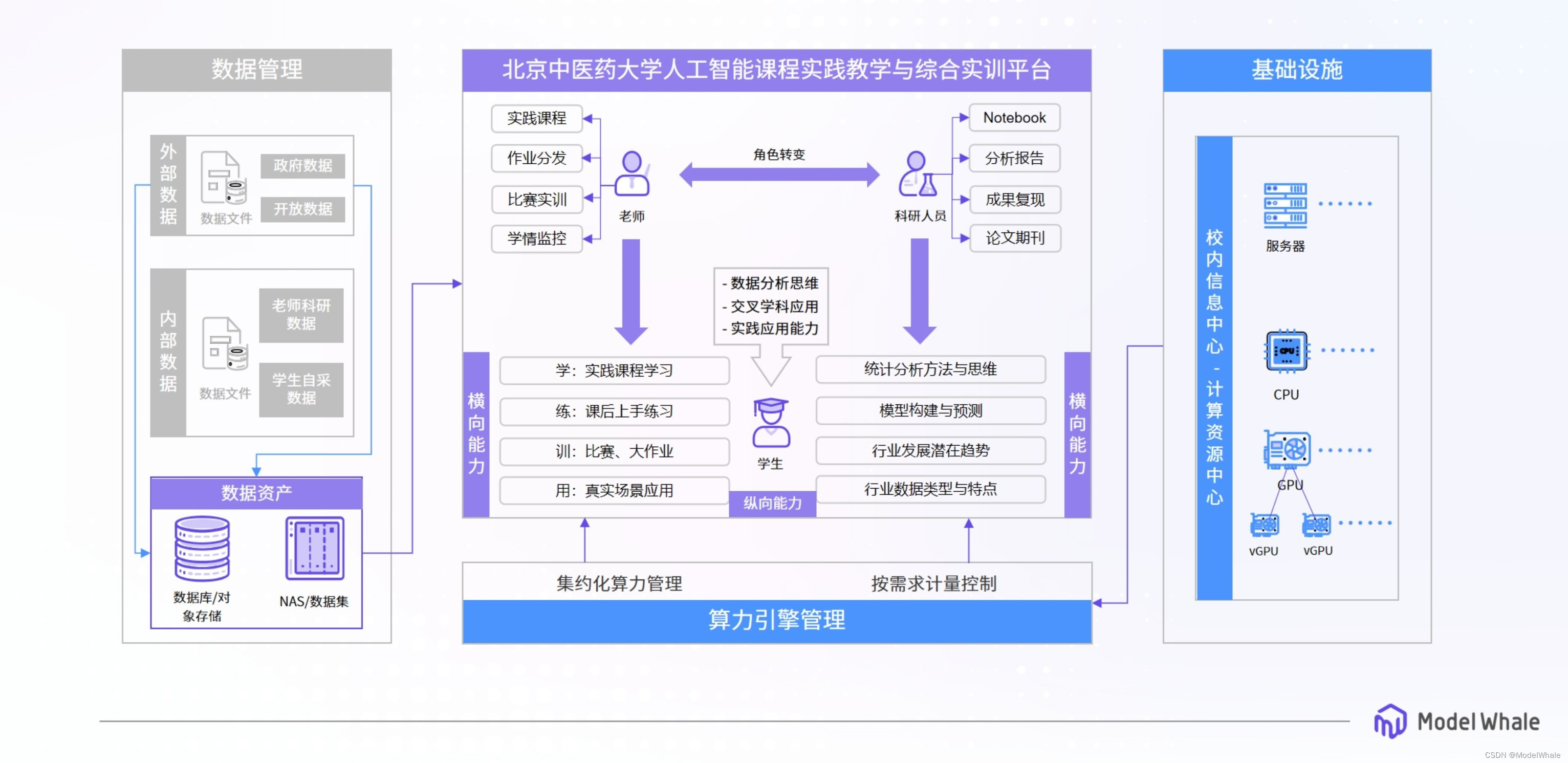
【学习之路】Multi Agent Reiforcement Learning框架与代码
Introduction
国庆期间,有个客户找我写个代码,是强化学习相关的,但我没学过,心里那是一个慌,不过好在经过详细的调研以及自身的实力,最后还是解决了这个问题。
强化学习的代码也是第一次接触,在这个过程中也大概了解了多agent强化学习的大致流程,因此记录这次代码和文章学习的过程还是十分有必要的。
要完成的文章是:Flexible Formation Control Using Hausdorff Distance: A Multi-agent Reinforcement Learning Approach,该文章没有开源。
以下均为个人简介,如有不当,还请见谅。
Timeline
- 从目标文章中查找类似文章,最好是开源的
- Decentralized Multi-agent Formation Control via Deep Reinforcement Learning:这篇文章有算法的基本流程
- Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments:这篇文章是目标文章所使用仿真环境的出处
- 查找多agent强化学习的开源代码
- Multi-Agent-Deep-Deterministic-Policy-Gradients:这是Multi-Agent Actor-Critic这篇文章里面所提方法代码的pytorch版本,官方是tensorflow写的
- Reinforcement_Learning_Swarm:这篇没有利用框架,但通过它可以较好地理解整个流程
- multiagent-particle-envs:这是算法的仿真环境,同时也相当于一个框架
- 学习这些代码,推荐先学习没有利用框架的,也就是第二篇,然后看用框架写的
Code Note
主要针对框架代码进行学习,即:multiagent-particle-envs 和Multi-Agent-Deep-Deterministic-Policy-Gradients,后者使用了前者的环境。
整体流程
首先介绍一下训练的整体流程,方便更好的理解:
- 创建多agent的环境
- 实现强化学习的模型M(actor-critic模型)
- 确定相关参数:迭代次数,学习率等
- 循环
- 重置环境获得当前的observation
- 根据observation输入到M中的actor网络(这部分不作讲解),得到action
- 根据action更新当前的state,获得reward,更新的observation
- 将这些state存入memory
- 每隔一定迭代次数,从memory里面采样一些state,输入到模型M里面,从而对M进行训练
环境代码
该项目下代码以及文件夹的功能如下:

下面主要介绍enviroment文件下一些函数的作用。
首先是为每个agent分配action空间,代码如下:

然后是在进行下一步(step函数)的时候,对每个agent的action进行更新,代码如下:

红框部分就是对每个agent的action进行设置,action里面的u我个人认为是受力,因为在后面的代码中存在利用u来计算受力的情况。
得到action后,利用action对state进行更新,该部分的代码在core.py里面的World类当中,代码如下:

其中利用u计算受力的代码为:

为什么说p_force是受力呢,可以看看integrate_state这个函数,如下:

得到agent的state之后,就是计算reward,observation等变量,代码的调用在environment.py下:

从make_env.py文件里面可以看出,这些函数的相关实现在scenarios文件下的py文件里面:

接下来看这些函数是怎么实现的,以simle_spread.py文件为例:
首先是reset_world函数,它是对环境里面的物体进行初始化,代码如下:

其中p_pos是位置信息,p_vel是速度信息,c是交流信息。
然后is_collision函数判断是否发生碰撞,代码如下:

接着是reward函数,如果你设计了自己的reward,需要在这里实现:

最后是observation函数,如果你有自己的设计,也要在这里实现:

了解了以上这些,对于一个简单的多agent强化学习的情况你也能够实现了。