峰会官网已上线,最新议程请关注:doris-summit.org.cn 点击报名 先到先得

本文导读:
随着网络直播规模的不断扩大,在线知识服务在直播行业中迎来了广阔的发展机遇。小鹅通作为一家以用户服务为核心的技术服务商,通过多平台直播与推流服务吸引和转化潜在用户,同时通过直播数据分析平台,帮助商家分析直播指标数据、分析用户观看情况、构建精准用户画像。然而,随着直播用户数量的激增,平台在写入和查询方面的支持逐渐无法满足业务需求,为了应对挑战,小鹅通开启了架构升级之旅。本文将详细介绍小鹅通直播数据分析平台的优化过程,分享小鹅通基于Apache Doris 优化写入与查询性能、完善用户标签功能和保障平台稳定性等实践经验,为商家提供了更精细化的用户经营支持。作者|小鹅通 大数据开发工程师 宫贺
深圳小鹅网络技术有限公司,是一家以知识产品与用户服务为核心的技术服务商,创始至今已累计生产了 2000 万个知识产品,已服务的商家规模达 160 万,其中不乏腾讯学堂、华夏基金、西贝、吴晓波频道、十点读书、凯撒旅游等各行业一线知名品牌。作为私域运营的一站式工具,针对商家业务痛点,小鹅通提供了多方面的闭环解决方案,包括产品与服务交付、营销获客、用户运营、组织角色管理、品牌价值输出等以实现业务升级。

随着“直播带货”消费模式的兴起,网络直播规模的持续上升,在线知识服务开始在直播行业中开拓广袤发展领域,借助直播工具的力量能够有效吸引和转化潜在用户,借助直播分析平台能够实现对 C 端用户数据留存与分析,助力 B 端商家客户的精细化用户运营。
在这一背景下,小鹅通直播为商家提供了多平台的直播与推流服务,以及多种直播带货的营销玩法,不仅能将公私域流量引导至直播间,实现商家引流目标,还提供了多维度的分析平台。商家可以通过直播数据分析平台导出和分析各项直播数据指标,生成用户标签,以了解用户观看直播的情况和动态、构建精准的用户画像。
目前,小鹅通直播场次已累积达 600 万次,终端用户数近 8 亿,最高同时在线观看人数超过 1000 万。然而,面对直播用户数量激增,直播数据分析平台在数据写、查方面的支持逐渐无法满足业务需求,我们希望能够借助分析平台掌握直播间在线人数、在线时长、商品转化率、交易额等数据,并在直播间波峰波谷时期记录以上数据的流量趋势图。为了满足上述的业务需求,小鹅通对于平台架构提出更高的性能要求:
- 写入性能:需具备海量数据实时写入的能力,确保在直播过程中高吞吐场景下数据稳定导入;
- 数据更新:为了应对直播期间交易状态和用户数据的变化,我们需要架构具备高效准确的更新机制,确保业务人员及时掌握最新数据;
- 查询性能:能够支持高并发点查,也能满足联邦查询的需求,保证不同查询场景下数据分析的时效性;
- 平台运维:由于直播业务具有明显的波峰波谷时段,分析平台需要确保在直播高峰时段保持稳定的运行状态。同时,在波谷时段,平台应该支持节点弹性缩容,以提高资源利用率并控制运维成本。此外,为了避免系统运行故障导致站点破坏、为了保持系统高可用性,架构还需要提供可靠的灾备方案,以确保业务连续。
在遭遇系统业务瓶颈后,小鹅通开启了平台基础建设重构之旅,在经过业务调研、选型对比和内测应用后,基于 Apache Doris 对最初 Elasticsearch 与 HBase 的架构进行了迭代升级,并于今年 5 月份正式上线 Apache Doris 版本的直播数据分析平台。
本文将详细介绍小鹅通直播数据分析平台的优化过程,分享小鹅通如何基于 Apache Doris 提升平台查询性能、完善用户标签功能、保障平台稳定性等实践经验,最终赋能商家精细化用户经营。
基于 Elasticsearch 与 HBase 早期架构
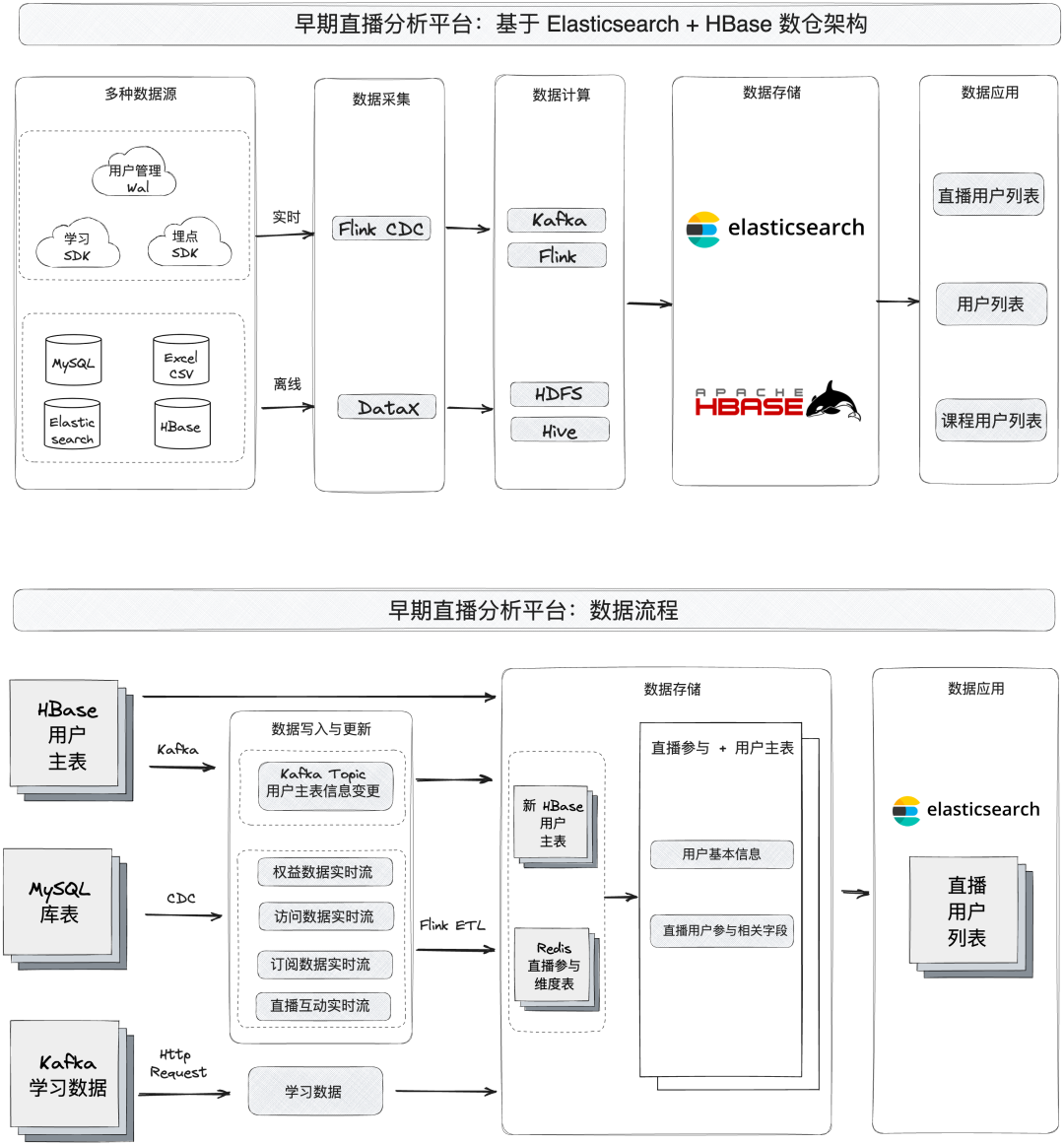
直播数据分析平台的原始数据主要来源于 MySQL 的业务数据库、学习 SDK、埋点 SDK,平台架构主要分为离线与实时链路:
- 离线链路:用户相关的数据通过 DataX 采集并全量存储于 HDFS ,由 Hive 计算写入 HBase,形成用户基本信息的主表。
- 实时链路:MySQL 业务库与学习 SDK 中的相关指标数据(例如实时订阅、访问、直播互动、用户权益等)通过 Flink CDC 采集后上报至 Kafka,利用 Flink 实时计算并存入 Redis 中。
两类数据依据业务需求,将用户基本信息与直播相关业务指标关联,形成直播参与用户大宽表,其中当权益、订阅等主业务数据发生变更时,需要与 HBase 中的用户维表进行关联补全数据。数据每次更新都会在宽表补全后,将所有字段一起发送至下游 Elasticsearch 来承载业务人员的查询需求,避免并发修改的情况。
随着直播用户规模的扩大,我们对于数据时效性、查询性能等方面要求逐渐升高,而原架构的局限性也逐渐影响业务分析需求:
- 数据流转时效性低:由于组件过多,导致计算链路过长、节点过多,写入与查询的时效性也必然会受到影响,无法支撑直播波峰时段的实时导入与极速分析。
- 数据更新链路复杂:直播数据每次发生变更时,都需要先将变更数据写入主表与维度表中,随后重新关联生成新的宽表以覆盖旧数据。这一过程涉及多个组件和长链路,更新机制的复杂度与低效也随之增加。
- 查询性能不足:在高并发查询场景下,Elasticsearch 需要处理大量的查询请求和数据访问,导致查询负载过重,分析效率低;在关联查询场景下,Elasticsearch 无法满足 Join 计算需求,查询灵活度低。
- 架构运维成本高:组件过多还会导致整体架构运维成本升高、开发人员学习成本加大、指标扩展较为局限等问题。
基于以上架构痛点,我们在 2022 年 7 月开启系统重构项目的调研工作,最终在众多数据仓库中选择了 Apache Doris 进行架构升级,并在同年 11 月开启长达 6 个月的内测工作,希望借助 Apache Doris 在实时写入、数据高效更新、极速查询性能和简易运维等方面的优势,在直播数据分析场景中强化直播用户数据挖掘,获取更多高价值的业务洞察。
基于 Apache Doris 的全新直播数据分析平台
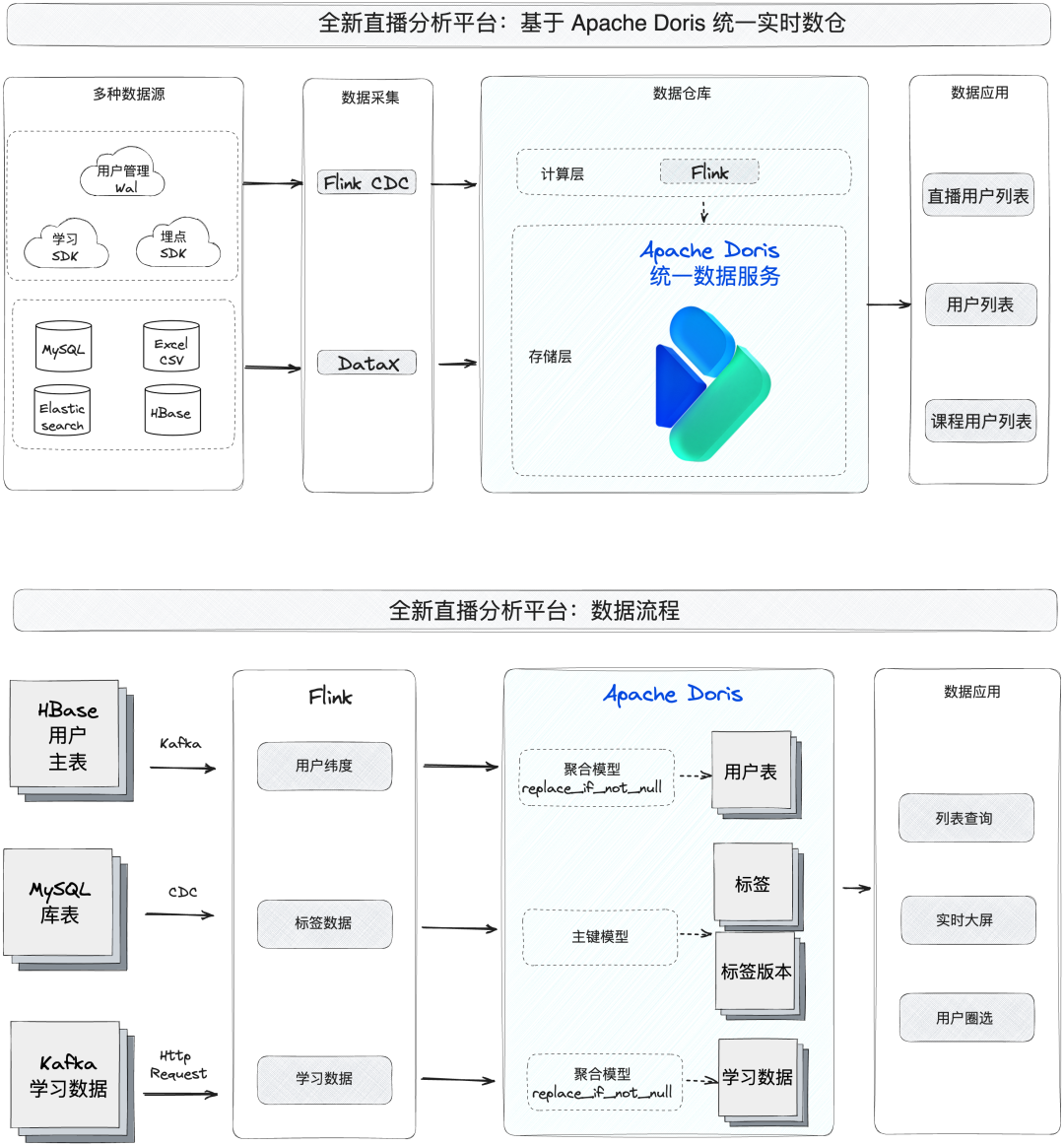
在升级到全新架构后,我们统一了实时和离线两条数据处理链路,全部交由 Apache Doris 来进行处理。如图所示,原始数据经过 Flink 流处理计算后,会实时写入到 Apache Doris 的表模型中,根据场景我们分别选用了不同的数据模型进行查询加速,数据表与对应的查询需求具体如下:
- 用户维度表:借助 Apache Doris 的 Aggregate Key 模型将用户维度数据聚合,同时通过 replace_if_not_null 方式实现部分列更新;
- 标签表:为了更好地构建用户标签体系,实时更新用户画像,我们借助 Unique Key 将数据分为标签与标签版本两类表,通过 Merge on Write 更新数据,并借助 Doris 关联查询性能,使商家获取最新版本的用户标签。
- 学习数据表:同样借助 Aggreagte Key 模型将用户在平台中的学习数据进行聚合,支持后续直播用户分析需求。
在 Apache Doris 引入后为我们提供了全新的数据流转,满足写入与查询时效性的需求,有效解决了原架构链路痛点。目前,我们基于 Doris 十余台集群规模为直播数据分析平台提供实时写入与极速分析,并带来了以下具体收益:
01 写查接口统一、写入效率更高
Flink-Doris-Connector 内置了 Flink CDC ,支持从业务数据库中全量和增量抽取数据,同时 Doris 也可以通过 Routine Load 来订阅 Kafka 中的数据、一流多表秒级写入,大幅提升了数据集成同步的效率。
利用 Apache Doris 替换原架构中 HBase 、Elasticsearch 等多个组件,减少了中间数据在不同链路中的流转,解决了链路过长、组件过多的问题,通过 Apache Doris 一套系统实现统一对外数据服务。
02 数据写时合并、高效更新
在 Apache Doris 聚合后,单表最大达数十亿的情况下,可以支撑每秒 20 万的数据 Upsert 与 Insert Overwrite,满足了直播高峰时期高吞吐写入需求。
在数据更新时,无需将字段补全后再重新开发宽表,可以直接利用 Merge On Write 功能进行轻量级 Merge,通过写时合并,实现微批高频实时写入与部分列更新。
03 多场景下的查询加速
在高并发点查时,我们高频使用 Doris 分区分桶裁剪功能,在查询时过滤非必要的数据,使数据扫描快速定位,加速查询响应时间。
在关联查询时,Apache Doris 支持对多张 10 亿级表进行 Join,满足分析人员将用户基础信息与学习、标签数据等关联查询需求。更重要的是,Doris 在标签检索、模糊查询、排序、分页等场景下都可以达到秒级甚至毫秒级的查询响应。
04 开发周期缩短、运维成本降低
Apache Doris 自身架构简单,FE 和 BE 两节点能够灵活扩缩容,易于部署、迁移与运维。在架构升级后,通过简化链路我们的运维成本相较于之前降低近 2/ 3。
同时 Doris 兼容 MySQL,使开发操作简单、使用门槛低,研发成本也随之降低。现在指标开发时间大幅度缩短,由原来单个指标耗时一个月缩短至现在仅需一周即可完成,加速指标迭代周期。
接下来,我们将从查询加速、容灾备份、数据可视化分析三方面分享 Apache Doris 在直播数据分析场景中应用实践,希望通过分享为读者提供更多关于 Doris 应用洞察。
用户画像场景查询加速实践
对于直播业务,用户标签是构成用户画像的核心因素,能够将用户在直播过程中所产生的行为数据分析提炼,生成具有差异性特征的标签词,以更好地掌握用户属性、用户偏好、直播习惯等信息。
在小鹅通直播分析平台中,商家可以自行定义规则生成标签,例如 “观看直播超过一分钟” 的用户为一类标签,“最近一分钟访问直播间”的用户为另一类标签。在这个过程中,商家会频繁不断地对用户“贴标签”(插入数据)或者“撕标签”(删减数据),与此同时每位用户也可能会存在多个自动或者手动标签。基于此,数仓需要具备以下能力:
- 面对标签变动频繁的情况,数仓需要支持实时写入与更新,并保证集群稳定。
- 面对同一用户的多类标签,数仓还需要提供强大的关联查询能力,并支持快速查询检索性能。
我们以下面的 SQL 为例,介绍基于 Apache Doris 在标签场景如何快速抽取数据、如何通过主键模型创建标签表与标签版本表、如何对字符串开启模糊查询解析,实现用户信息的快速检索,加速用户行为与经营业务分析。
创建标签表:
create table db.tags (
u_id string,
version string,
tags string
) with (
'connector' = 'doris',
'fenodes' = '',
'table.identifier' = 'tags',
'username' = '',
'password' = '',
'sink.properties.format' = 'json',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.fuzzy_parse' = 'true',
'sink.properties.columns' = 'id,u_id,version,a_tags,m_tags,a_tags=bitmap_from_string(a_tags),m_tags=bitmap_from_string(m_tags)',
'sink.batch.interval' = '10s',
'sink.batch.size' = '100000'
);
创建标签版本表:
create table db.tags_version (
id string,
u_id string,
version string
) with (
'connector' = 'doris',
'fenodes' = '',
'table.identifier' = 'db.tags_version',
'username' = '',
'password' = '',
'sink.properties.format' = 'json',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.fuzzy_parse' = 'true',
'sink.properties.columns' = 'id,u_id,version',
'sink.batch.interval' = '10s',
'sink.batch.size' = '100000'
);
两类表写入:
insert into db.tags
select
u_id,
last_timestamp as version,
tags
from db.source;
insert into rtime_db.tags_version
select
u_id,
last_timestamp as version
from db.source;
Bitmap 索引加速标签查询:
在写入完成后,业务人员开始对用户相关数据进行查询分析。以常见查询场景为例,我们需要查找某位姓张用户在最新版本中的标签数据,首先会在用户主表中使用 LIKE 匹配符合要求的用户名,其次在分页查询中对标签字段分别创建 Bitmap 索引,如 “123”、“124”、“125”、“126”、“333”,最后通过三表关联快速找到标签信息。
with t_user as (
select
u_id,
name
from db.user
where partition_id = 1
and name like '%张%'
),
t_tags as (
select
u_id,
version
from db.tags
where (
bitmap_and_count(a_tags, bitmap_from_string("123,124,125,126,333")) > 0
)
),
t_tag_version as (
select id, u_id, version
from db.tags_version
)
select
t1.u_id
t1.name
from t_user t1
join t_tags t2 on t1.u_id = t2.u_id
join t_tag_version t3 on t2.u_id = t3.u_id and t2.version = t3.version
order by t1.u_id desc
limit 1,10;
在直播数亿用户规模、每位用户存在上千个标签的场景下,**使用 Bitmap 索引来查询用户相关数据后,查询时间均能够在 1 秒内响应并准确地为业务人员提供所需结果,**大大加速了标签查询速度。
双集群高可用方案
在直播课程大促期间,为了带动直播间的下单氛围,提升用户秒抢积极性与下单率,平台会在直播间开启抽奖等活动。在引入 Doris 之前,我们将每日备份数据到对象存储中。当直播过程中优惠券领取、下单等出现故障时,从用户反馈、层层上报,再到故障恢复,需要花费数个小时。
然而,在这数小时中,成百上千的用户会因此流失,我们则需要承受用户退出直播间、寻找其他替代产品等巨大风险与损失。因此,平台面对海量用户访问的冲击,数据恢复与解决故障的速度成为了直播间业务效益的关键。
为了保障短期指数级业务波峰下平台的稳定运行,我们决定采取全新容灾方案。基于 Apache Doris 主备双集群的方式,实现热备;使用 Airflow 通过 Backup 与 Freeze 策略将每日数据备份至对象存储,以实现冷备,其中热备具体流程如下:
- 数据双写:改造 Flink Doris Connector,通过配置将数据写到两个集群或单个集群,在处理某个集群需要升级的场景时,先停止写一个集群后再去改造另外一个集群,有效保证集群的稳定性。
- 负载均衡:通过反向代理来切换查询请求到指定集群。当某一集群出现了问题,我们可以及时把请求接到另外一个集群上面。
- 监控校验:定期校验主从集群的数据及表结构的一致性,以便及时发现数据性不一致的情况。
我们还将进一步引入 Doris 2.0 版本中推出的 CCR 跨集群数据复制功能,尝试使用该功能减少开发运维成本,降低人工储备集群双写所导致两个集群 DDL 不一致的风险。
自研数据可视化平台,统一实时查询出口
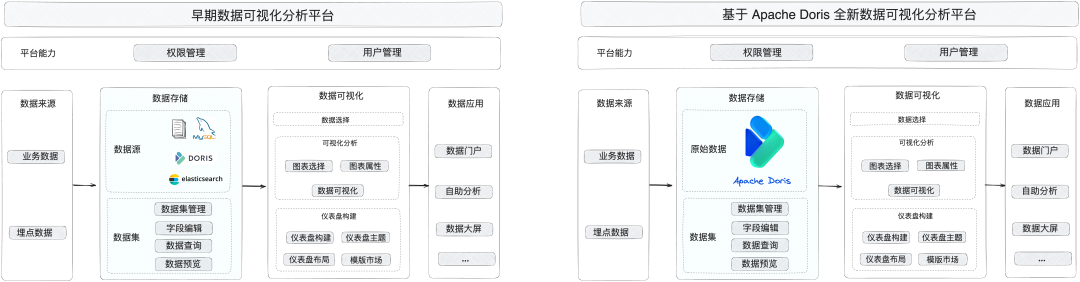
数据可视化分析平台主要用于离线报表、即席查询、实时数据大屏(Dashboard)三大场景,为商家业务人员、管理层等提供可视化分析功能。在引入 Doris 之后,我们将 MySQL、Elasticseach、本地文件等多种数据源统一交给 Apache Doris 实现。
同时,为了更好地将数据呈现给商家,我们还增加了数据源管理与数据集创建功能,业务人员可以直接在平台中选择数据源进行配置、测试等操作,形成可视化列表。除此之外,平台结合了 BI 工具中丰富的图表样式,满足商家配置数据看板的个性化需求。
在引入 Apache Doris 之后,通过数据集的配置实现了数据管理、权限管理等功能,并利用 Apache Doris 极速多维分析、联邦查询的能力加速了数字化平台的查询展示性能,摒弃了原来的 T+1 报表,在 Apache Doris 之上实现即时查询。
未来规划
目前,基于 Apache Doris 构建的分析平台主要用于小鹅通直播业务,为用户相关数据提供服务。在 Apache Doris 引入后,平台架构实现了写查出口统一、时效性大幅提升、用户数据多维分析场景拓展,同时 Doris 的加持还使后台系统具备稳定性、可扩展性、安全性等关键优势。这些突破促使平台基础技术能力进一步提高,也促进了用户数量、直播效益进一步增长。
后续我们希望继续拓展 Apache Doris 的使用场景,将课程分析、用户日志分析等交由 Apache Doris 对外提供统一的数据分析服务。同时,我们也希望继续探索 Apache Doris 2.0 版本的新特性,进一步提升集群稳定性能,包括:
- Pipeline 执行引擎和基于成本的查询优化器:在做用户直播列表时有许多复杂的售后场景需要人工优化,当有了 Pipeline 执行引擎和查询优化器后,不再需要人工调 SQL ,使执行性能更优;
- CCR 跨集群数据同步:通过用户多集群的数据库表自动同步以提升在线服务数据的可用性;
- 倒排索引:利用 Apache Doris 2.0 版本的倒排索引功能,对现有的索引结构进行丰富,实现模糊查询、等值查询和范围查询等能力,进一步加速查询响应速度。
在此特别感谢 SelectDB 技术团队在使用过程中遇到任何问题都能及时响应,为我们降低了许多试错成本。未来,我们也会更积极参与 Apache Doris 社区贡献及活动,与社区共同进步和成长!





![把字符串转换成整数[考虑溢出]](https://img-blog.csdnimg.cn/33c63ba0f6384a2db1bc306a21640d71.png)