个人论文精读笔记,主要是翻译+心得,欢迎旁观,如果有兴趣可以在评论区留言,我们一起探讨。
Paper: https://arxiv.org/pdf/2111.12933.pdf
Code: https://github.com/Alibaba-MIIL/ML_Decoder
文章目录
- 0. 摘要
- 1. 介绍
- 2. 方法
- 2.1 Baseline分类头
- 2.2 回顾-Attention and Transformer-Decoder
- 2.3 ML-Decoder
0. 摘要
-
翻译
本文介绍了一种新的基于注意力的分类头——ML-Decoder。ML-Decoder通过查询预测类标签的存在,与全局平均池化相比,它能够更好地利用空间数据。通过重新设计解码器架构,并使用一种新颖的组解码方案,ML-Decoder具有很高的效率,并且可以很好地扩展到数千个类。与使用更大的主干相比,ML-Decoder始终提供更好的速度-精度权衡。ML-Decoder也是通用的——它可以作为各种分类头的临时替代品,并且在与单词查询操作时推广到不可见的类。新颖的查询扩充进一步提高了其泛化能力。使用ML-Decoder,我们在几个分类任务上取得了最先进的结果:在MS-COCO多标签上,我们达到了91.4%的mAP;在NUS-WIDE的zero-shot上,我们达到了31.1%的ZSL(Zero shot learning) mAP;在ImageNet单标签上,我们在没有额外数据或蒸馏的情况下,用vanilla ResNet50主干达到了80.7%的新最高分。 -
笔记
- 摘要主要讲了下ML-Decoder不同于一般的全局平均池化,通过查询来预测类别能更好的利用空间信息;
- 跟更大的backbone相比,ML-Decoder能更好权衡速度-精度;
- ML-Decoder也是通用的——它可以作为各种分类头的临时替代品,并且在与单词查询操作时推广到不可见的类;
- 最后展示了下实验数据,能在不同数据集上多标签分类的任务达到SOTA的性能;
1. 介绍
先说了一下图像分类的概念,可以根据图像中的物体分配一个或多个标签,那么分配一个标签的就是单分类,多个标签就是多分类。然后单分类需要对输出结果做softmax操作,softmax操作其实就是把输出的多个类别通过运算缩放到0~1之间的值,我们可以称为概率值,然后对于每个物体预测的所有类别之和为1,具体可以参考这篇博文。再说回多分类,其实自然图片通常包括多个对象,那么就需要多标签分类。然后作者介绍了下他的做法:类似处理多任务问题,分别独立地预测每个类别。然后介绍了业界一般的做法:通过图神经网络利用标签相关性,改进损失函数、预训练方法和主干,在多标签分类领域取得了显著的成功。
极端分类时,我们需要预测大量类的存在(通常是数千或更多),迫使我们的模型和训练方案是高效和可扩展的。多标签零次学习(ZSL)是多标签分类的扩展,在推理过程中,网络尝试识别看不见的标签,即在训练过程中未使用的其他类别的标签。这通常是通过文本模型在可见类(用于训练)和不可见类之间共享知识来实现的。
分类网络通常包含主干和分类头。主干输出空间嵌入张量,分类头将空间嵌入张量转换为预测逻辑。在单标签分类中,这通常是通过全局平均池化 (GAP)完成的,然后是一个全连接层。基于GAP的分类头也用于多标签分类。然而,由于需要识别具有不同位置和大小的多个对象,这可能会使平均池的使用不是最优的。最近,一些研究提出了基于注意力分类头的多标签分类方法。有论文提出一种双流注意力框架,用于从全局图像到局部区域的多类别物体识别。还有论文提出了简单的空间注意分数,然后将其与类别无关的平均池化特征相结合。还有论文提出了一个具有可学习查询的池化transformer,用于多标签分类,获得了顶级结果。(具体哪篇论文请参考原文)
基于GAP的分类头简单而有效,并且由于它们具有固定的空间池化成本,因此可以很好地随类数量的增加而扩展。然而,它们提供了次优结果,并且不能直接应用于ZSL。基于注意力的分类头确实改善了结果,但通常成本很高,即使对于具有少量类别的数据集也是如此,并且对于极端的分类场景实际上是不可行的。它们也没有自然延伸到ZSL。
在本文中,我们介绍了一种新的分类头,称为ML-Decoder,它为单标签、多标签和零采样分类提供了统一的解决方案,并取得了最先进的结果(见图1)。ML-Decoder的设计基于原始的transformer-decoder,进行了两大修改,显著提高了其可扩展性和效率。首先,它通过去除冗余的自关注块,将解码器在输入查询数量上的二次依赖关系降低为线性依赖关系。其次,ML-Decoder使用一种新颖的组解码方案,它不是为每个类分配查询,而是使用固定数量的查询,这些查询通过称为组全连接(group
fully-connected)的新体系结构块插值到最终数量的类。使用组解码,ML-Decoder还享有固定的空间池成本,并且可以很好地扩展到数千个类。
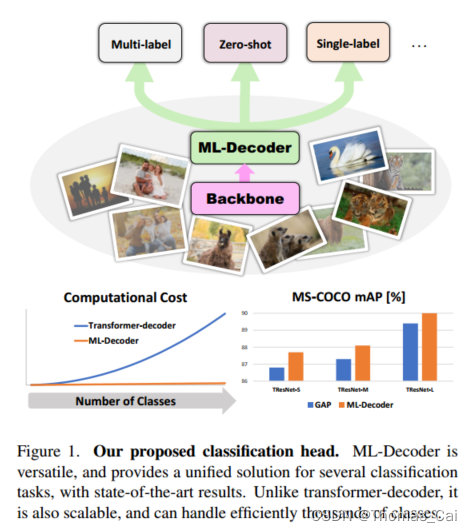
ML-Decoder灵活高效。它可以用可学习的或固定的查询进行同样好的训练,并且可以在训练和推理期间使用不同的查询(见图2)。这些关键特性使ML-Decoder适合ZSL任务。当我们为每个类分配查询并使用单词查询训练MLdecoder时,它可以很好地泛化到看不见的查询,并显着改进了以前最先进的ZSL结果。我们还证明了组解码方案可以扩展到ZSL场景,并在训练过程中引入新的查询增强以进一步促进泛化。
本文的贡献可以总结如下:
- 我们提出了一种新的分类头,称为ML-Decoder,它为多标签、零标签和单标签分类提供了统一的解决方案,并具有最先进的结果。
- ML-Decoder可以作为全局平均池化的替代方案。它简单而高效,与更大的主干或其他基于注意力的头相比,它提供了更好的速度和精度权衡。
- ML-Decoder新颖的设计使其可扩展到分类数千类。互补的查询增强技术也提高了它对不可见类的通用性。
- 我们通过对常用分类数据集(MS-COCO、Open Images、NUS-WIDE、PASCAL-VOC和ImageNet)的综合实验验证了ML-Decoder的有效性。
- 笔记:
以上是翻译带一点补充,然后是Intro,是介绍关于分类、多分类各大家的做法,然后提出自己的做法,并且总结了下自己的贡献。比较关键的几点在最后的贡献也总结了,好像也没啥其他好写的了= =下面看具体的方法,方法我就不翻译了,直接带理解的做笔记。
2. 方法
先是回顾baseline分类头,包括 GAP-based 和 Attention-based。然后再介绍本文的重点ML-Decorder,包括他的优点以及介绍他在CV多重任务中什么适用的,多重任务当然就包括多标签分类、ZSL、单标签分类。
2.1 Baseline分类头
首先是统一一套框架,backbone+cls head的结构:
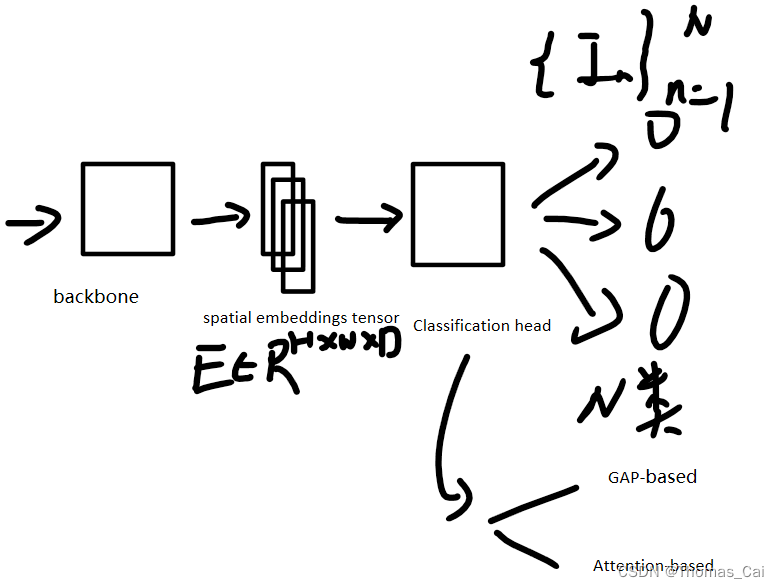
cls head又分为GAP-based和Attention-based,GAP-based就是用全局平均池化算子把backbone输出的tensort减到一维,然后全连接层转换为N个输出,N为类别,GAP通常处理单标签分类任务,有一定的泛化性,有些论文也把GAP作为多标签分类的baseline。
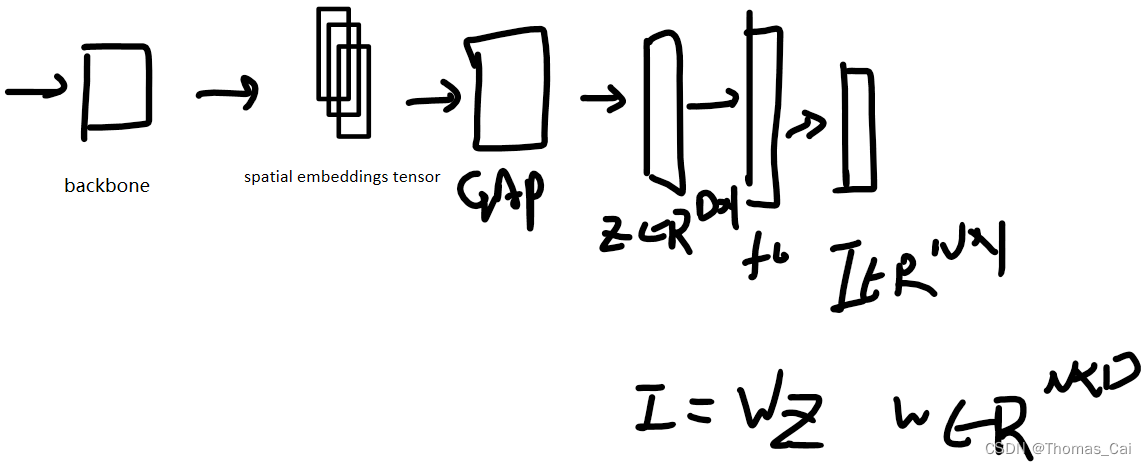
对于Attention-based的分类头,可以更好的使用空间数据,并提高结果,具体看下面。