文章目录
- 前言
- 一、join是什么?
- 二、join的使用例子
- 三、join的连接方式
- 1、简单嵌套
- 2、索引嵌套
- 3、块嵌套
- 4、哈希连接
前言
面试的时候,被问到join 的底层原理,之前没有深入了解过,今天对这个知识点进行一个学习。
一、join是什么?
JOIN 是用于将多个表中的数据按照指定的条件关联起来的操作,其本质就是各个表之间数据的循环匹配
二、join的使用例子
假设有两个表:customers 和 orders。
customers 表包含以下列:
- customer_id (主键)
- customer_name
- customer_email
orders 表包含以下列:
- order_id (主键)
- customer_id (外键,关联
customers表中的 customer_id) - order_date
- order_total
我们可以使用 JOIN 操作来查询某个客户的订单信息。以下是一个示例查询:
SELECT customers.customer_name, orders.order_id, orders.order_date, orders.order_total
FROM customers
JOIN orders ON customers.customer_id = orders.customer_id
WHERE customers.customer_name = 'John Doe';
上述查询使用 INNER JOIN 连接 customers 表和 orders 表,连接条件是 customers.customer_id = orders.customer_id。它将返回所有满足条件(customer_name 为 ‘John Doe’)的客户的订单信息。
在这个例子中,MySQL 的 JOIN 操作会根据连接条件将 customers 表和 orders 表进行连接。它会首先找到满足连接条件的行,然后将这些行组合起来形成结果集。最终的查询结果将包含客户名、订单ID、订单日期和订单总额等信息。
三、join的连接方式
5.5 版本之前,MySQL本身只支持一种表间关联方式,就是嵌套循环(Nested Loop Join)。如果关联表的数据量很大,则join关联的执行时间会非常长。在5.5以后的版本中,MySQL通过引入BNLJ算法来优化嵌套执行。
1、简单嵌套
这是 JOIN 操作最基本的连接算法。它通过两层循环嵌套来实现连接。对于 JOIN 操作中的每一行,MySQL 在连接的另一个表中执行一个循环,找到满足连接条件的匹配行。嵌套循环连接算法简单直观,但在处理大型数据集时可能效率较低。
2、索引嵌套
其优化的思路主要是为了 减少内层表数据的匹配次数,所以要求被驱动表上必须 有索引 才行。通过索引逐行匹配连接条件,而不是使用嵌套循环。这可以减少循环的次数,提高连接的性能。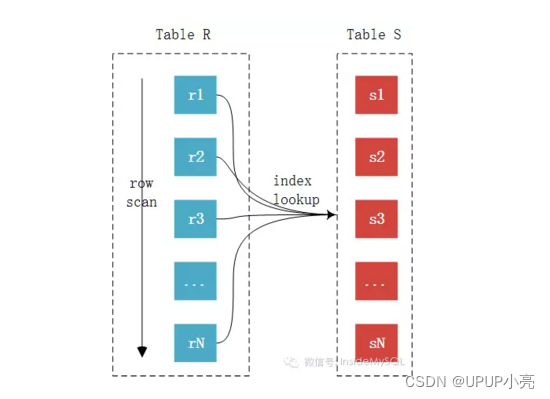
3、块嵌套
如果关联的是非驱动表的索引会走索引嵌套,但如果join的列不是索引,就会采用Block Nested-Loop Join
不再是逐条获取驱动表的数据,而是一块一块的获取,引入了 join buffer 缓冲区,将驱动表 join 相关的部分数据列(大小受 join buffer 的限制)缓存到 join buffer 中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和 join buffer 中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被动表的访问频率。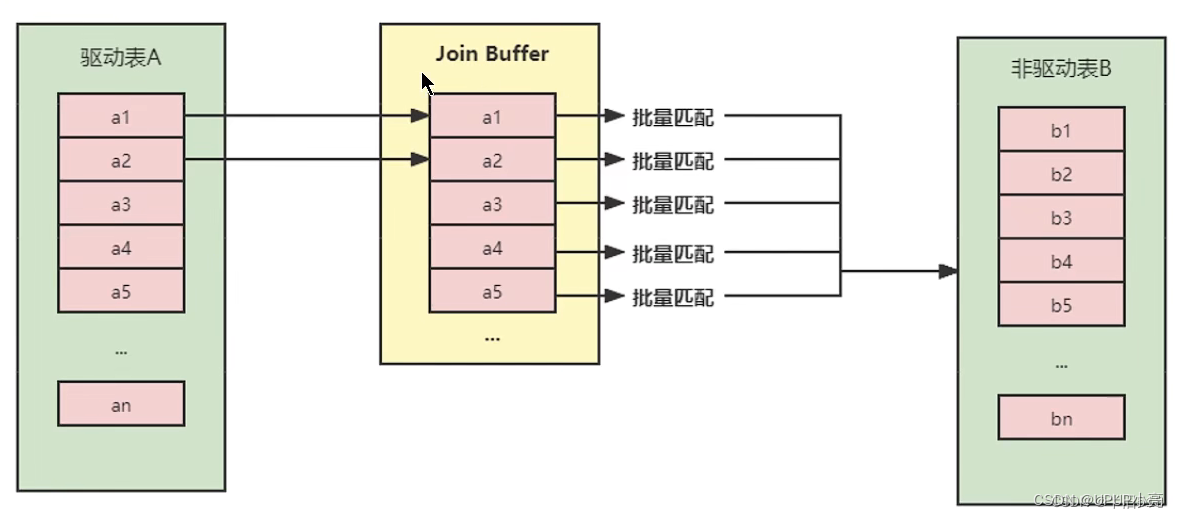
4、哈希连接
如果连接的列上没有适用的索引,并且数据量较大,MySQL 可以使用哈希连接算法。哈希连接算法首先将连接的两个表中的连接列进行哈希操作,然后根据哈希值将行分配到不同的哈希桶中。接下来,MySQL 通过匹配相同哈希值的行来找到满足连接条件的行。哈希连接算法适用于大型数据集和无序的连接列,但它需要额外的内存来存储哈希表




![2023年中国超导磁体市场规模、需求量及行业竞争现状分析[图]](https://img-blog.csdnimg.cn/img_convert/c980ca74031ba7a842bede9752dbebcf.png)





![[电源选项]没有系统散热方式,没有被动散热选项](https://img-blog.csdnimg.cn/dcd5e6e7c5b24b12a496aa18247ae64f.png)
