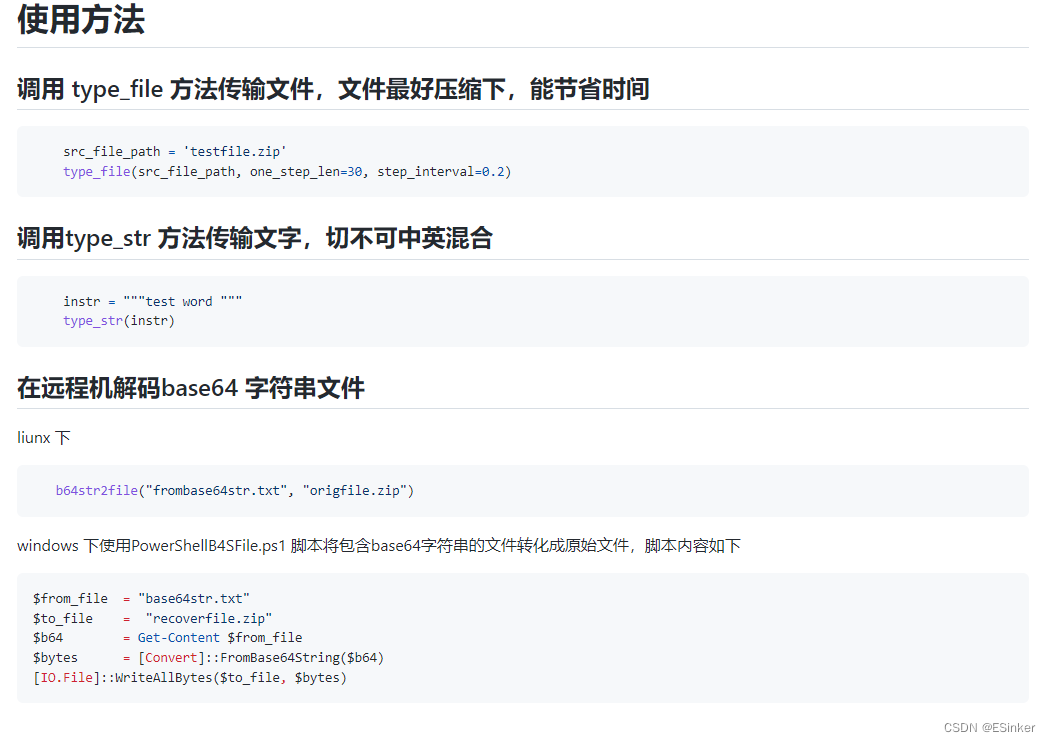
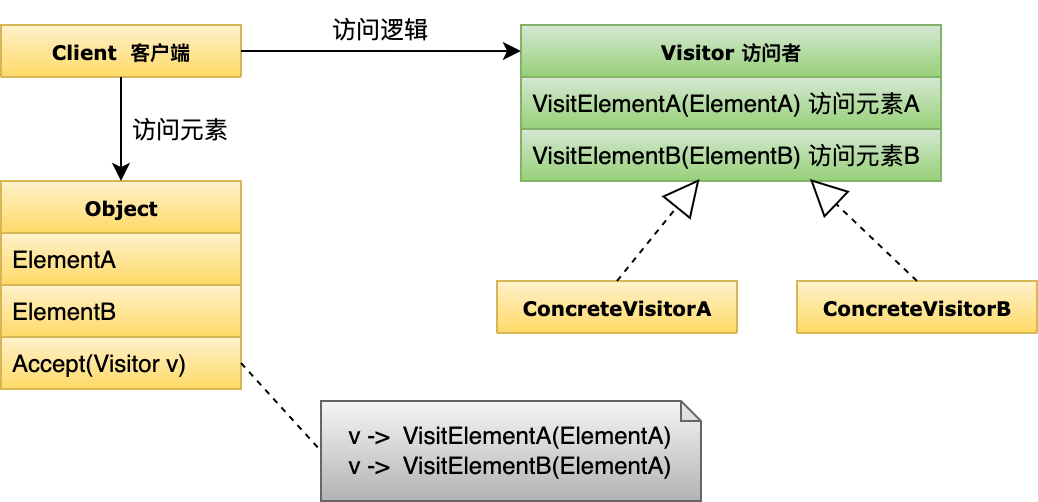
问题
一直很疑惑spark中数据的流向是如何的,网上的文章基本上都是在讲述RDD的基本概念,看来看去都是些RDD直接相互依赖、Spark构造DAG、RDD计算只能由行动算子触发等一些基础概念,没有解开我的疑惑,因此自己点击源码查看,并记录下来。
我们都知道spark是通过RDD的相互依赖构成一张DAG,而构成DAG的单位是一个个的STAGE,每个STAGE中数据不涉及Shuffle,多个RDD构成了一个STAGE。那么问题来了,数据在RDD中是怎样流通的呢?是一条一条的进入RDD,从第一个到最后一个呢?还是Spark会读取所有数据进内存后再供给每个RDD计算呢?既然RDD不存储数据,那么它又如何去拉取数据进行计算的呢?下面将对RDD的处理机制进行描述。
Spark中的数据流
Spark并不会直接把数据全部存储到内存之中,而是利用RDD的依赖关系构建一个RDD依赖链,在阶段提交时按阶段切分成一系列的任务给Executor执行,由于RDD是懒执行的,所以当行动算子触发job时,才会真正去读取数据进行处理。spark中存储数据的情况:
- RDD缓存spark可以选择把后面rdd频繁使用的rdd进行缓存,由于rdd只是对操作函数的封装,因此数据不会存在rdd中,如果后续很多rdd依赖于当前rdd,那么当前rdd会频繁的执行加工数据,因此把本RDD缓存在内存中,后面的rdd可以直接从内存中拿去数据,省去了在通过rdd依赖加载转换数据的开销。
- Shuffle暂存数据在进行shuffle时,会有shuffle read 和 shuffle write 两个阶段,在进行shuffle write时,把数据缓存到spark的execution内存区域并装入AppendOnlyMap或Pairbuffer中,当内存不足时,会对排序才写到磁盘文件。而在shuffle read 阶段,会把数据读入内存并进行聚合,如果内存满了会溢写磁盘,最后再把内存和磁盘的文件进行归并。
- 系统或用户对象对象存储开销
RDD的调用机制
RDD调用链过程
首先RDD并不存储数据,只是存储获取数据的分区getPartition以及每个分区的计算函数compute。rdd1经过转换map成rdd2时,rdd2会把rdd1记录成自己的父rdd,并且把rdd1进行的map方法记录成函数f,并使用一个迭代器去通过map方法执行该函数(map方法一条条的处理数据),也就是说一个新的rdd会记录它的父rdd,以及它是如何由父rdd转换而来的,源码:


上面的f函数就是转换操作。iter是一个迭代器,new的时候f函数的逻辑是调用iter迭代器的map方法,执行传入的转换操作。而在computer中实现时,这个迭代器就是firstParent的iterator,那么firstParent是哪个RDD呢?看new一个RDD的时候:
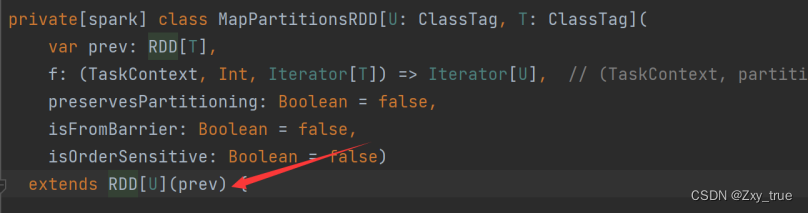
它继承了RDD,并且传入了prev就是它的父RDD作为构造函数的参数,再看这个构造函数:

可以看到在一对一依赖的情况下,传入的这个rdd就是它的依赖表的唯一成员,也就是说调用firstParent的时候实际上获取的就是传入的这个prev。
而根rdd则是读取数据的rdd,如通过textfile获得的rdd则是通过读取文件生成的hadoopRdd,hadooprdd的compute函数就是读取文件的过程。
到这里整个rdd调用链就清楚了:
行动算子触发计算时,将由最后一个rdd调用iterator方法进而调用compute方法,在compute方法里,会调用compute所在rdd的父rdd的迭代器执行父rdd传入的处理过程函数,而调用父rdd的迭代器时,又会导致父rdd的iterator方法调用父rdd的compute方法,如此不断往上调用,直到来到读取文件的rdd(hadoopRdd),调用hadooprdd的compute方法,读取文件数据,再依次进过层层处理,来到最后一个rdd,调用结束。
第一个调用iterator的地方
现在知道compute方法的入口方法时iterator方法,即整个调用链是从iterator方法开始的,既然rdd的处理调用是一个向上迭代的过程,那么第一个调用iterator的地方在哪里呢?
RDD算子最终会被转化为shuffle map task和result task,并发送到executor执行。而这个地方就在ShuffleMapTask的runTask方法中:
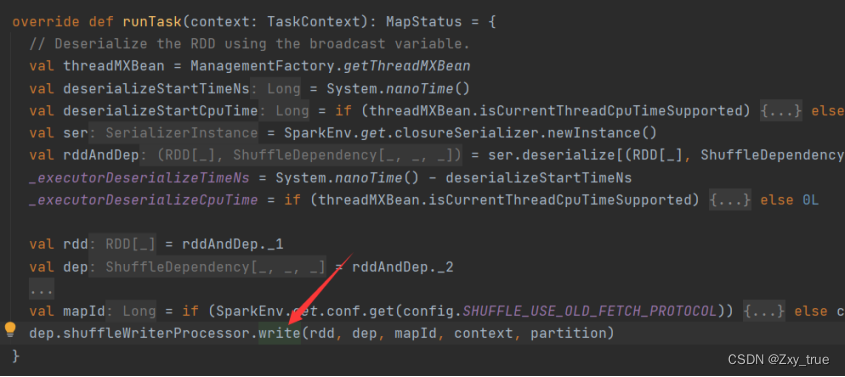
进入write方法
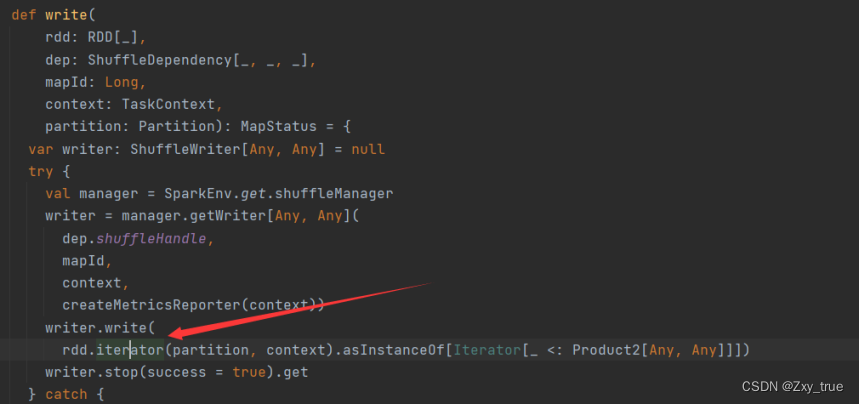
会在传入的rdd基础上调用RDD的iterator方法。进入该方法:
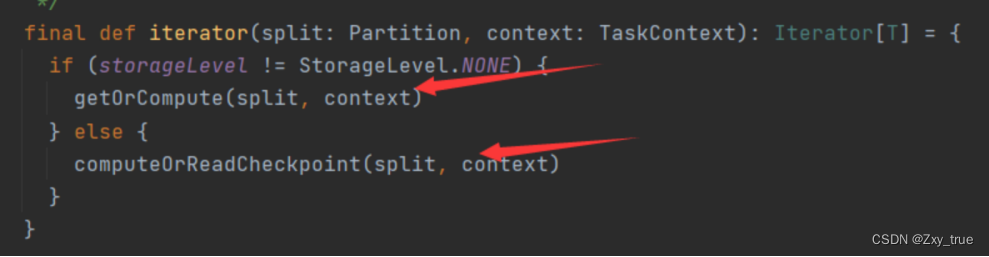
当该rdd有存储级别时(被cache或者persist过)会先在当前executor上的BlockManager获取指定blockId的block,如果没有缓存则调用computeOrReadCheckpoint。
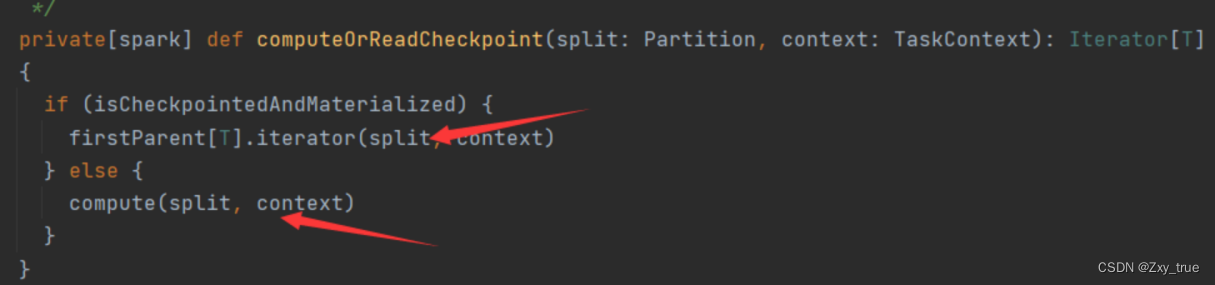

isCheckpointedAndMaterialized方法会判断checkpointData是否有当前rdd,如果有则会调用firstParent[T].iterator(split, context)方法返回checkpoint的rdd,然后调用该rdd的iterator方法。
如果没有checkpoint,则直接调用本rdd的compute方法执行具体逻辑。
所以在executor执行maptask时,会拿出一个rdd执行它的iterator,而这个rdd就是一个stage中的最后一个rdd。
RDD中流通的数据大小
那么iterator迭代的数据量又是多少呢,换句话说,究竟在rdd间流通的数据是一条数据,还是多条呢?上面分析可知转换操作会通过iter的map方法作用在每一条数据上,所以肯定是一批数据在rdd间流通,并且我们知道一个task是运行在一个分区上,所以流通的数据量实际上就是一个分区的数据量。因此一个文件如果不止一个分区,就会划分成多个task,在executor中不断执行!