目录
- 问题描述
- 问题分析
- 问题解决
问题描述
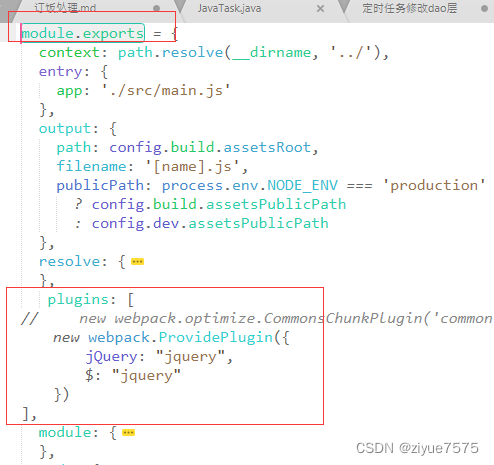
我在保存模型结构的时候,先获取模型参数,然后再保存,代码如下:
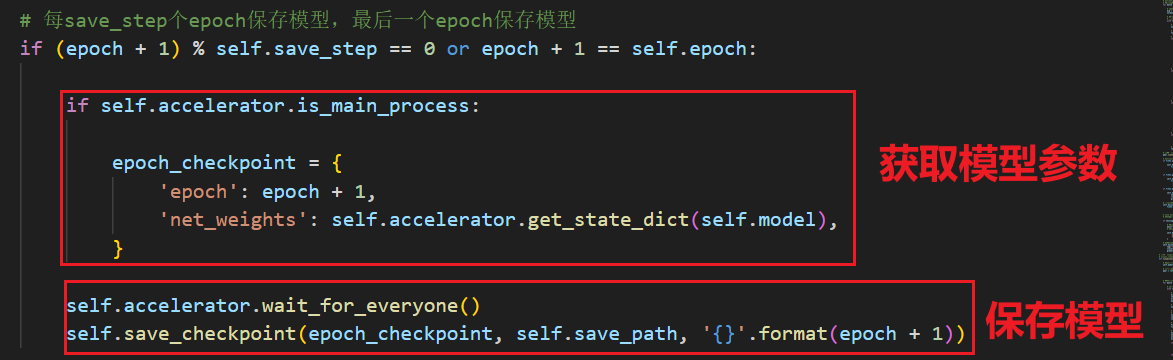
图示代码是在训练主循环中的:
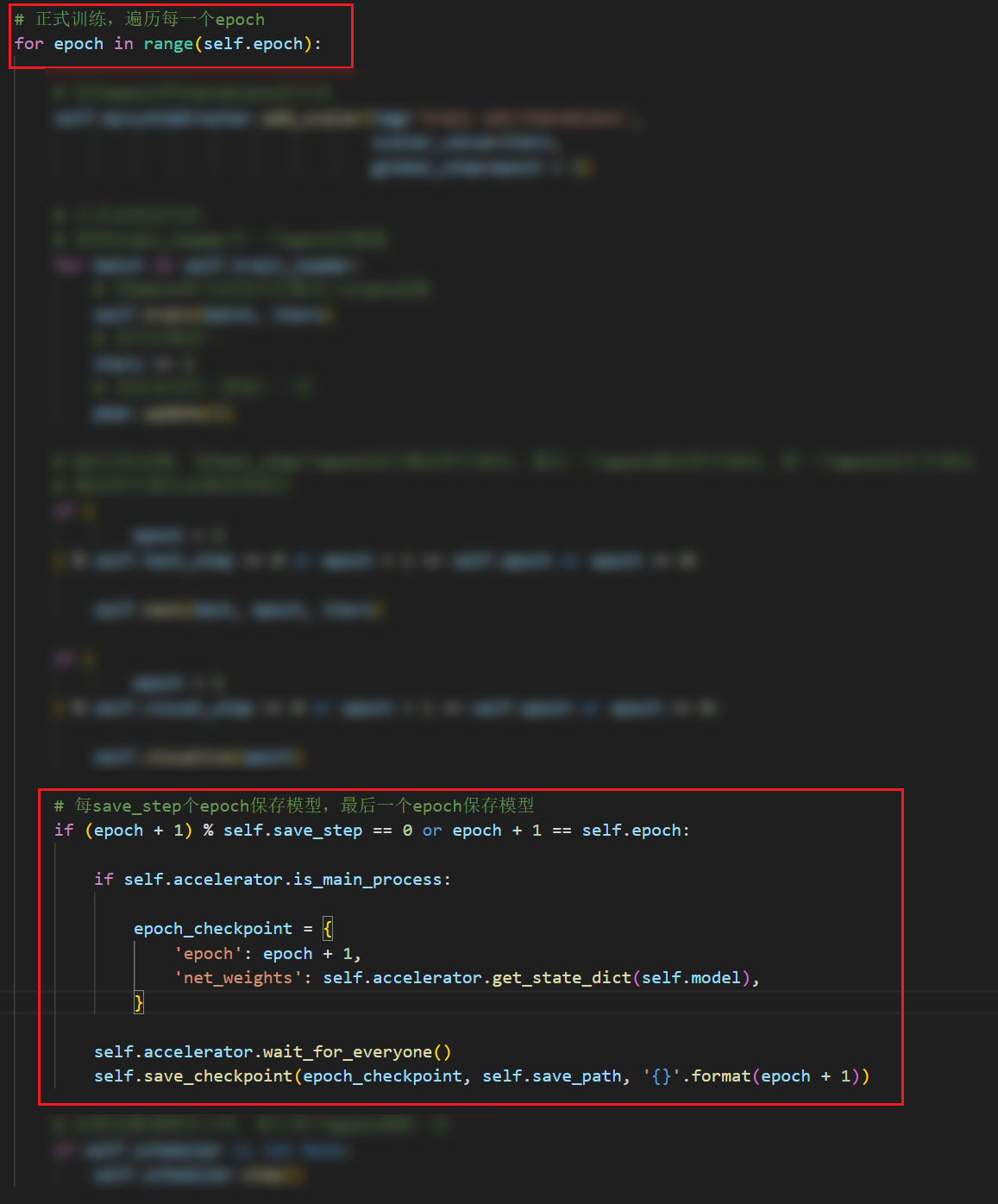
这种情况下会出现报错:
nboundLocalError: UnboundLocalErrorlocal variable 'epoch checkpoint’referenced before assignment:
完整报错:


简单来说就是我用于存储模型的函数有一个输入参数是epoch_checkpoint,但是python认为我在引用这个变量前没有定义(分配)这个变量。
这就很奇怪,因为我的代码明明在我使用这个变量前是幅值定义了的。
问题分析
我经过思考,认为在单GPU训练的时候是不会出现这种问题的,因为我确实先定义了变量再引用的变量,那么应该是多GPU训练出现的问题。
在accelerate库中进行多GPU训练的时候,通过开启多个进程来控制多个GPU,可能是多个进程中,主进程还在获取模型参数那一步,其他进程就已经到了保存模型这一步,导致出现这个报错。
(当然我这个分析也不一定对,毕竟我再保存模型前用了self.accelerator.wait_for_everyone(),理论上不应该出现这个报错的)
问题解决
虽然不知道问题到底是为啥出现,但是我们也有解决方法:
即先在主循环中获取模型参数,不进行模型保存,在最后再保存模型
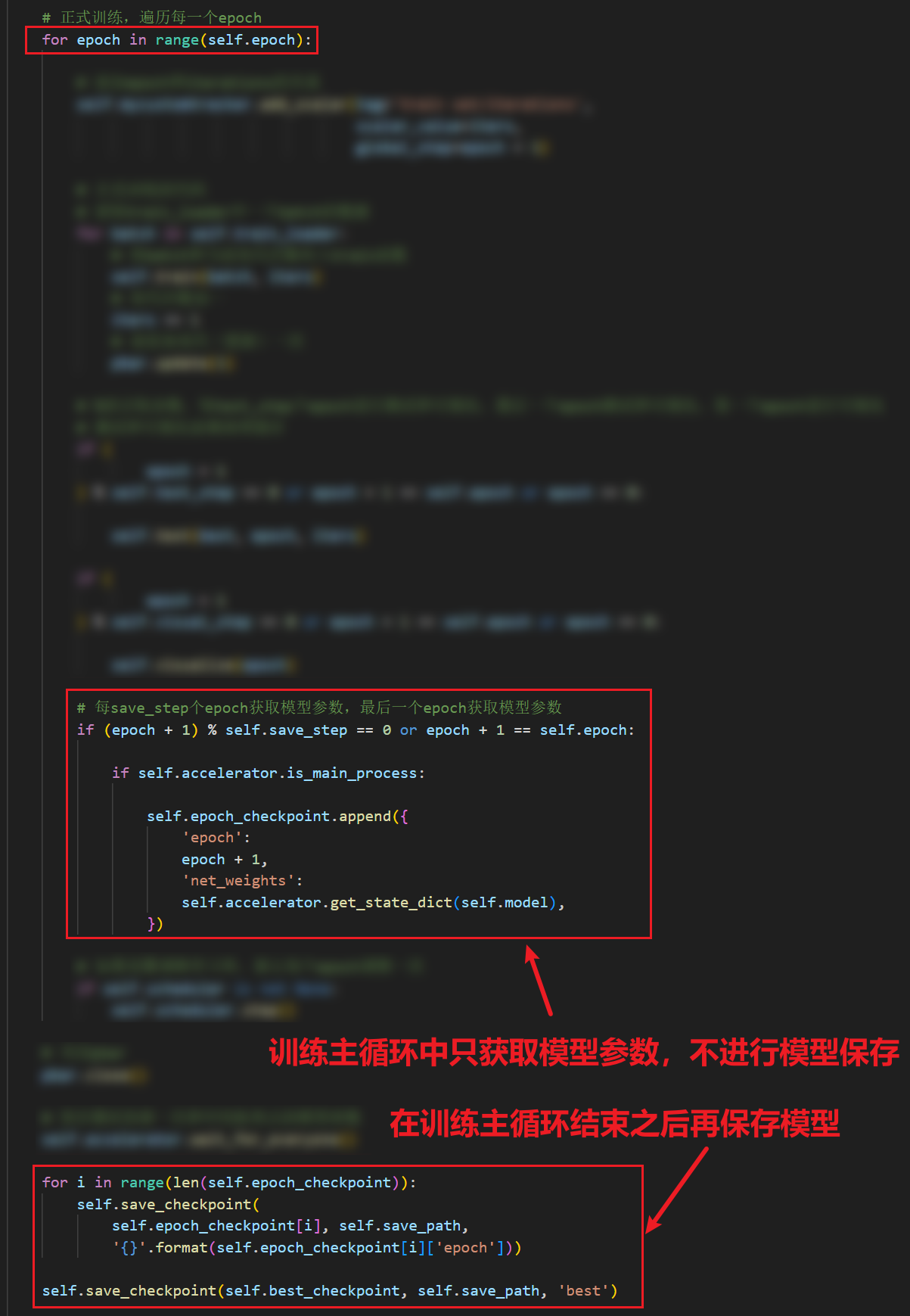
这样做需要事先定义一个list,存储检查点