💡💡💡YOLO医学影像检测:http://t.csdnimg.cn/N4zBP
✨✨✨实战医学影像检测项目,通过创新点验证涨点可行性;
✨✨✨入门医学影像检测到创新,不断打怪进阶;
1.血细胞检测介绍
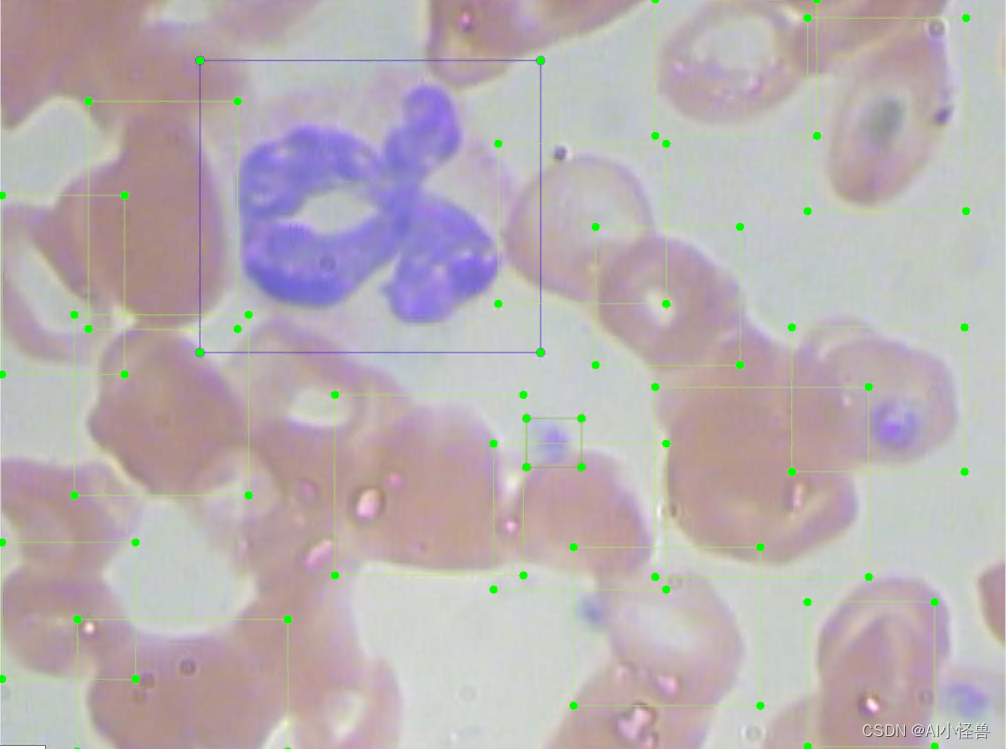
数据来源于医疗相关数据集,目的是解决血细胞检测问题。任务是通过显微图像读数来检测每张图像中的所有红细胞(RBC)、白细胞(WBC)以及血小板 (Platelets)共三类
意义:选择该数据集的原因是我们血液中RBC、WBC和血小板的密度提供了大量关于免疫系统和血红蛋白的信息,这些信息可以帮助我们初步地识别一个人是否健康,如果在其血液中发现了任何差异,我们就可以迅速采取行动来进行下一步的诊断。然而通过显微镜手动查看样品是一个繁琐的过程,这也是深度学习模式能够发挥重要作用的地方,YOLOv8可以从显微图像中分类和检测血细胞,并且达到很高的精确度。
1.1血细胞检测数据集介绍
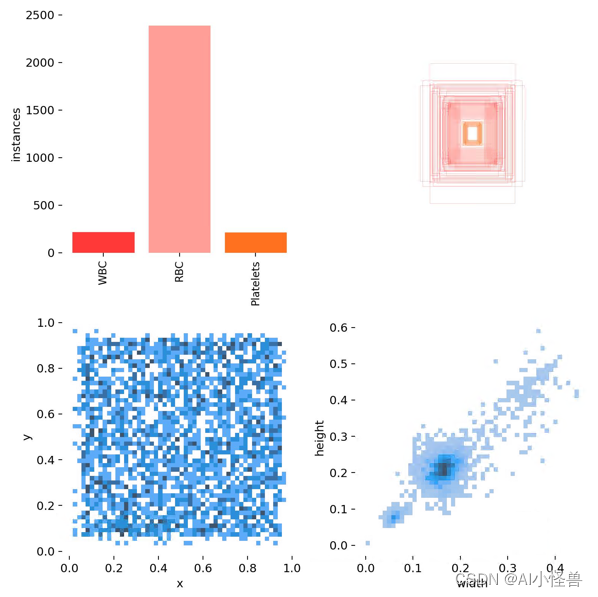
数据集大小:364张

检测难点:1)类别不平衡;2)同个类别相互遮挡、不同类别相互遮挡;3)检测物长宽差异较大;等
不同类别统计:
WBC: 321个
RBC: 4155个
Platelets: 361个同个类别相互遮挡、不同类别相互遮挡:
2.改进创新点介绍
2.1 动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱特征 | ICCV2023
Dynamic Snake Convolution | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.908
主要的挑战源于细长微弱的局部结构特征与复杂多变的全局形态特征。本文关注到管状结构细长连续的特点,并利用这一信息在神经网络以下三个阶段同时增强感知:特征提取、特征融合和损失约束。分别设计了动态蛇形卷积(Dynamic Snake Convolution),多视角特征融合策略与连续性拓扑约束损失。

我们希望卷积核一方面能够自由地贴合结构学习特征,另一方面能够在约束条件下不偏离目标结构太远。在观察管状结构的细长连续的特征后,脑海里想到了一个动物——蛇。我们希望卷积核能够像蛇一样动态地扭动,来贴合目标的结构。
我们希望卷积核一方面能够自由地贴合结构学习特征,另一方面能够在约束条件下不偏离目标结构太远。在观察管状结构的细长连续的特征后,脑海里想到了一个动物——蛇。我们希望卷积核能够像蛇一样动态地扭动,来贴合目标的结构。

实验结果:

YOLOv8-C2f-DySnakeConv summary: 249 layers, 3426089 parameters, 0 gradients, 8.7 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:03<00:00, 1.77s/it]
all 87 1138 0.828 0.895 0.908 0.614
WBC 87 87 0.982 1 0.99 0.763
RBC 87 968 0.74 0.819 0.859 0.597
Platelets 87 83 0.761 0.867 0.875 0.482YOLOv8血细胞检测(2):动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱特征 | ICCV2023_AI小怪兽的博客-CSDN博客
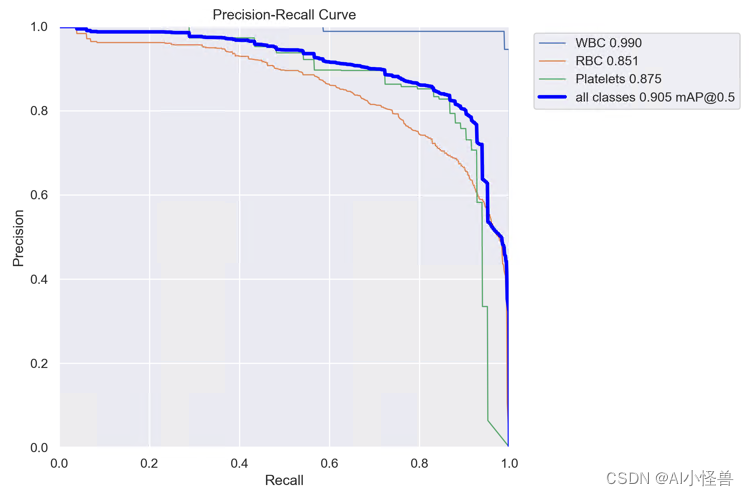
2.2 通道优先卷积注意力(Channel Prior Convolutional Attention,CPCA)| 中科院 2023.6发布
CPCA | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.905
图3:通道先验卷积注意力(CPCA)的整体结构包括通道注意力和空间注意力的顺序放置。特征图的空间信息是由通道注意力通过平均池化和最大池化等操作来聚合的。 随后,空间信息通过共享 MLP(多层感知器)进行处理并添加以生成通道注意力图。 通道先验是通过输入特征和通道注意力图的元素相乘获得的。 随后,通道先验被输入到深度卷积模块中以生成空间注意力图。 卷积模块接收空间注意力图以进行通道混合。 最终,通过通道混合结果与通道先验的逐元素相乘,获得细化的特征作为输出。 通道混合过程有助于增强特征的表示
YOLOv8_CPCAChannelAttention summary (fused): 171 layers, 3137817 parameters, 0 gradients, 7.8 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:04<00:00, 2.05s/it]
all 87 1138 0.864 0.865 0.905 0.605
WBC 87 87 0.988 0.981 0.99 0.78
RBC 87 968 0.791 0.747 0.851 0.595
Platelets 87 83 0.814 0.867 0.875 0.441YOLOv8血细胞检测(3):通道优先卷积注意力(Channel Prior Convolutional Attention,CPCA)| 中科院 2023.6发布-CSDN博客
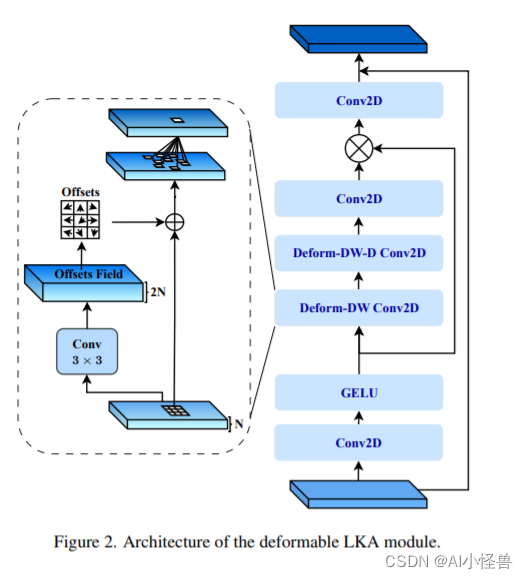
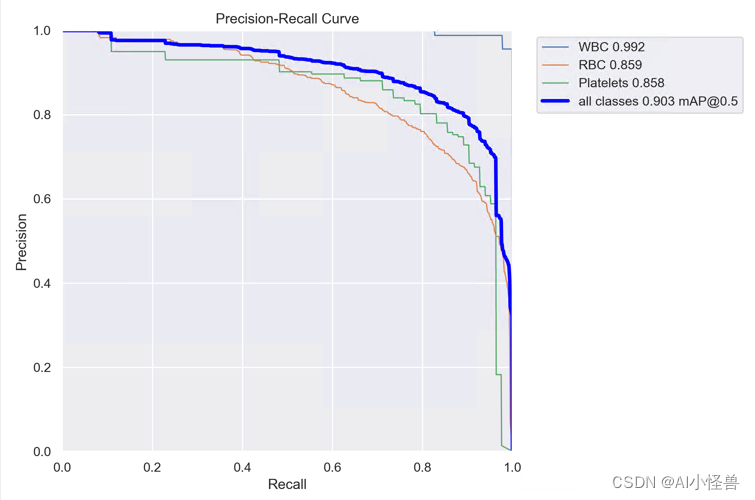
2.3 可变形大核注意力(D-LKA Attention),超越自注意力| 2023.8月最新发表
D-LKA Attention | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.903
这种机制在类似于自注意力的感受野中运行,同时避免了计算开销。 此外,我们提出的注意力机制受益于可变形卷积来灵活地扭曲采样网格,使模型能够适当地适应不同的数据模式。 我们设计了 D-LKA Attention 的 2D 和 3D 适应,后者在跨深度数据理解方面表现出色。
YOLOv8_C2f_deformable_LKA summary (fused): 205 layers, 4388553 parameters, 0 gradients, 12.9 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:07<00:00, 3.94s/it]
all 87 1138 0.825 0.888 0.903 0.601
WBC 87 87 0.988 0.968 0.992 0.78
RBC 87 968 0.735 0.822 0.859 0.599
Platelets 87 83 0.751 0.874 0.858 0.425YOLOv8血细胞检测(5):可变形大核注意力(D-LKA Attention),超越自注意力| 2023.8月最新发表-CSDN博客
2.4 多维协作注意模块MCA | 原创独家创新首发
MCA | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.910
顶部分支用于捕获空间维度 W 中特征之间的交互。类似地,中间分支用于捕获空间维度 H 中特征之间的交互。底部分支负责捕获通道之间的交互。 在前两个分支中,我们采用置换操作来捕获通道维度与任一空间维度之间的远程依赖性。 最后,在积分阶段通过简单平均来聚合所有三个分支的输出。

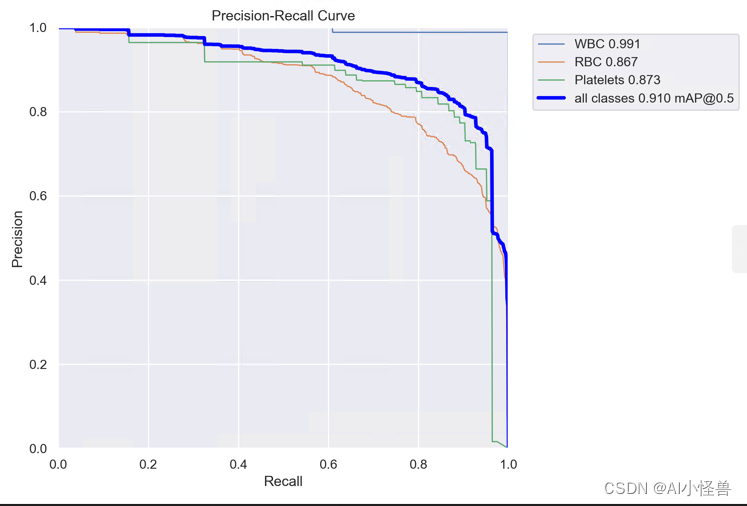
YOLOv8_MCALayer summary (fused): 220 layers, 3006273 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:13<00:00, 6.55s/it]
all 87 1138 0.846 0.894 0.91 0.613
WBC 87 87 0.983 1 0.991 0.78
RBC 87 968 0.74 0.828 0.867 0.606
Platelets 87 83 0.816 0.853 0.873 0.454YOLOv8血细胞检测(6):多维协作注意模块MCA | 原创独家创新首发-CSDN博客
2.5 Dual-ViT:一种多尺度双视觉Transformer ,Dualattention助力小目标检测| 顶刊TPAMI 2023
Dualattention | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.907
如上图(d)所示,双ViT由两个特殊路径组成,分别称为“语义路径”和“像素路径”。通过构造的“像素路径”进行局部像素级特征提取是强烈依赖于“语义路径”之外的压缩全局先验。由于梯度同时通过语义路径和像素路径,因此双ViT训练过程可以有效地补偿全局特征压缩的信息损失,同时减少局部特征提取的困难。前者和后者都可以并行显著降低计算成本,因为注意力大小较小,并且两条路径之间存在强制依赖关系。

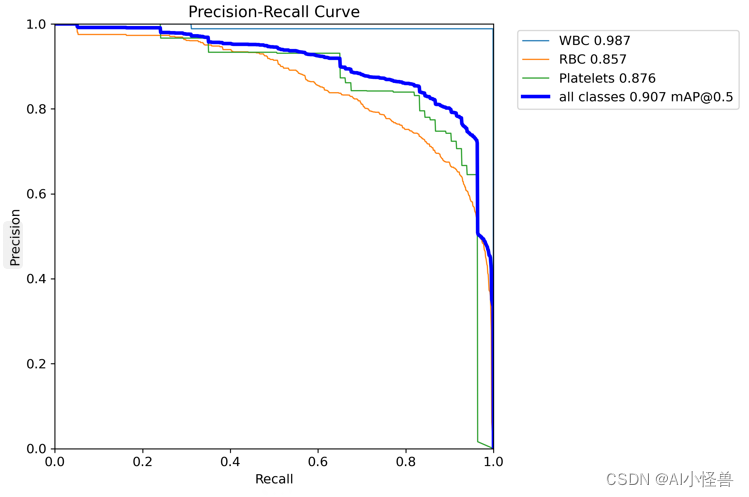
YOLOv8_DualAttention summary (fused): 186 layers, 4605209 parameters, 0 gradients, 8.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 3/3 [00:03<00:00, 1.15s/it]
all 87 1138 0.847 0.891 0.907 0.602
WBC 87 87 0.989 0.999 0.987 0.782
RBC 87 968 0.724 0.843 0.857 0.595
Platelets 87 83 0.828 0.831 0.876 0.429YOLOv8血细胞检测(4):Dual-ViT:一种多尺度双视觉Transformer ,Dualattention助力小目标检测| 顶刊TPAMI 2023_AI小怪兽的博客-CSDN博客
2.6 小目标大目标一网打尽,轻骨干重Neck的轻量级GFPN | 阿里ICLR2022 GiraffeDet
GFPN | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.904
本文提出了GiraffeDet用于高效目标检测,giraffe包含轻量space-to-depth chain、Generalized-FPN以及预测网络
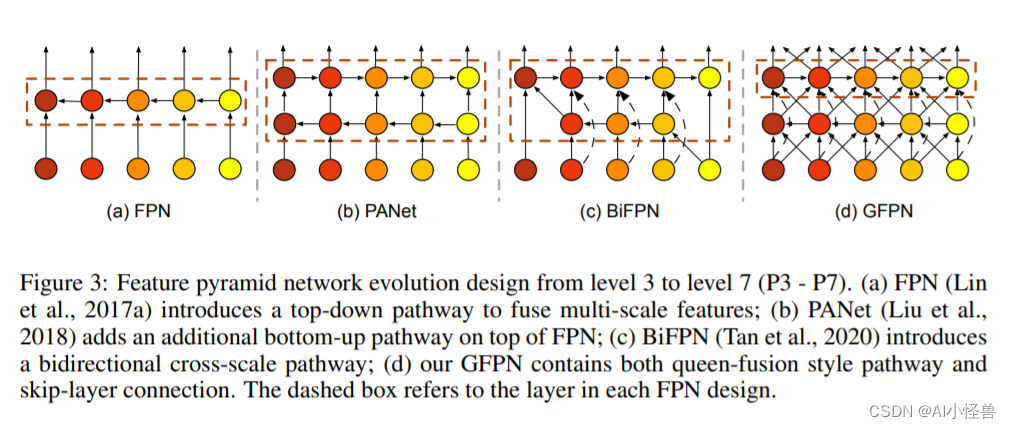
FPN旨在对CNN骨干网络提取的不同分辨率的多尺度特征进行融合。上图给出了FPN的进化,从最初的FPN到PANet再到BiFPN。我们注意到:这些FPN架构仅聚焦于特征融合,缺少了块内连接。因此,我们设计了一种新的路径融合GFPN:包含跳层与跨尺度连接,见上图d。
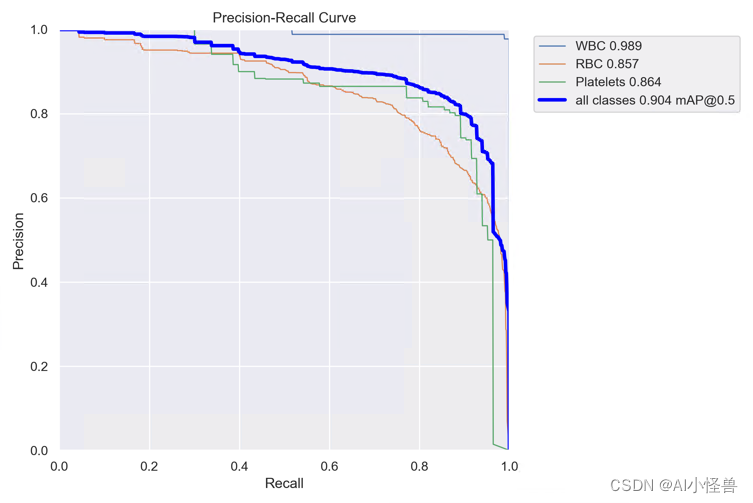
YOLOv8_GPFN summary: 232 layers, 2982937 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:03<00:00, 1.71s/it]
all 87 1138 0.843 0.897 0.904 0.604
WBC 87 87 0.982 0.989 0.989 0.771
RBC 87 968 0.739 0.841 0.857 0.596
Platelets 87 83 0.808 0.863 0.864 0.446YOLOv8血细胞检测(7):小目标大目标一网打尽,轻骨干重Neck的轻量级GFPN | 阿里ICLR2022 GiraffeDet_AI小怪兽的博客-CSDN博客
2.7 BiLevelRoutingAttention基于动态稀疏注意力构建高效金字塔网络架构,对小目标涨点明显 | CVPR 2023 BiFormer
BiLevelRoutingAttention | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.910
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
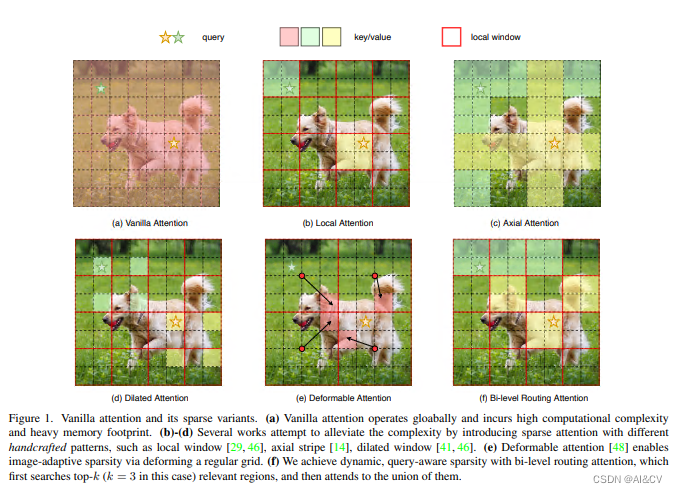
YOLOv8_BiFormerBlock1 summary (fused): 216 layers, 3423897 parameters, 0 gradients, 25.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:03<00:00, 1.66s/it]
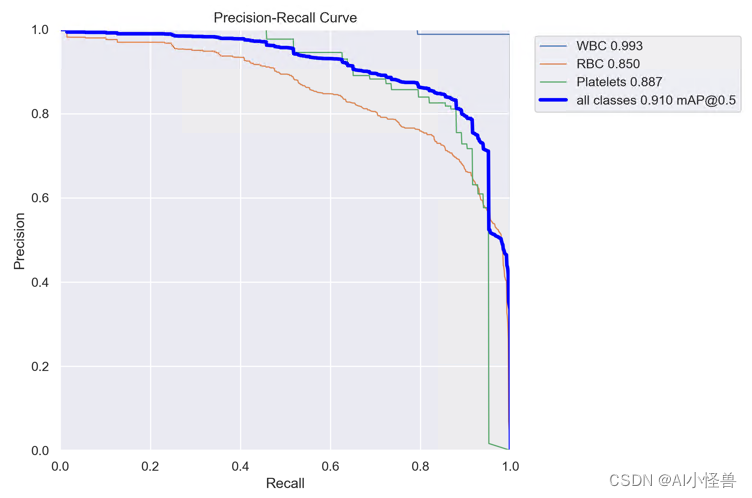
all 87 1138 0.832 0.9 0.91 0.619
WBC 87 87 0.983 1 0.993 0.788
RBC 87 968 0.694 0.879 0.85 0.593
Platelets 87 83 0.82 0.822 0.887 0.475 YOLOv8血细胞检测(8): BiLevelRoutingAttention基于动态稀疏注意力构建高效金字塔网络架构,对小目标涨点明显 | CVPR 2023 BiFormer-CSDN博客
2.8 SEAM注意力机制,提升遮挡小目标检测性能
SEAM | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.902
即不同人脸之间的遮挡,以及其他物体对人脸的遮挡。前者使得检测精度对 NMS 阈值非常敏感,从而导致漏检。作者使用排斥损失进行人脸检测,它惩罚预测框转移到其他真实目标,并要求每个预测框远离具有不同指定目标的其他预测框,以使检测结果对 NMS 不太敏感。后者导致特征消失导致定位不准确,设计了注意力模块 SEAM 来增强人脸特征的学习。
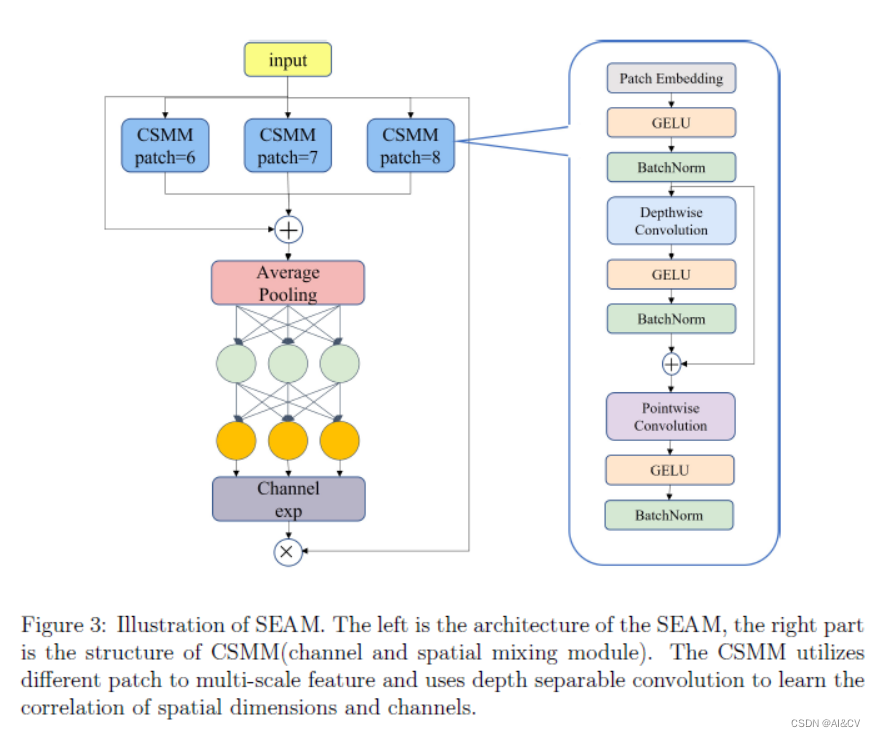
YOLOv8_SEAM summary (fused): 219 layers, 3109721 parameters, 0 gradients, 8.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:03<00:00, 1.62s/it]
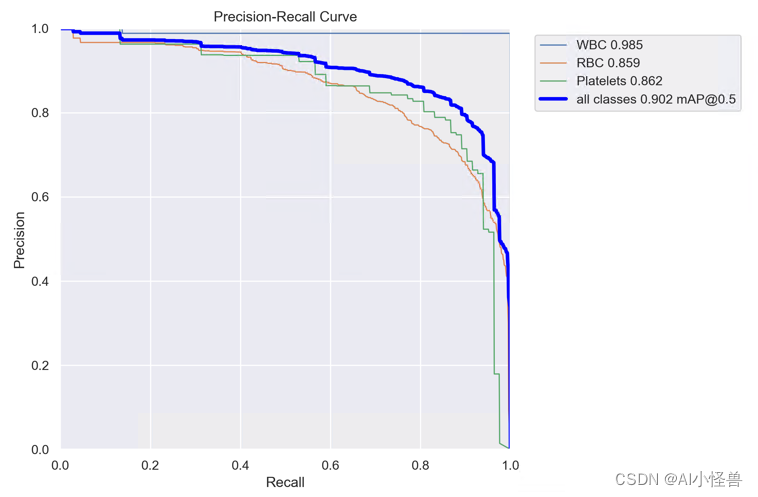
all 87 1138 0.835 0.895 0.902 0.605
WBC 87 87 0.974 1 0.985 0.767
RBC 87 968 0.747 0.831 0.859 0.596
Platelets 87 83 0.785 0.855 0.862 0.451 YOLOv8血细胞检测(9):SEAM注意力机制,提升遮挡小目标检测性能-CSDN博客
2.9 多尺度MultiSEAM,提高特征图的分辨率增强小目标检测能力
MultiSEAM | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.906
解决多尺度问题的主要方法是构建金字塔来融合人脸的多尺度特征。例如,在 YOLOv5 中,FPN 融合了 P3、P4 和 P5 层的特征。但是对于小尺度的目标,经过多层卷积后信息很容易丢失,保留的像素信息很少,即使在较浅的P3层也是如此。因此,提高特征图的分辨率无疑有利于小目标的检测。
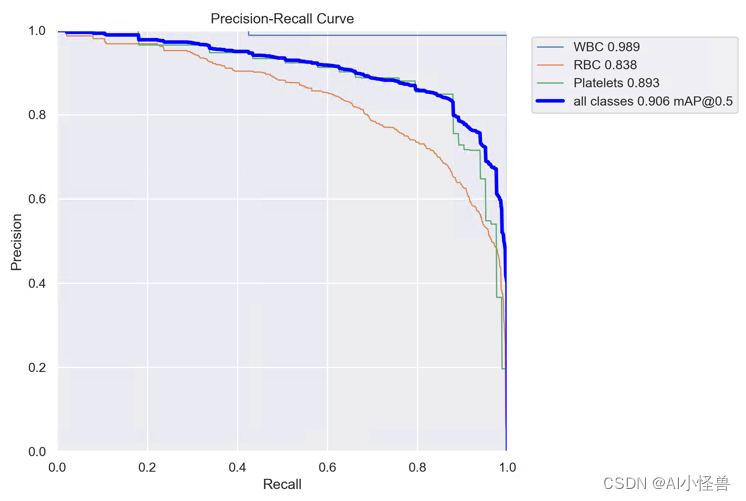
YOLOv8_MultiSEAM summary: 325 layers, 5742681 parameters, 0 gradients
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 3/3 [00:03<00:00, 1.29s/it]
all 87 1138 0.841 0.906 0.906 0.606
WBC 87 87 0.984 1 0.989 0.785
RBC 87 968 0.71 0.838 0.838 0.584
Platelets 87 83 0.829 0.88 0.893 0.449YOLOv8血细胞检测(10):多尺度MultiSEAM,提高特征图的分辨率增强小目标检测能力-CSDN博客
2.10 SPD-Conv,低分辨率图像和小物体涨点明显
SPD-Conv | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.916
SPD- conv由一个空间到深度(SPD)层和一个非跨步卷积层组成。SPD组件推广了一种(原始)图像转换技术[29]来对CNN内部和整个CNN的特征映射进行下采样:
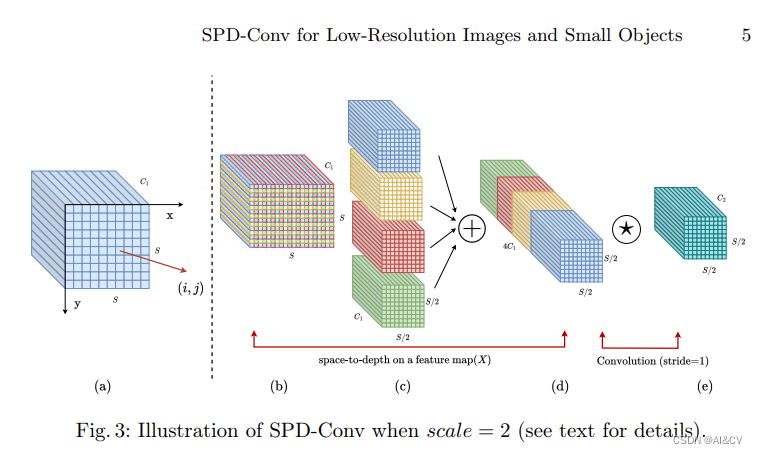
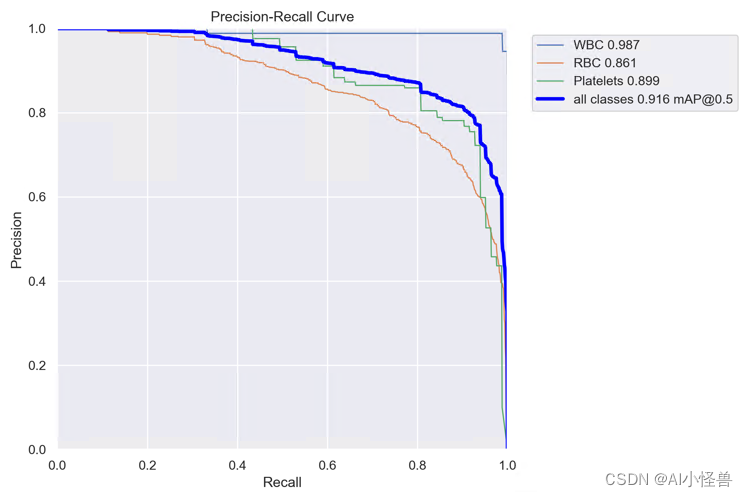
YOLOv8_SPD summary (fused): 174 layers, 3599129 parameters, 0 gradients, 49.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 6/6 [00:04<00:00, 1.24it/s]
all 87 1138 0.819 0.918 0.916 0.601
WBC 87 87 0.975 0.989 0.987 0.754
RBC 87 968 0.723 0.851 0.861 0.605
Platelets 87 83 0.759 0.916 0.899 0.444YOLOv8血细胞检测(11):SPD-Conv,低分辨率图像和小物体涨点明显-CSDN博客
2.11 最新开源移动端网络架构 RepViT | RepViTBlock | 清华 ICCV 2023
RepViTBlock | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.907
通过集成轻量级 ViT 的高效架构选择,逐步增强标准轻量级 CNN(特别是 MobileNetV3)的移动友好性。 最终产生了一个新的纯轻量级 CNN 系列,即 RepViT。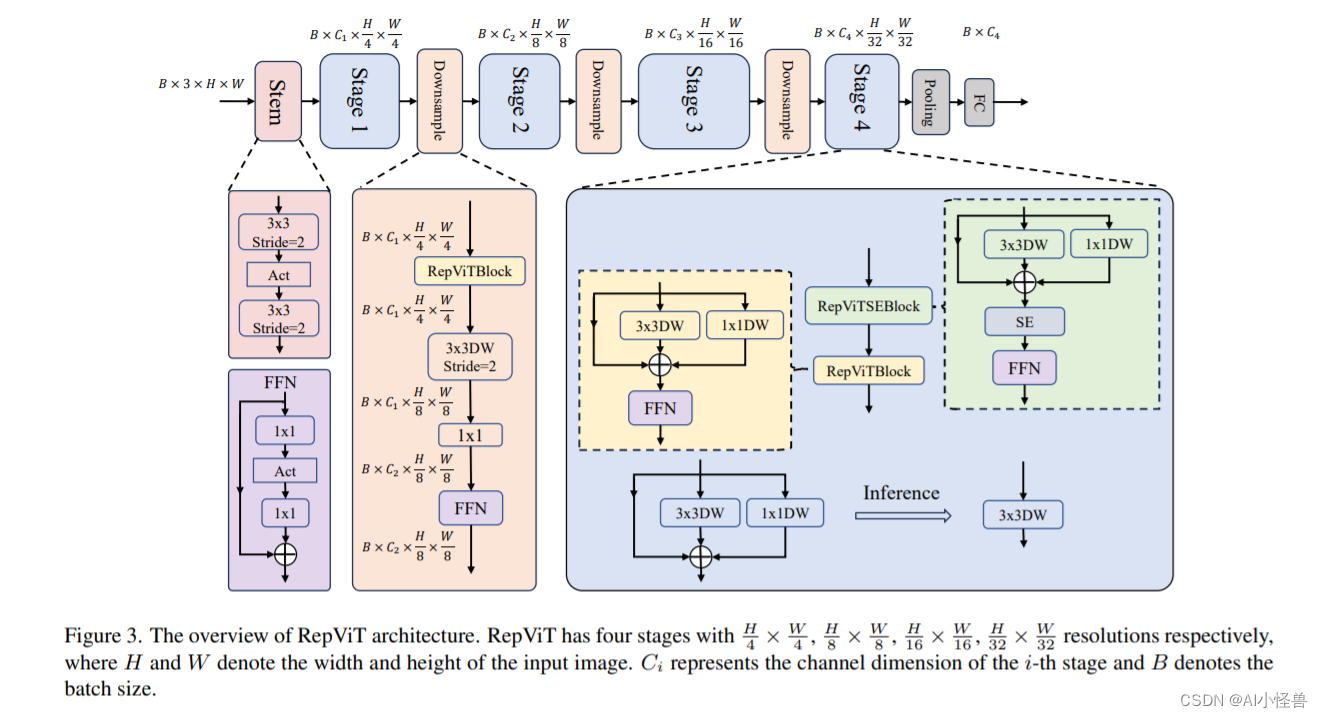
RepViT 通过逐层微观设计来调整轻量级 CNN
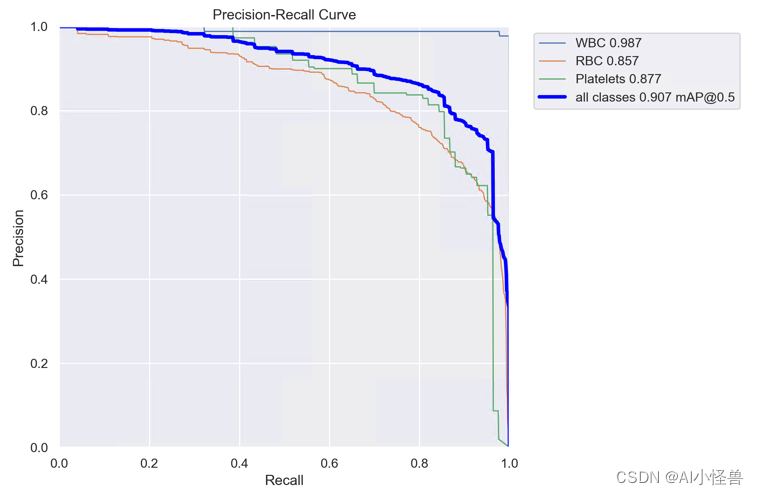
YOLOv8_RepViTBlock summary (fused): 186 layers, 3338777 parameters, 0 gradients, 7.9 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 6/6 [00:04<00:00, 1.38it/s]
all 87 1138 0.856 0.873 0.907 0.606
WBC 87 87 0.972 1 0.987 0.786
RBC 87 968 0.783 0.781 0.857 0.599
Platelets 87 83 0.813 0.837 0.877 0.434YOLOv8血细胞检测(13): 最新开源移动端网络架构 RepViT | RepViTBlock | 清华 ICCV 2023-CSDN博客
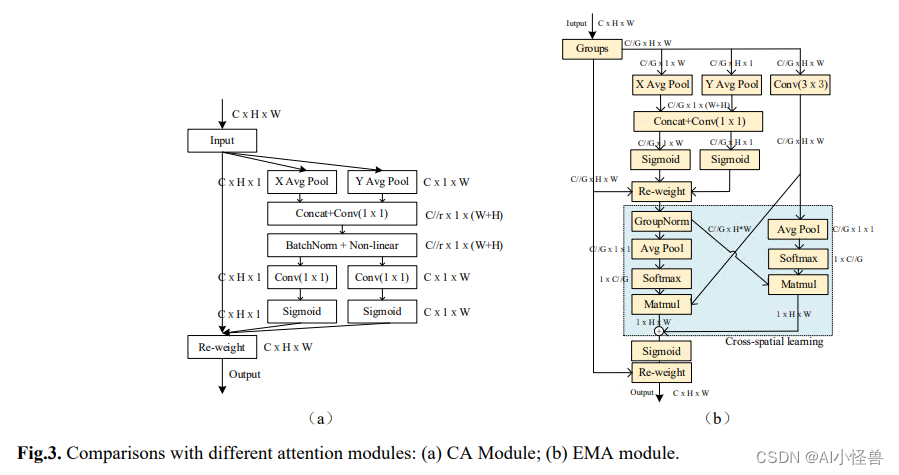
2.12 EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA | ICASSP2023
EMA | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.9
并行子结构帮助网络避免更多的顺序处理和大深度。给定上述并行处理策略,我们在EMA模块中采用它。EMA的整体结构如图3 (b)所示。在本节中,我们将讨论EMA如何在卷积操作中不进行通道降维的情况下学习有效的通道描述,并为高级特征图产生更好的像素级注意力。具体来说,我们只从CA模块中挑选出1x1卷积的共享组件,在我们的EMA中将其命名为1x1分支。为了聚合多尺度空间结构信息,将3x3内核与1x1分支并行放置以实现快速响应,我们将其命名为3x3分支。考虑到特征分组和多尺度结构,有效地建立短期和长程依赖有利于获得更好的性能。
map@0.5 从原始0.895提升至0.9
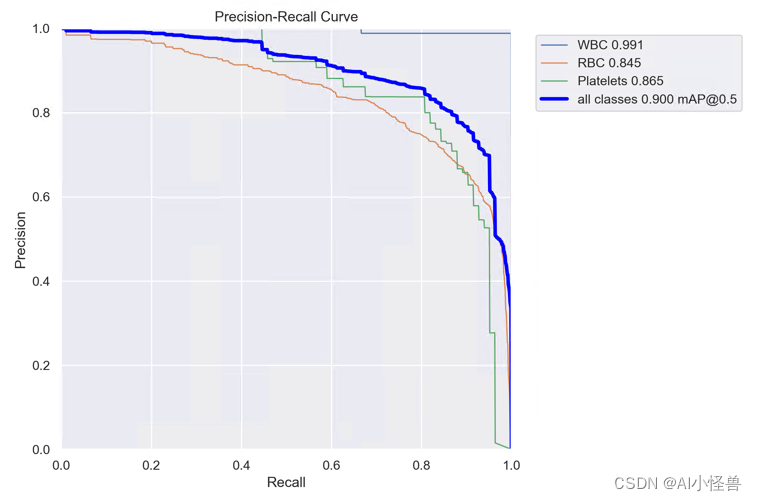
YOLOv8_EMA summary (fused): 176 layers, 3006905 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:03<00:00, 1.89s/it]
all 87 1138 0.825 0.873 0.9 0.617
WBC 87 87 0.989 0.994 0.991 0.79
RBC 87 968 0.779 0.751 0.845 0.588
Platelets 87 83 0.707 0.874 0.865 0.472YOLOv8血细胞检测(12):EMA基于跨空间学习的高效多尺度注意力、效果优于ECA、CBAM、CA | ICASSP2023-CSDN博客
2.12 微小目标检测的上下文增强和特征细化网络ContextAggregation
ContextAggregation | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.907
提供了一个统一视角表明:它们均是更广义方案下通过神经网络集成空间上下文信息的特例。我们提出了CONTAINER(CONText AggregatIon NEtwoRK),一种用于多头上下文集成(Context Aggregation)的广义构建模块 。
本文有以下几点贡献:
- 提出了关于主流视觉架构的一个统一视角;
- 提出了一种新颖的模块CONTAINER,它通过可学习参数和响应的架构混合使用了静态与动态关联矩阵(Affinity Matrix),在图像分类任务中表现出了很强的结果;
- 提出了一种高效&有效的扩展CONTAINER-LIGHT在检测与分割方面取得了显著的性能提升。
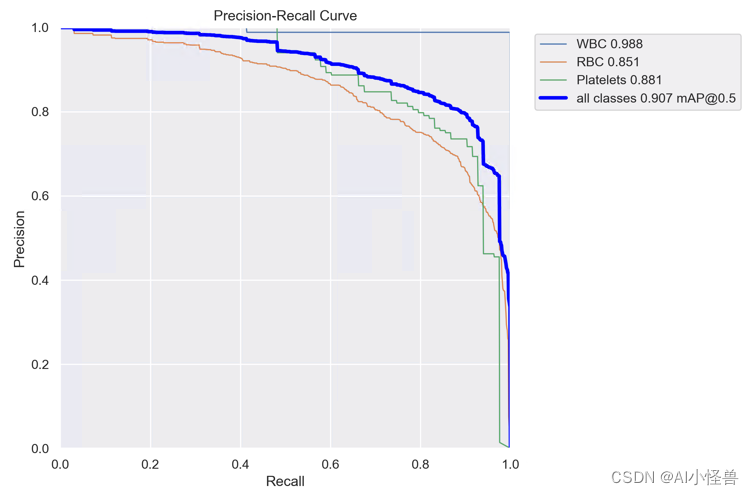
YOLOv8_ContextAggregation1 summary (fused): 195 layers, 3008482 parameters, 0 gradients, 8.1 GFLOPs
8.0920064
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:03<00:00, 1.86s/it]
all 87 1138 0.824 0.892 0.907 0.613
WBC 87 87 0.984 1 0.988 0.785
RBC 87 968 0.727 0.836 0.851 0.596
Platelets 87 83 0.76 0.84 0.881 0.457YOLOv8血细胞检测(15):微小目标检测的上下文增强和特征细化网络ContextAggregation-CSDN博客
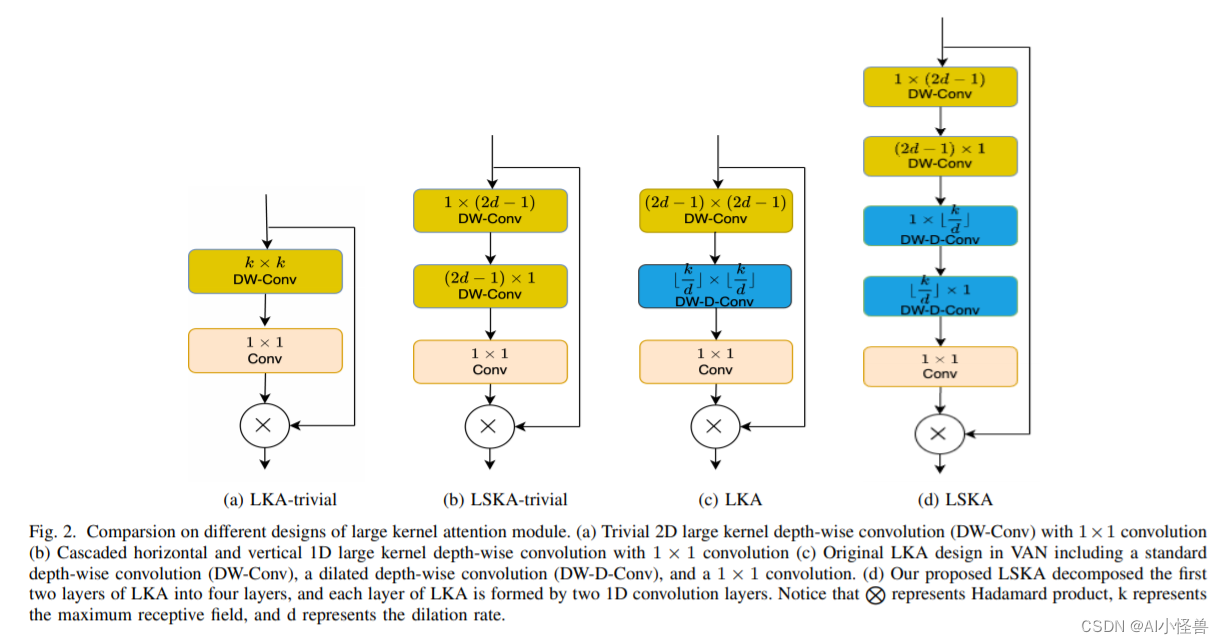
2.12 大型分离卷积注意力模块( Large Separable Kernel Attention),实现暴力涨点同时显著减少计算复杂性和内存 | 2023.8月最新发表
Large Separable Kernel Attention| 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.904,YOLOv8n GFLOPs 8.1降低到 7.0
我们首先讨论如何通过使用一维卷积核来设计 LSKA 模块来重构 LKA 模块(使用和不使用扩张的深度卷积)。 然后我们总结了 LSKA 模块的几个关键属性,然后对 LSKA 进行了复杂性分析。
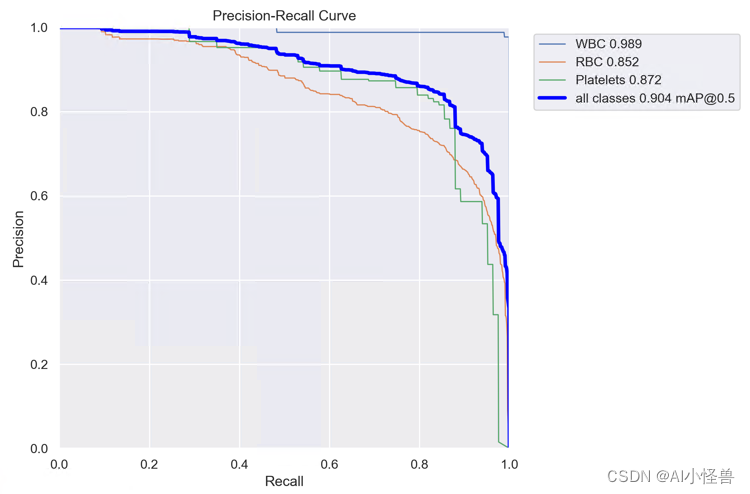
YOLOv8_C2f_LSKA_Attention summary (fused): 207 layers, 2613737 parameters, 0 gradients, 7.0 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:08<00:00, 4.28s/it]
all 87 1138 0.838 0.895 0.904 0.601
WBC 87 87 0.985 0.989 0.989 0.777
RBC 87 968 0.704 0.865 0.852 0.593
Platelets 87 83 0.827 0.831 0.872 0.433YOLOv8血细胞检测(16):大型分离卷积注意力模块( Large Separable Kernel Attention),实现暴力涨点同时显著减少计算复杂性和内存 | 2023.8月最新发表_AI小怪兽的博客-CSDN博客
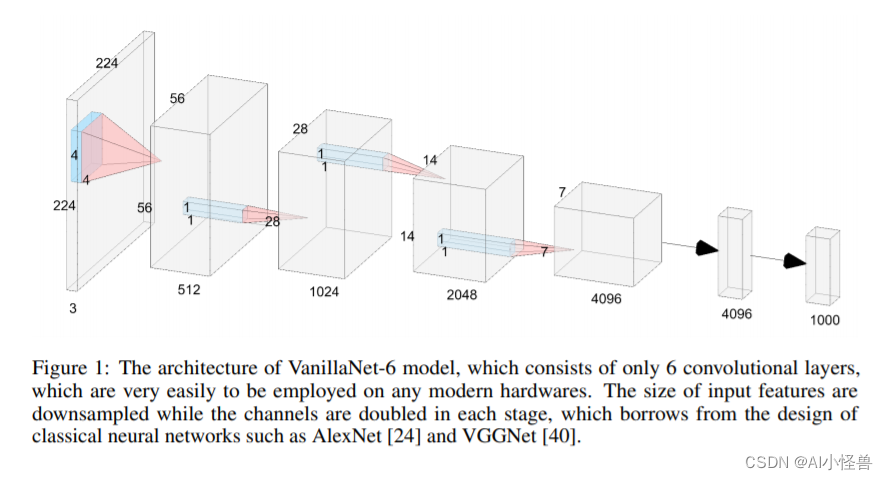
2.13 极简的神经网络模型 VanillaNet---VanillaBlock助力检测实现涨点的同时降低参数量 |华为诺亚2023
VanillaBlock | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.90,YOLOv8n GFLOPs 8.1降低到6.2
VanillaNet,这是一种设计优雅的神经网络架构。 通过避免高深度、shortcuts和自注意力等复杂操作,VanillaNet 简洁明了但功能强大。
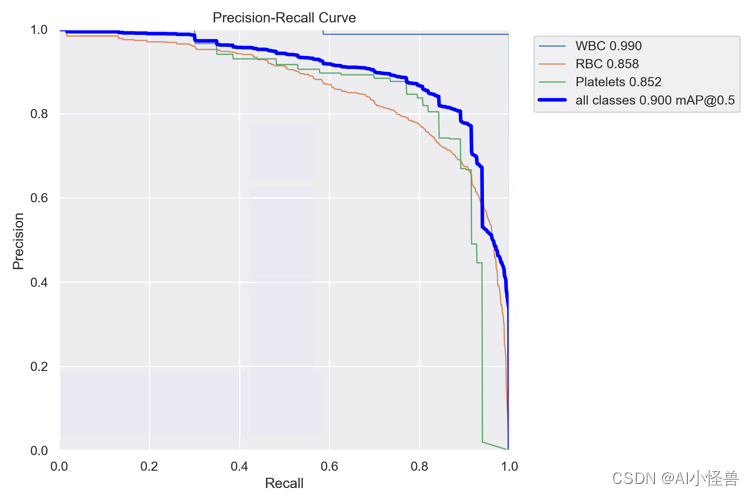
YOLOv8_VanillaBlock summary (fused): 198 layers, 3203801 parameters, 0 gradients, 6.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 2/2 [00:04<00:00, 2.21s/it]
all 87 1138 0.858 0.872 0.9 0.594
WBC 87 87 0.984 1 0.99 0.774
RBC 87 968 0.79 0.772 0.858 0.586
Platelets 87 83 0.799 0.843 0.852 0.422YOLOv8血细胞检测(17):极简的神经网络模型 VanillaNet---VanillaBlock助力检测实现涨点的同时降低参数量 |华为诺亚2023-CSDN博客
持续更新中