复制集群搭建
基本介绍
什么是复制集?
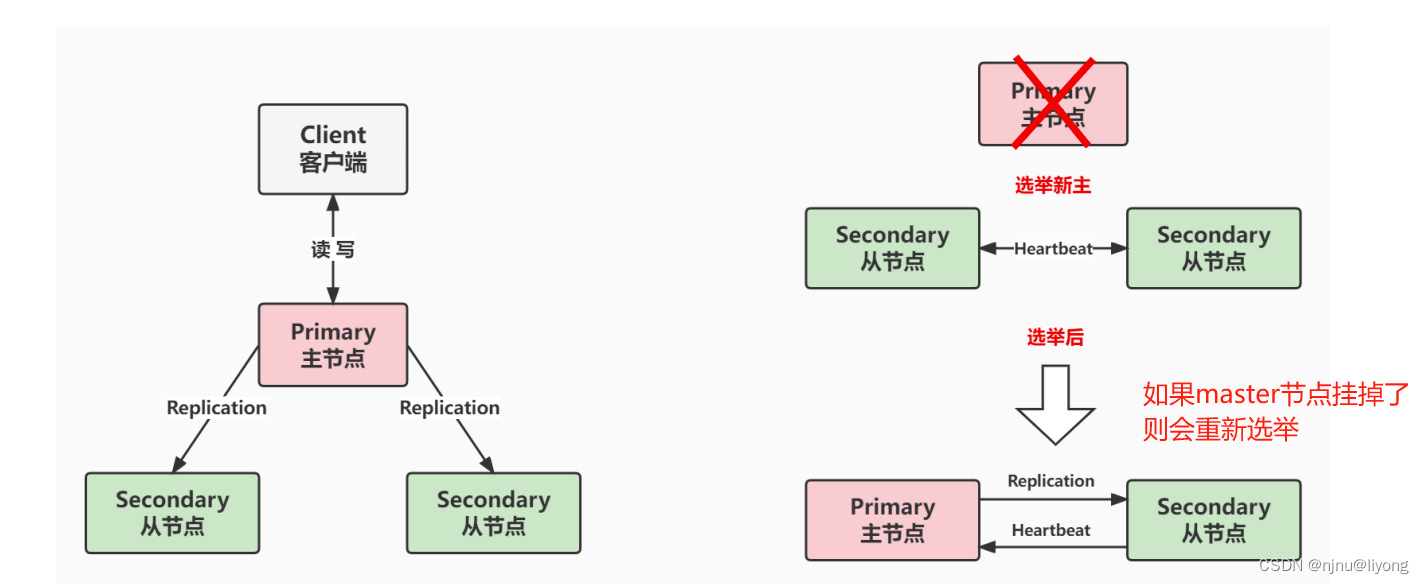
复制集是由一组拥有相同数据集的MongoDB实例做组成的集群。
复制集是一个集群,它是2台及2台以上的服务器组成,以及复制集成员包括Primary主节点,Secondary从节点和投票节点。
复制集提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,保证数据的安全性。
有一台Master机器,负责客户端的写入操作,然后有一台或者多台的机器做Slave,用来同步Master机器数据。一旦Master宕机,集群会快速的在Slave机器中选出一台机器来切换成为Master。这样使用多台服务器来维护相同的数据副本,提高MongoDB的可用性。
整个复制集中,只有主节点负责write操作,read操作不限制。
集群搭建
1 创建目录和配置文件
#创建目录及日志文件
mkdir -p /env/mogosets/data/server1
mkdir -p /env/mogosets/data/server2
mkdir -p /env/mogosets/data/server3
mkdir -p /env/mogosets/logs
touch server1.log server2.log server3.log
# 主节点配置
dbpath=/env/mogosets/data/server1
bind_ip=0.0.0.0
port=37017
fork=true
logpath=/env/mogosets/logs/server1.log
# 集群名称
replSet=heroMongoCluster
#从节点1
dbpath=/env/mogosets/data/server2
bind_ip=0.0.0.0
port=37018
fork=true
logpath=/env/mogosets/logs/server2.log
# 集群名称
replSet=heroMongoCluster
#从节点2
dbpath=/env/mogosets/data/server3
bind_ip=0.0.0.0
port=37019
fork=true
logpath=/env/mogosets/logs/server3.log
# 集群名称
replSet=heroMongoCluster
分别新建三个mogo的配置文件:

2 编辑启动脚本和关闭脚本
2-1 启动脚本
/env/liyong/install/mongodb/mongodb/bin/mongod -f /env/mogosets/mongocluster/mongo_37017.conf
/env/liyong/install/mongodb/mongodb/bin/mongod -f /env/mogosets/mongocluster/mongo_37018.conf
/env/liyong/install/mongodb/mongodb/bin/mongod -f /env/mogosets/mongocluster/mongo_37019.conf
echo "start mongo cluster..."
ps -ef | grep mongodb
2-2 关闭脚本
/env/liyong/install/mongodb/mongodb/bin/mongod --shutdown -f /env/mogosets/mongocluster/mongo_37017.conf
/env/liyong/install/mongodb/mongodb/bin/mongod --shutdown -f /env/mogosets/mongocluster/mongo_37018.conf
/env/liyong/install/mongodb/mongodb/bin/mongod --shutdown -f /env/mogosets/mongocluster/mongo_37019.conf
echo "stop mongo cluster..."
ps -ef | grep mongodb
3 初始化集群
var cfg ={"_id":"heroMongoCluster", "protocolVersion" : 1, "members":[ {"_id":1,"host":"127.0.0.1:37017","priority":10}, {"_id":2,"host":"127.0.0.1:37018"} ] } #_id要和replSet=heroMongoCluster保持一致
rs.initiate(cfg) #初始化集群 这里可以将下面的37019加入members 这里放到后面试演示节点的动态增加和删除
rs.status() #查询集群的变化
3-1 关于配置里面我们可以指定下面这些参数

4 节点的动态增删
rs.add("127.0.0.1:37019") #添加节点
rs.remove("127.0.0.1:37019") #删除节点
rs.status()
5 测试集群
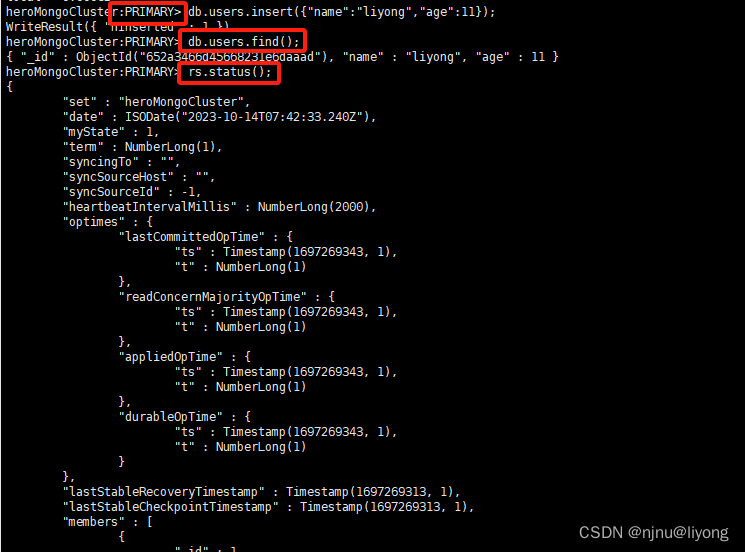
5-1 primary节点
#连接primary节点
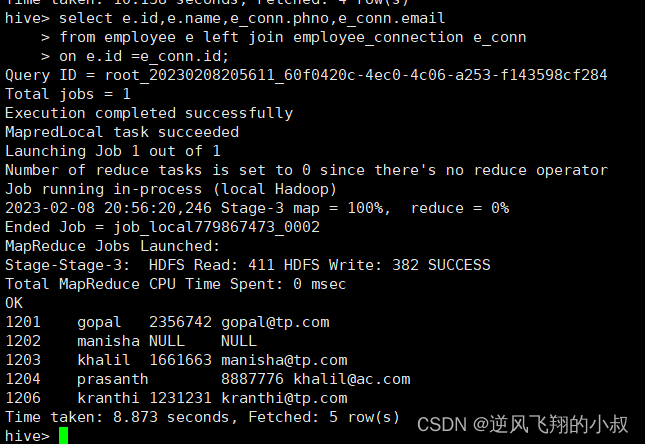
mongo --host 127.0.0.1 --port=37017
db.users.insert({"name":"liyong","age":11});
db.users.find();
可以看到集群搭建成功以后连接
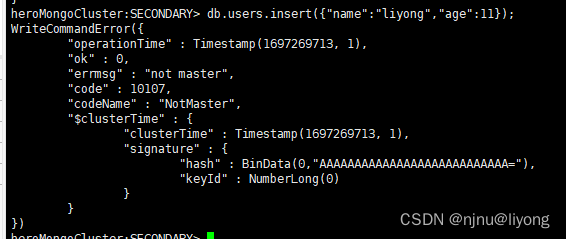
5-2 secondary节点
mongo --host 127.0.0.1 --port=37018
db.users.insert({"name":"liyong","age":11});
插入数据的时候提示我们了,不是主节点,这也验证了前面提到的再从节点是只读的,主节点可读可写
db.users.find(); #在从节点进行查询数据
我们可以看到这也一个错误,需要执行rs.slaveOk();
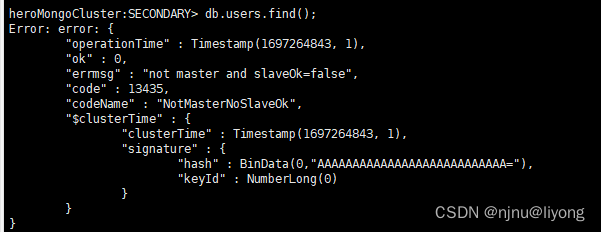
rs.slaveOk(); #执行此命令以后我们就可以进行查询数据了
6 关闭primary节点,演示主节点重新选取
/env/liyong/install/mongodb/mongodb/bin/mongod --shutdown -f /env/mogosets/mongocluster/mongo_37017.conf
可以看到18这个从节点变成了主节点
然后我们再启动17节点
/env/liyong/install/mongodb/mongodb/bin/mongod -f /env/mogosets/mongocluster/mongo_37017.conf #可以看到我们的17又成为了主节点 因为我们再初始化配置的时候指定了它的优先级会高一点

7 仲裁节点
用于管理集群的主从节点
7-1 新增一个节点为仲裁节点
rs.addArb("127.0.0,1:37020"); #添加仲裁节点到当前集群
rs.status() # 查询集群的状态
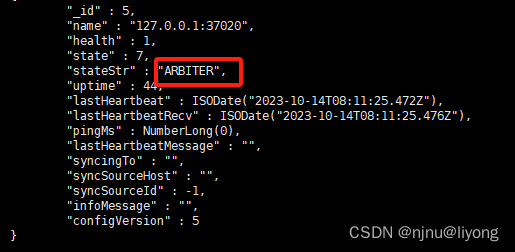
7-2 也可以在一开始就初始化为仲裁节点
var cfg ={"_id":"heroMongoCluster",
"protocolVersion" : 1,
"members":[
{"_id":1,"host":"127.0.0.1:37017","priority":10},
{"_id":2,"host":"127.0.0.1:37018","priority":0},
{"_id":3,"host":"127.0.0.1:37019","priority":5},
{"_id":4,"host":"127.0.0.1:37020","arbiterOnly":true}
]
};
# 重新装载配置,并重新生成集群节点。
rs.reconfig(cfg)
# 重新查看集群状态
rs.status()
分片集群
基本介绍
为什么要分片?
存储容量需求超出单机磁盘容量
活跃的数据集超出单机内存容量,导致很多请求都要从磁盘读取数据,影响性能
IOPS超出单个MongoDB节点的服务能力,随着数据的增长,单机实例的瓶颈会越来越明显
副本集具有节点数量限制
分片集群由以下3个服务组成:
Shards Server:每个shard由一个或多个mongod进程组成,用于存储数据
Router Server:数据库集群的请求入口,所有请求都通过Router(mongos)进行协调,不需要在应用程序添加一个路由选择器,就是一个请求分发中心它负责把应用程序的请求转发到对应的Shard服务器
Config Server:配置服务器。存储所有数据库元信息(路由、分片)的配置
片键(Shard Key): 为了在数据集合中分配文档,MongoDB使用分片主键分割集合。
区块(Chunk):在一个Shards Server内部,MongoDB还是会把数据分为区块chunk,每个chunk代表这个Shards Server内部一部分数据,包含基于分片主键的左闭右开的区间范围chunk。
怎么合理选择分片?
当我们在选择分片方式的时候,从数据的查询和写入,关键在于权衡性能和负载
最好的效果:
数据查询时能命中更少的分片
数据写入时能够随机的写入每个分片
数据库中没有合适的 Shard Key 供选择,或者使用的Shard Key基数太小,即变化少(如:星期,只有7天可变化),可以选择使用组合键(A + B),甚至可以添加冗余字段组合。一般是粗粒度 + 细粒度进行组合。
常见发分片方式
1)范围分片
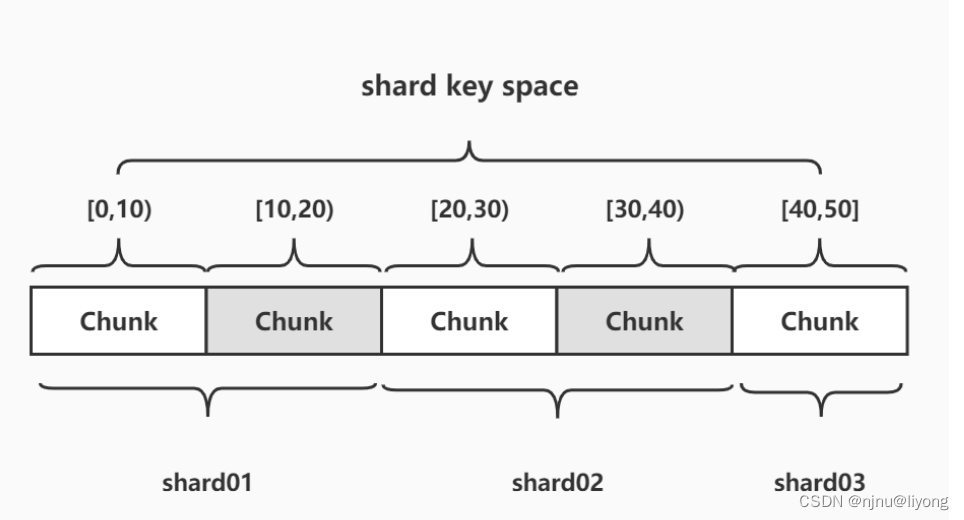
范围分片是基于分片Shard Key的值切分数据,每一个Chunk将会分配到一个范围
范围分片适合满足在一定范围内的查找
例如:查找X的值在[20,30)之间的数据,mongo 路由根据Config Server中存储的元数据,直接定位到指定的Shards的Chunk
缺点:如果Shard Sey有明显递增(或者递减)趋势,则新插入的文档多会分布到同一个chunk,所以并发写入会出现明显瓶颈
hash分片(Hash based sharding)
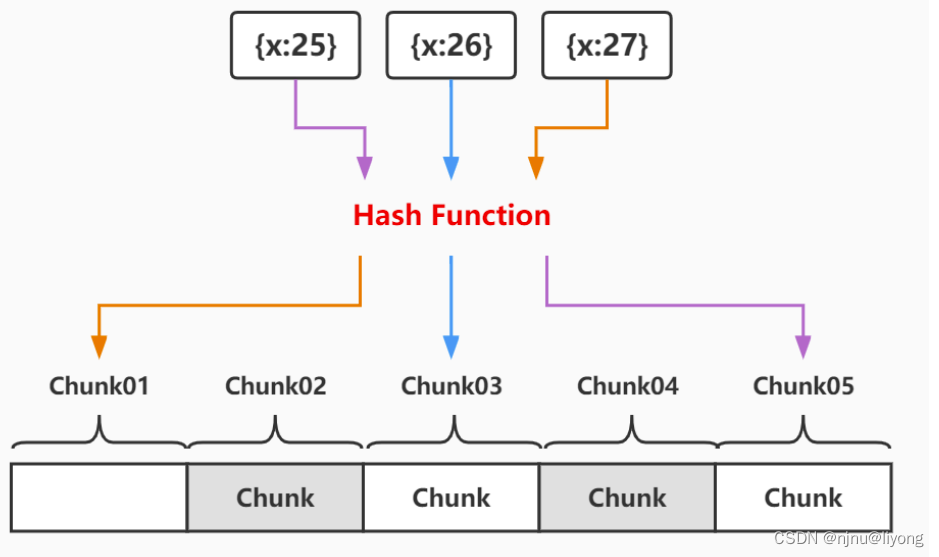
Hash分片是计算一个分片Shard Key的hash值,每一个区块将分配一个范围的hash值
Hash分片与范围分片互补,能将文档随机的分散到各个Chunk,充分的利用分布式写入能力,弥补了范围分片的不足
缺点:范围查询性能不佳,所有范围查询要分发到后端所有的Shard才能找出满足条件的文档
搭建实战
1 架构图
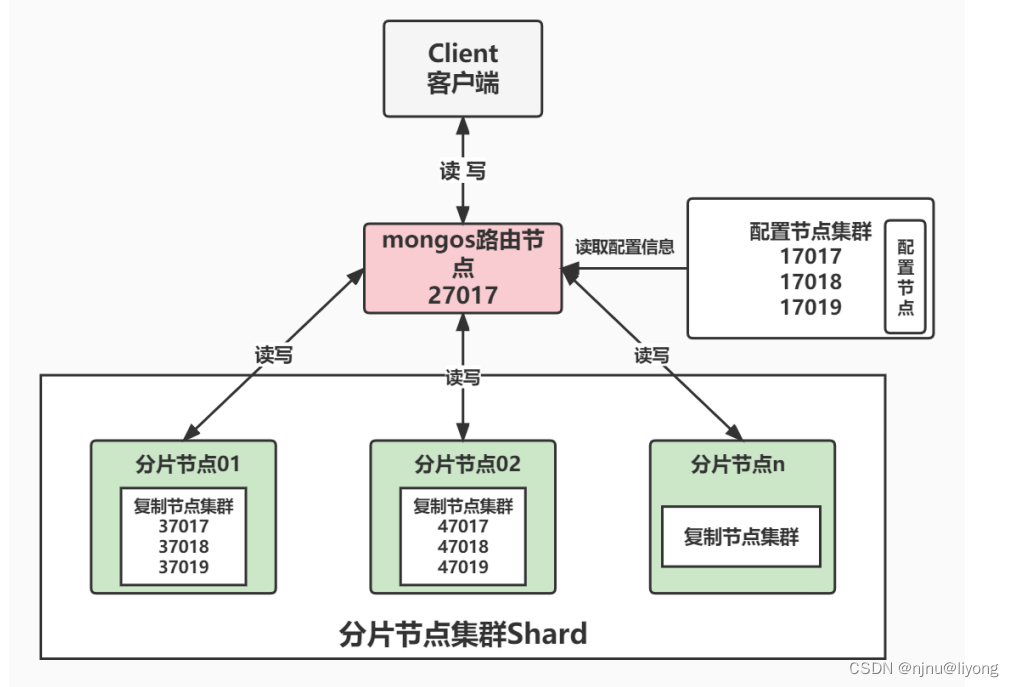
2 这里分片节点集群我们可以复用上面的那个集群,这里我们按照上面的方式在搭建一个分片集群和节点集群,这里不再赘述了
#节点集群
var cfg ={"_id":"configcluster", # _id要和mongo.conf replSet=configcluster保持一致
"protocolVersion" : 1,
"members":[
{"_id":1,"host":"127.0.0.1:17017","priority":10},
{"_id":2,"host":"127.0.0.1:17018","priority":0},
{"_id":3,"host":"127.0.0.1:17019","priority":5},
]
};
rs.initiate(cfg);
rs.status();
#分片集群
var cfg ={"_id":"shad2",
"protocolVersion" : 1,
"members":[
{"_id":1,"host":"127.0.0.1:47017","priority":10},
{"_id":2,"host":"127.0.0.1:47018","priority":0},
{"_id":3,"host":"127.0.0.1:47019","priority":5},
]
};
rs.initiate(cfg);
rs.status();
特别注意配置节点的配置文件有所不同
# 数据库文件位置
dbpath=/data/mongo/config2
#日志文件位置
logpath=/data/mongo/logs/config2.log
# 以追加方式写入日志
logappend=true
# 是否以守护进程方式运行
fork = true
bind_ip=0.0.0.0
port = 17017
# 表示是一个配置服务器
configsvr=true
#配置服务器副本集名称
replSet=configsvr
3 配置和启动路由节点
路由节点的配置
port=17117
bind_ip=0.0.0.0
fork=true
logpath=/env/mogosets/route/route.log
configdb=configsvr/127.0.0.1:17017,127.0.0.1:17018,127.0.0.1:17019
#特别注意这里的命令和上面的启动命令不一样
/env/liyong/install/mongodb/mongodb/bin/mongos -f ./route-17117.conf
4 连接
mongo --host 127.0.0.1 --port 17117
sh.status()
sh.addShard("shard1/27.0.0.1:37017,27.0.0.1:37018,27.0.0.1:370
19");
sh.addShard("shard2/27.0.0.1:47017,27.0.0.1:47018,27.0.0.1:470
19");
sh.status()
5 开启分片
# 为数据库开启分片功能
use admin
db.runCommand( { enablesharding :"myRangeDB"});
# 为指定集合开启分片功能
db.runCommand( { shardcollection : "myRangeDB.coll_shard",key : {_id: 1} } )
6 插入数据并查看情况
use myRangeDB;
for(var i=1;i<= 1000;i++){
db.coll_shard.insert({"name":"test"+i,salary:
(Math.random()*20000).toFixed(2)});
}
db.coll_shard.stats();
sharded true
# 可以观察到当前数据全部分配到了一个shard集群上。这是因为MongoDB并不是按照文档的级别将数据散落在各个分片上的,而是按照范围分散的。也就是说collection的数据会拆分成块chunk,然后分布在不同的shard
# 这个chunk很大,现在这种服务器配置,只有数据插入到一定量级才能看到分片的结果
# 默认的chunk大小是64M,可以存储很多文档
# 查看chunk大小:
use config
db.settings.find()
# 修改chunk大小
db.settings.save( { _id:"chunksize", value: NumberLong(128)} )
7 使用hash分片
use admin
db.runCommand({"enablesharding":"myHashDB"})
db.runCommand({"shardcollection":"myHashDB.coll_shard","key":
{"_id":"hashed"}})
参考资料: 极客时间高级体系课