文章目录
- 11. 流计算概述
- 11.1 流计算概述
- 11.1.1 数据的处理模型
- 11.1.2 流计算概念与典型框架
- 11.2 流计算处理流程
- 11.3 流计算的应用
- 11.4 开源流计算框架Storm
- 11.4.1 Storm 简介
- 11.4.2 Storm设计思想
- 11.4.3 Storm框架设计
- 11.5 Spark Spark Streaming Samza以及三种流计算框架比较
- 11.6 Storm 的安装和编程实例
- 11.6.1 编写Storm程序
- 11.6.2 安装Storm的基本过程和实例
11. 流计算概述
11.1 流计算概述
11.1.1 数据的处理模型
-
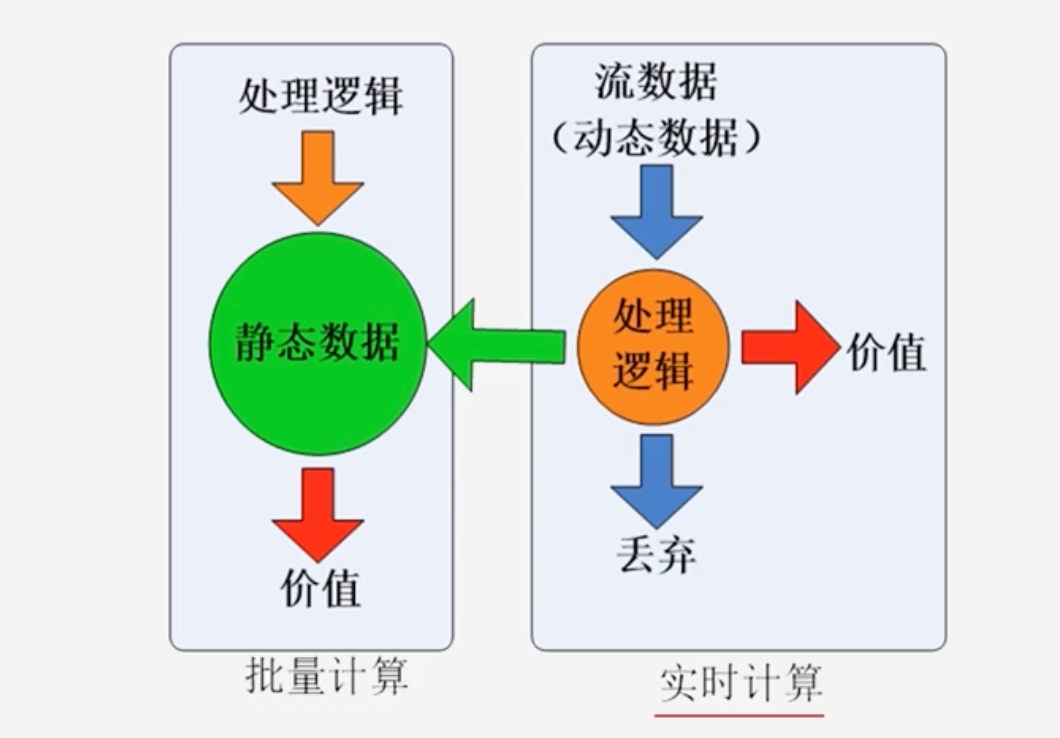
静态数据和流数据
-
静态数据用一个非常形象的比喻,就是三峡水库里面蓄的水一样静止不动
例如:数据仓库中的数据存入数仓后就维持不变,是典型的静态数据
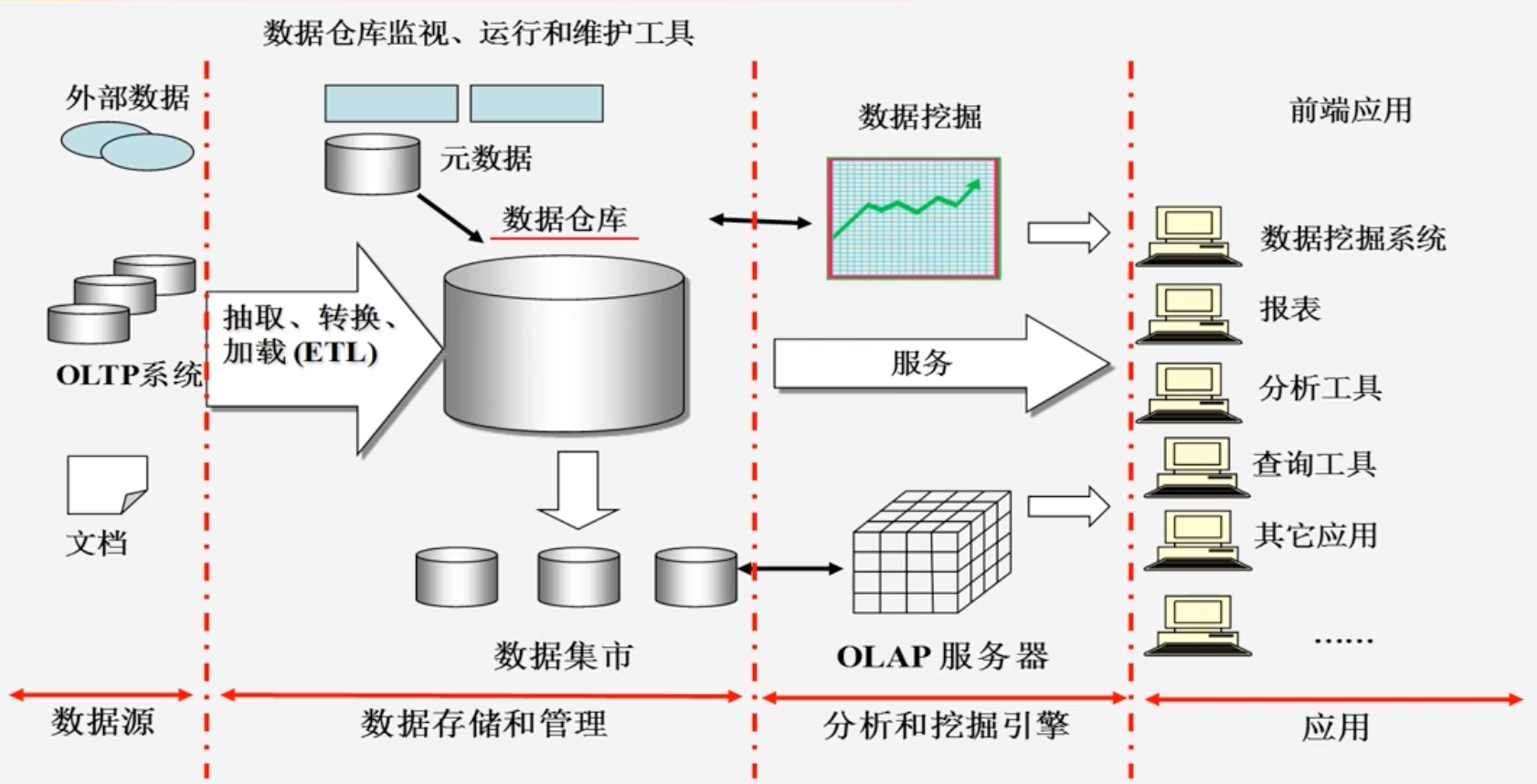
-
流数据:近年来,在Web应用、网络监控、传感检测等领域,兴起的一种新的数据密集型应用–流数据,即数据以大量、快速、时变的流形式持续到达
- 其数据产生方式是实时产生,并且实时不断地像流水一样到达,所以称为流数据
-
-
流数据特征
- 数据快速持续到达,潜在大小也许是无穷无尽的
- 数据来源众多,格式复杂
- 数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储
- 注重数据的整体价值,不过分关注个别数据
- 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序
-
针对这两类数据的分析计算
11.1.2 流计算概念与典型框架
-
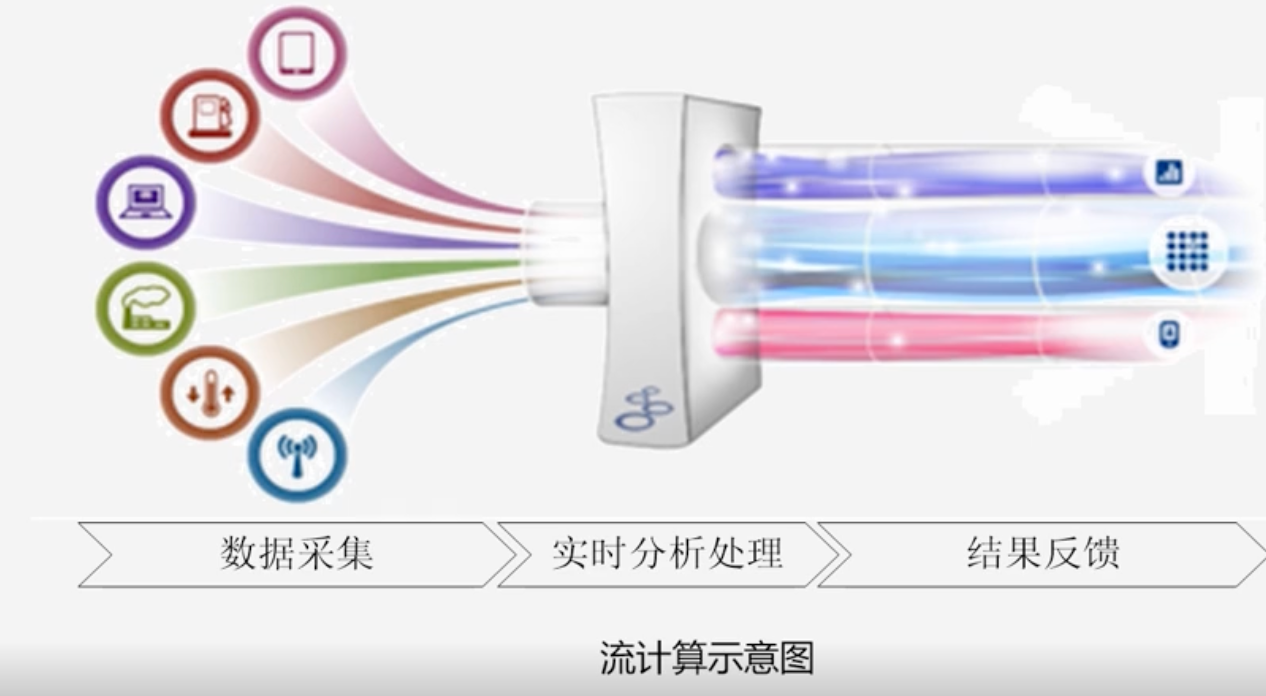
流计算的概念
-
实时获取来自不同数据源的海量数据,经过实时分析处理,获得有价值的信息
-
-
流计算的基本理念
-
数据的价值随着时间的流逝而降低,如用户点击流
-
因此,当时间出现时就应该立即进行处理,而不是缓存起来进行批量处理
-
需要一个低延迟、高可靠、可扩展的处理引擎帮我们去完成流数据的实时处理
-
-
流计算系统要求

-
Hadoop是否适合做流式处理?
-
Hadoop的设计初衷是面向大规模数据的批量处理
-
MapReduce是专门面向静态数据的批量处理的,内部各种机制都为批处理做了高度优化,不适合用户处理持续到达的动态数据
-
-
通过降低批处理时间延迟的方式完成流式数据的处理?
-
采用变通的方式对MapReduce进行相关的改造
-
MapReduce的批量数据转换为很多的小量的数据,一大批数据将其切割成很多小批
-
每隔一个周期去启动一次MapReduce作业,变相地完成一个流式数据的处理
问题:
- 切分成小片段,可以降低延迟,但是也增加了附加开销,还要处理片段之间依赖关系
- 需要改造MapReduce以支持流式处理(结果不能写入磁盘,IO消耗大,应该写入内存)
-
因此,Hadoop擅长批处理,不适合流计算
-
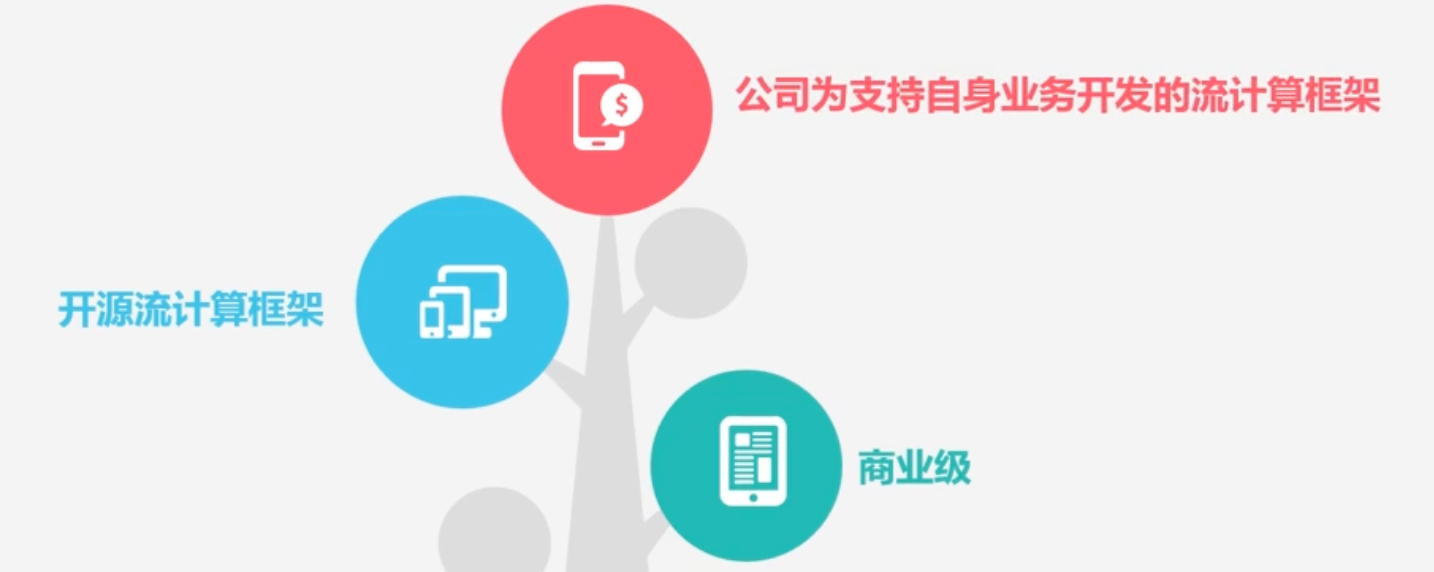
当前业界诞生了许多专门的流数据实时计算系统来满足各自需求
-
商业级:IBM InfoSphere Streams、IBM StreamBase
-
开源流计算框架:
- Twitter Storm:免费、开源的分布式实时计算系统、可简单、高效、可靠地处理大量的流数据
- Yahoo!S4(Simple Scalable Streaming System):开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统
-
公司为支持自身业务开发的流计算框架

-
11.2 流计算处理流程
-
传统的数据处理流程

- 传统的数据处理流程隐含两个前提
- 存储的数据肯定是旧的,存储的静态数据是过去某一时刻的快照,这些数据在查询时可能已不具备时效性
- 需要用户主动去发出查询来获取结果
- 传统的数据处理流程隐含两个前提
-
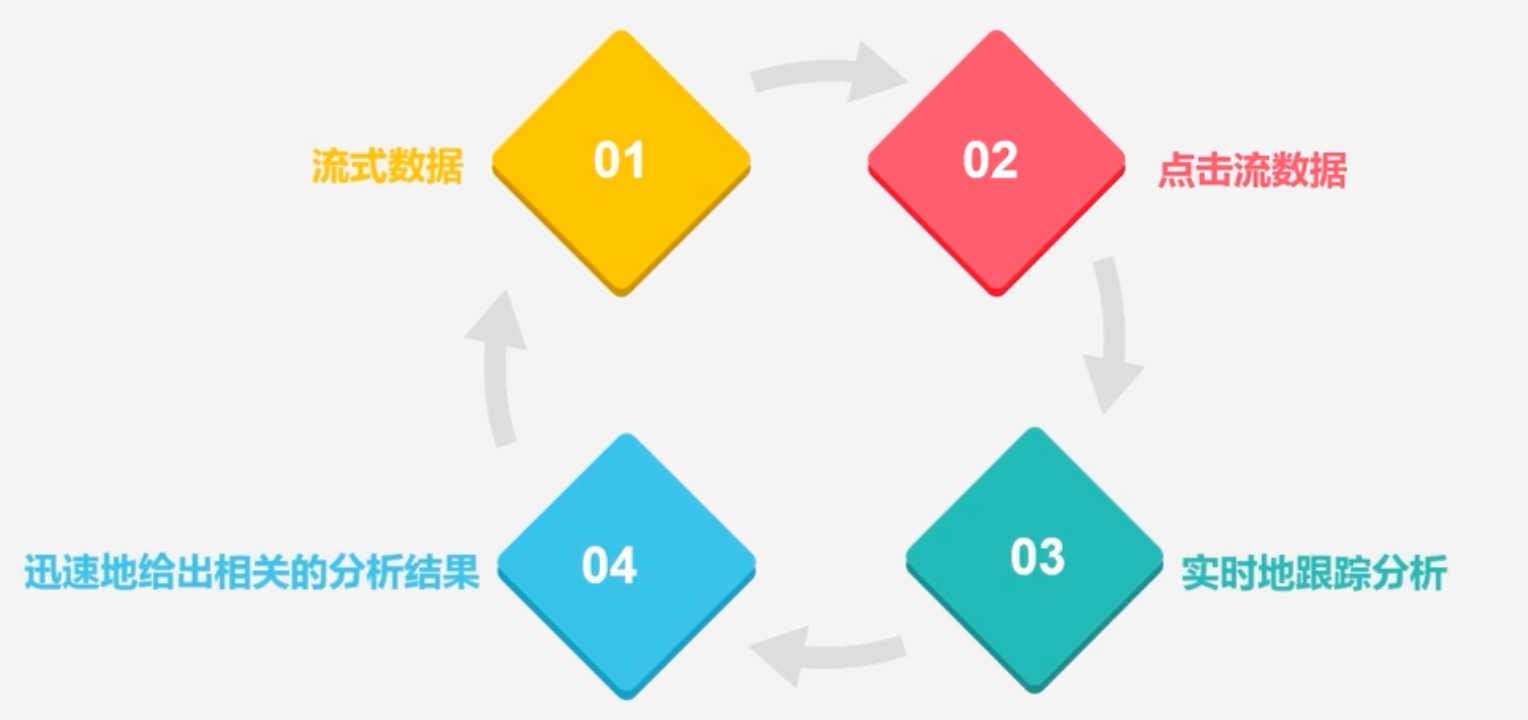
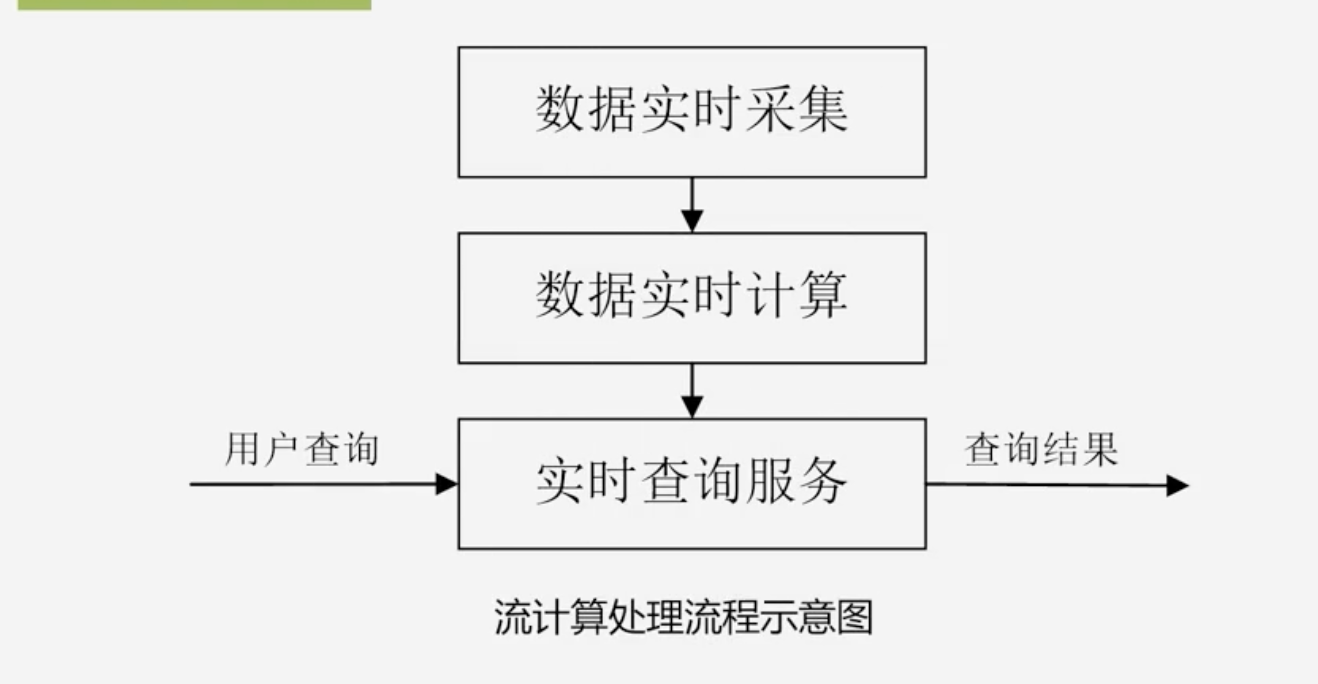
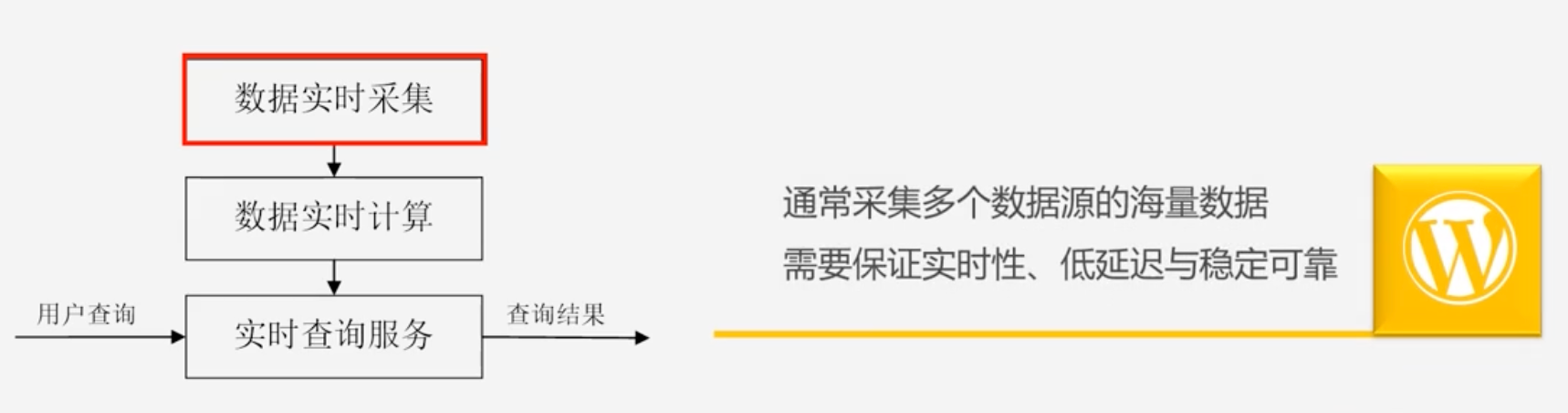
流计算的处理流程
-
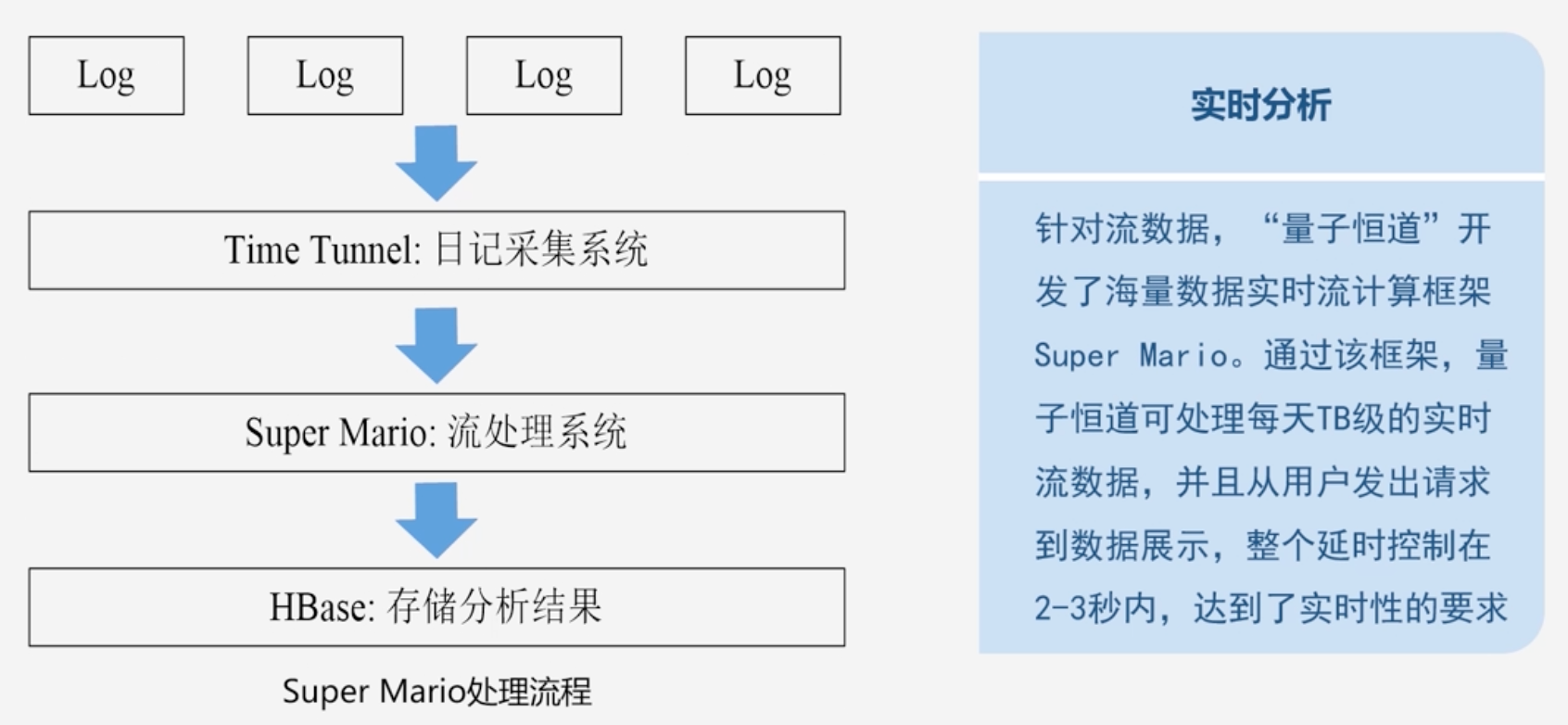
数据实时采集过程
- 日志数据为例:需要借助于相关的开源产品帮你从各个源系统上把日志采集过来
- 目前开源的分布式日志采集系统如:scribe、kafka、chukwa、flume
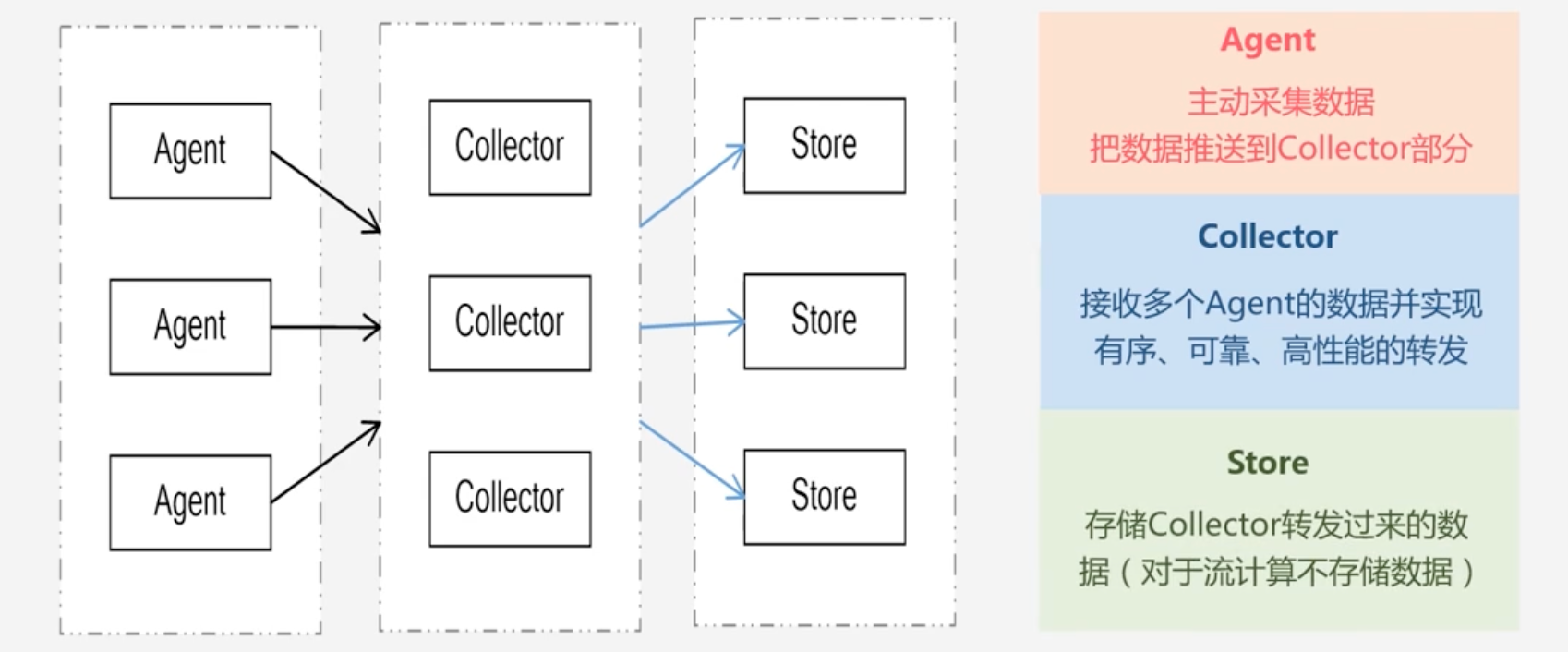
-
数据采集系统的基本架构
-
数据实时计算
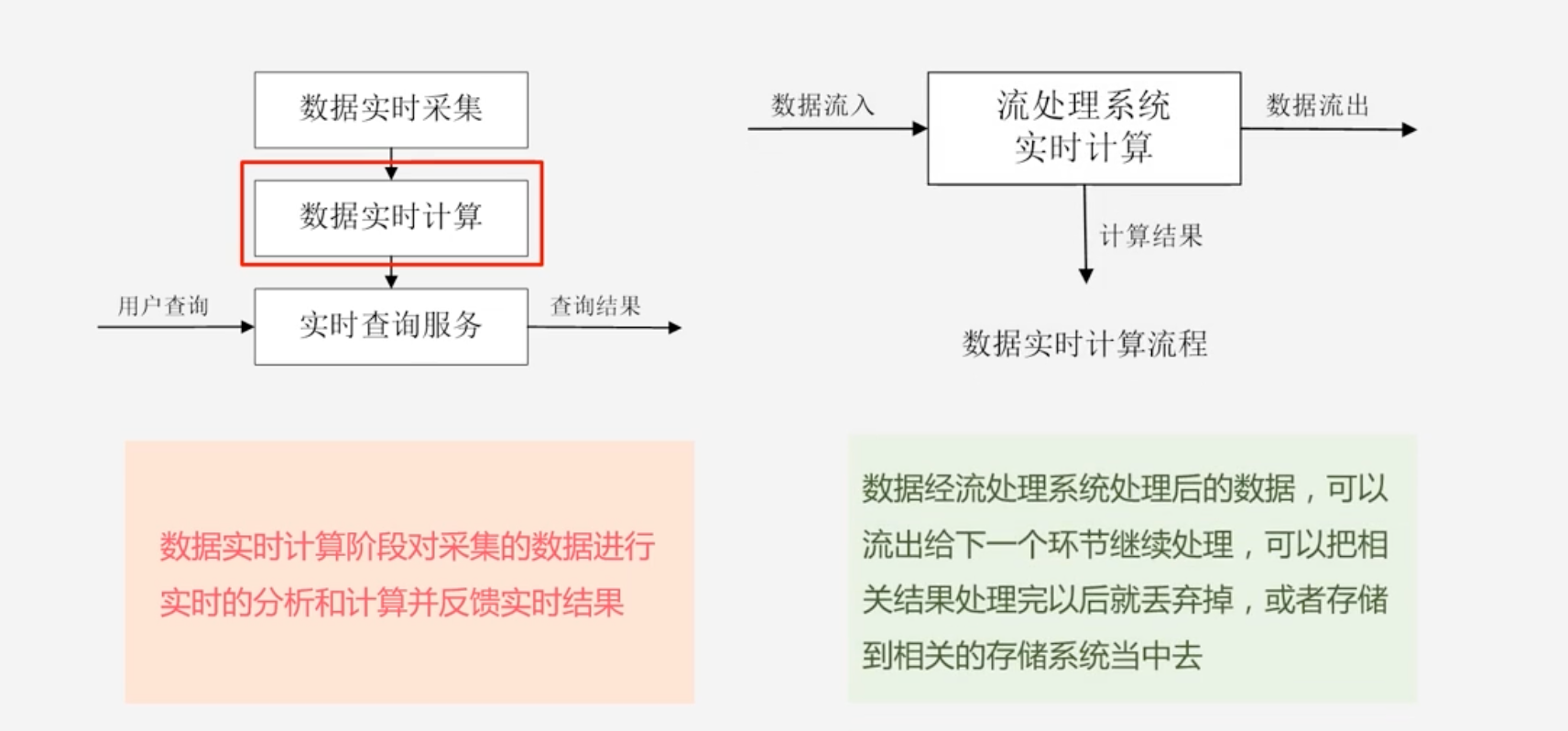
-
实时查询服务
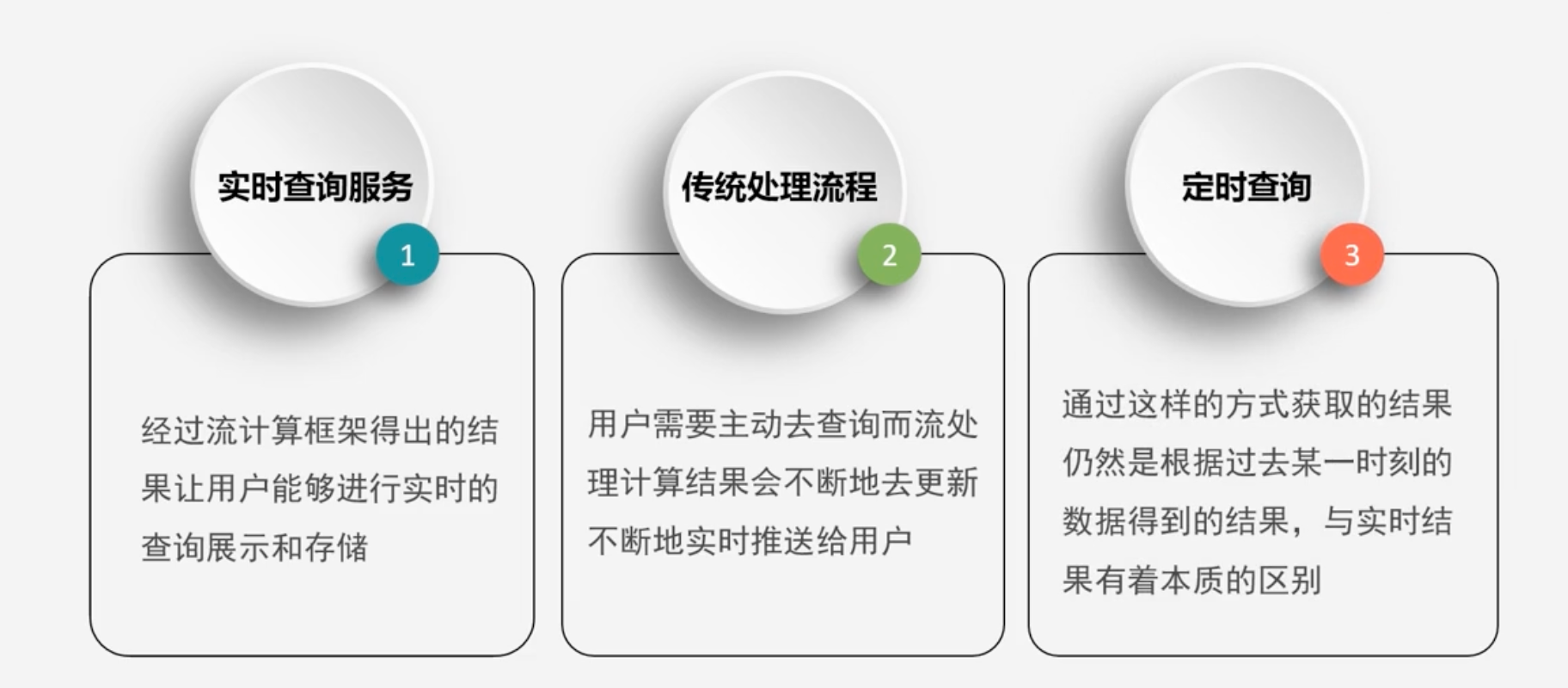
-
-
流处理系统和传统的数据处理系统的区别
- 流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据
- 用户通过流处理系统获取到的一般是实时结果而传统的数据处理方式获取的都是过去某一个历史时刻的快照
- 流处理系统不需要用户主动发出查询,它会实时地把生成的查询结果不断推送给用户
11.3 流计算的应用
-
传统的应用分析已经不适合现在的很多应用场景
-
流式处理可以实现实时性的要求
-
流计算可应用于实时交通
11.4 开源流计算框架Storm
11.4.1 Storm 简介
-
流计算的发展
-
以前只有政府机构和金融机构才会去做流计算,为了解决实时数据处理需求
-
开发产品都是基于对传统数据库处理的流式化,最终开发的都是实时数据库产品,很少有企业研究流计算框架

-
-
流计算框架在流式数据处理方面比MapReduce更有优势

-
Storm
- Storm是Twitter公司开发的一个开源免费框架
- Storm对于实时计算的意义就相当于Hadoop对于批处理的意义
-
三大分布式处理系统
- hadoop、Spark、Storm
-
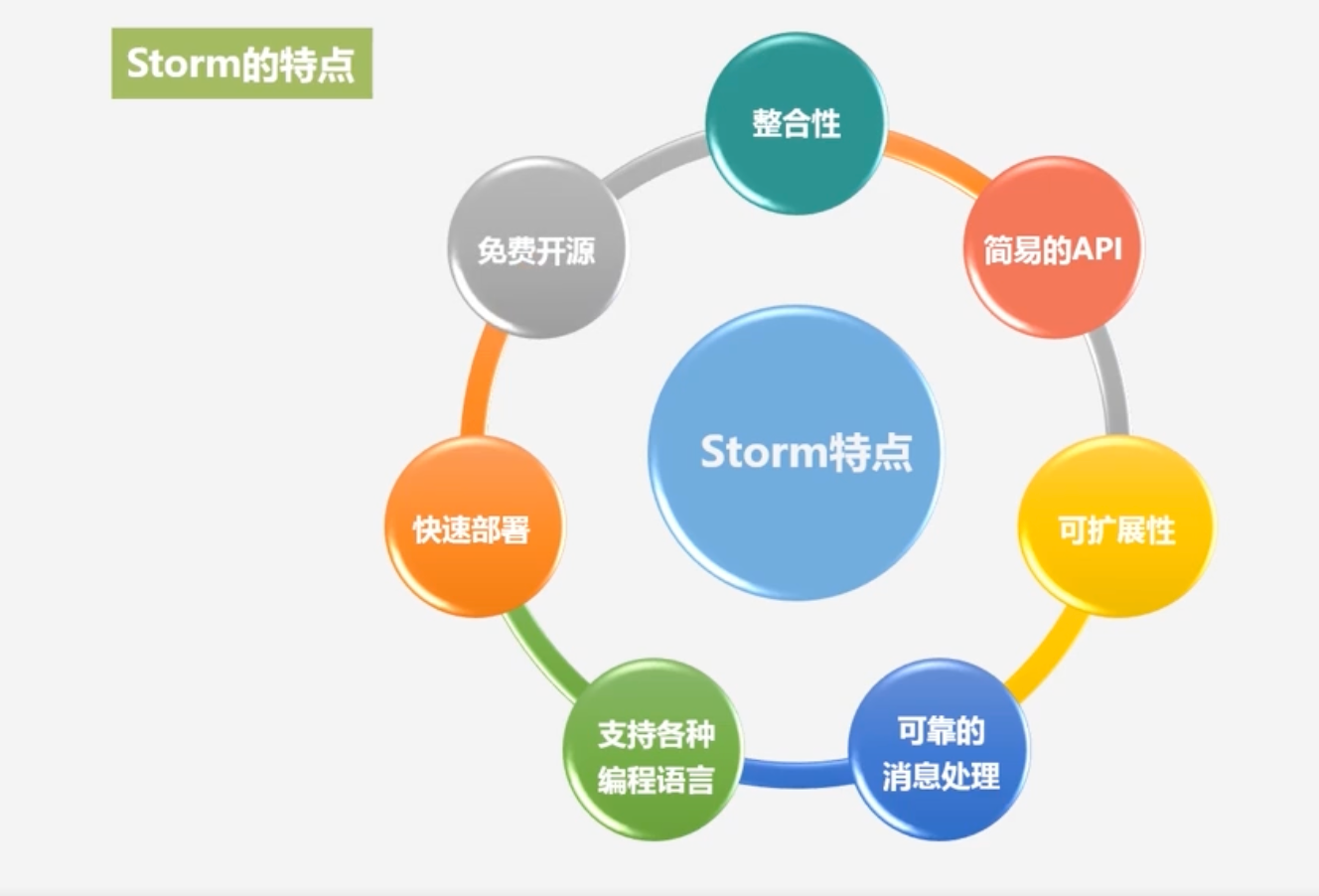
Storm的优点:
- 可以简单、高效、可靠地处理流数据,支持多种编程语言、处理非常灵活
- 可以非常方便地与现有的数据库系统产品进行融合,从而开发出非常强大的实时计算系统
-
以Twitter公司为例

-
Storm的特点
11.4.2 Storm设计思想
-
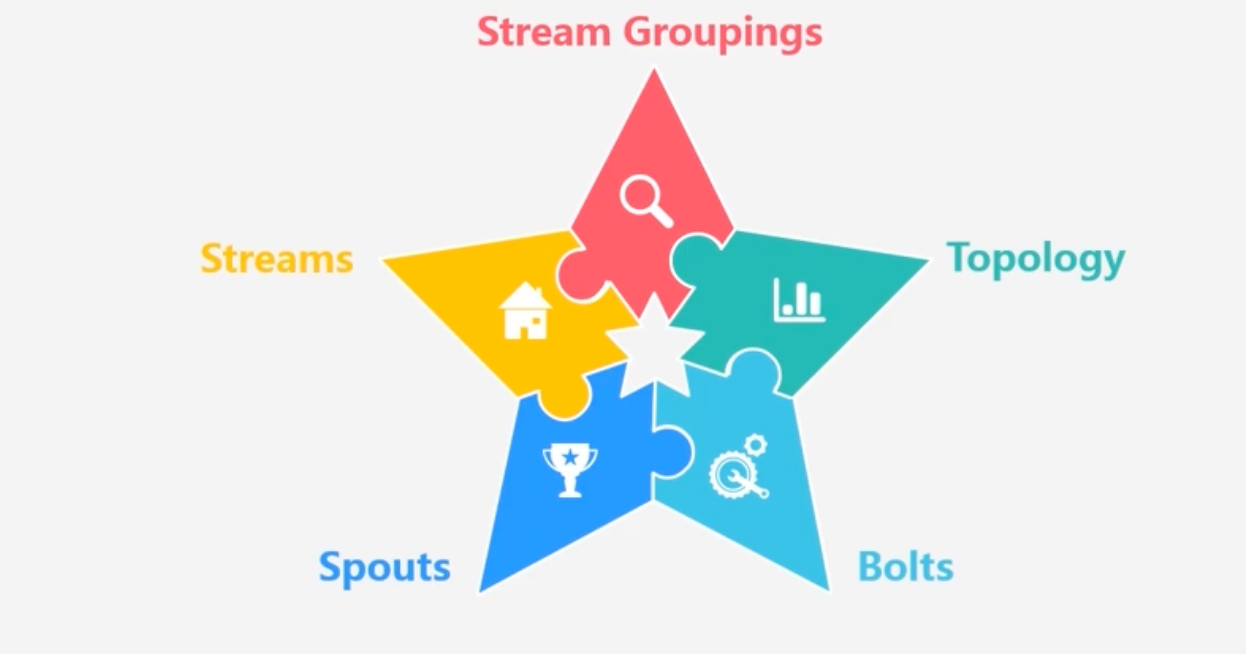
Storm主要术语
-
Stream:将流数据Stream描述成一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行的创建和处理
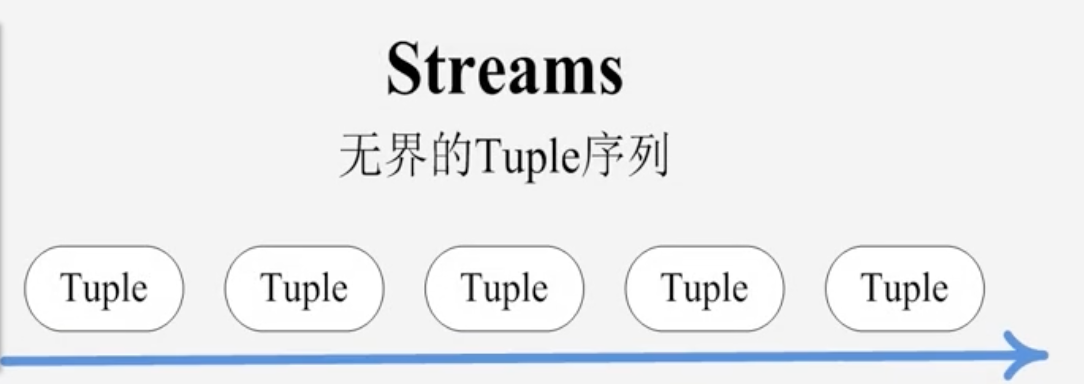
- 每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型
- Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按需填入各个Value,所以是一个Value Lisy(值列表)
-
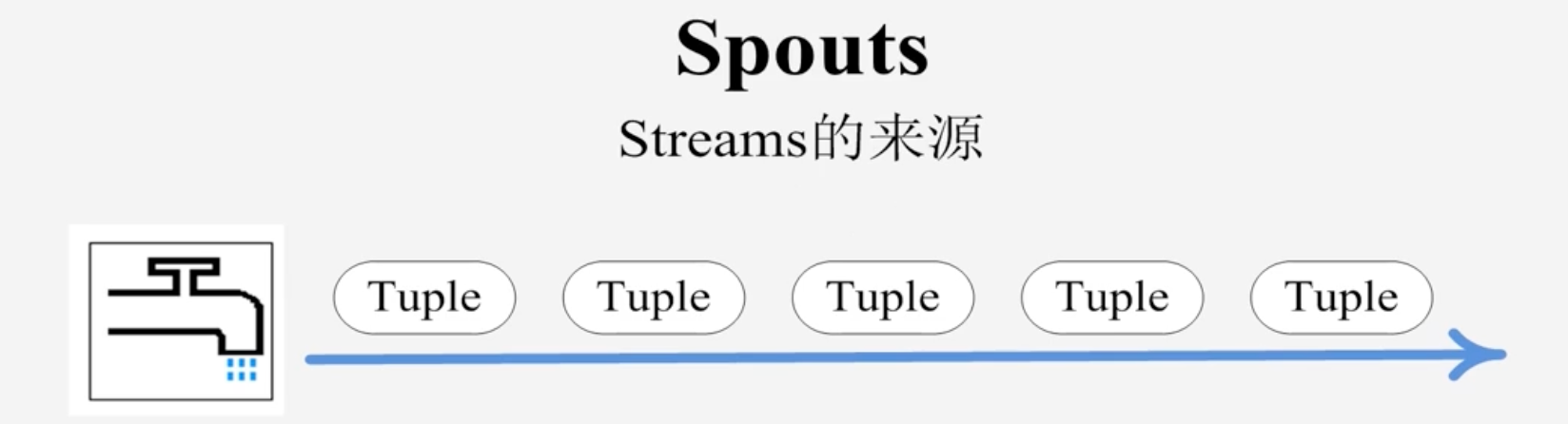
Spout
-
Storm认为每个Stream都有一个源头,并把这个源头抽象位Spout
-
通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,发送到Stream中
-
Spout是一个主动的角色,在接口内部有一个nextTuple函数,Storm框架会不停的调用该函数
-
-
Bolt
-
Storm将Streams的状态转化过程抽象为Bolt
-
Bolt即可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送给其他Bolt
-
Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作
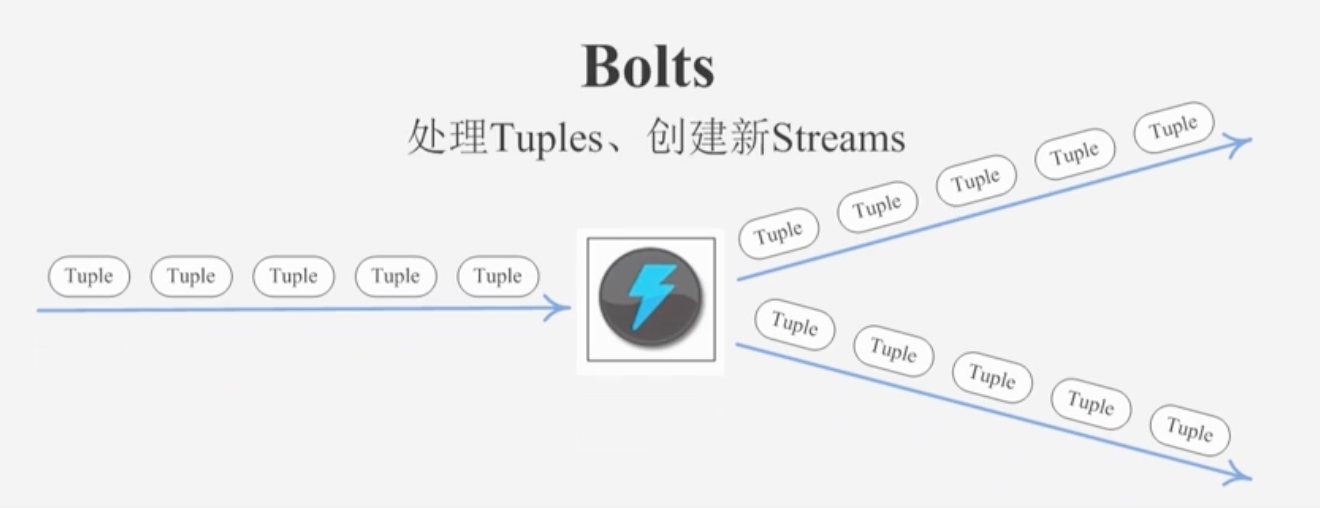
注意:Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用次函数,用户可以在此方法中执行自己的处理逻辑
-
-
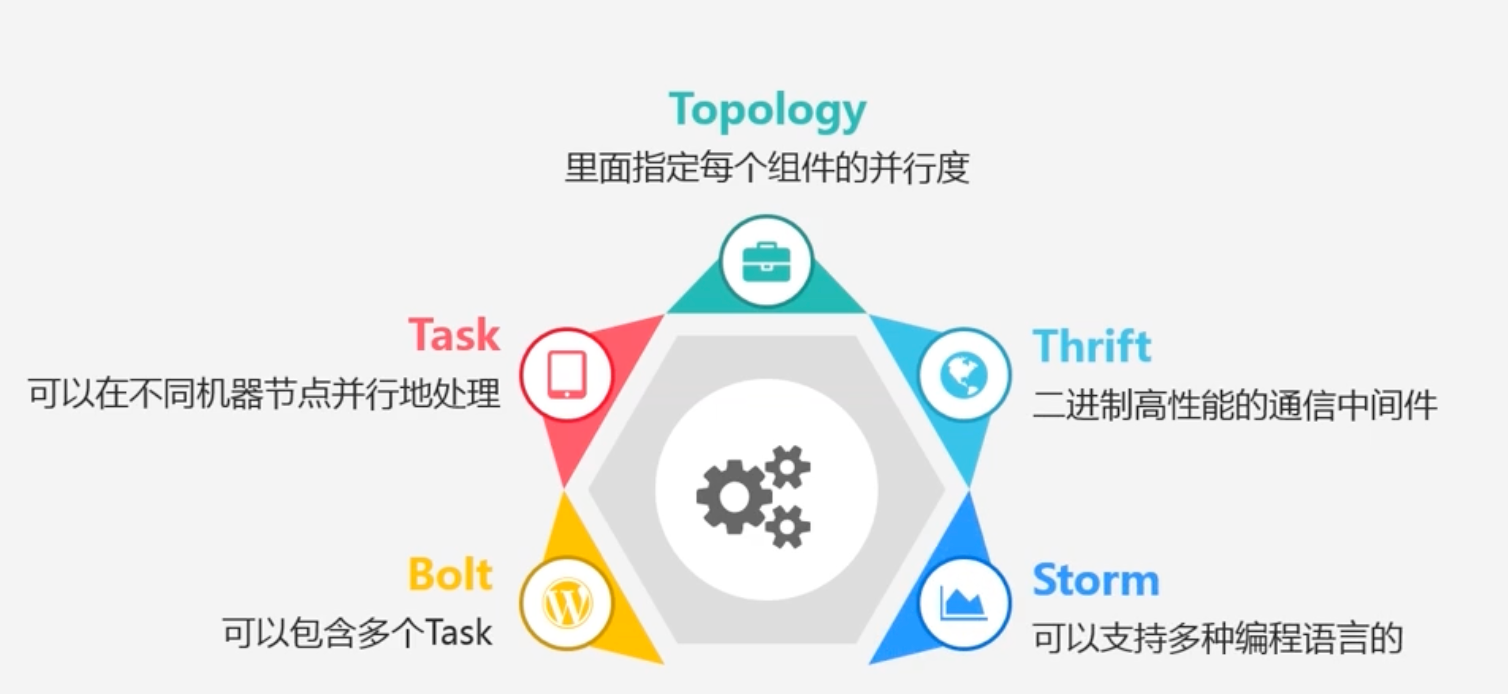
Topology:相当于应用程序中的Job,流计算任务是以Topology的形式提交
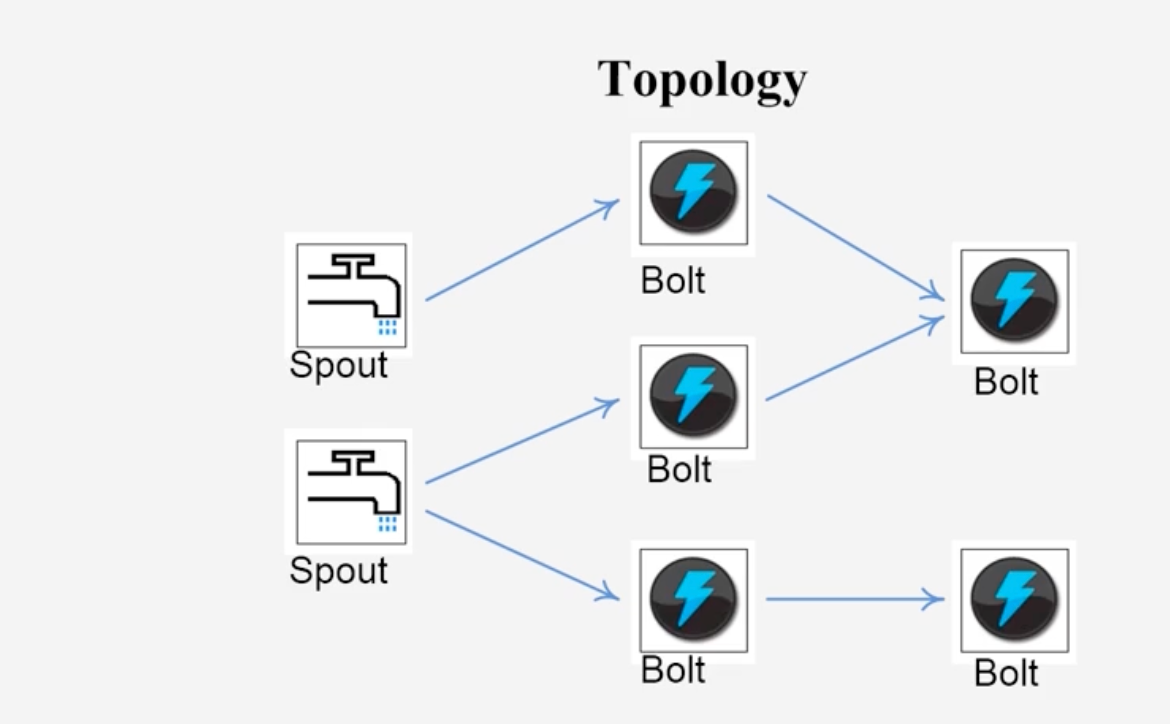
Topology中每一个组件(Bolt或者Spout)之间都是并行运行的
其中每个Bolt里面是可以包含多个Task任务的
-
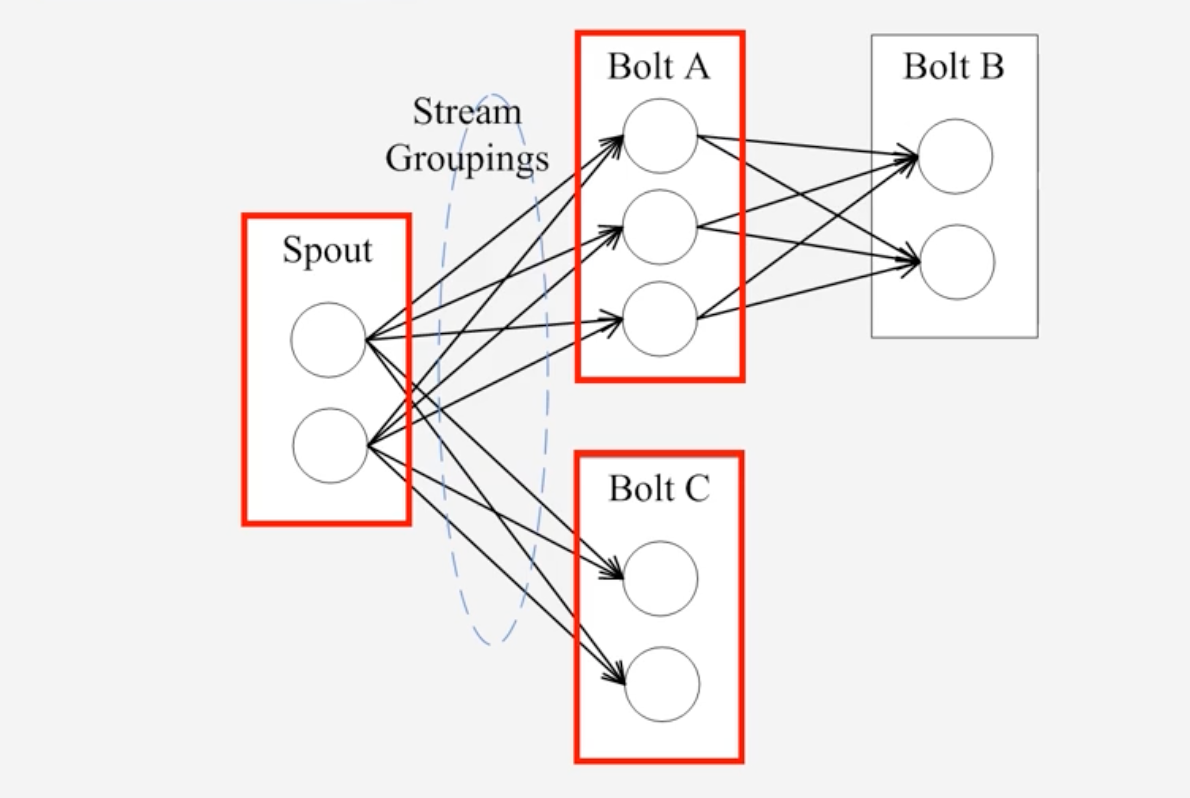
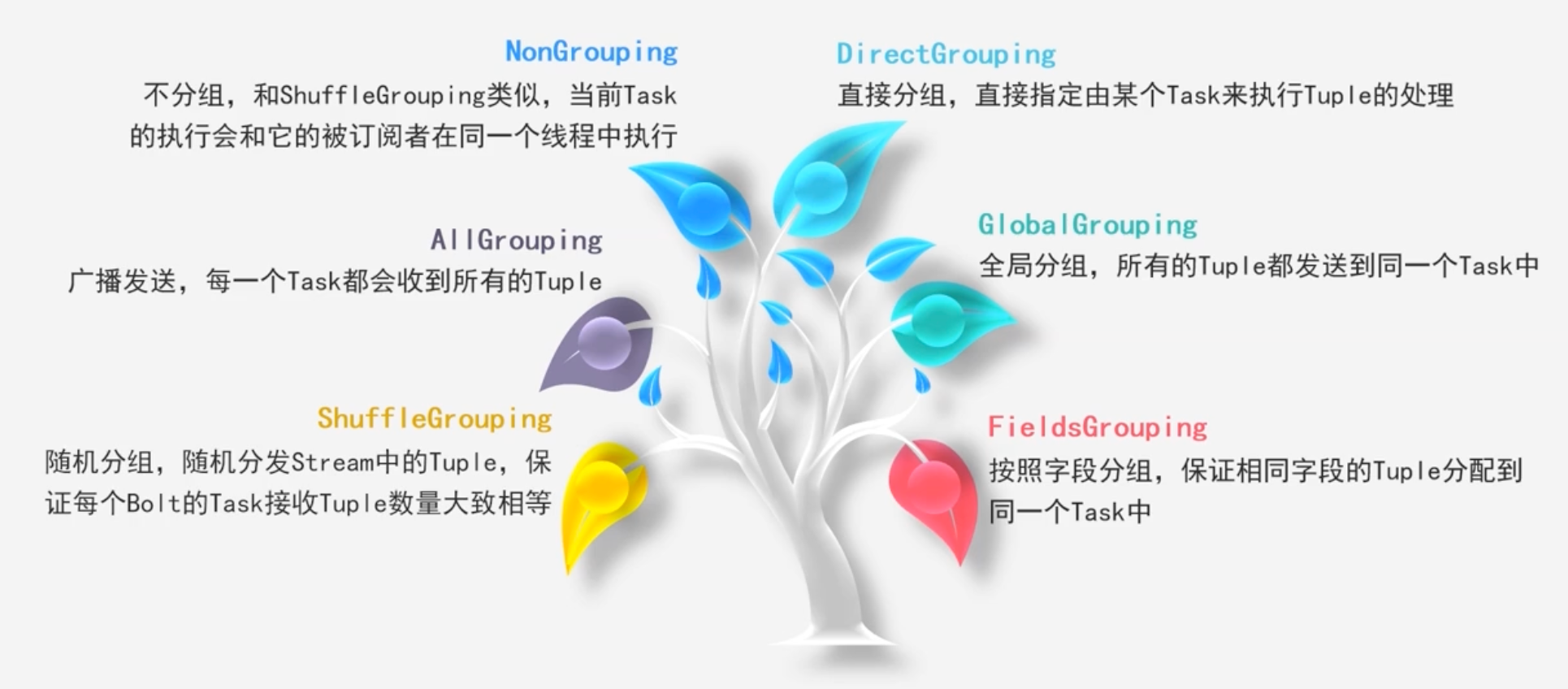
Stream Groupings
- 一个Spout或者Bolt内都有着多个Task,可以并行执行
-
通过设置StreamGrouping可以设置将Spout分发给Bolt中的哪一个Task来执行
11.4.3 Storm框架设计
-
Storm运行任务的方式与Hadoop类似
- Hadoop运行的是MapReduce作业,而Storm运行的是“Topology”
-
Storm和Hadoop架构组织功能对应关系

MapReduce作业最终会完成计算并结束运行
而Topology将持续处理消息(直到人为终止)
-
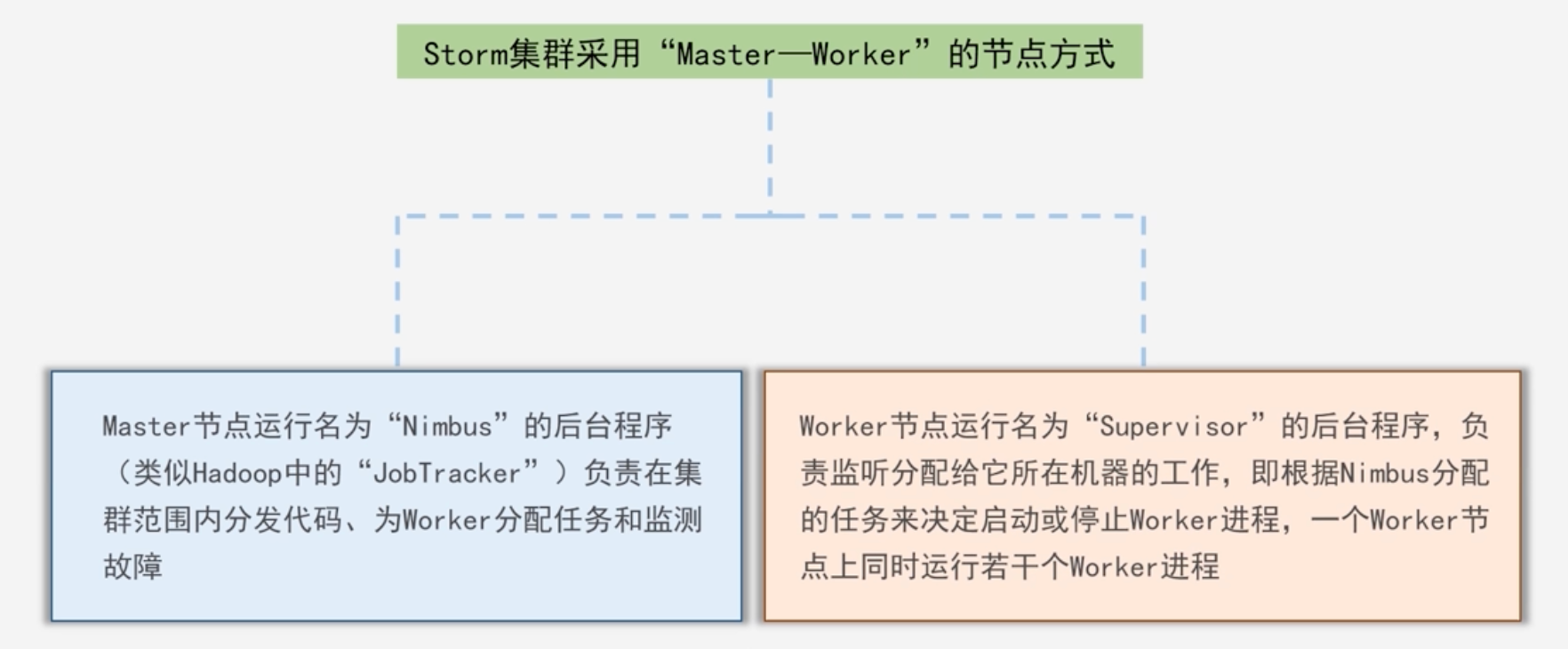
Storm集群采用“Master-Worker”的节点方式
-
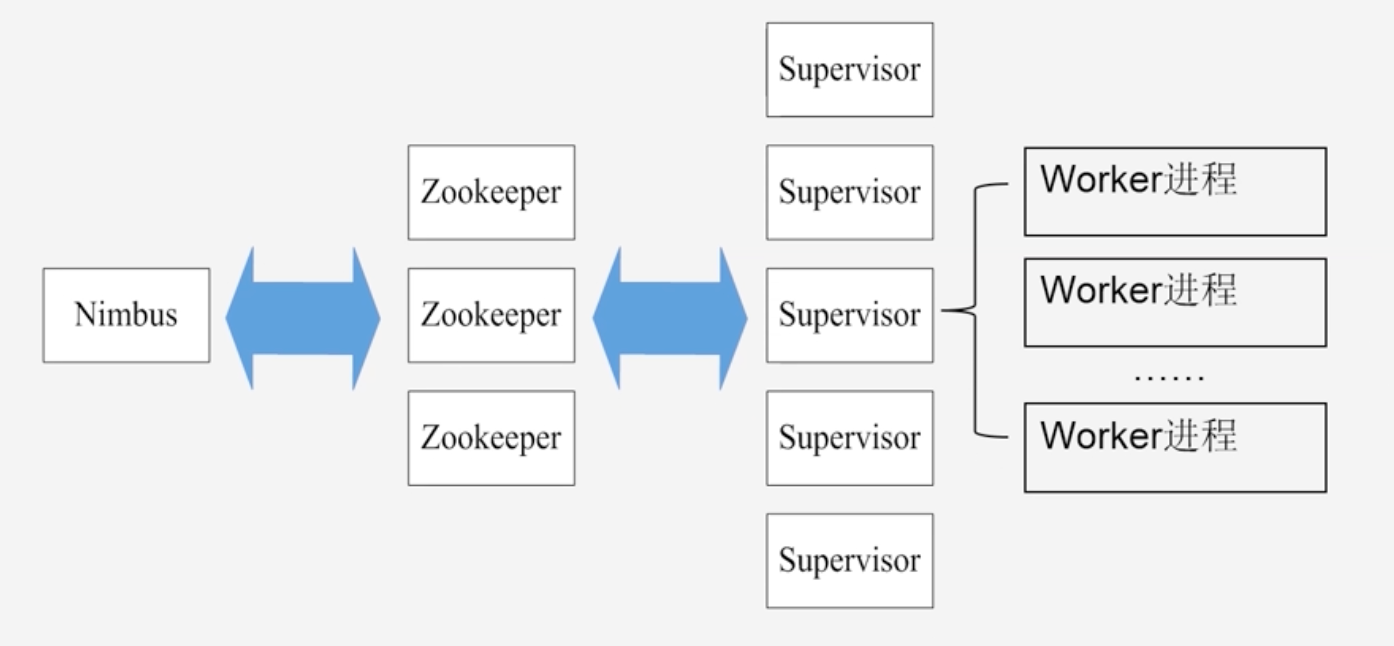
Storm集群架构示意图
-
Storm使用Zookeeper来作为分布式协调组件,负责Nimbus和多个Supervisor之间的所有协调工作
- Nimbus将任务分配给相应的Supervisor,Supervisor拿到任务将任务分配给Worker进程去启动
- 所有的Nimbus和Supervisor的状态信息都交给Zookeeper来保存
- 借助Zookeeper,若Nimbus进程或者Supervisor进程意外终止,重启时也能读取、恢复之前的状态,并继续工作,使得Storm极其稳定
-
-
Worker进程
-
每个worker进程都属于一个特定的Topology,每个Supervisor节点的worker可以有多个,每个worker对Topology的每个组件(Spout或Bolt)运行一个或者多个executor线程来提供Task的运行服务
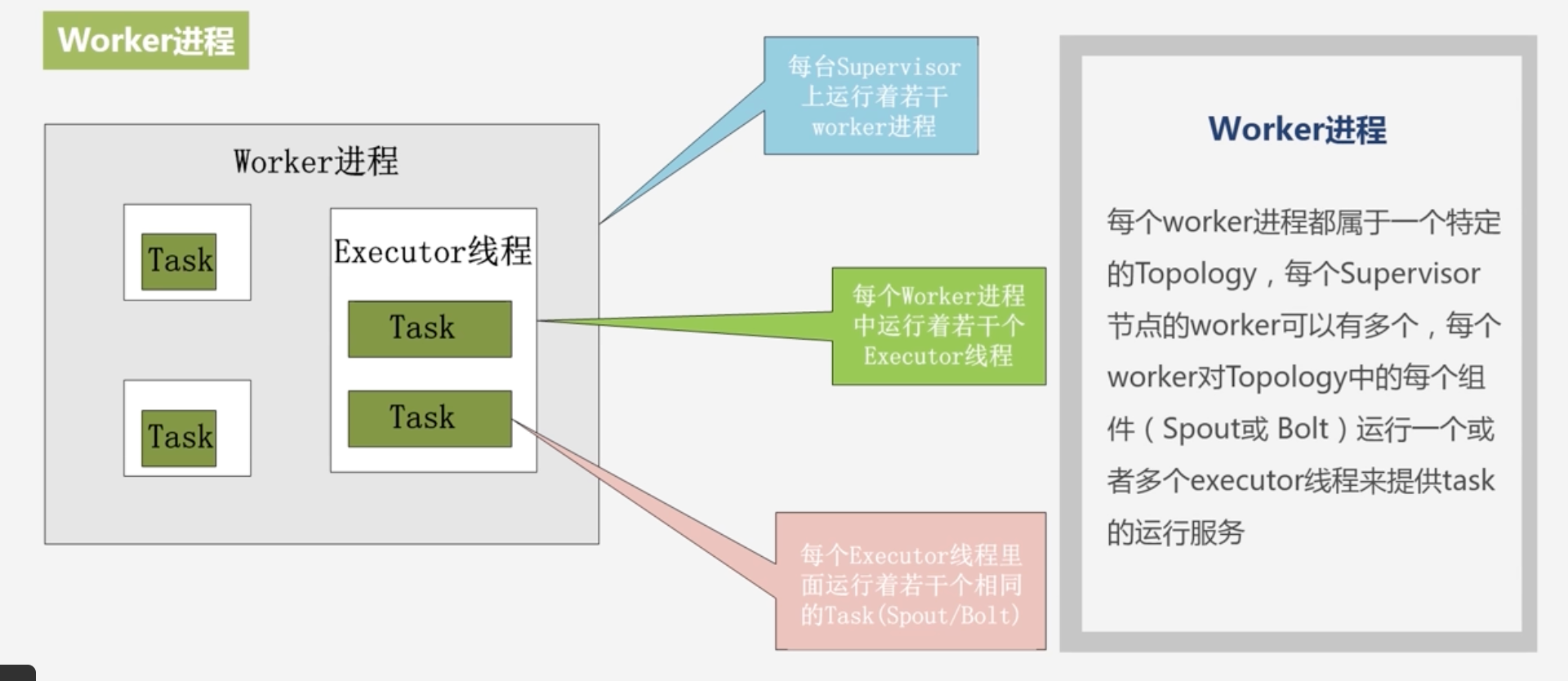
Executor:excutor是产生于worker进程内部的线程,会执行同一个组件的一个或者多个Task
一般Topology生命周期中每个组件对应的Task数量是不变的,但是Executora的数量是变化的
一般Executor的数量是小于Task的
实际的数据处理都是由Task完成的
-
-
Storm工作流程
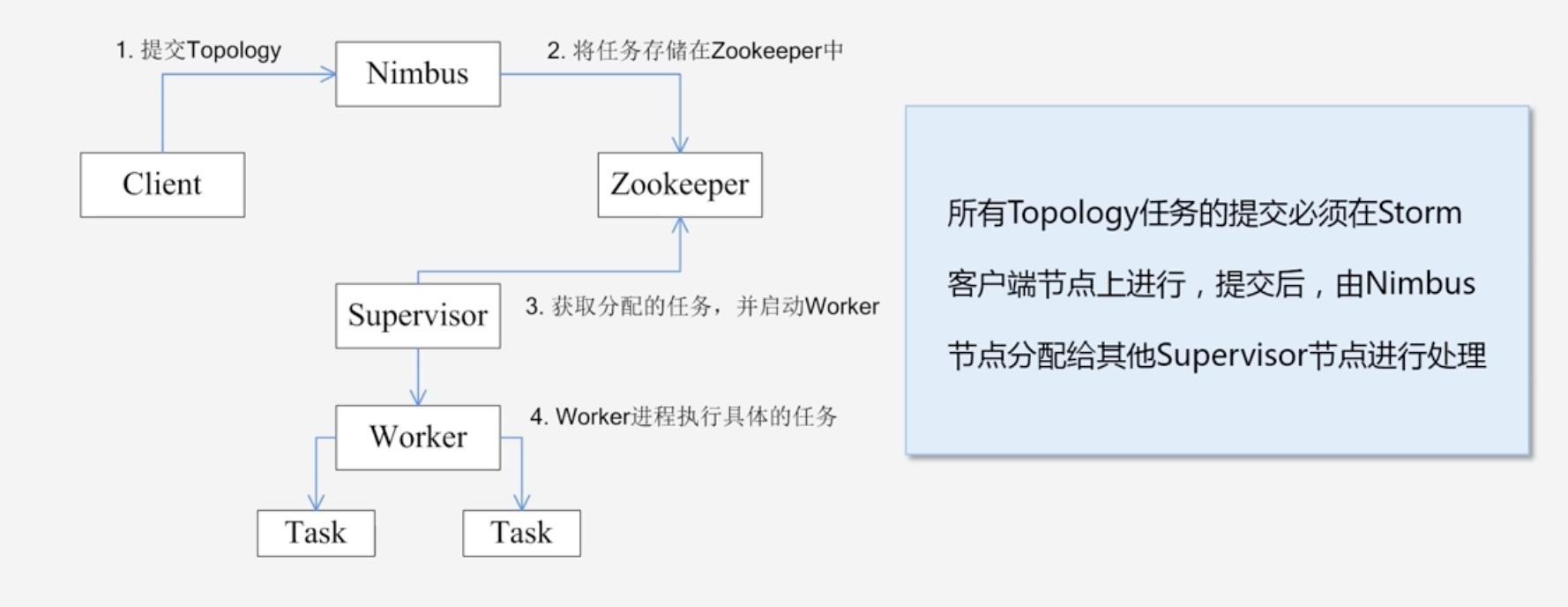
- Nimbus节点首先将提交的Topology进行分片,分成一个个Task,分配给相应的Supervisor,并将Task和Supervisor相关的信息提交到Zookeeper集群上
- Supervisor会去Zookeeper集群上认领自己的Task,通知自己的Worker进程进行Task的处理
11.5 Spark Spark Streaming Samza以及三种流计算框架比较
-
Spark Streaming
-
Spark Streaming 可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字,经处理后的数据可存储至文件系统、数据库,或显示在仪表盘中

-
-
Spark Streaming执行流程
-
其基本原理:将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据

-
DStream操作示意图
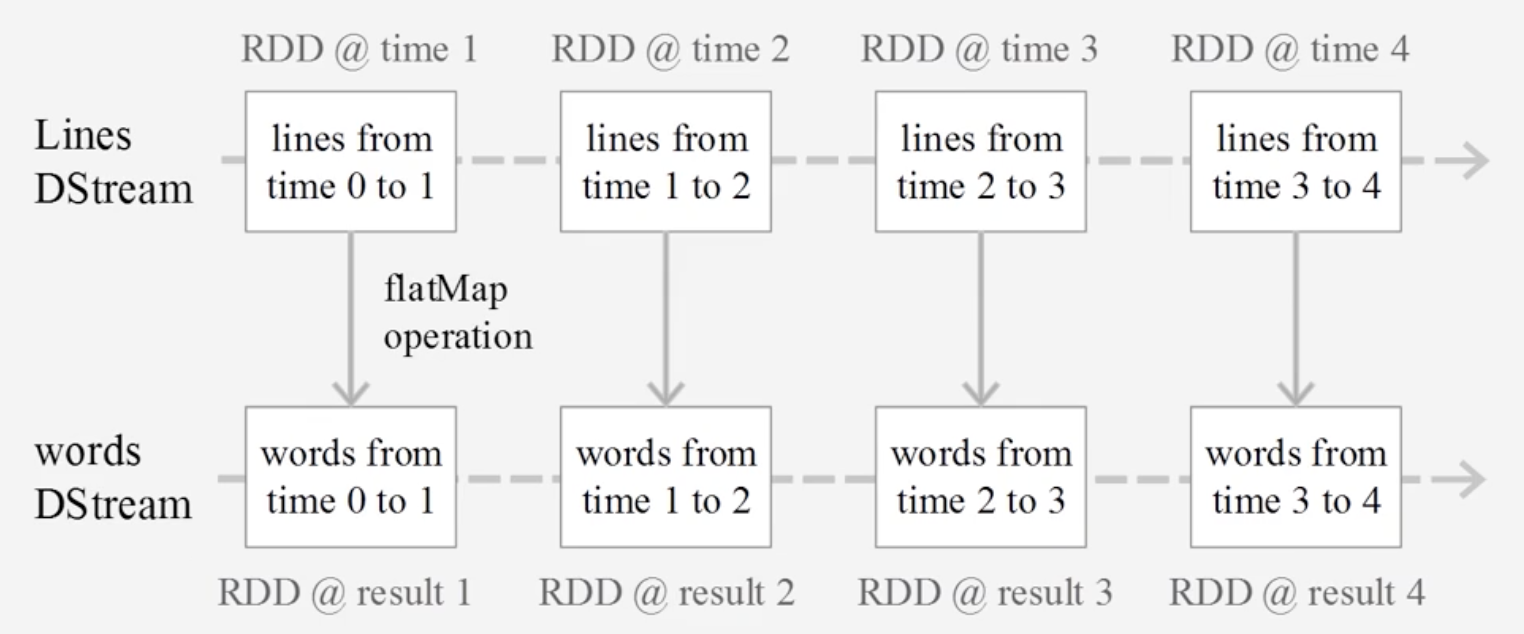
Spark Streaming最主要的抽象是DStream (Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒) 分成一段一段的DStream,每一段数据转换为Spark中的RDD,并且对Dstream的操作都最终转变为对相应的RDD的操作
-
-
Spark Streaming和Storm的对比
- Spark Streaming 无法实现毫秒级的流计算,而Storm可以实现毫秒级响应
- Spark Streaming是构建在Spark伤的,Spark的低延迟执行(100ms+)可以用于实时计算。相比于Storm,RDD数据集更容易做高效的容错处理
- Spark Streaming采用的小批量处理的方式使得它可以同时兼容批量和实时处理的逻辑和算法,因此,方便了一些需要历史数据和实时数据联合分析的特定应用场景
-
Samza
-
基本概念
-
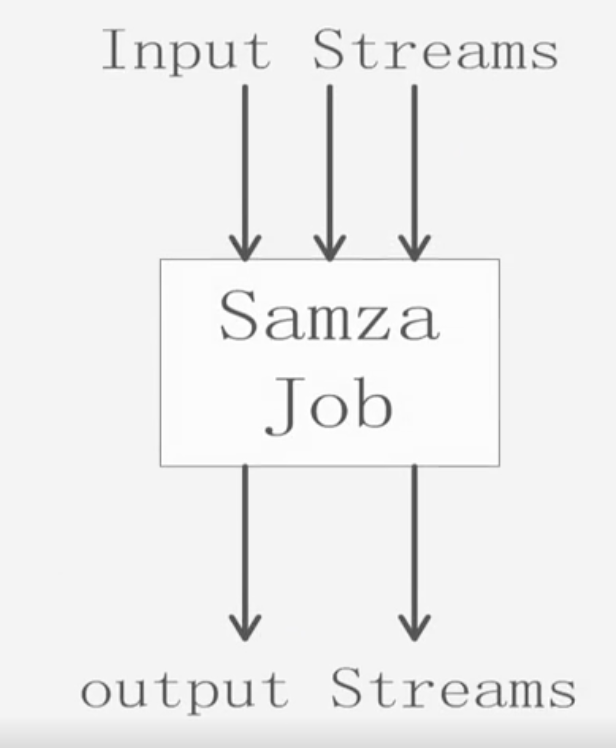
作业:一个作业(Job)是对一组输入流进行处理转换成输出流的程序
-
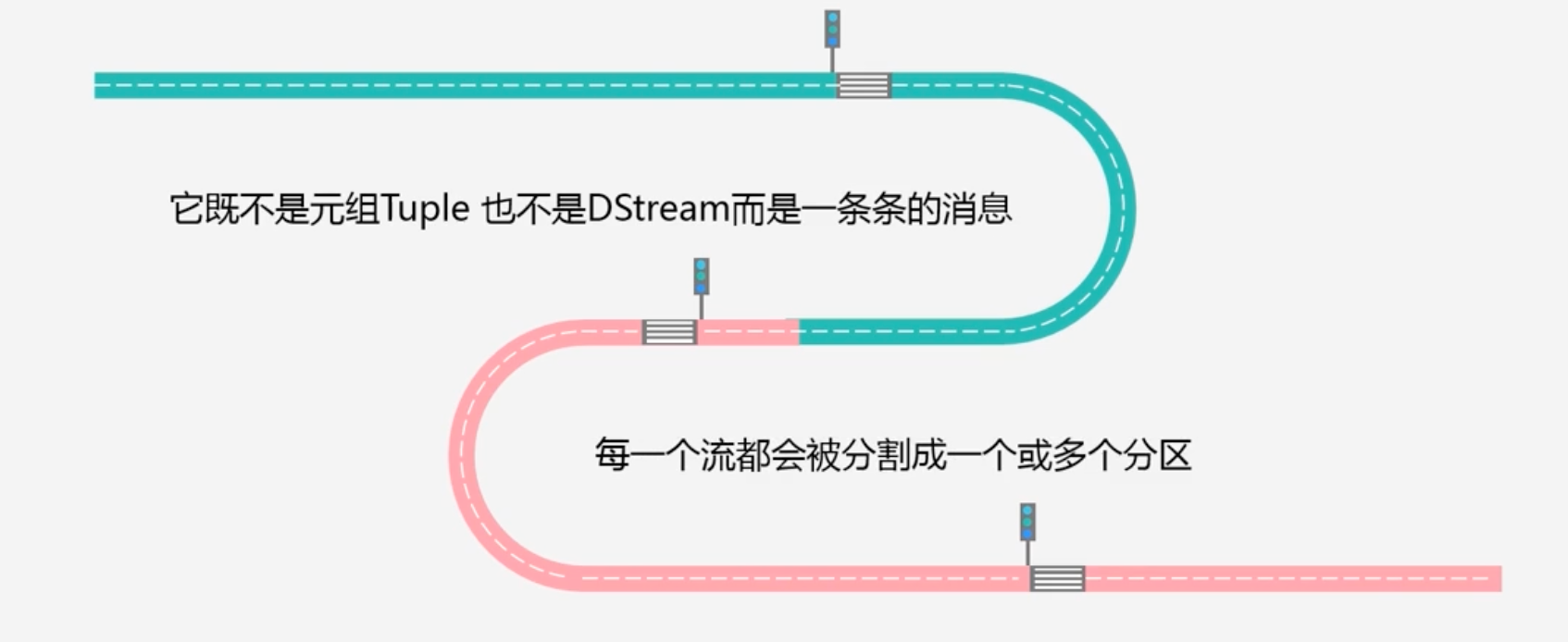
分区:既不是元组Tuple,也不是Stream,而是一条条的消息;每个流会被分成一个或者多个分区
-
它将数据流划分为分区,每个分区都是一个有趣的消息队列
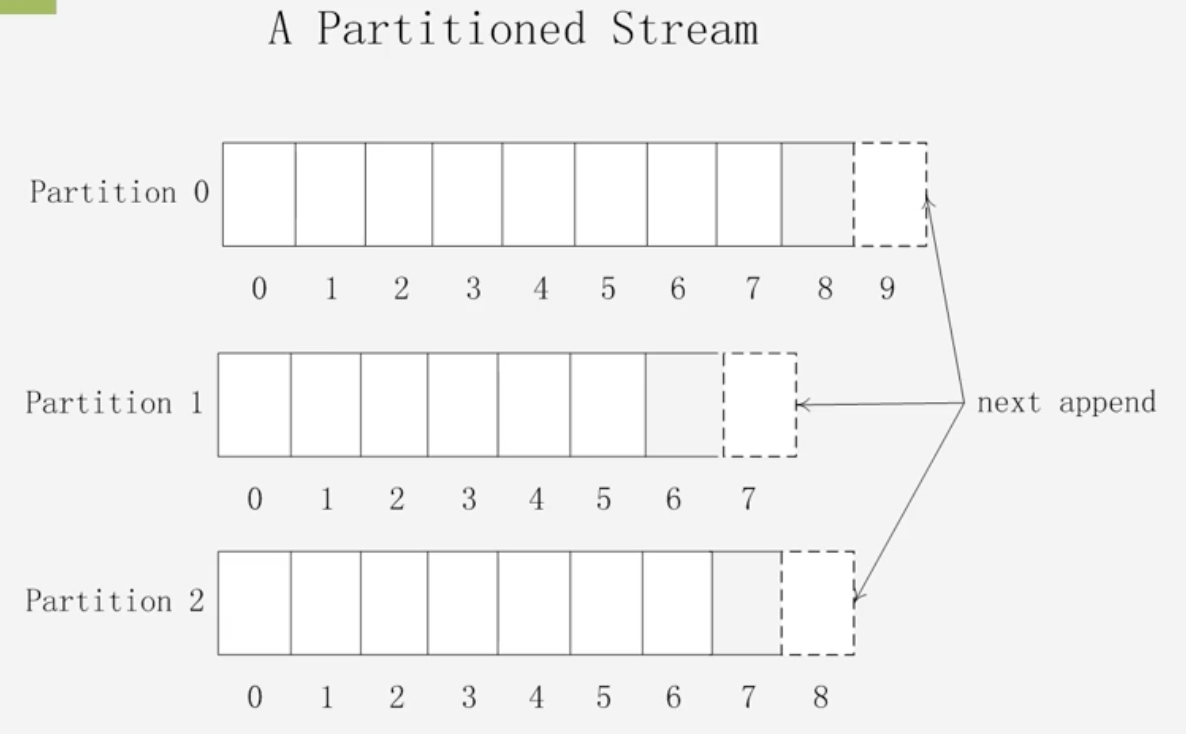
-
-
任务
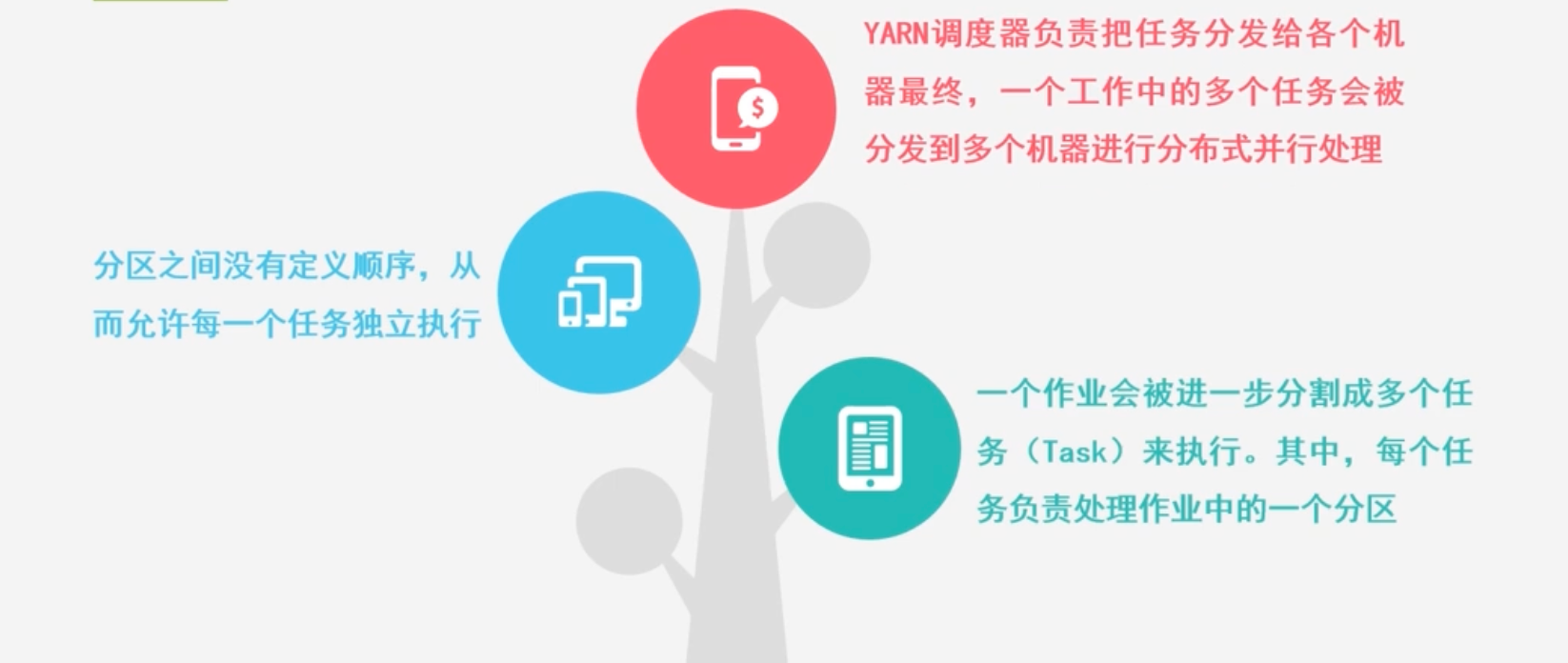
-
-
数据流图
-
是通过多个作业串联起来,构成这么一个完整的数据流图才可以完成一个完整的流数据处理流程
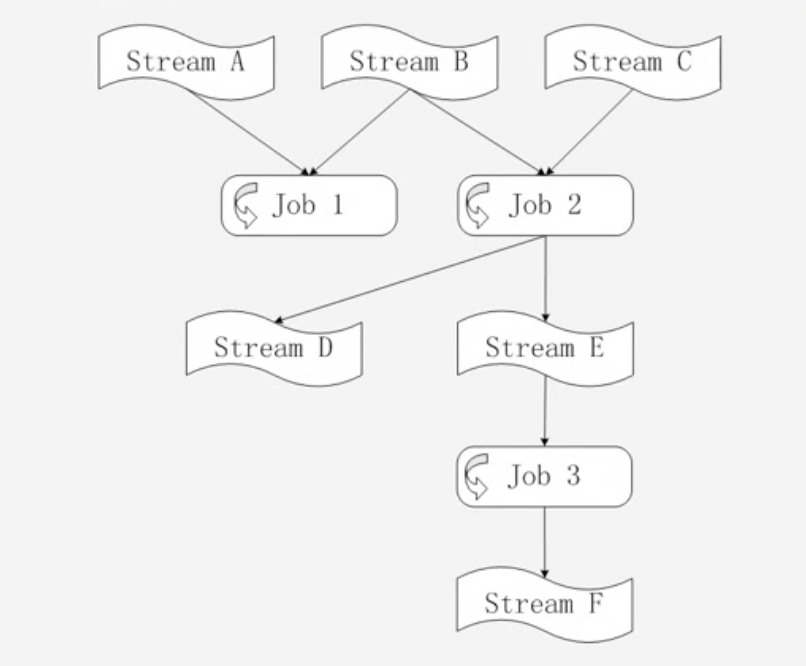
-
-
Samza系统架构
- 包括流数据层、执行层、处理层
- 流数据层
- 负责数据流的收集分发,流处理层和执行层都被设计成可插拔的,开发人员可以使用其他框架替代YARN和Kafka
-
-
MapReduce批处理架构和Samza流处理架构的类比
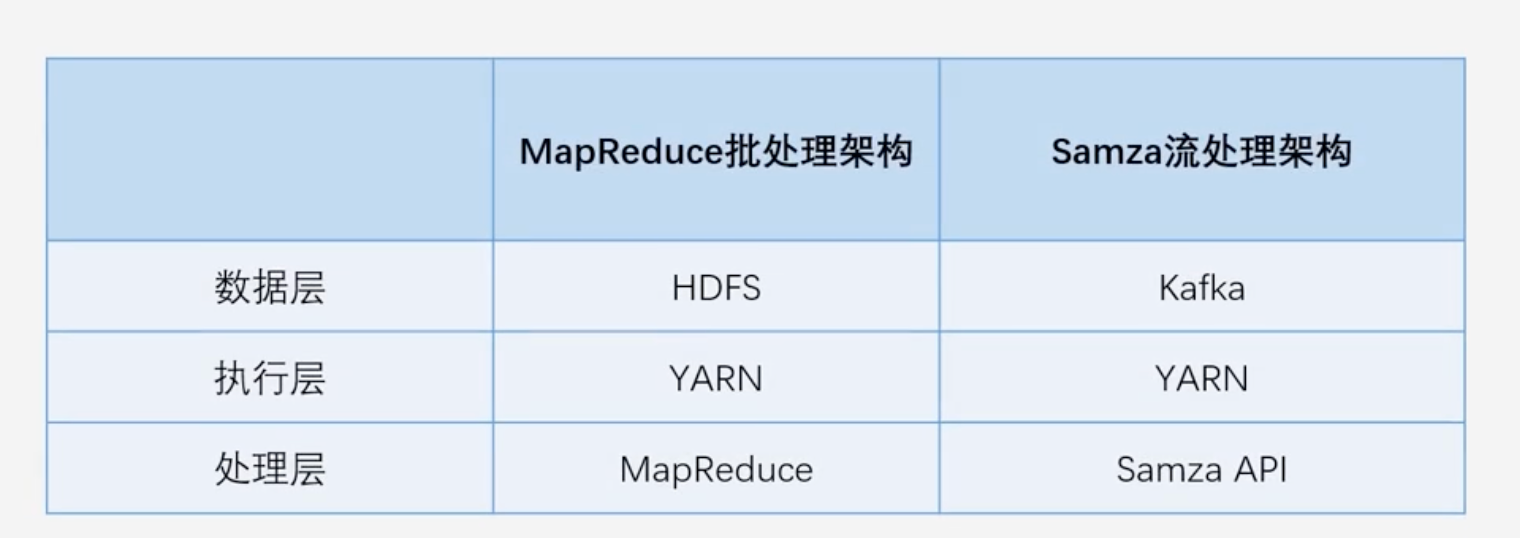
-
Samza处理分析过程
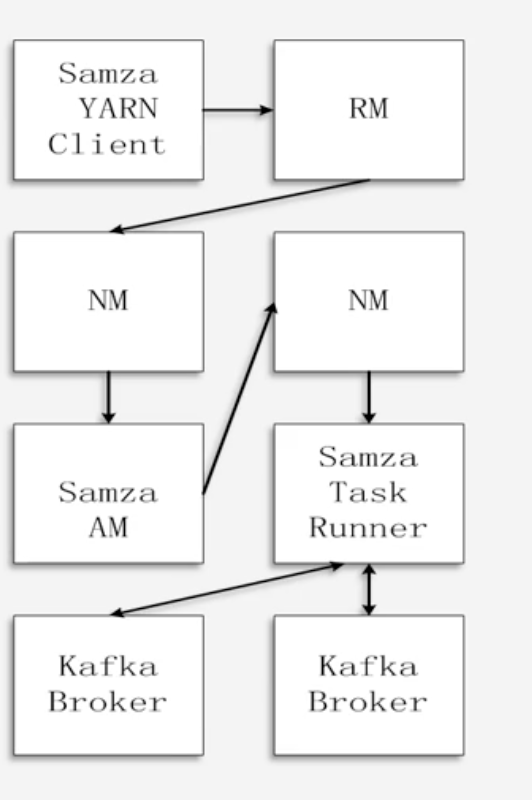
- 1.Samza客户端需要执行一个Samza作业时,它会向YARN的ResourceManager提交作业请求
- 2.ResouceManager和NodeManager沟通,为该作业分配容器(包含CPU、内存等资源)来运行Samza ApplicationMaster
- 3.Samza ApplicationMaster进一步向ResourceManager申请运行任务的容器
- 4.获得容器后,Samza ApplicationMaster与容器所在的NodeManager沟通启动该容器,并在其中运行Samza Task Runner
- 5.Samza Task Runner负责执行具体的Samza任务,完成流数据处理分析
- Kafka Broker:完成消息的处理、分发等
-
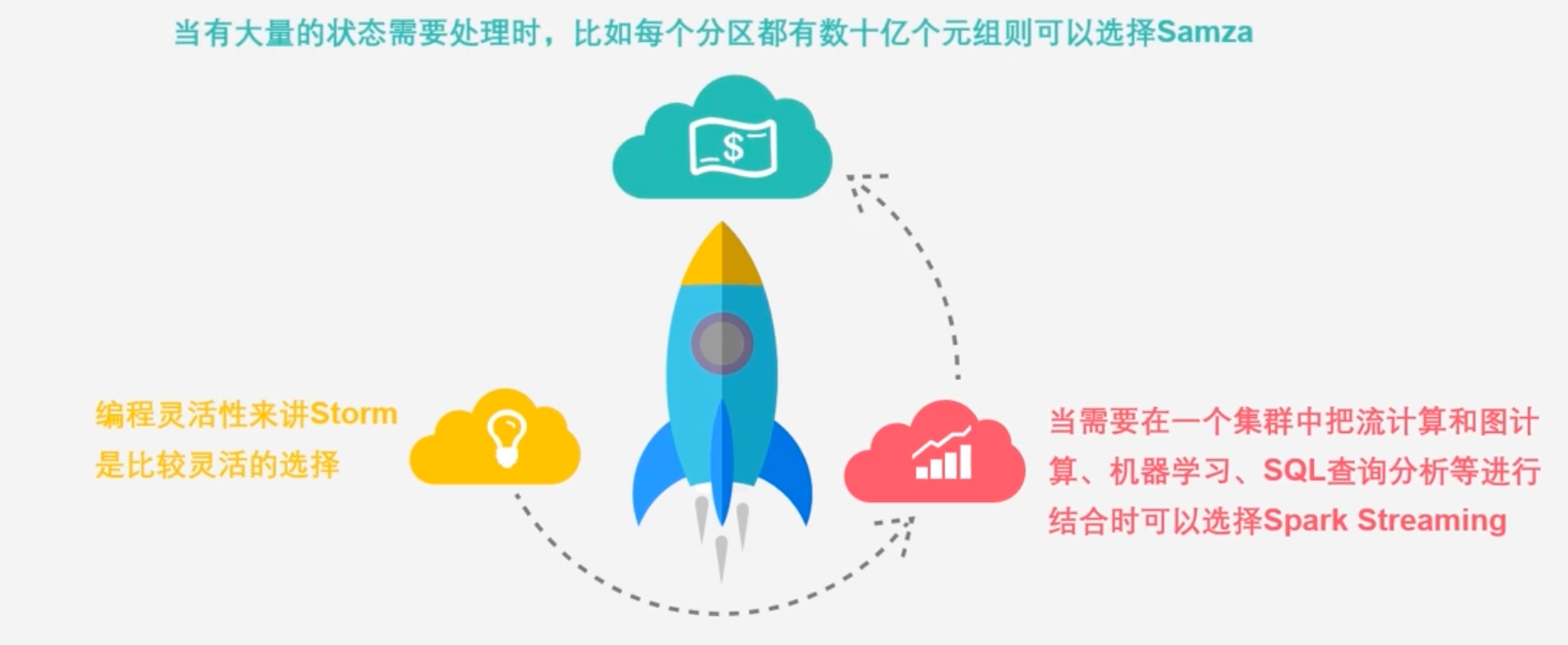
Storm Spark Streaming和Samaza应用场景
11.6 Storm 的安装和编程实例
11.6.1 编写Storm程序
-
程序任务:单词统计

-
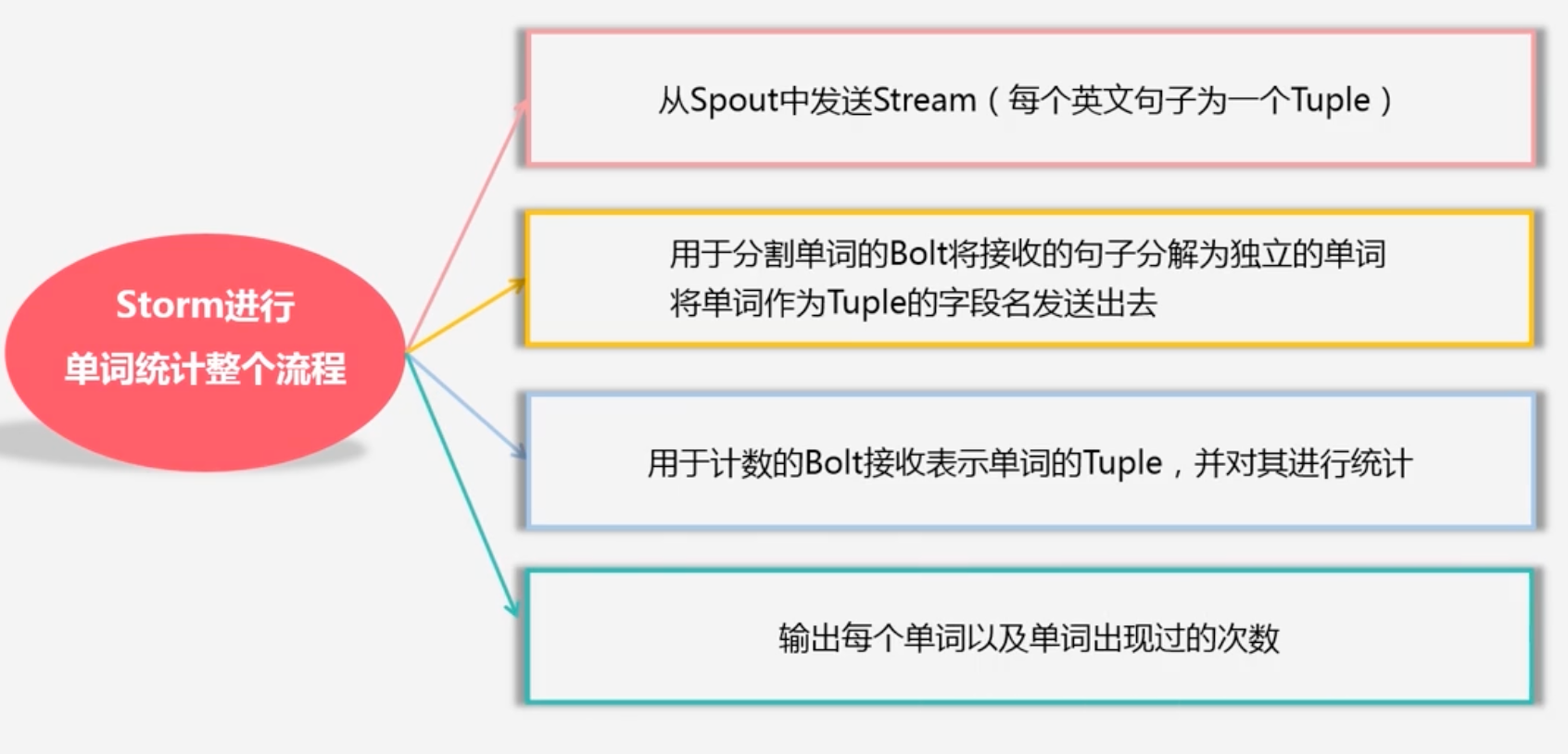
Storm进行单词统计整个流程
-
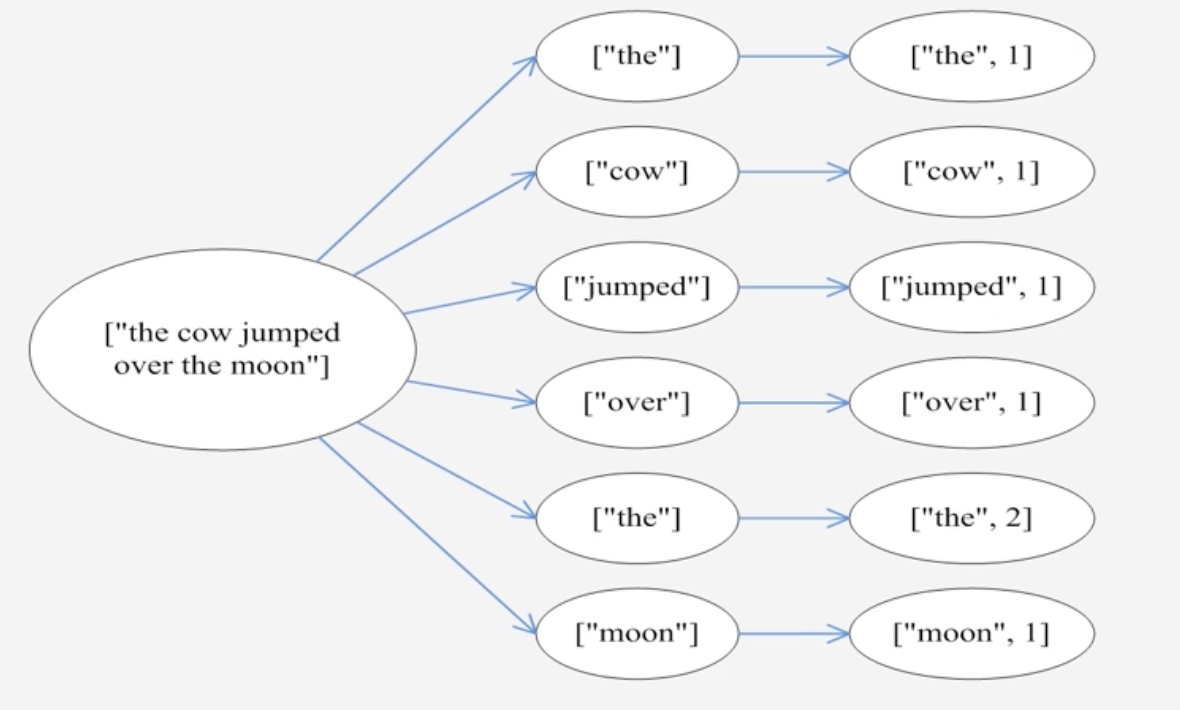
一个句子经Storm的单词统计得出的结果
-
整个单词统计Topology的整体逻辑

-
main函数中的处理逻辑
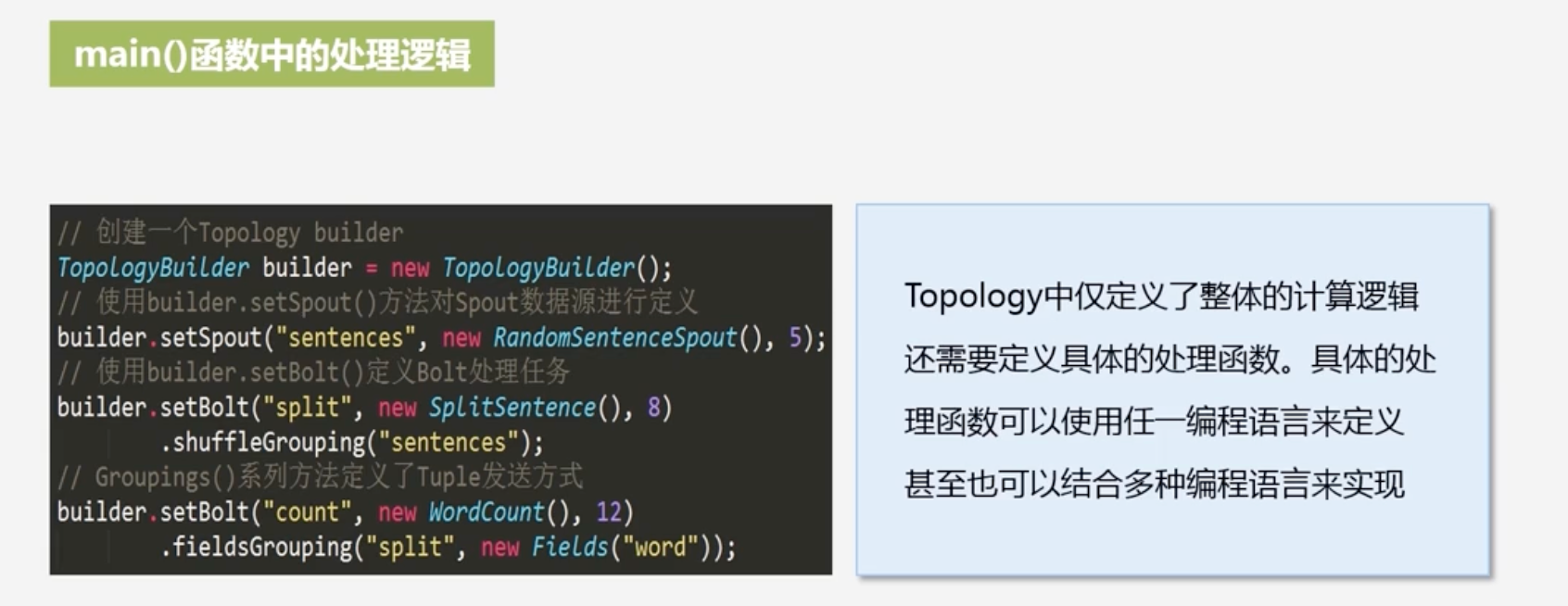
-
各个类的作用
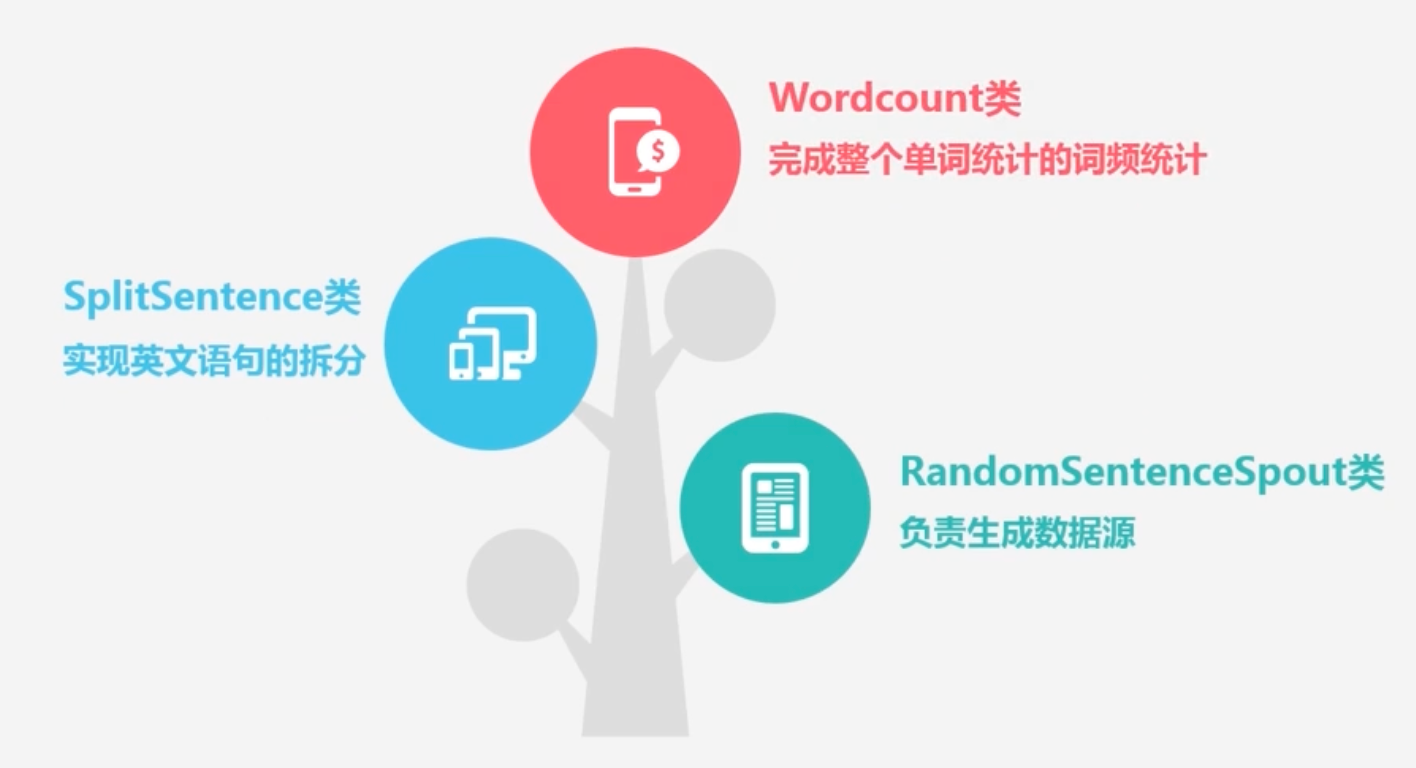
-
RandomSentenceSpout类

-
SplitSentence类

splitisentence.py脚本

-
WordCount类
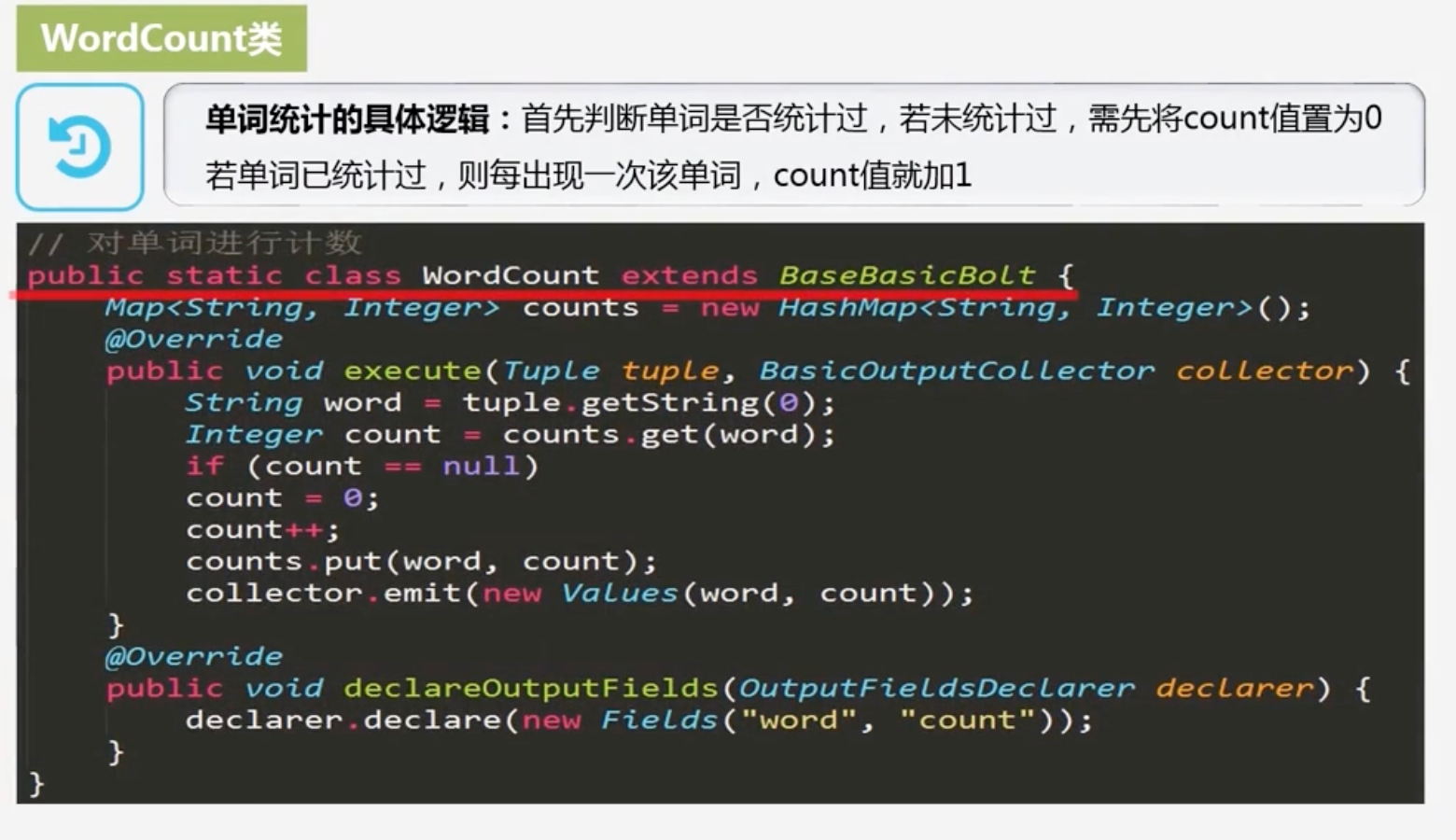
-
-
-
Twiteer也是使用了Storm框架实现了实时热门话题
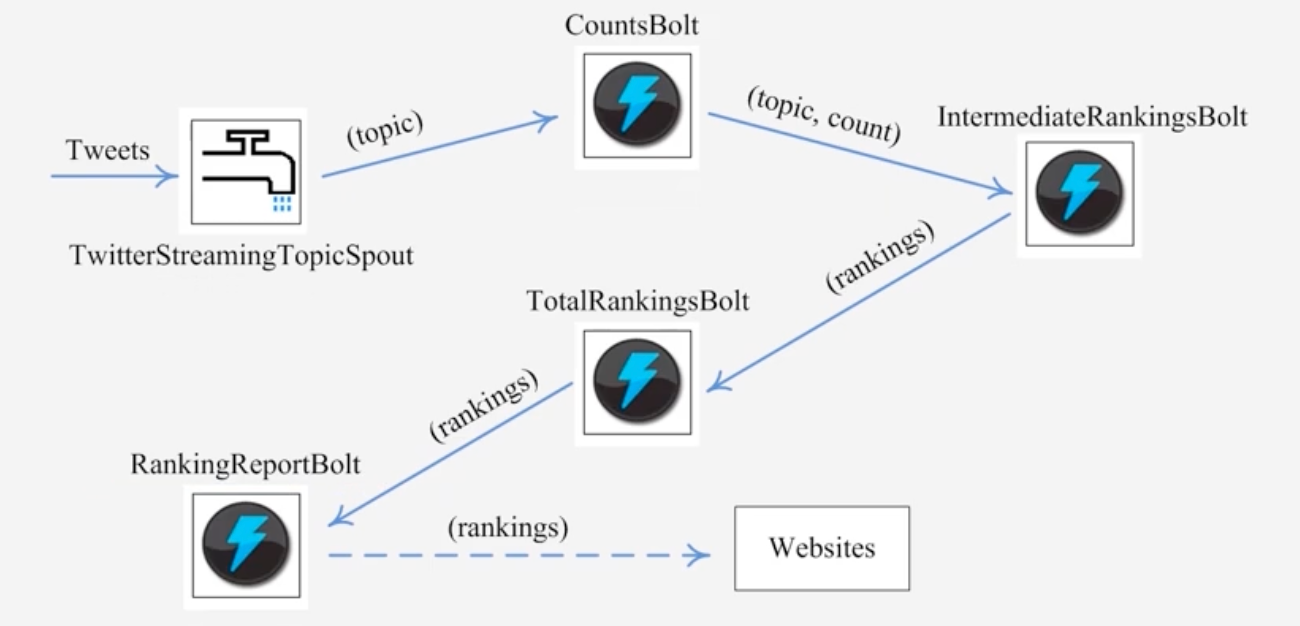
11.6.2 安装Storm的基本过程和实例
-
见:Storm安装教程_CentOS6.4/Storm0.9.6_厦大数据库实验室博客 (xmu.edu.cn)
-
Storm的具体运行环境
-
Storm单机模式