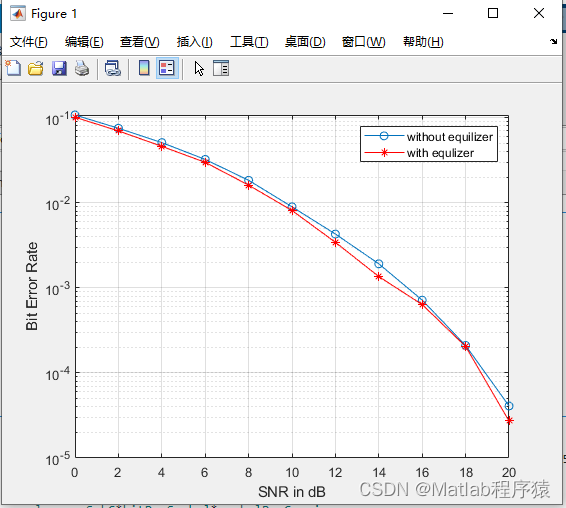
双链表
- 双链表的特点
- 声明双链表的结构体成员
- 双链表的初始化
- 带头结点的双链表初始化
- 不带头结点的双链表初始化
- 调用双链表的初始化
- 双链表的判空
- 带头结点的双链表判空
- 不带头结点的双链表判空
- 双链表的插入(按值插入)
- 头插法建立双链表
- 带头结点的头插法
- 每次调用头插法只能插入一个结点
- 每次调用头插法可插入任意个结点
- 调用头插法建立带头结点的双链表的完整代码(可以直接赋值运行的)
- 不带头结点的头插法
- 每次调用只能插入一个结点
- 每次调用可以插入任意个结点
- 调用头插法建立不带头结点的双链表的完整代码(可以直接赋值运行的)
- 尾插法建立双链表
- 带头结点的尾插法
- 每次调用只能插入一个结点
- 我自己能理解的实现尾插法的思路
- 我的思路的完整代码,可以运行的
- 教材用的实现尾插法的代码(我看不懂)
- 不带头结点的尾插法
- 我自己的思路
- 打印双链表
- 二级目录
- 三级目录
双链表的特点
1. 双链表在创建的过程中,每个结点都需要一个数据域和两个指针域,所以它的存储密度比之单链表更低一些。
2. 可进可退,解决了单链表无法逆向搜索的问题。
声明双链表的结构体成员
typedef struct DNode {
ElemType data;
struct DNode *prior, *next;
}DNode, *DLinklist;
// DNode *就等价于DLinklist 之前文章有解释过
DNode *就等价于DLinklist
双链表的初始化
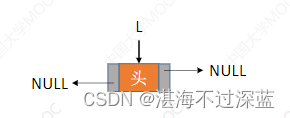
双链表的每个结点都有两个指针域,一个指向前驱结点,一个指向后继结点。头结点的prior永远指向NULL
带头结点的双链表初始化
有几个需要注意的地方:
1. DLinklist&L是头指针,而不是头结点,这是两东西。
2. 头结点不存储数据,只起到一个标记作用,方便对链表进行操作。
3. 头指针指向头结点,用于记录链表的起始位置。
4. 给&L分配内存空间,是因为这是带头结点的双链表,而头指针指向头结点,所以实际上是给头结点分配内存空间,创建头结点。
5. 不带头结点的双链表,不用创建头结点,自然也不用分配内存空间,直接创建第一个结点即可。
6. 注意:原先我一直疑惑的地方是,为啥带头结点就要分配内存空间,不带头结点的双链表哪怕不需要头结点,也要给第一个结点分配内
存空间,但是初始化代码的时候并没有写,后来我发现,不是没写,而是不应该在初始化链表的时候给链表的第一个实际结点分配内存空
间,此时是为了初始化一个空链表,后续给链表插入结点的时候,才会开始分配内存空间。而此时分配的,仅仅只是头结点的内存空间,
并不是第一个实际结点的,带就分配,不带就不分配,就这么个意思。
bool initDList(DLinklist&L) {
L=(DNode *)malloc(sizeof(DNode));
/**
* L本身是头指针,带头结点时,它指向头结点的指针域,所以可以把L看作是头结点,指针域为NULL,说明这是个空指针。
* 注意:空指针本身不占用内存空间。
* 指针变量在内存中占用一定的空间,但当指针被赋值为NULL时,它指向的内存地址为空,不指向任何有效的内存空间。
* 因此,空指针并不占用额外的内存空间
*/
if(L==NULL) { // 空指针不占用内存空间,可用此来判断内存不足,给头结点分配存储空间失败
return false;
}
// 头结点的prior永远指向NULL
// 头指针L指向头结点,存储头结点的地址;L->prior指向头结点的前指针域,存储前指针域的地址,为NULL。
L->prior=NULL;
// 头结点之后还没有结点,初始化链表这句必须写,因为要创建个空表,以防被内存中残留数据污染
L->next=NULL;
// 头指针L指向头结点,存储头结点的地址;L->next指向头结点的后指针域,存储后指针域的地址,为NULL。
return true;
}
不带头结点的双链表初始化
void initDList(DLinklist&L) {
// 由于不带头结点,所以头指针L直接指向双链表的第一个实际结点,此时链表为空,所以指向NULL,可看作是个空指针,空指针的前、后指针不指向任何有效的内存空间,自然不用再区分next、prior
L=NULL;
}
调用双链表的初始化
int main() {
DLinklistL;
// 初始化双链表
initDList(L);
}
双链表的判空
带头结点的双链表判空
1. 带头结点的双链表,由于头结点的前指针永远指向NULL,所以不用管。
2. 主要是头结点的后指针,看它后面有没有结点,没结点时它应该指向NULL。
bool Empty(DLinklist L) {
if(L->next==NULL) {
return true;
}else {
return false;
}
// 这个if判断可以简写成:
return L->next==NULL;
}
不带头结点的双链表判空
bool Empty(DLinklist L) {
return L==NULL;
}
双链表的插入(按值插入)
1. 这是按值插入,不是按位插入,只要在找到链表中某个已存在的结点,在其后面分配存储空间,创建一个新结点,改变前、后指针指向,以及
新结点的数据域,就可以实现插入了,这算是后插。
2. 此处只是说明了插入的逻辑,代码并不完整,也还没有分带不带头结点
1. DNode *p表示声明一个指针变量p,它指向下一结点的指针域。
2. p=NULL表示p指针所在的结点的指针域为NULL,它不指向任何有效的地址,说明p是个空指针。
- 为什么要判断指针p和指针s是否是空指针?
1. 因为该函数是在找到p结点之后,通过改变p结点原先的指向,来实现插入的。
2. 如果p是个空指针,它的后指针域没有任何指向,那我在它后面插入一个新结点,新结点的后指针域就没有赋值指向了。
3. 并且,一般链表的最后一个结点的后面是NULL,肯定不能在NULL后面再插入新结点,要插也最后是在最后一个实际结点后面插
4. 参数s表示指针s,它所指向的结点是我要插入的新结点,一个新结点,都要插入一个新结点了,肯定不能是个空指针啊,如果是个
空指针,那这个链接岂不是断链了。
3. p->next=NULL:p->next表示指针p所在的结点的指针域,它存储下一结点的地址,指向下一结点的指针域。p-next=NULL就表示指针p指向
的结点的下一结点是NULL。
4. 把指针变量p指向的结点看作是p结点,那它的下一结点就是紧跟其后的一个结点,即p结点—NULL。
5. 首先明确,p是用DNode *去声明的,所以p一定是个指针,那一个指针,它会指向一个结点,就可以把p看作是p结点,p=NULL就是说p结点本
身是NULL。
6. 其次,p->next就可以看作是p结点的下一结点是NULL
bool InsertNextNode(DNode *p, DNode *s) {
if(p==NULL || s==NULL) {
return false;
}
/**
* s指针所指向的结点(简称s结点)的指针域指向p指针所指向的结点(简称p结点)的指针域指向的结点,即:s结点指向p结点的下一个结点,
* 此时顺序是p—p下一结点,s—p下一结点
*/
s->next=p->next;
/**
* 由于是双链表,每个结点都有前指针和后指针,p结点如果是最后一个结点,说明它后面没有结点了,指向NULL。
* 它的后指针指向NULL,这没问题,这样子的双链表才是完整的。
* 但是NULL没有前、后指针啊,所以在操作结点的前指针指向的时候,要加个判断,当前结点下一结点不是NULL才能操作其前指针
*/
if(p->next!=NULL) {
/**
* p->next表示p结点的下一结点(简称q结点),
* p->next->prior表示q结点的前指针域指向的结点,
* 赋值s就表示q结点的指针域指向指针s所指向的结点,即s结点。
* 此时顺序为:p—q,s—q
*/
p->next->prior=s;
}
// 现在只要把p和s再连上就好了
p->next=s;
s->prior=p;
return true;
}
头插法建立双链表
需求:把一个数组中的数据,插入到初始的双链表中,如果当前双链表带头结点,那么每次都是插在头结点的后面,这样每次插入的新结点都是
链表的第一个结点。
如果当前双链表不带头结点,那么每次插入都应该让头指针L直接指向当前新插入的这个结点。
这便是头插法。
带头:
1. 带头结点的初始双链表:头指针L—头结点—NULL
2. 插入1个需要的参数:要建立的链表&L,要插入的元素e
3. 插入n个需要的参数:要建立的链表&L,要插入的多个元素e[],要插入的结点个数n
不带头:头指针L—NULL
4. 带头结点的初始双链表:头指针L—NULL
5. 需要的参数:要建立的链表&L,要插入的元素e
带头结点的头插法
每次调用头插法只能插入一个结点
DLinklist head_insert(DLinklist &L, int e) {
// 创建新结点,分配内存空间
DLinklist *s = (DLinklist *)malloc(sizeof(DLinklist));
/**
* 头指针L指向头结点,L->next指向头结点的指针域,头结点的指针域指向头结点的下一结点,
* 即L可看作是头结点,L->next就是头结点的下一结点。
* 1、头结点指向创建的新结点s,即在头结点之后插入新结点,
* 2、此时头结点原指向的结点就要变成s结点的下一结点
* 3、此时后指针的指向已全部完成,双链表还要再操作一下前指针的指向:
* - s结点的前指针指向头结点,头结点原下一结点的前指针指向s结点
* 4、但是要注意一个问题,如果是第一次插入,双链表此时是空的,头结点指向NULL,插入的新结点s是链表中最后一个结点,
* 只要操作其后指针即可,而其下一结点的无前指针无需操作,所以为了代码的健壮性要加个判断
*/
s->data=e;
s->next=L->next;
if(L->next!=NULL) {
L->next->prior=s;
}
L->next=s;
s->prior=L;
}
每次调用头插法可插入任意个结点
1. 首先要给分配内存空间,有多少个n,就分配多少个。
2. 由于插入的n个,每个的前指针和后指针还要链接起来,所以最好当作1个来操作,然后通过循环的方式,变成n个。
3. i是数组的下标,从0开始表示数组中第一个元素,假设n=3那就是插入3个结点,必须从i=0开始循环,那就要i<n或者i<=n-1才能正好取3个。
DLinklist head_insert_mult(DLinklist &L, int e[], int n) {
for(int i=0;i<n;i++) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->next=L->next;
s->data=e[i];
if(L->next!=NULL) {
L->next->prior=s;
}
s->prior=L;
L->next=s;
}
return L
}
调用头插法建立带头结点的双链表的完整代码(可以直接赋值运行的)
#include<stdio.h>
#include<stdlib.h>
// 声明结构体成员
typedef struct DNode {
ElemType data;
struct DNode *prior, *next;
}DNode, *DLinklist;
// 初始化一个带头结点的双链表
DLinklist InitList(DLinklist &L) {
L=(DNode *)malloc(sizeof(DNode));
if(L==NULL) {
return NULL;
}
L->next=NULL;
L->prior=NULL;
return L;
}
// 头插法建立双链表(单个)
DLinklist head_insert(DLinklist &L,int e) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->data=e;
s->next=L->next;
if(L->next!=NULL)
L->next->prior=s;
L->next=s;
s->prior=L;
return L;
}
// 头插法建立双链表(多个)
DLinklist head_insert_mult(DLinklist &L, int e[], int n) {
for(int i=0;i<=n-1;i++) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->next=L->next;
s->data=e[i];
if(L->next!=NULL) {
L->next->prior=s;
}
s->prior=L;
L->next=s;
}
return L;
}
// 打印双链表
void printDLinkList(DLinklist L)
{
DNode* p = L;
while(p)
{
printf("%d ", p->data);
p = p->next;
}
}
int main() {
DLinklist L;
InitList(L);
head_insert(L,2);
head_insert(L,3);
int arr[5]={1,2,3,4,5};
head_insert_mult(L,arr,3);
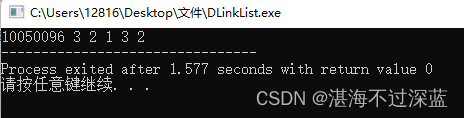
// 顺序为 头结点 3 2 1 3 2
printDLinkList(L);
return 0;
}
不带头结点的头插法
由于没有头结点了,所以操作头指针L直接指向双链表第一个实际结点
每次调用只能插入一个结点
DLinklist head_insert_NoT(DLinklist &L, int e) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->next=L;
s->data=e;
if(L!=NULL) {
L->prior=s;
}
L=s;
s->prior=L;
return L;
}
每次调用可以插入任意个结点
DLinklist head_insert_NoT_mult(DLinklist &TL, int e[], int n) {
for(int i=0;i<n;i++) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->data=e[i]; // 此时双链表只有一个NULL,由TL指向
s->next=TL; // s指针所在的结点(简称s结点)的指针域为头指针TL的指向,也就是说s结点下一个是NULL:s—NULL
if(TL!=NULL) {
TL->prior=s; // 由于是头茬,所以每次TL原先指向的那个结点的前指针都要指向新插入的s
}
TL=s; // TL是头指针,每次都要指向新插入的s指针所指向的结点
s->prior=NULL; // 由于s指针是以头插的形式新插入的,它就是第一个结点,前面没有任何东西,前指针指向NULL
}
return TL;
}
调用头插法建立不带头结点的双链表的完整代码(可以直接赋值运行的)
#include<stdio.h>
#include<stdlib.h>
// 声明结构体成员
typedef struct DNode {
ElemType data;
struct DNode *prior, *next;
}DNode, *DLinklist;
// 初始化一个带头结点的双链表
DLinklist InitList(DLinklist &L) {
L=NULL;
return L;
}
DLinklist head_insert_NoT(DLinklist &L, int e) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->next=L;
s->data=e;
if(L!=NULL) {
L->prior=s;
}
L=s;
s->prior=L;
return L;
}
DLinklist head_insert_NoT_mult(DLinklist &TL, int e[], int n) {
for(int i=0;i<n;i++) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->data=e[i];
s->next=TL;
if(TL!=NULL) {
TL->prior=s;
}
TL=s;
s->prior=NULL;
}
return TL;
}
// 打印双链表
void printDLinkList(DLinklist L)
{
DNode* p = L;
while(p)
{
printf("%d ", p->data);
p = p->next;
}
}
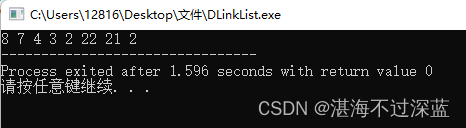
int main() {
DLinklist L;
InitList_NoT(L);
head_insert_NoT(L,2);
head_insert_NoT(L,21);
head_insert_NoT(L,22);
int arr1[5]={2,3,4,7,8};
head_insert_NoT_mult(L,arr1,5);
printDLinkList(L);
return 0;
}
尾插法建立双链表
尾插就是:每次都在双链表的末尾再插入一个结点,新结点后面不会再有其他结点,应该是指向NULL的。
带头:
1. 插入一个需要的参数:双链表L、要插入的元素e
不带头:
2、
带头结点的尾插法
每次调用只能插入一个结点
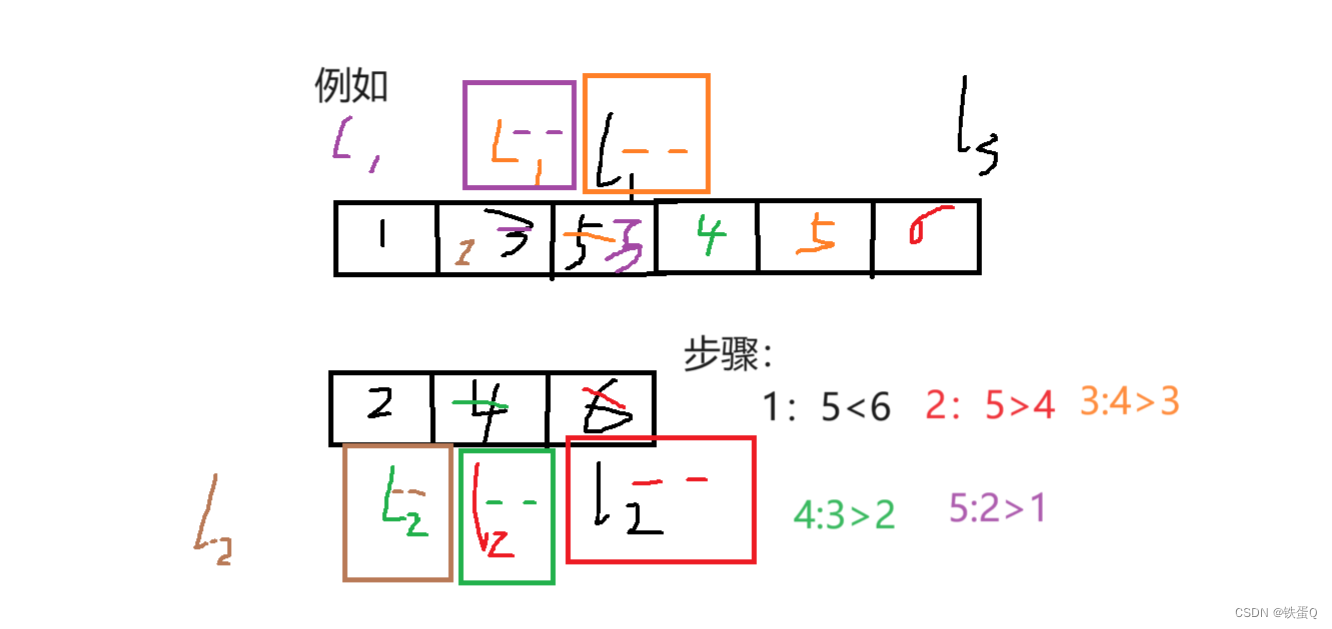
我自己能理解的实现尾插法的思路
带头结点:那就是头结点—新结点—NULL
尾插法思路:
1. 要在双链表的最后一个结点后面插入,那肯定要找到最后一个结点。而最后一个结点后面没结点,指向NULL,所以可以根据这个来判断。
DNode *tail; // 这是我声明的指向尾结点指针变量tail
if(tail->next==NULL) // 说明tail指针目前已经是指向尾结点
2. 双链表是个链表,它不具有随机存取的特点,所以要找到尾结点,只能从第一个结点开始按序遍历
tail=L; // tail指针要指向头指针L指向的结点,即头结点,由此开始遍历
while(tail->next!=NULL)
tail=tail->next; // 如果tail指针当前指向的结点的下个结点不是NULL,那就指向下一个,循环遍历
// 此处应该是跳出循环的操作了,而跳出循环就说明tail指针已经指向尾结点了
3. 要插入新结点,肯定要创建并分配存储空间,先让新结点指向尾结点的下一结点,再让尾结点指向新结点,然后让新结点的前指针指向尾结点
s->next=tail->next;
tail->next=s;
s->prior=tail;
DLinklist tail_insert(DLinklist &L, int e) {
DNode *tail=L; // 声明一个指针变量tail表示尾指针,赋值L表示初始值指向头结点
while(tail->next!=NULL) {
tail=tail->next;
}
DNode *s=(DNode *)malloc(sizeof(DNode));
s->next=tail->next;
s->data=e;
tail->next=s;
s->prior=tail;
// 因为是尾插法,所以最后s一定指向NULL,tail->next-prior是不存在的不用考虑
}
我的思路的完整代码,可以运行的
#include<stdio.h>
#include<stdlib.h>
typedef struct DNode {
int data;
struct DNode *prior;
struct DNode *next;
}DNode,*DLinklist;
DLinklist InitList(DLinklist &L) {
L=(DNode *)malloc(sizeof(DNode));
if(L==NULL) {
return NULL;
}
L->next=NULL;
L->prior=NULL;
return L;
}
DLinklist tail_insert(DLinklist &L, int e) {
DNode *tail=L;
while(tail->next!=NULL) {
tail=tail->next;
}
DNode *s=(DNode *)malloc(sizeof(DNode));
s->next=tail->next;
s->data=e;
tail->next=s;
s->prior=tail;
}
// 打印双链表
void printDLinkList(DLinklist L)
{
DNode* p = L;
while(p)
{
printf("%d ", p->data);
p = p->next;
}
}
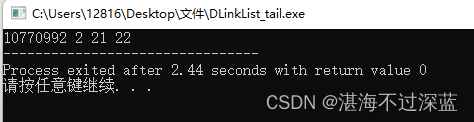
int main() {
DLinklist L;
InitList(L);
tail_insert(L,2);
tail_insert(L,21);
tail_insert(L,22);
printDLinkList(L);
return 0;
}
DLinklist tail_insert(DLinklist &L, int e) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s-next=L->next;
}
教材用的实现尾插法的代码(我看不懂)
不带头结点的尾插法
我自己的思路
由于此处是双链表不带头结点,那么此时头指针L指向双链表的第一个实际结点,所以当双链表为空时,L=NULL,但如果双链表不为空,L自然也不会是NULL,就要通过遍历去获取双链表的尾结点,所以要做个if判断
DLinklist tail_insert_NoT(DLinkList &L,int e) {
DNode *s=(DNode *)malloc(sizeof(DNode));
s->data=e;
// 这两句没有就无法运行
s->next = NULL;
s->prior = NULL;
/**
* 初始化的时候L=NULL,头结点是NULL,所以tail指针指向NULL,
* 但是只要插入过结点,再调用该函数进行尾插,头指针L就不再是指向NULL,而是指向一个实际结点,
* 此时就要通过遍历去获取该链表的尾结点,过程同上
*/
DNode *tail;
if(L==NULL) { // 不带头的双链表为空时,L指向的就是第一个实际结点,插入的新结点s就应该是由L指向的:L=s,第一个结点的前指针用于指向NULL
L=s;
s->prior=NULL;
}else {
while(tail->next!=NULL) {
tail=tail->next;
}
s->next=tail->next;
tail->next=s;
s->prior=tail;
}
return L;
}
打印双链表
插入结点之后,想看看当前双链表的结点顺序,可以用以下代码打印输出
void PrintDLinkList(DLinklist L) {
/**
* 声明一个指针变量p让它指向头指针L指向的结点,
* 如果是带头结点的双链表,就指向头结点;
* 如果是不带的,就指向双链表的第一个实际结点。
* 此处我写L是为了区分终端打印效果,如果不想要头结点,写成:DNode *p=L->next
*/
DNode *p=L;
while(p!=NULL) {
printf("%d", p->data);
p=p->next;
}
}