文章目录
- 线程池简诉
- ThreadPoolExecutor详解
- ThreadPoolExecutor参数详解
- 创建线程池的工具类Executors
线程池简诉
针对各种池子,比如
- 连接池:用于管理和重复使用数据库连接,避免频繁创建和销毁数据库连接带来的性能开销。
- 对象池:用于管理和重复使用对象,避免频繁创建和销毁对象带来的性能开销。
- 字符串池:用于管理和重复使用字符串,避免频繁创建和销毁字符串带来的性能开销。
线程池的话也是一样的,用于管理和重复使用线程,避免频繁创建和销毁线程带来的性能开销。
而线程池的工作原理就是相当于把任务提交到一个阻塞队列里面,如何线程去阻塞队列里面拿到任务去执行.
ThreadPoolExecutor详解
首先看看UML图:
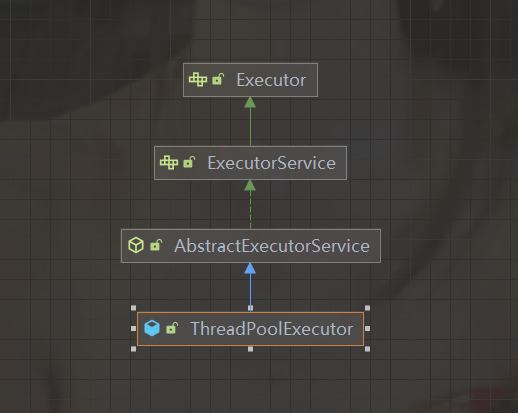
可以看到最顶层的接口是Executor,就是线程池的顶层接口,线程池的作用就是执行方法,而Executor方法里面就一个方法:
void execute(Runnable command);
这个方法就是线程池最主要的方法,执行runnable任务,然后ExecutorService又对线程池的功能进行了加强,比如可以进行管理线程池,且提供了执行任务的能力,比如执行异步返回Future结果的方法,执行多个任务的方法;
ThreadPoolExecutor参数详解
最主要的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
- int corePoolSize 核心线程数(一般为cpu数Runtime.getRuntime().availableProcessors())
- int maximumPoolSize 最大线程数(一般为cpu数*2)
- long keepAliveTime 存活的时长(<最大线程数,<核心线程数的)
- TimeUnit 时间单位
- BlockingQueue workQueue 工作队列
- ThreadFactory threadFactory 线程工厂,创建线程的地方
- RejectedExecutionHandler handler 拒绝策略
需要注意的是,maximumPoolSize 是当线程队列满了,且核心线程都在执行中的时候,再提交任务,就不会放到队列里面,只会新建线程执行,如果线程数量等于了最大线程数的时候,就会走对应的拒绝策略,如果任务执行完,过期时间才会对新增线程有效,当然有个方法allowCoreThreadTimeOut,让核心线程也可以过期(一般不会设置的),一般工作队列不会设置为无限队列,因为如果队列无限长可能会造成oom,且最大线程数就没用了.
创建线程池的工具类Executors
- newFixedThreadPool
创建固定大小的线程池。核心数和最大数是一样的,任务如果过多会在队列中阻塞.如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。 - newWorkStealingPool
1.8新加的线程池,forkJoinPool 可以根据CPU的核数并行的执行,适合使用在很耗时的操作,可以充分的利用CPU执行任务,
任务窃取线程池,不保证执行顺序,适合任务耗时差异较大。
线程池中有多个线程队列,有的线程队列中有大量的比较耗时的任务堆积,而有的线程队列却是空的,就存在有的线程处于饥饿状态,当一个线程处于饥饿状态时,它就会去其它的线程队列中窃取任务。解决饥饿导致的效率问题。
默认创建的并行 level 是 CPU 的核数。主线程结束,即使线程池有任务也会立即停止。 - newSingleThreadExecutor
创建一个单线程的线程池。这个线程池的核心数和最大数都是1,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。 - newCachedThreadPool
创建一个可缓存的线程池。核心数是0,最大数是 Integer.MAX_VALUE,如果一下子任务很多,且执行时间长,容易发生异常,堆溢出,且执行效率降低,并不是线程数目越多,执行越快的,如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。 - newScheduledThreadPool
支持周期性任务的调度。此线程池支持定时以及周期性执行任务的需求。按道理来说线程池的最大数是 Integer.MAX_VALUE,但是,线程数并不会超过核心数…是固定长度的.
这些方法基本都是创建ThreadPoolExecutor,或者继承ThreadPoolExecutor,对其进行增强.
#任务拒绝策略
默认的拒绝策略是AbortPolicy,直接抛出异常
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
public static class AbortPolicy implements RejectedExecutionHandler {
/**
* Creates an {@code AbortPolicy}.
*/
public AbortPolicy() { }
/**
* Always throws RejectedExecutionException.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
* @throws RejectedExecutionException always
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
- ThreadPoolExecutor.AbortPolicy 丢弃任务并且抛出- RejectedExecutionException异常。在任务不能提交的时候,抛出异常,及时反馈程序运行状态。如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承受更大的并发量的时候,能够及时通过异常发现。
- ThreadPoolExecutor.DiscardPolicy 丢弃任务,但是不抛出异常。使用此策略,可能会使我们无法发现系统的异常状态。建议是一些无关紧要的业务采用此策略。
- ThreadPoolExecutor.DiscardOldestPolicy 丢弃队列最前面的任务,然后重新提交被拒绝的任务。
- ThreadPoolExecutor.CallerRunsPolicy 由调用线程(提交任务的线程)处理该任务。这种情况是需要让所有任务都执行完毕,那么就适合大量计算的任务类型去执行,多线程仅仅是增大吞吐量的手段,最终必须要让每个任务都执行完毕。