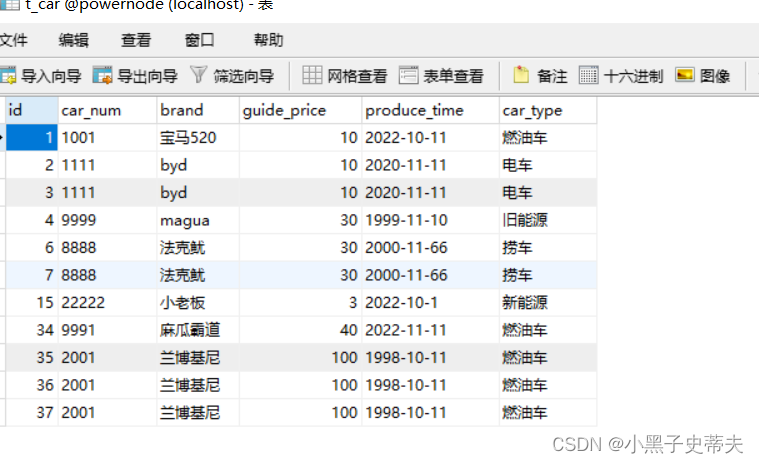
这篇文章,笔者想聊聊 RocketMQ 最佳实践之一:保证订阅关系一致。
订阅关系一致指的是同一个消费者 Group ID 下所有 Consumer 实例所订阅的 Topic 、Tag 必须完全一致。
如果订阅关系不一致,消息消费的逻辑就会混乱,甚至导致消息丢失。
1 订阅关系演示
首先我们展示正确的订阅关系:多个 Group ID 订阅了多个 Topic,并且每个 Group ID 里的多个消费者的订阅关系保持了一致。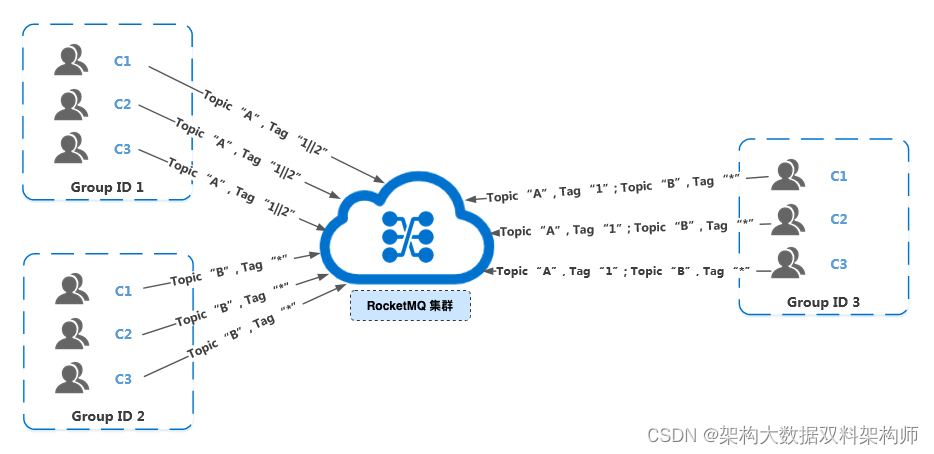
接下来,我们展示错误的订阅关系。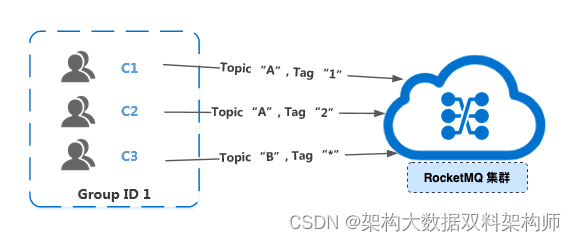
从上图中,单个 Group ID 订阅了多个 Topic,但是该 Group ID 里的多个消费者的订阅关系并没有保持一致。
代码逻辑角度来看,每个消费者实例内订阅方法的主题、 TAG、监听逻辑都需要保持一致。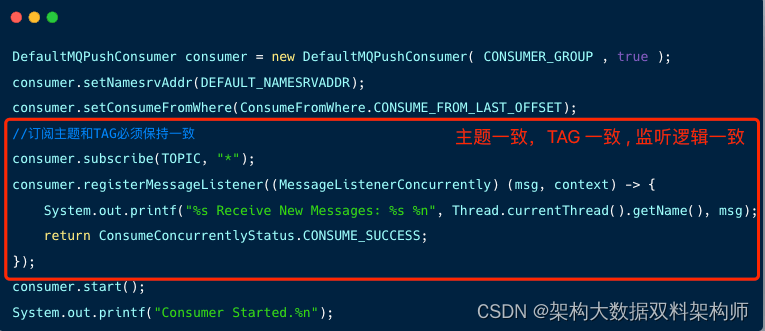
接下来,我们实验相同消费组,两种不正确的场景,看看消费者和 Broker 服务有什么异常。
订阅主题不同,标签相同
订阅主题相同,标签不同
2 订阅主题不同,标签相同

当我们启动两个消费者后,消费者组名:myconsumerGroup。C1 消费者订阅主题 TopicTest , C2 消费者订阅主题 mytest。
在 Broker 端的日志里,会不停的打印拉取消息失败的日志 :
2023-10-09 14:52:53 WARN PullMessageThread_2 -
the consumer’s subscription not exist, group: myconsumerGroup, topic:TopicTest
那么在这种情况下,C1 消费者是不可能拉取到消息,也就不可能消费到最新的消息。
为什么呢 ? 我们知道客户端会定时的发送心跳包到 Broker 服务,心跳包中会包含消费者订阅信息,数据格式样例如下:
"subscriptionDataSet": [
{
"classFilterMode": false,
"codeSet": [],
"expressionType": "TAG",
"subString": "*",
"subVersion": 1696832107020,
"tagsSet": [],
"topic": "TopicTest"
},
{
"classFilterMode": false,
"codeSet": [],
"expressionType": "TAG",
"subString": "*",
"subVersion": 1696832098221,
"tagsSet": [],
"topic": "%RETRY%myconsumerGroup"
}
]Broker 服务会调用 ClientManageProcessor 的 heartBeat 方法处理心跳请求。
最终跟踪到代码: org.apache.rocketmq.broker.client.ConsumerManager#registerConsumer

Broker 服务的会保存消费者信息,消费者信息存储在消费者表 consumerTable 。消费者表以消费组名为 key , 值为消费者组信息 ConsumerGroupInfo 。
#org.apache.rocketmq.broker.client.ConsumerManager
private final ConcurrentMap<String/* Group */, ConsumerGroupInfo> consumerTable =
new ConcurrentHashMap<String, ConsumerGroupInfo>(1024);
如果消费组的消费者信息 ConsumerGroupInfo 为空,则新建新的对象。
更新订阅信息时,订阅信息是按照消费组存放的,这步骤就会导致同一个消费组内的各个消费者客户端的订阅信息相互被覆盖。
回到消费者客户端,当消费者拉取消息时,Broker 服务会调用 PullMessageProcessor 的 processRequest 方法 。
首先会进行前置判断,查询当前的主题的订阅信息若该主题的订阅信息为空,则打印告警日志,并返回异常的响应结果。
subscriptionData = consumerGroupInfo.findSubscriptionData(requestHeader.getTopic());
if (null == subscriptionData) {
log.warn("the consumer's subscription not exist, group: {}, topic:{}", requestHeader.getConsumerGroup(),
response.setCode(ResponseCode.SUBSCRIPTION_NOT_EXIST);
response.setRemark("the consumer's subscription not exist" + FAQUrl.suggestTodo(FAQUrl.SAME_GROUP_DIFFERENT_TOPIC));
return response;
}通过调研 Broker 端的代码,我们发现:相同消费组的订阅信息必须保持一致,否则同一个消费组内的各个消费者客户端的订阅信息相互被覆盖,从而导致某个消费者客户端无法拉取到新的消息。
C1 消费者无法消费主题 TopicTest 的消息数据,那么 C2 消费者订阅主题 mytest,消费会正常吗 ?

上图来看,依然有问题。 主题 mytest 有四个队列,但只有两个队列被分配了, 另外两个队列的消息就没有办法消费了。
要解释这个问题,我们需要重新温习负载均衡的原理。
负载均衡服务会根据消费模式为” 广播模式” 还是 “集群模式” 做不同的逻辑处理,这里主要来看下集群模式下的主要处理流程:
(1) 获取该主题下的消息消费队列集合;
(2) 查询 Broker 端获取该消费组下消费者 Id 列表;
(3) 先对 Topic 下的消息消费队列、消费者 Id 排序,然后用消息队列分配策略算法(默认为:消息队列的平均分配算法),计算出待拉取的消息队列;

这里的平均分配算法,类似于分页的算法,将所有 MessageQueue 排好序类似于记录,将所有消费端排好序类似页数,并求出每一页需要包含的平均 size 和每个页面记录的范围 range ,最后遍历整个 range 而计算出当前消费端应该分配到的记录。
(4) 分配到的消息队列集合与 processQueueTable 做一个过滤比对操作。

消费者实例内 ,processQueueTable 对象存储着当前负载均衡的队列 ,以及该队列的处理队列 processQueue (消费快照)。
- 标红的 Entry 部分表示与分配到的消息队列集合互不包含,则需要将这些红色队列 Dropped 属性为 true , 然后从 processQueueTable 对象中移除。
- 绿色的 Entry 部分表示与分配到的消息队列集合的交集,processQueueTable 对象中已经存在该队列。
- 黄色的 Entry 部分表示这些队列需要添加到 processQueueTable 对象中,为每个分配的新队列创建一个消息拉取请求 pullRequest , 在消息拉取请求中保存一个处理队列 processQueue (队列消费快照),内部是红黑树(TreeMap),用来保存拉取到的消息。
最后创建拉取消息请求列表,并将请求分发到消息拉取服务,进入拉取消息环节。
通过上面的介绍 ,通过负载均衡的原理推导,原因就显而易见了。
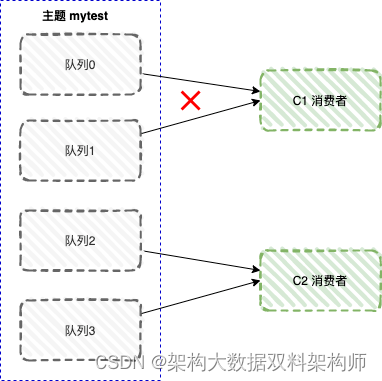
C1 消费者被分配了队列 0、队列 1 ,但是 C1 消费者本身并没有订阅主题 mytest , 所以无法消费该主题的数据。
从本次实验来看,C1 消费者无法消费主题 TopicTest 的消息数据,C2 消费者只能部分消费主题 mytest 的消息数据。
但是因为在 Broker 端,同一个消费组内的各个消费者客户端的订阅信息相互被覆盖,所以这种消费状态非常混乱,偶尔也会切换成:C1 消费者可以部分消费主题 TopicTest 的消息数据,C2 消费者无法消费主题 mytest 的消息数据。
3 订阅主题相同,标签不同
如图,C1 消费者和 C2 消费者订阅主题 TopicTest ,但两者的标签 TAG 并不相同。
启动消费者服务之后,从控制台观察,负载均衡的效果也如预期一般正常。
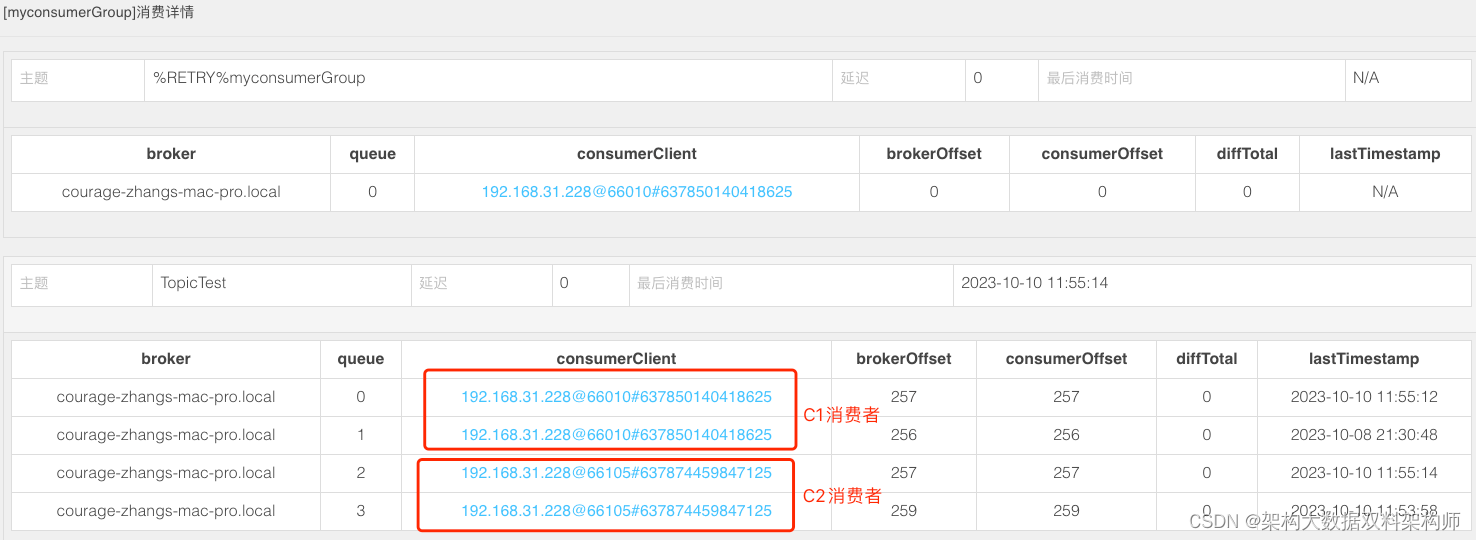
笔者在 Broker 端打印埋点日志,发现主题 TopicTest 的订阅信息为 :
{
"classFilterMode": false,
"codeSet": [66],
"expressionType": "TAG",
"subString": "B",
"subVersion": 1696901014319,
"tagsSet": ["B"],
"topic": "TopicTest"
}
那么这种状态,消费正常吗 ?笔者做了一组实验,消费依然混乱:
C1 消费者无法消费 TAG 值为 A 的消息 ,C2 消费者只能消费部分 TAG 值为 B 的消息。
想要理解原因,我们需要梳理消息过滤机制。
首先 ConsumeQueue 文件的格式如下 :
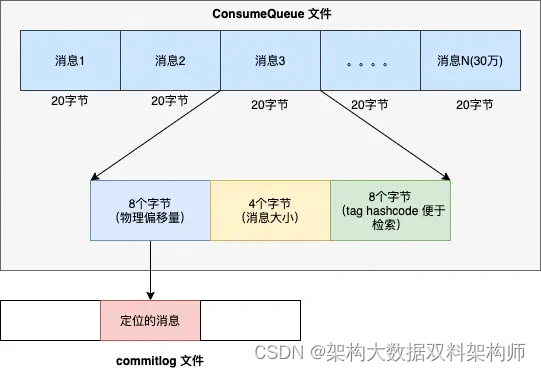
- Broker 端在接收到拉取请求后,根据请求参数定位 ConsumeQueue 文件,然后遍历 ConsumeQueue 待检索的条目, 判断条目中存储 Tag 的 hashcode 是否和订阅信息中 TAG 的 hashcode 是否相同,若不符合,则跳过,继续对比下一个, 符合条件的聚合后返回给消费者客户端。
- 消费者在收到过滤后的消息后,也要执行过滤机制,只不过过滤的是 TAG 字符串的值,而不是 hashcode 。
我们模拟下消息过滤的过程:
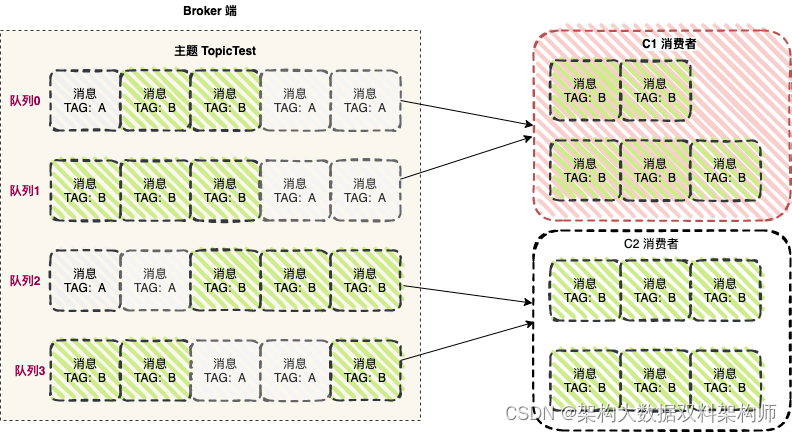
首先,生产者将不同的消息发送到 Broker 端,不同的 TAG 的消息会发送到保存的不同的队列中。
C1 消费者从队列 0 ,队列 1 中拉取消息时,因为 Broker 端该主题的订阅信息中 TAG 值为 B ,经过服务端过滤后, C1 消费者拉取到的消息的 TAG 值都是 B , 但消费者在收到过滤的消息后,也需要进行客户端过滤,A 并不等于 B ,所以 C1 消费者无法消费 TAG 值为 A 的消息。
C2 消费者从队列 2, 队列 3 中拉取消息,整个逻辑链路是正常的 ,但是因为负载均衡的缘故,它无法消费队列 0 ,队列 1 的消息。
4 总结
什么是消费组 ?消费同一类消息且消费逻辑一致 。RocketMQ 4.X 源码实现就是为了和消费组的定义保持一致 。
规避订阅关系不一致这个问题有两种方式:
- 合理定义好主题和标签
当我们定义好主题和标签后,需要添加新的标签时,是否可以换一个思路:换一个新的消费组或者新建一个主题。
- 严格规范上线流程
在上线之前,梳理好相关依赖服务,梳理好上线流程,做好上线评审,并严格按照流程执行。
最后的思考:
假如从基础架构层面来思考,将订阅关系信息中心化来设计,应该也可以实现 ,但成本较高,对于中小企业来讲,并不合算。