萌新的SOC学习之AXI-DMA环路测试
AXI DMA环路测试
DMA(Direct Memory Access,直接存储器访问)是计算机科学中的一种内存访问技术。它允许某些计算机内部的硬件子系统可以独立地直接读写系统内存,而不需中央处理器(CPU)介入处理。DMA 是一种快速的数据传送方式,通常用来传送数据量较多的数据块,很多硬件系统会使用 DMA,包括硬盘控制器、绘图显卡、网卡和声卡,在使用高速 AD/DA 时使用 DMA 也是不错的选择。
DMA 是所有现代计算机的重要特色,它允许不同速度的硬件设备进行沟通,而不需要依于中央处理器的大量中断负载。否则,中央处理器需要从来源把每一片段的数据复制到寄存器,然后把它们再次写回到新的地方。在这个时间里,中央处理器就无法执行其它的任务。DMA 是用硬件实现存储器与存储器之间或存储器与 I/O 设备之间直接进行高速数据传输。使用 DMA时,CPU 向 DMA 控制器发出一个存储传输请求,这样当 DMA 控制器在传输的时候,CPU 执行其它操作,传输操作完成时 DMA 以中断的方式通知 CPU。
AXI DMA简介
AXI DMA提供了一个高性能的内存直接访问 在内存和AXI4-stream流 目标内存之间 。[提供了一个可选的(分散/聚集)的功能 可以将CPU从数据搬运中解救出来]
AXI DMA : AXI Direct Memory Access 直接内存访问
AXI DMA为内存和 AXI4-Stream外设之间提供了高带宽的直接内存访问
其可选的S/G 功能 可以将CPU从数据搬运任务中解放出来
为了发起传输事务,DMA 控制器必须得到以下数据:
• 源地址 — 数据被读出的地址
• 目的地址 — 数据被写入的地址
• 传输长度 — 应被传输的字节数
- 为了配置用 DMA 传输数据到存储器,处理器发出一条 DMA 命令
- DMA 控制器把数据从外设传输到存储器或从存储器到存储器,而让 CPU 腾出手来做其它操作。
- 数据传输完成后,向 CPU 发出一个中断来通知它 DMA 传输可以关闭了。ZYNQ 提供了两种 DMA,一种是集成在 PS 中的硬核 DMA,另一种是 PL 中使用的软核 AXI DMA IP。在 ARM CPU 设计的过程中,已经考虑到了大量数据搬移的情况,因此在 CPU 中自带了一个 DMA 控制器 DMAC,这个 DMAC 驻留在 PS 内,而且必须通过驻留在内存中的 DMA 指令编程,这些程序往往由CPU 准备,因此需要部分的 CPU 参与。DMAC 支持高达 8 个通道,所以多个 DMA 结构的核可以挂在单个DMAC 上。DMAC 与 PL 的连接是通过 AXI_GP 接口,这个接口最高支持到 32 位宽度,这也限制了这种模式下的传输速率,理论最高速率为 600MB/s。这种模式不占用 PL 资源,但需要对 DMA 指令编程,会增加软件的复杂性。
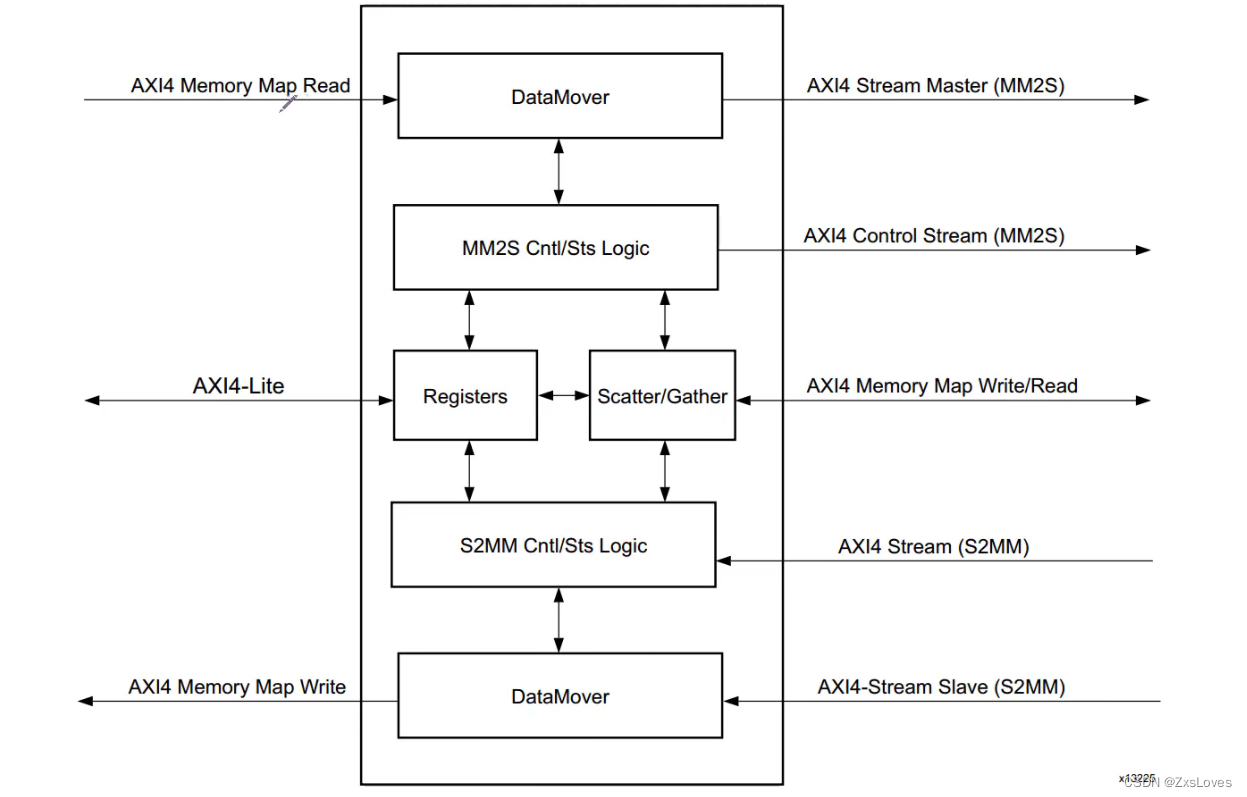
AXI DMA 用到了三种总线,AXI4-Lite 用于对寄存器进行配置,AXI4 Memory Map 用于与内存交互,又分为 AXI4 Memory Map Read 和 AXI4 Memory Map Write 两个接口,一个是读一个是写。AXI4 Stream 接口用于对外设的读写,其中 AXI4 Stream Master(MM2S,Memory Map to Stream)用于对外设写,AXI4-Stream Slave(S2MM,Stream to Memory Map)用于对外设读。总之,在以后的使用中需要知道 AXI_MM2S 和AXI_S2MM 是存储器端映射的 AXI4 总线,提供对存储器(DDR3)的访问。AXIS_MM2S 和 AXIS_S2MM是 AXI4-streaming 总线,可以发送和接收连续的数据流,无需地址。AXI DMA 提供 3 种模式,分别是 Direct Register 模式、Scatter/Gather 模式和 Cyclic DMA 模式,这里我们简单的介绍下常用的 Direct Register 模式和 Scatter/Gather 模式。Direct Register DMA 模式也就是 Simple DMA。Direct Register 模式提供了一种配置,用于在 MM2S 和S2MM 通道上执行简单的 DMA 传输,这需要更少的 FPGA 资源。Simple DMA 允许应用程序在 DMA 和Device 之间定义单个事务。它有两个通道:一个从 DMA 到 Device,另一个从 Device 到 DMA。应用程序必须设置缓冲区地址和长度字段以启动相应通道中的传输。Scatter/Gather DMA 模式允许在单个 DMA 事务中将数据传输到多个存储区域或从多个存储区域传输数据。它相当于将多个 Simple DMA 请求链接在一起。SGDMA 允许应用程序在内存中定义事务列表,硬件将在应用程序没有进一步干预的情况下处理这些事务。在此期间,应用程序可以继续添加更多工作以保持硬件工作。用户可以通过轮询或中断来检查事务是否完成。SGDMA 处理整个数据包(被定义为表示消息的一系列数据字节)并允许将数据包分解为一个或多个事务。例如,采用以太网 IP 数据包,该数据包由 14 字节的报头后跟 1 个或多个字节的有效负载组成。使用 SGDMA,应用程序可以将 BD(Buffer Descriptor,用于描述事务的对象)指向报头,将另一个 BD 指向有效负载,然后将它们作为单个消息传输。这种策略可以使TCP / IP 堆栈更有效,它允许将数据包标头和数据保存在不同的内存区域,而不是将数据包组装成连续的内存块。
AXI DMA 通过 AXI4-lite接口对寄存器做一些配置和获取 。
MM2S : Memory Map to stream 存储器映射(AXI4-Full) 到 AXI4 - Stream
S2MM : Stream to MemoryMap AXI4-Stream 到存储器映射
对于IP核的设计
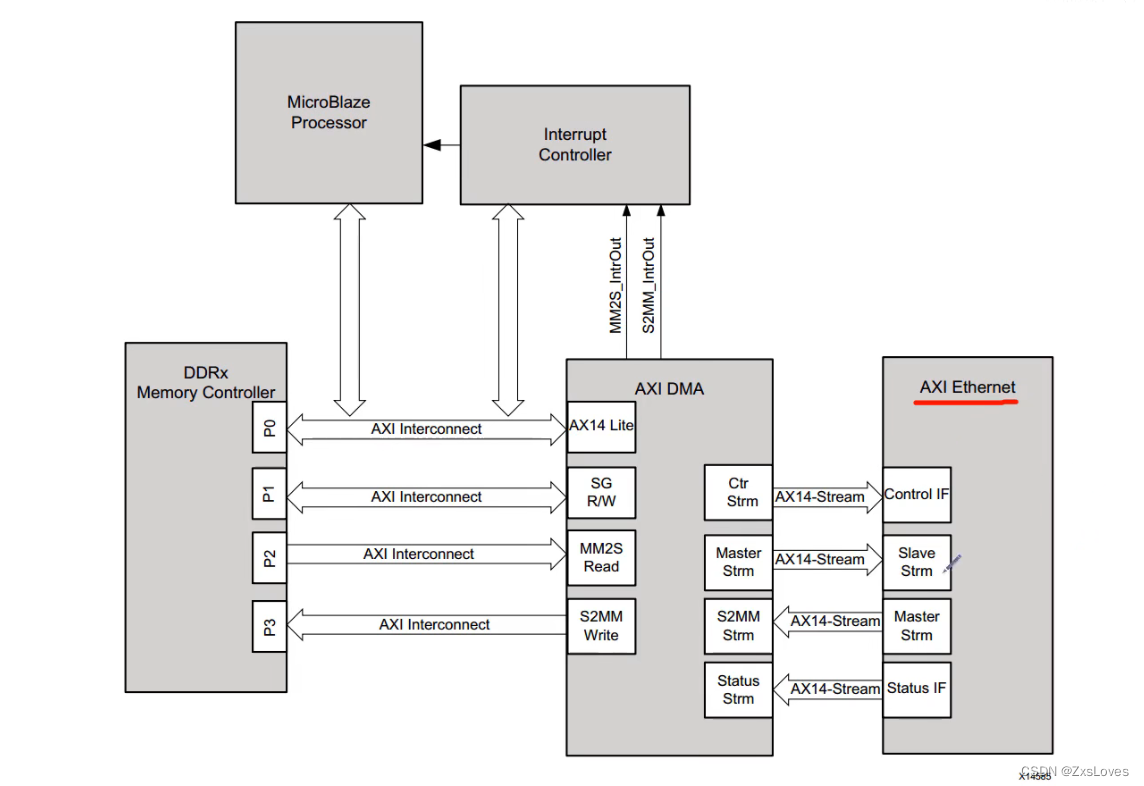
这个是整体的结构框图
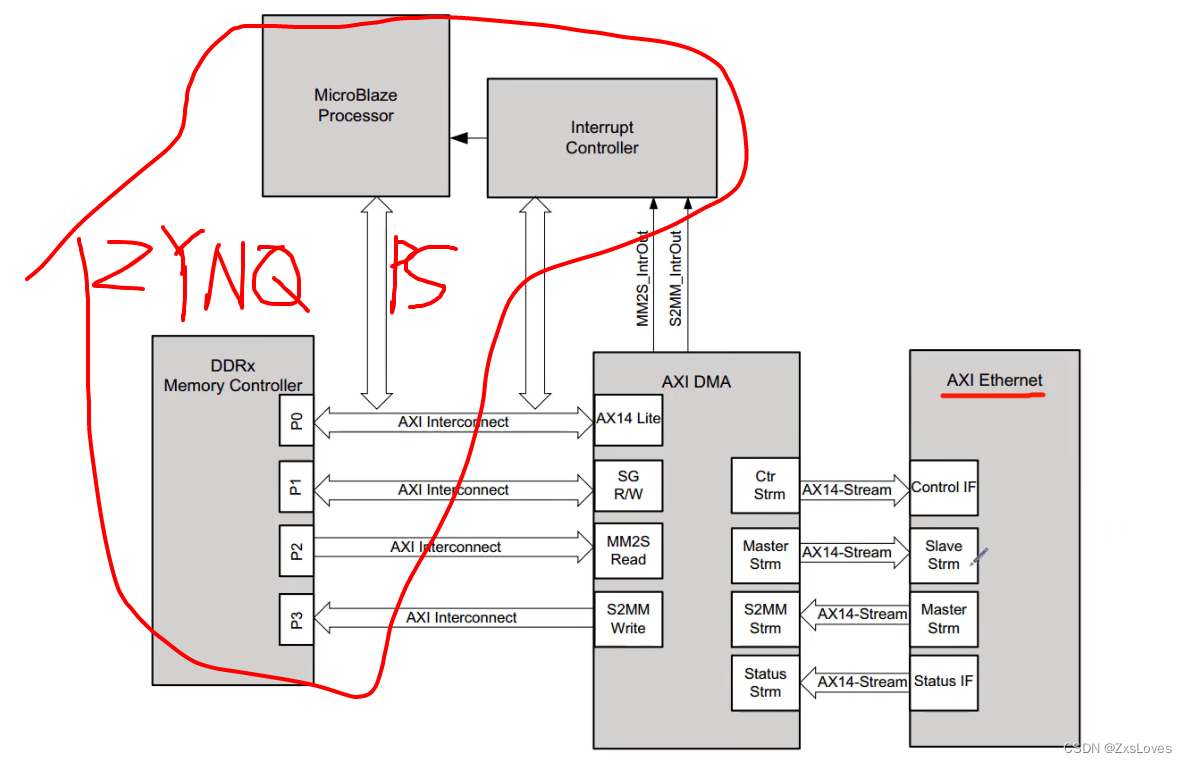
(单一的DMA传输模式
这个模式是我们当前需要的模式 ,也就是(SG模式被disable的情况下的)
为了发起传输事务,DMA 控制器必须得到以下数据:
• 源地址 — 数据被读出的地址
• 目的地址 — 数据被写入的地址
• 传输长度 — 应被传输的字节数)
AXI DMA编程顺序
Direct Register Mode(简单DMA)
此模式提供了在MM2S 和 S2MM 通道上进行简单的DMA传输的配置 ,只需要较少的FPGA资源
我们可以通过访问 DMACR , 源地址 , 或者 目的 地址 和长度寄存器 发起 DMA传输 。当传输完成后,如果使能了产生中断输出, 那么DMASR寄存器相关联的通道位会有效。
对于复位时钟 必须至少保持16个s_axi_lite_aclk
看一下DMA的MM2S(存储器映射到Stream) 通道的启动顺序
1.把MM2S通道 打开
2.使能中断
3. 朝着MM2S_SA 寄存器中写一个有效的源地址 (如果AXI DMA 没有配置一个数据重对齐的选项的话 , 这个有效的地址必须进行对齐 否则会产生未定义的结果 ) (这里就是说如果在写地址的时候 DRE被使能了,那么就可以写成任意地址 。如果DRE没有被使能 ,那么只能写成4的倍数)
4. 朝着MM2S_LENGTH 寄存器写传输的字节数 (这个必须是最后一个进行配置,其他的没有顺序要求)
一个长度为0的值是无效的,一个非0 的值将会决定存储器映射到Stream流的数据个数 。
S2MM通道顺序
1.差不多
SG模式
它把传输的基本参数,存储在内存中;
这些参数被称为BD(Buffer Descriptor)
在工作时,通过SG接口加载和更新BD中的状态
axi 时钟的同步和异步的选择 并不是简单的通过对axi_dma进行配置 而是通过对外部的连线 完成时钟 假设连接在不同的时钟频率,就是异步了
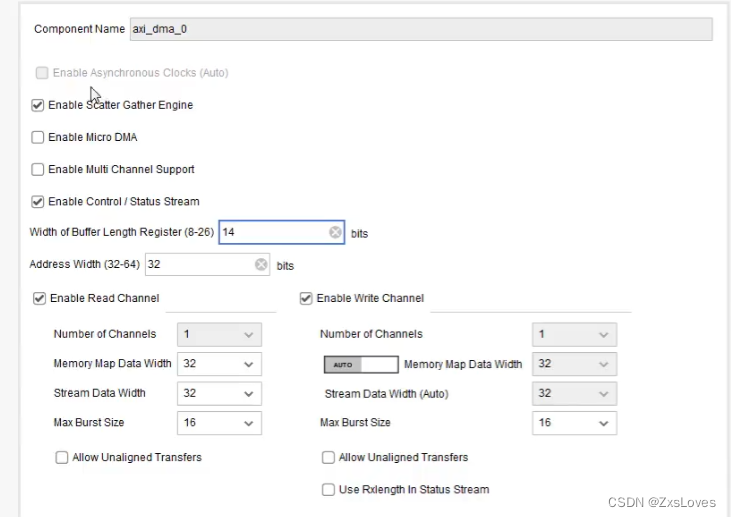
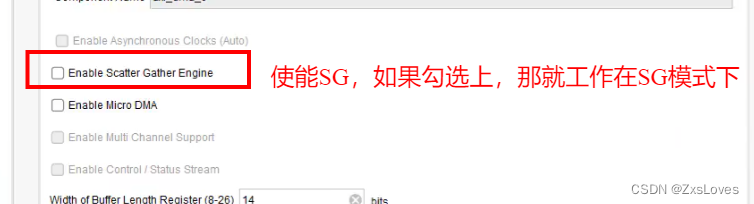
一般用在传输非常少量数据的情况下

指派的数据位宽 也就是说2的多少次方

指定地址位宽
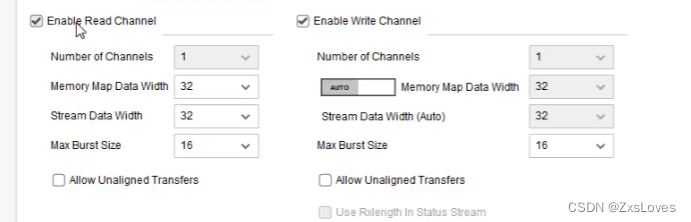
使能读 和 使能写
Memory Map Data Width 指的是 memory map 这一侧的数据位宽
Stream Data Width 值的是stream 流的数据位宽
最大突发大小 影响的AXI4
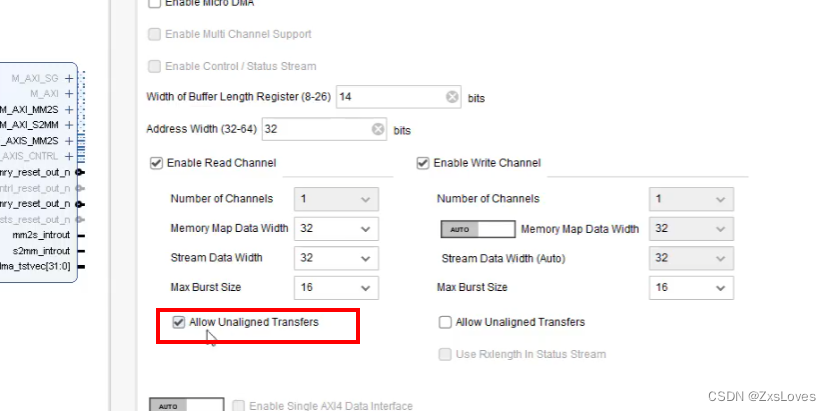
是否使能对齐 如果勾选 就可以任意给定 不勾选 就是4的倍数
AXI DMA环路实验
本章的实验任务是在领航者ZYNQ开发板上使用PL的AXI DMA IP核从DDR3 中 读取数据,并将数据写回到DDR3中
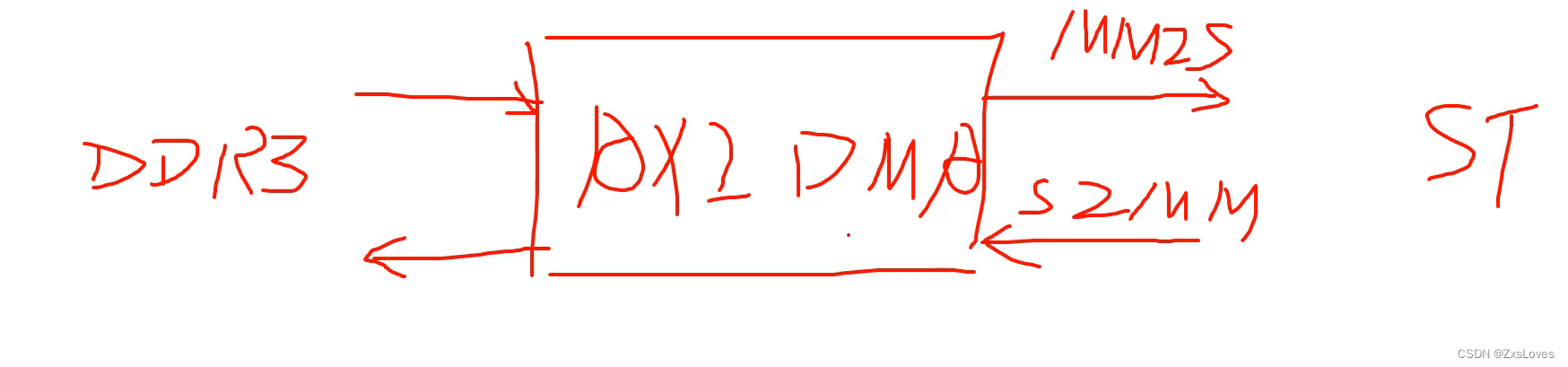
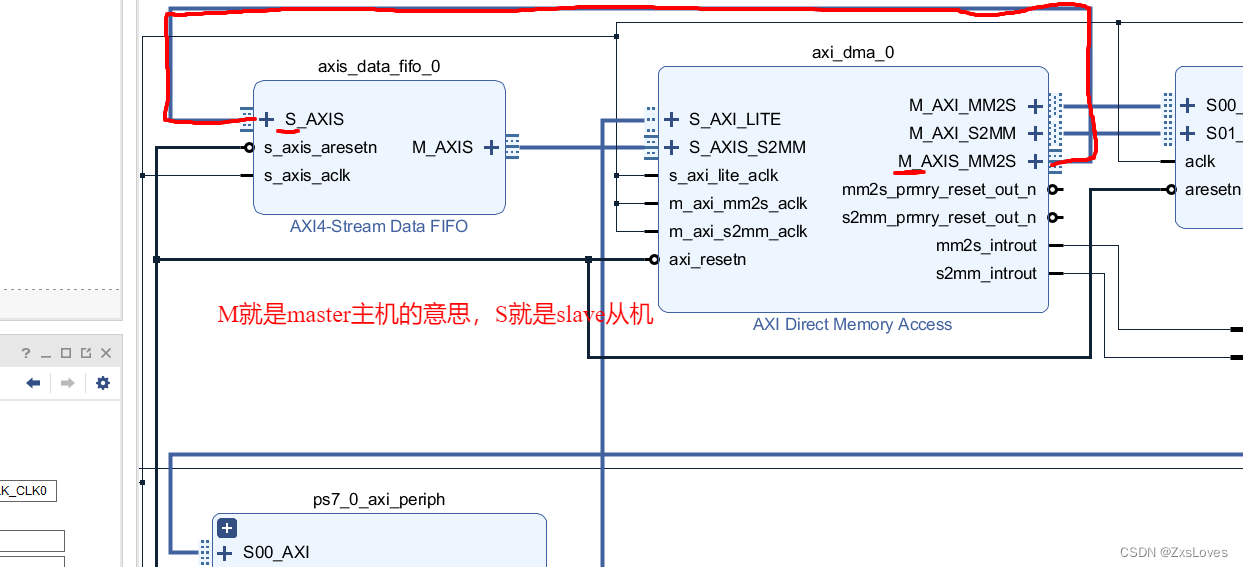
我们下面来观察整个设计的系统框图
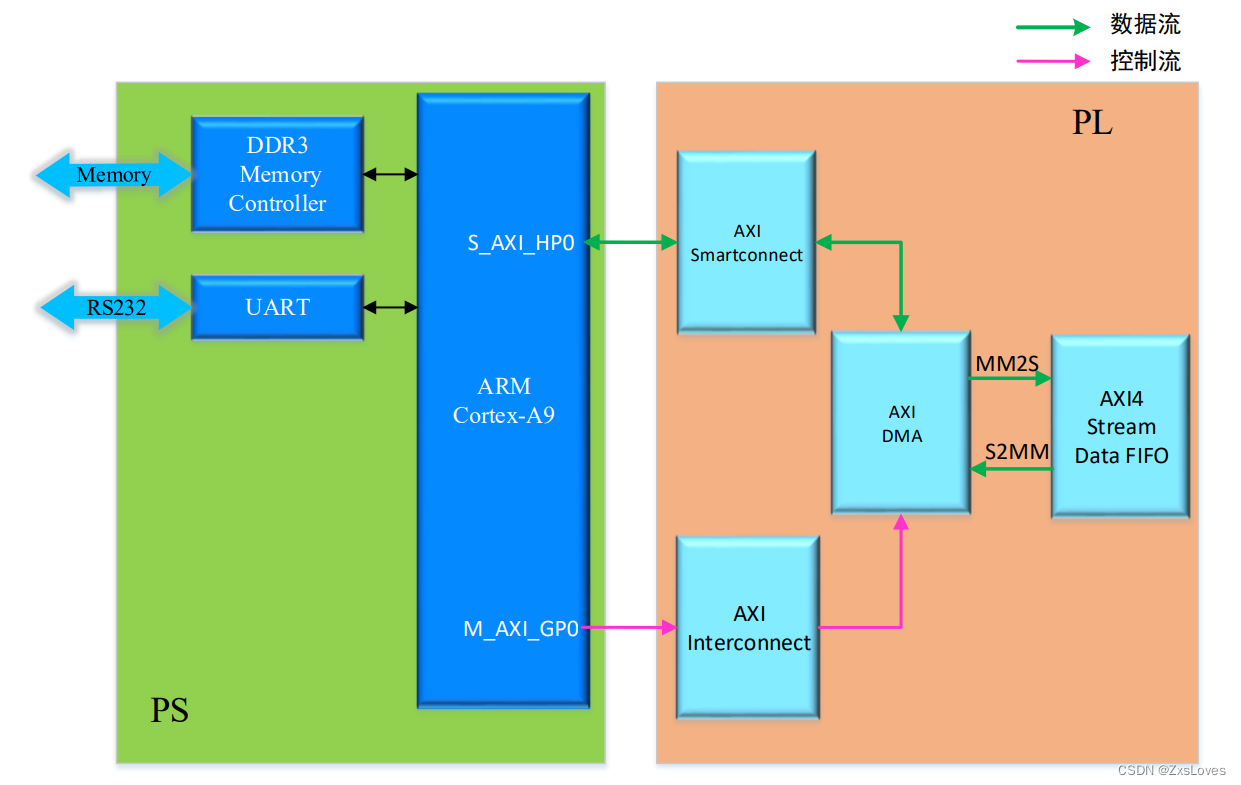
上面的走向是数据流的走向
下面的走向是控制流的走向
我们可以不经过AXI4的外设 将两端的信号 连接在一起
我们需要通过 concat接口 将两个中断信号连接到一起

总体连接
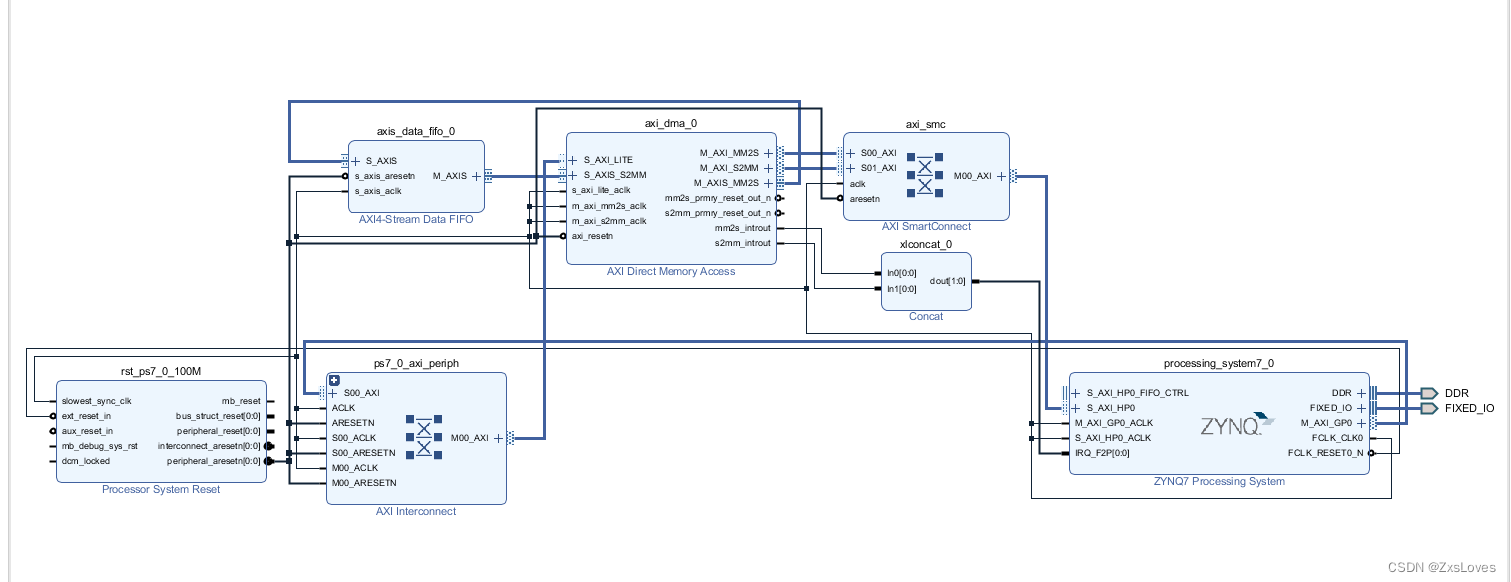
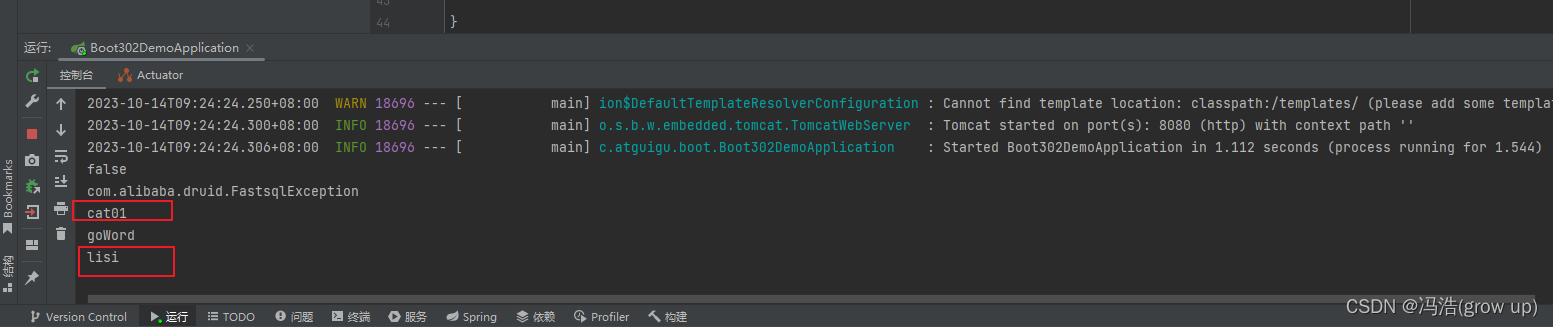
在代码的第 14 行,我们重新宏定义了 XPAR_PS7_DDR_0_S_AXI_BASEADDR,即 DDR3 的基址,打开 XPAR_PS7_DDR_0_S_AXI_BASEADDR 的定义处,我们可以看到 DDR3 的基址为 0x00100000

![2023年中国改性聚乙烯产能、产量及市场规模现状分析[图]](https://img-blog.csdnimg.cn/img_convert/8dc35a1941a21d7fdfa34cc75ab13618.png)
![[12 种安卓数据恢复方案] 最佳免费 Android 照片恢复工具榜单](https://img-blog.csdnimg.cn/img_convert/fd15a460a99b31013b28d5b2eb354bea.jpeg)