实体的艺术表现斯特凡·伯克纳
一、说明
实体解析是确定数据集中的两条或多条记录是否引用同一现实世界实体(通常是个人或公司)的过程。乍一看,实体分辨率可能看起来像一个相对简单的任务:例如,给定一张人物的两张照片,即使是一个小孩子也可以确定它是否以相当高的精度显示同一个人。计算机也是如此:比较包含姓名、地址、电子邮件等属性的两条记录可以很容易地完成。然而,深入探讨该主题,它就越具有挑战性:需要评估各种匹配算法,处理数百万或数十亿条记录意味着二次复杂性,更不用说实时和数据删除用例了。
二、模糊文本匹配
让我们从比较著名艺术家文森特梵高的两张唱片开始——还是梵高?

第二条记录中有一些错误(除了一个世纪后出生和电子邮件地址):姓名拼写错误,出生日期混淆,邮政编码丢失,电子邮件地址略有不同。
那么我们如何比较这些值呢?如果,假设名称相等,那么对这些值进行简单的字符串比较就足够了。由于情况并非如此,我们需要一些更高级的模糊匹配。有许多不同的算法可用于基于文本的模糊匹配,它们可以大致分为三组。语音算法侧重于文本的发音相似程度。最著名的算法是Soundex和Metaphone,它们主要用于英语文本,但其他语言也存在这些算法的变体,例如德语的Kölner Phonetik(科隆语音)。文本距离算法通常定义文本需要更改多少个字符才能到达其他文本。Levenshtein和Hamming距离是该组中两个众所周知的算法。相似性算法,如余弦相似性或杰卡德指数,计算文本的结构相似性,通常以百分比表示相似性。
出于本文的目的,我们将使用一种非常简单的方法,仅使用名称上的Levenshtein距离和城市的相等性。此示例和以下所有示例将使用 golang 作为编程语言,并尽可能使用现有库。将其转换为python,java或任何其他语言应该是微不足道的。此外,它只会对 name 属性执行匹配。添加更多属性甚至使其可配置不是本文的目的。
package main
import (
"fmt"
"github.com/hbollon/go-edlib"
)
type Record struct {
ID int
Name string
City string
}
func matches(a, b Record) bool {
distance := edlib.LevenshteinDistance(a.Name, b.Name)
return distance <= 3 && a.City == b.City
}
func main() {
a := Record{
Name: "Vincent Van Gogh",
City: "Paris",
}
b := Record{
Name: "Vince Van Gough",
City: "Paris",
}
if matches(a, b) {
fmt.Printf("%s and %s are probably the same person\n", a.Name, b.Name)
} else {
fmt.Printf("%s and %s are probably not the same person\n", a.Name, b.Name)
}
}在围棋游乐场尝试:Go Playground - The Go Programming Language
两个名字之间的列文森距离正好是3。这是因为,还有三个附加字符(名字中的“en”和姓氏中的“u”)。请注意,这适用于此特定输入。然而,它离完美还很远。例如,“Joe Smith”和“Amy Smith”这两个名字的Levenshtein距离也是三个,但显然不是同一个人。将距离算法与语音算法相结合可以解决这个问题,但这超出了本文的范围。
使用基于规则的方法而不是基于 ML 的方法时,选择为您的使用案例产生最佳结果的正确算法是业务成功的最关键方面。这是您应该花费大部分时间的地方。不幸的是,正如我们现在将发现的那样,如果您决定自己开发实体解析引擎,还有很多其他事情会分散您优化这些规则的注意力。
三、朴素实体解析
现在我们知道了如何比较两个记录,我们需要找到彼此匹配的所有记录。最简单的方法是简单地将每条记录与所有其他记录进行比较。出于此示例的目的,我们使用随机选择的名称和城市。对于名称,我们最多强制三个错误(用 x 替换任何字符)。
var firstNames = [...]string{"Wade", "Dave", "Seth", "Ivan", "Riley", "Gilbert", "Jorge", "Dan", "Brian", "Roberto", "Daisy", "Deborah", "Isabel", "Stella", "Debra", "Berverly", "Vera", "Angela", "Lucy", "Lauren"}
var lastNames = [...]string{"Smith", "Jones", "Williams", "Brown", "Taylor"}
func randomName() string {
fn := firstNames[rand.Intn(len(firstNames))]
ln := lastNames[rand.Intn(len(lastNames))]
name := []byte(fmt.Sprintf("%s %s", fn, ln))
errors := rand.Intn(4)
for i := 0; i < errors; i++ {
name[rand.Intn(len(name))] = 'x'
}
return string(name)
}
var cities = [...]string{"Paris", "Berlin", "New York", "Amsterdam", "Shanghai", "San Francisco", "Sydney", "Cape Town", "Brasilia", "Cairo"}
func randomCity() string {
return cities[rand.Intn(len(cities))]
}
func loadRecords(n int) []Record {
records := make([]Record, n)
for i := 0; i < n; i++ {
records[i] = Record{
ID: i,
Name: randomName(),
City: randomCity(),
}
}
return records
}
func compare(records []Record) (comparisons, matchCount int) {
for _, a := range records {
for _, b := range records {
if a == b {
continue // don't compare with itself
}
comparisons++
if matches(a, b) {
fmt.Printf("%s and %s are probably the same person\n", a.Name, b.Name)
matchCount++
}
}
}
return comparisons, matchCount
}
func main() {
records := loadRecords(100)
comparisons, matchCount := compare(records)
fmt.Printf("made %d comparisons and found %d matches\n", comparisons, matchCount)
}在围棋游乐场尝试:Go Playground - The Go Programming Language
您应该看到一些类似的输出(如果您没有得到随机数据的任何匹配项,您可能需要多次运行它):
Daisy Williams and Dave Williams are probably the same person
Deborax Browx and Debra Brown are probably the same person
Riley Brown and RxxeyxBrown are probably the same person
Dan Willxams and Dave Williams are probably the same person
made 9900 comparisons and found 16 matches如果幸运的话,您还会得到像“黛西”和“戴夫”这样的不匹配。这是因为我们使用的 Levenshtein 距离为 3,作为短名称的唯一模糊算法,这是高的方式。请随时自行改进。
性能方面,真正有问题的一点是获得结果所需的 9,900 次比较,因为输入量加倍将大约使所需比较量翻两番。39 条记录需要 800,200 次比较。对于只有 100,000 条记录的少量数据,这意味着需要近 10 亿次比较。无论您的系统有多大,随着数据量的增长,系统都将无法在可接受的时间内完成此操作。
一个快速但几乎无用的优化是不对每个组合进行两次比较。我们将 A 与 B 进行比较或将 B 与 A 进行比较应该无关紧要。然而,这只会减少因子 2 所需的比较量,由于二次增长,这是可以忽略的。
四、通过阻塞降低复杂性
如果我们查看我们创建的规则,我们很容易注意到,如果城市不同,我们将永远不会有匹配。所有这些比较都是完全浪费的,应该加以防止。将您怀疑相似的记录放入公共存储桶中,而将其他不相同的记录放入另一个存储桶中,在实体解析中称为阻塞。由于我们想使用城市作为我们的阻塞键,因此实现相当简单。
func block(records []Record) map[string][]Record {
blocks := map[string][]Record{}
for _, record := range records {
blocks[record.City] = append(blocks[record.City], record)
}
return blocks
}
func main() {
records := loadRecords(100)
blocks := block(records)
comparisons := 0
matchCount := 0
for _, blockRecords := range blocks {
c, m := compare(blockRecords)
comparisons += c
matchCount += m
}
fmt.Printf("made %d comparisons and found %d matches\n", comparisons, matchCount)
}在围棋游乐场尝试:Go Playground - The Go Programming Language
现在的结果将是相同的,但我们只有大约十分之一的比较,因为我们有十个不同的城市。在实际应用中,由于城市的差异要大得多,这种影响会大得多。此外,每个块可以独立于其他块进行处理,例如在相同或不同的服务器上并行处理。
找到正确的阻止密钥本身就是一个挑战。使用像城市这样的属性可能会导致分布不均匀,因此会导致一个巨大的区块(例如大城市)比所有其他区块花费更长的时间。或者城市包含微小的拼写错误,不再被视为有效匹配。使用多个属性和/或使用拼音键或 q-gram 作为阻塞键可以解决这些问题,但会增加软件的复杂性。
五、从匹配项到实体
到目前为止,关于我们的记录,我们只能说,其中两个是否匹配。对于非常基本的用例,这可能已经足够了。但是,在大多数情况下,您想知道属于同一实体的所有匹配项。这可以从简单的星形模式,其中 A 与 B、C 和 D 匹配,到 A 匹配 B、B 匹配 C 和 C 匹配 D 的链状模式,到非常复杂的图形模式。这种所谓的传递记录链接可以使用连接的组件算法轻松实现,只要所有数据都适合单个服务器上的内存。同样,在实际应用中,这更具挑战性。
func compare(records []Record) (comparisons int, edges [][2]int) {
for _, a := range records {
for _, b := range records {
if a == b {
continue // don't compare with itself
}
comparisons++
if matches(a, b) {
edges = append(edges, [2]int{a.ID, b.ID})
}
}
}
return comparisons, edges
}
func connectedComponents(edges [][2]int) [][]int {
components := map[int][]int{}
nextIdx := 0
idx := map[int]int{}
for _, edge := range edges {
a := edge[0]
b := edge[1]
aIdx, aOk := idx[a]
bIdx, bOk := idx[b]
switch {
case aOk && bOk && aIdx == bIdx: // in same component
continue
case aOk && bOk && aIdx != bIdx: // merge two components
components[nextIdx] = append(components[aIdx], components[bIdx]...)
delete(components, aIdx)
delete(components, bIdx)
for _, x := range components[nextIdx] {
idx[x] = nextIdx
}
nextIdx++
case aOk && !bOk: // add b to component of a
idx[b] = aIdx
components[aIdx] = append(components[aIdx], b)
case bOk && !aOk: // add a to component of b
idx[a] = bIdx
components[bIdx] = append(components[bIdx], a)
default: // create new component with a and b
idx[a] = nextIdx
idx[b] = nextIdx
components[nextIdx] = []int{a, b}
nextIdx++
}
}
cc := make([][]int, len(components))
i := 0
for k := range components {
cc[i] = components[k]
i++
}
return cc
}
func main() {
records := loadRecords(100)
blocks := block(records)
comparisons := 0
edges := [][2]int{}
for _, blockRecords := range blocks {
c, e := compare(blockRecords)
comparisons += c
edges = append(edges, e...)
}
cc := connectedComponents(edges)
fmt.Printf("made %d comparisons and found %d matches and %d entities\n", comparisons, len(edges), len(cc))
for _, component := range cc {
names := make([]string, len(component))
for i, id := range component {
names[i] = records[id].Name
}
fmt.Printf("found the following entity: %s from %s\n", strings.Join(names, ", "), records[component[0]].City)
}
}在围棋游乐场尝试:Go Playground - The Go Programming Language
连接的组件功能遍历所有边,然后创建新组件、将新 id 添加到现有组件或将两个组件合并为一个组件。结果如下所示:
made 1052 comparisons and found 6 matches and 2 entities
found the following entity: Ivan Smxth, Ixan Smith, Ivax Smitx from Cairo
found the following entity: Brxan Williams, Brian Williams from Cape Town保持这些边缘给我们带来了一些优势。我们可以使用它们来使生成的实体易于理解和解释,理想情况下,即使有一个漂亮的 UI 来显示实体的记录是如何连接的。或者,在使用实时实体解析系统时,我们可以使用边缘在删除数据时拆分实体。或者,您在构建图神经网络 (GNN) 时使用它们,从而获得更好的 ML 结果,而不仅仅是记录。
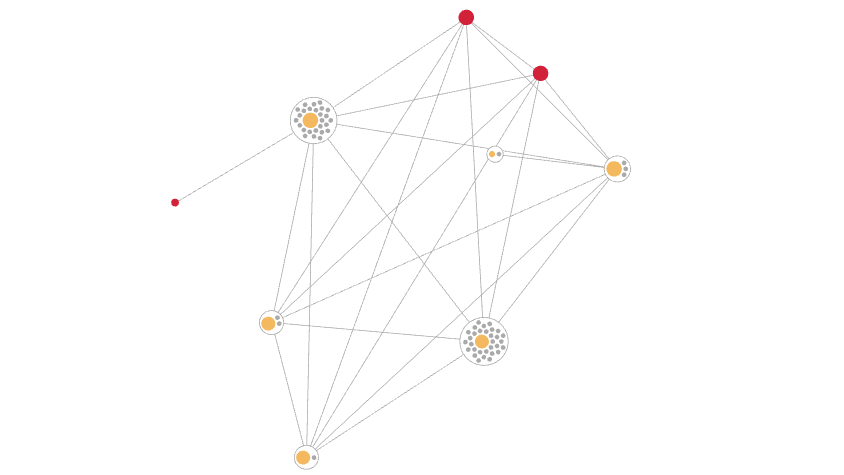
实体的可视化表示(作者图片)
当有很多非常相似的记录时,可能会出现一个来自边缘的问题。例如,如果 A 与 B 匹配,B 与 C 匹配,则 C 也可能与 A 匹配,具体取决于使用的规则。如果 D、E、F 等也与现有记录匹配,那么我们又回到了二次增长问题,很快导致如此多的边变得不再可处理。
还记得我们是如何构建阻塞桶的吗?惊喜!对于非常相似的数据,这些数据最终都集中在几个巨大的桶中,计算性能再次急剧下降——即使您遵循了之前从多个属性创建桶的建议。
这种不相同的重复项的典型示例是有人定期在同一家商店订购,但具有来宾访问权限(抱歉,没有很好的客户 ID)。该人可能几乎总是使用相同的送货地址,并且大多能够正确写下自己的名字。因此,应以特殊方式处理这些记录,以确保稳定的系统性能,但这本身就是一个主题。
在你对所获得的知识感到太舒服并想开始实施自己的解决方案之前,让我快速粉碎你的梦想。我们还没有讨论实时执行任何操作的挑战。即使你认为你不需要一个总是最新的实体(显而易见的好处),实时方法也会产生进一步的价值:你不需要一遍又一遍地做同样的计算,而只需要对新数据。另一方面,实现起来要复杂得多。想要阻止?将新记录与其所属存储桶的所有记录进行比较,但这可能需要一段时间,并且可以被视为增量批处理。同样在最终完成之前,还有大量新记录等待处理。想要使用连接的组件计算实体?当然,将整个图形保留在内存中,只需添加新的边。但是不要忘记跟踪由于新记录而刚刚合并在一起的两个实体。
因此,您仍然愿意自己实现这一点。你做出了(在这种情况下)明智的决定,不存储边缘,不支持实时。因此,您成功地运行了包含所有数据的第一个实体解析批处理作业。这花了一段时间,但你每个月只会这样做一次,所以这很好。当您看到您的数据保护官跑到拐角处并告诉您由于GDPR投诉而从数据集中删除该人时,可能就在那时。因此,您再次为单个已删除的实体运行整个批处理作业 — 耶。
六、结论
进行实体解析乍一看可能相当简单,但它包含许多重大的技术挑战。其中一些可以简化和/或忽略,但其他问题需要解决以获得良好的性能。