.setTopics("topic_1") //消费的Topic
.setGroupId("code9527") //消费者组id
//Flink程序做为Kafka的消费者,要进行对象的反序列化,setDeserializer对key和value都生效
.setStartingOffsets(OffsetsInitializer.latest()) //指定Flink消费Kafka的策略
.setValueOnlyDeserializer(new SimpleStringSchema()) //反序列化Value的反序列化器
.build();
DataStreamSource<String> stream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka-source");
stream.print("Kafka");
env.execute();
}
}
//很多传参Ctrl+P看源码类型、Ctrl+H实现类自行分析
Kafaka的消费者参数:
- earliest:有offset,就从offset继续消费,没offset,就从
最早开始消费 - latest:有offset,就从offset继续消费,没offset,就从
最新开始消费
Flink下的KafkaSource,offset消费策略有个初始化器OffsetInitializer,默认是earliest:
- earliest:
一定从最早消费 - latest:
一定从最新消费
注意和Kafka自身的区别。
6、从数据生成器读取数据
Flink从1.11开始提供了一个内置的DataGen 连接器,主要是用于生成一些随机数来调试。1.17版本提供了新写法,导入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-datagen</artifactId>
<version>${flink.version}</version>
</dependency>
public class DataGeneratorDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setParallelism(1);
DataGeneratorSource<String> dataGeneratorSource =
new DataGeneratorSource<>(
new GeneratorFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
return "Number:"+value;
}
},
Long.MAX_VALUE,
RateLimiterStrategy.perSecond(10),
Types.STRING
);
env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "datagenerator")
.print();
env.execute();
}
}
new数据生成器源对象,有四个参数:
- 第一个为GeneratorFunction接口,key为Long型,value为需要map转换后的类型。需要实现map方法,输入方法固定是Long类型
- 第二个为自动生成数字的最大值,long型,到这个值就停止生成
- 第三个为限速策略,比如每秒生成几个
- 第四个为返回的数据类型,Types.xx,Types类是Flink包下的
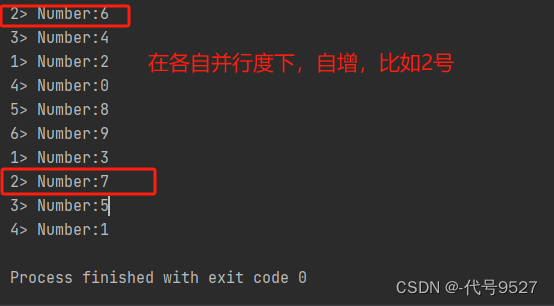
嘶,并行度默认为CPU核心数了,输出算子6个子任务,且是每个并行度上是各自自增的(先按总数/并行度划分,再各自执行,比如最大值100,并行度2,那一个从0开始,另一个从50到99)。数字打印出来看着有点乱了,改下并行度
env.setParallelism(1);
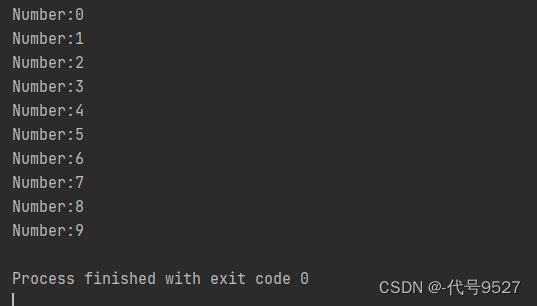
可以看到程序结束了,相当于有界流了,想模拟无界流,可以第二个参数传Long.MAX_VALUE,这就一直输出了
7、Flink支持的数据类型
Flink使用
类型信息(TypeInformation)来统一表示数据类型。TypeInformation类是Flink中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器
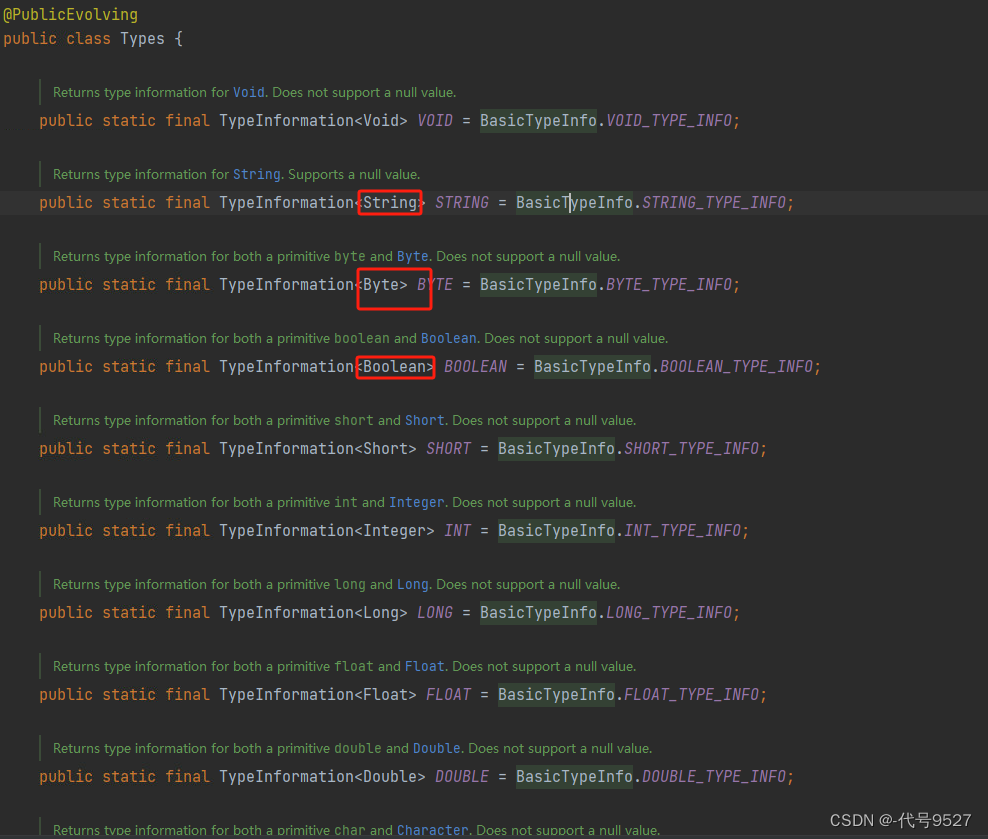
对于Java和Scale常见的数据类型,Flink都支持,在Types工具类中可以看到:
Flink支持所有自定义的Java类和Scala类,但要符合以下要求:
- 类是公有(public)的
- 有一个无参的构造方法
- 所有属性都是可访问的,即公有public或private+getter、setter
- 类中所有属性的类型都是可以序列化的
不满足以上要求的类,会被Flink当作泛型类来处理。Flink会把泛型类型当作黑盒,无法获取它们内部的属性,它们也不是由Flink本身序列化的,而是由Kryo序列化的。
8、Flink的类型提示(Type Hints)
Flink还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于Java中泛型擦除的存在,在某些特殊情况下(比如Lambda表达式中),自动提取的信息是不够精细的,需要我们手动显示提供类型信息。
之前的word count流处理程序,我们在将String类型的每个词转换成(word, count)二元组后,就明确地用returns指定了返回的类型。因为对于map里传入的Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
//....
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));