文章目录
- 10. Spark
- 10.1 Spark简介
- 10.1.1 Spark简介
- 10.1.2 Spark和Hadoop的对比
- 10.2 Spark生态系统
- 10.3 Spark运行架构
- 10.3.1 基本概念和架构设计
- 10.3.2 Spark运行基本流程
- 10.3.3 RDD概念
- 10.3.4 RDD特性
- 10.3.5 RDD的依赖关系和运行过程
- 10.4 Spark SQL
- 10.5 Spark的部署和应用方式
- 10.6 Spark安装和编程实践
- 10.6.1 安装Spark
- 10.6.2 Spark RDD基本操作
- 10.6.3 使用Maven编译打包Java程序
- 10.6.4 使用sbt编译打包Scala程序
10. Spark
10.1 Spark简介
10.1.1 Spark简介
-
Spark最初由美国加州伯克利大学 ( UC Berkeley )的AMP实验室于2009年开发,是基于
内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序 -
2013年Spark加入Apache孵化器项目后发展迅猛,如今己成为Apache软件基金会最重要的三大分布式计算系统开源项目之一 ( Hadoop、Spark、 Storm )
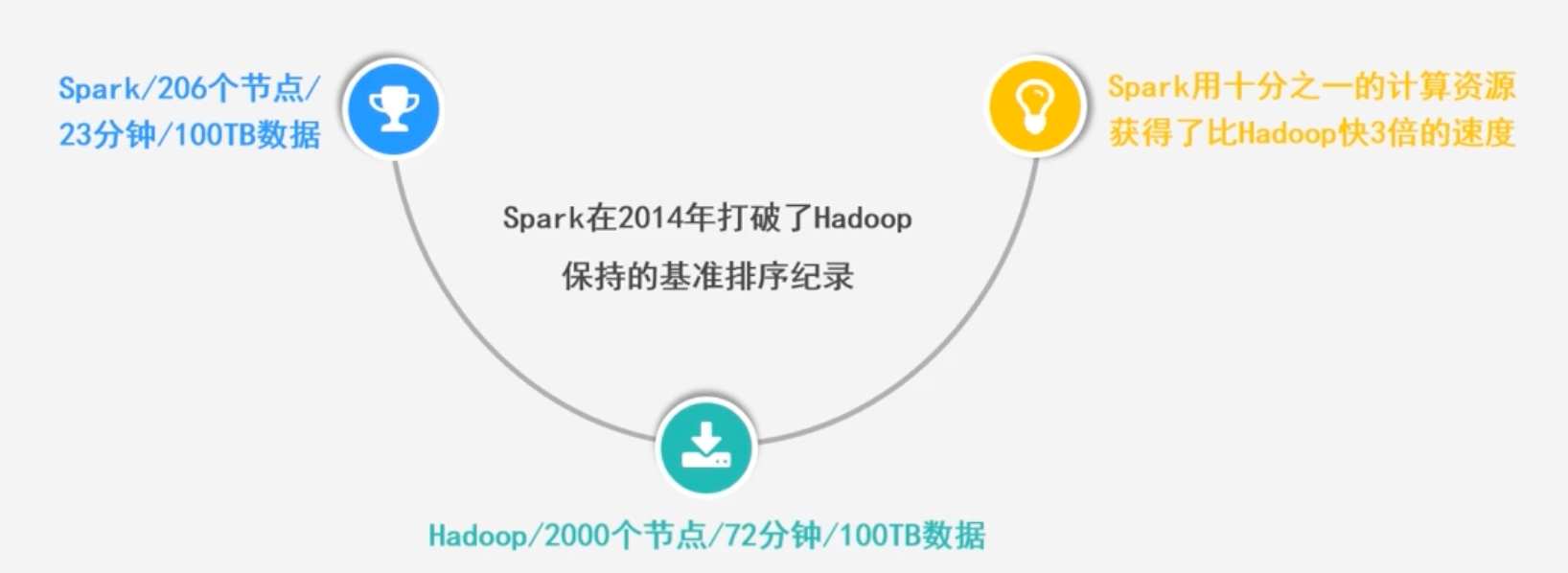
- 运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
- 容易使用:支持使用Scala、Java、Python和R语言进行编程、可以通过Spark Shell进行交互式编译
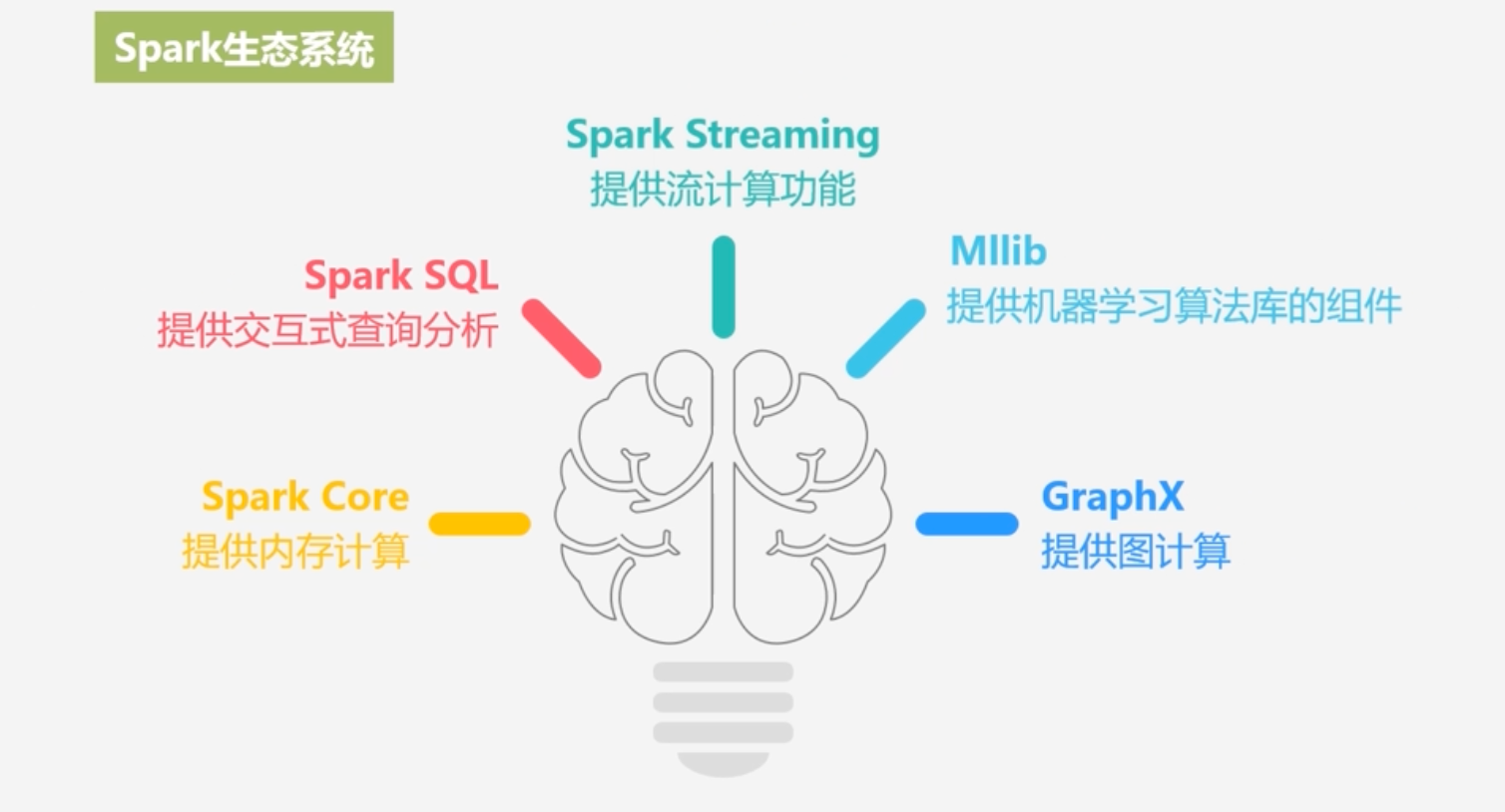
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
- 运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源
-
Spark的发展趋势
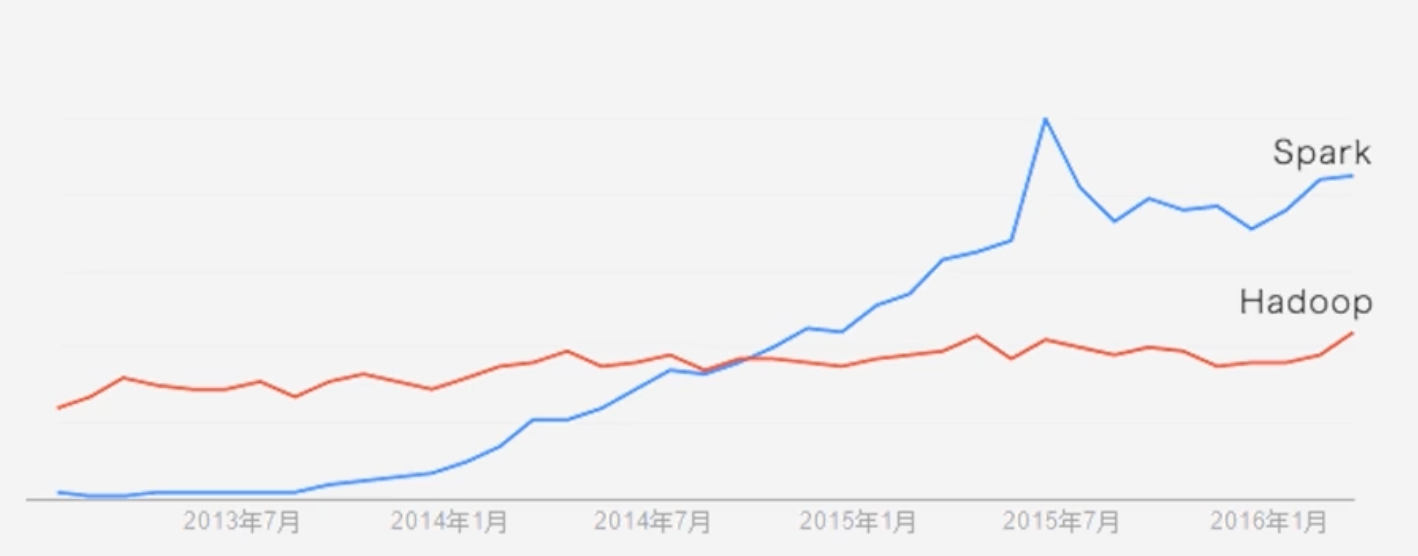
-
Scala是一门现代的多范式编程语言
- Spark是由Scala编写的,运行于Java平台(JVM、Java虚拟机),并兼容现有的Java程序
- Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统
- Scala语法简洁,能提供优雅的API
- Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中
注意:虽然Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言
Scala的优势是提供了REPL(Read-Eval-Print Loop,交互式解释器),提高程序开发效率
10.1.2 Spark和Hadoop的对比
-
Hadoop的缺点
-
表达能力有限:并不是所有的任务都能用MapReduce去解决
-
磁盘IO开销大:所有中间结果需要写到HDFS中去
-
延迟高
-
任务之间的衔接涉及IO开销
-
在前一个任务执行完成之前,其他任务久无法开始,难以胜任复杂、多阶段的计算任务
-
-
Spark相比于MapReduce的优点
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
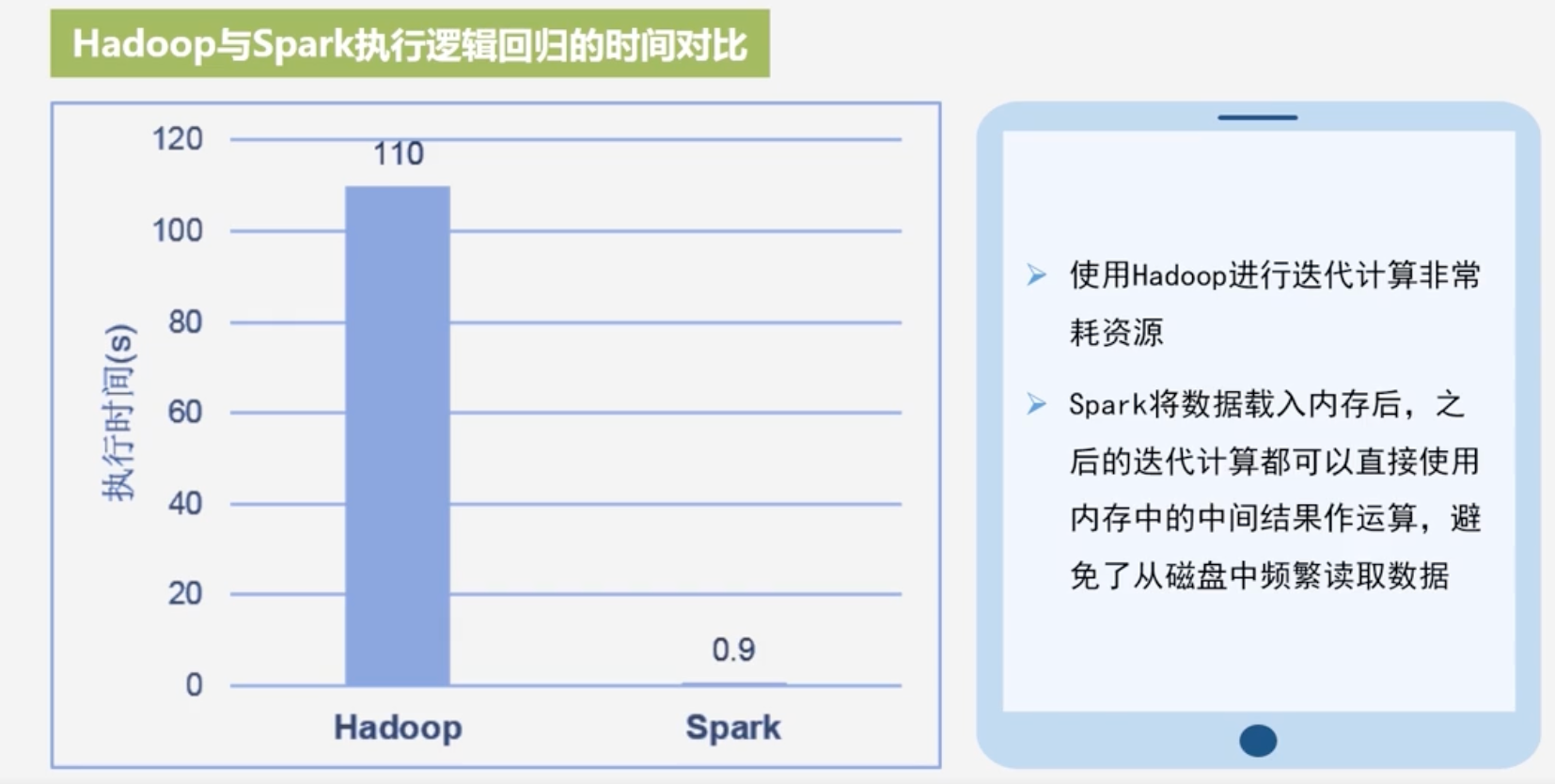
- Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
- Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
-
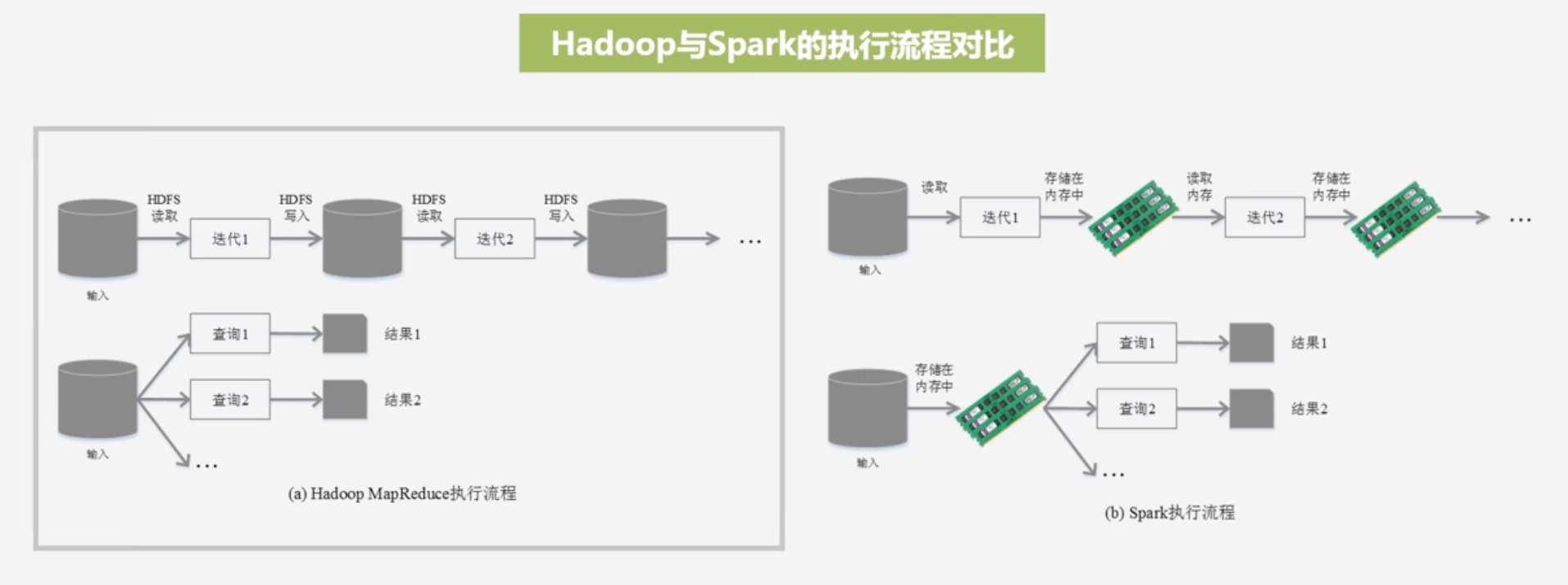
Hadoop与Spark的执行流程对比
- Hadoop每次都是从磁盘读取数据,完成迭代计算,再写入磁盘,如此往复
- Spark从磁盘中读取完数据就放在内存,迭代的结果仍然保存在内存中
-
Hadoop与Spark执行逻辑回归的时间对比
10.2 Spark生态系统
-
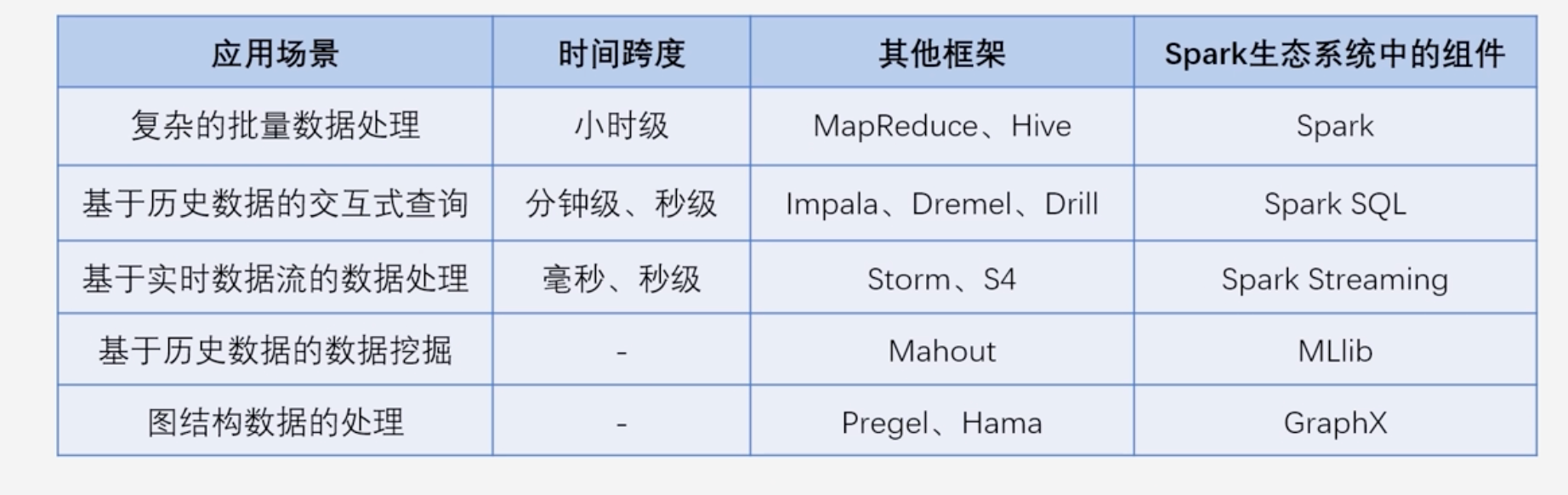
大数据处理主要包括以下三个场景类型
- 复杂的批量数据处理:通常跨度在数十分钟到数小时之间
- 基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间
- 基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间
-
当同时存在以上三种场景时,就需要同时部署三种不同的软件

- 同时部署不同软件问题?
- 不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
- 不同软件需要不同的开发和维护团队,带来了较高的使用成本
- 比较难以对同一个集群中的各个系统进行统一的资源协调和分配
- 同时部署不同软件问题?
-
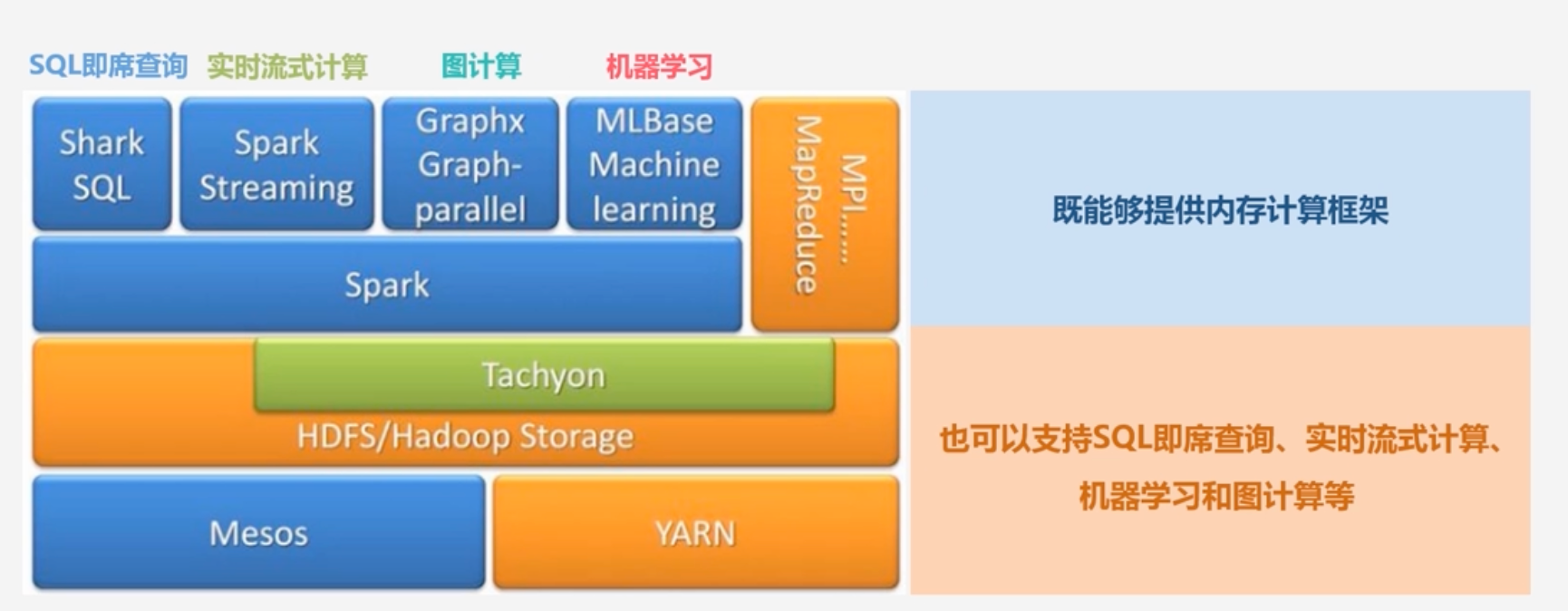
Spark设计:遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统
-
既能够提供内存计算框架
-
也可以支持SQL即时查询、实时流式计算、机器学习和图计算等
-
Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案
-
Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理
-
Spark生态系统已经成为伯克利数据分析软件栈BDAS(Berkeley Data Analytics Stack)的重要组成部分

-
-
Spark生态系统
-
Spark生态系统组件的应用场景
10.3 Spark运行架构
10.3.1 基本概念和架构设计
-
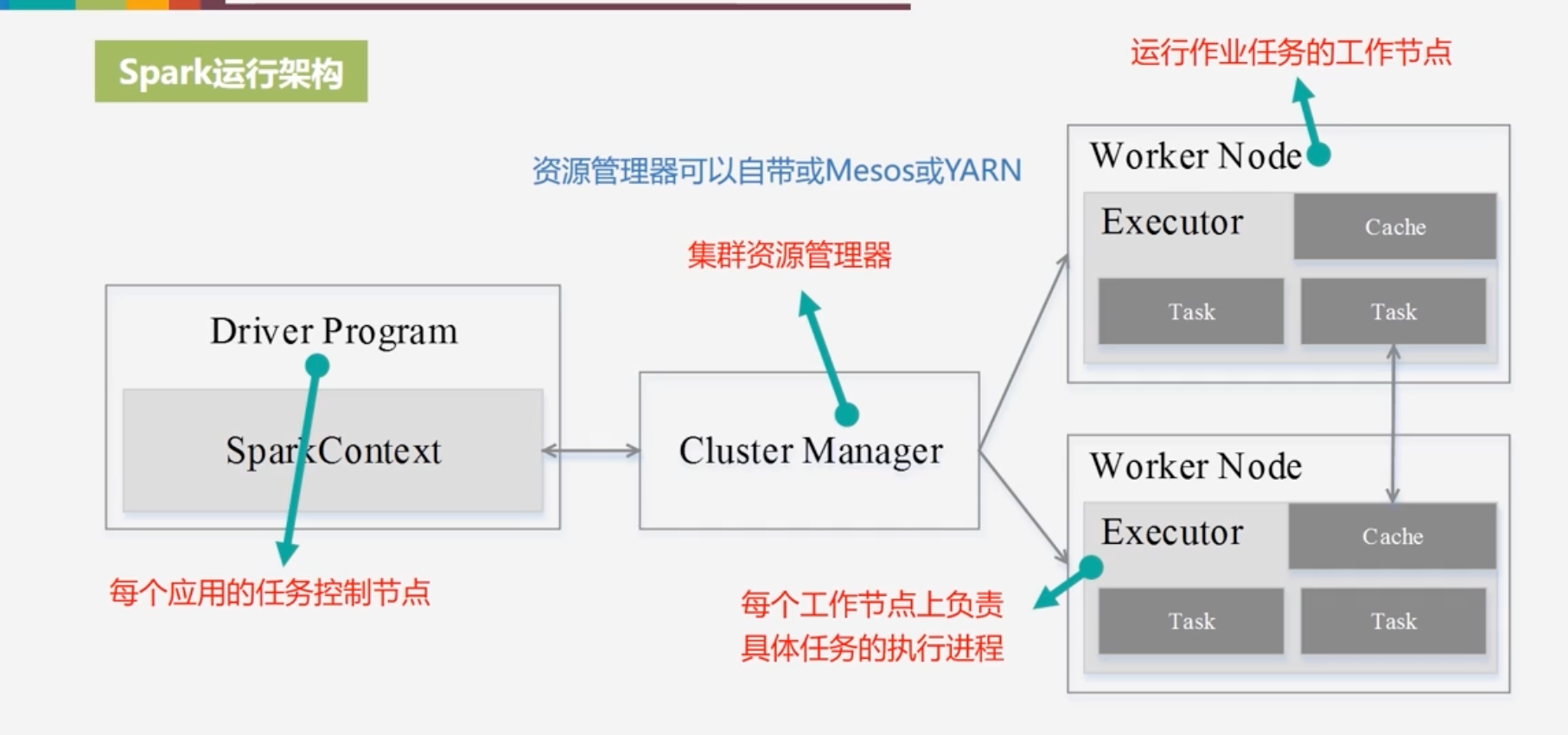
基本概念
-
RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
-
DAG:是Directed Acyalic Graph(有向无环图)的简称,反映RDD之问的依赖关系
-
Executor:是运行在工作节点 (WorkerNode)的一个进程,负责运行Task
-
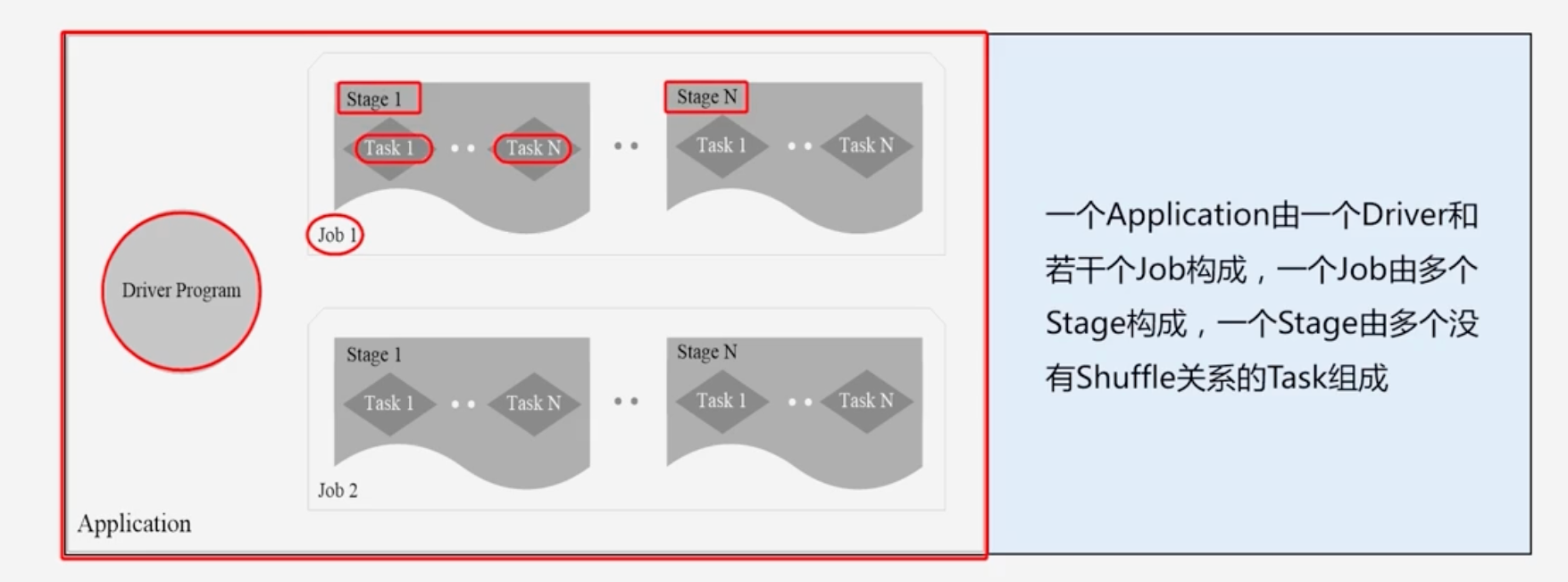
Application:用户编写的Spark应用程序
-
Task:运行在Executor 上的工作单元
-
Job:一个Job包含多个RDD及作用于相应RDD上的各种操作
-
Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage, 或者也被称为TaskSet,代表了一组关联的、相互之问没有
Shuffle依赖关系的任务组成的任务集
-
-
Spark运行架构
-
Cluster Manager:集群资源管理器,负责对集群资源的分配和调度
-
-
Spark架构设计
- 与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点
- Executor是利用多线程的方式来执行具体的Task任务,减少任务的启动开销,MapReduce是以进程的方式启动
- Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销
- 与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点
-
Spark中各种概念之间的相互关系
-
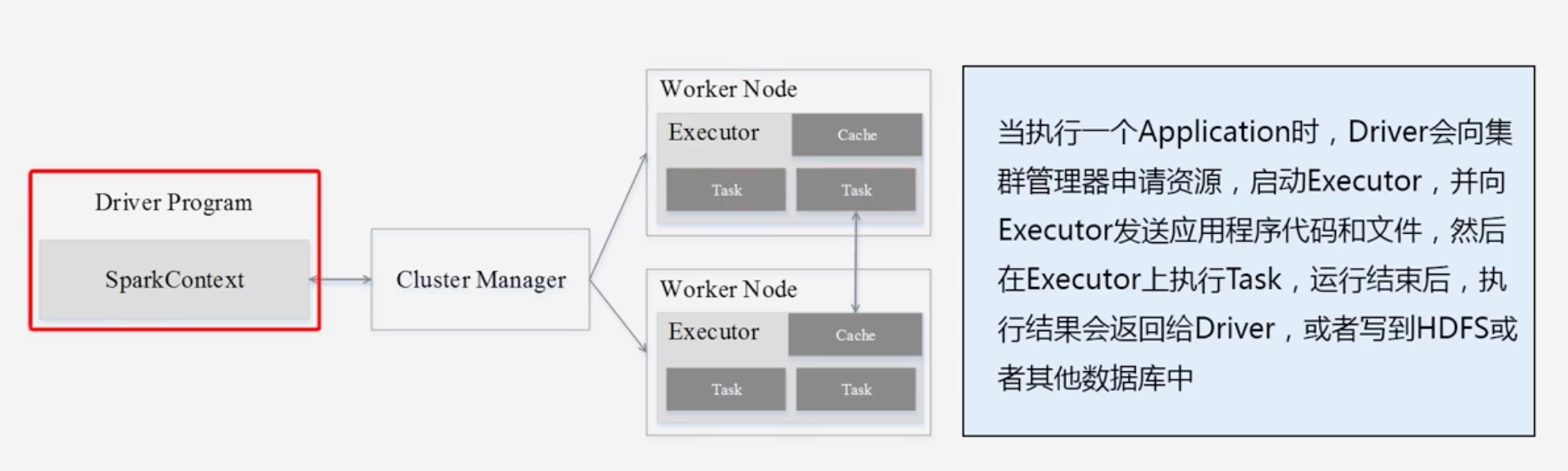
Spark执行Application过程
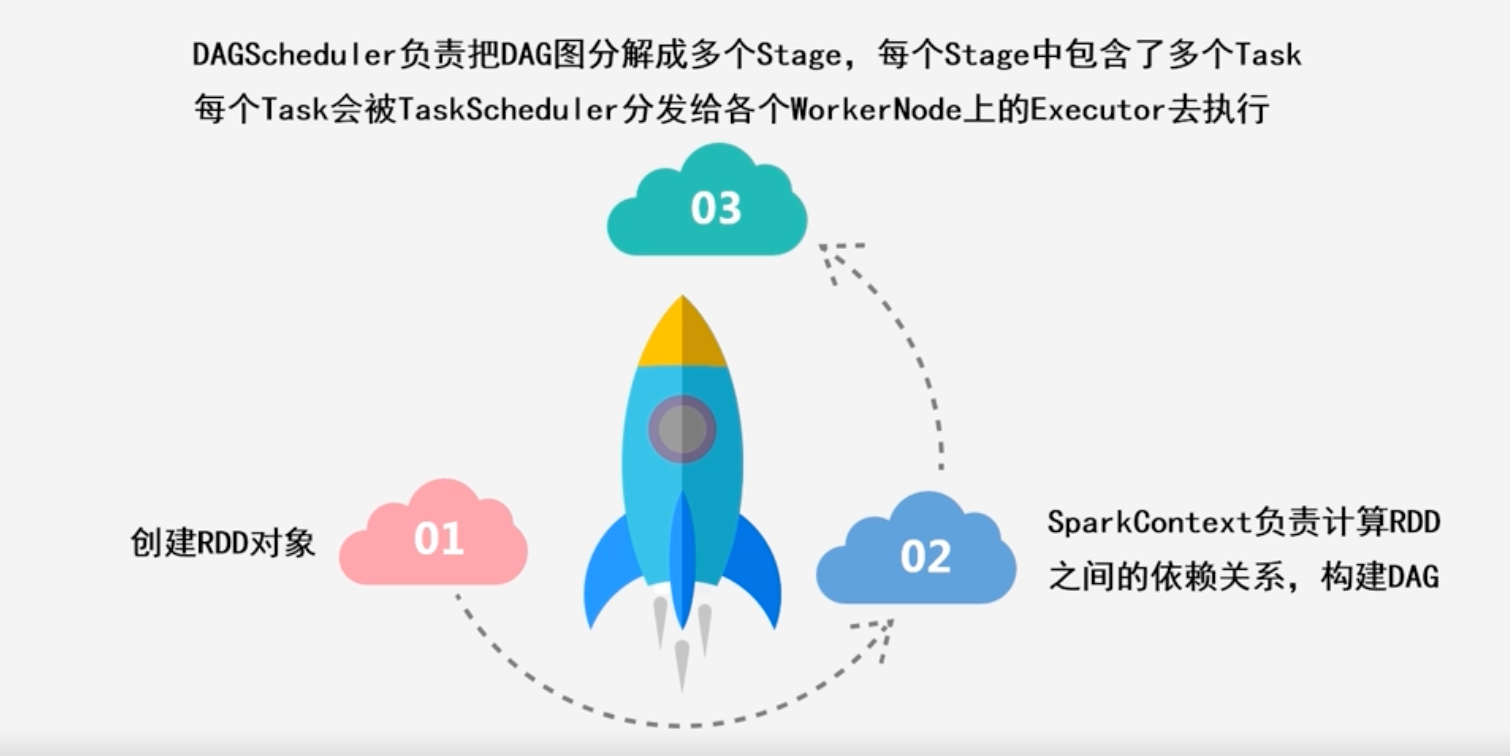
10.3.2 Spark运行基本流程
-
Spark运行基本流程
-
- 注册并申请资源
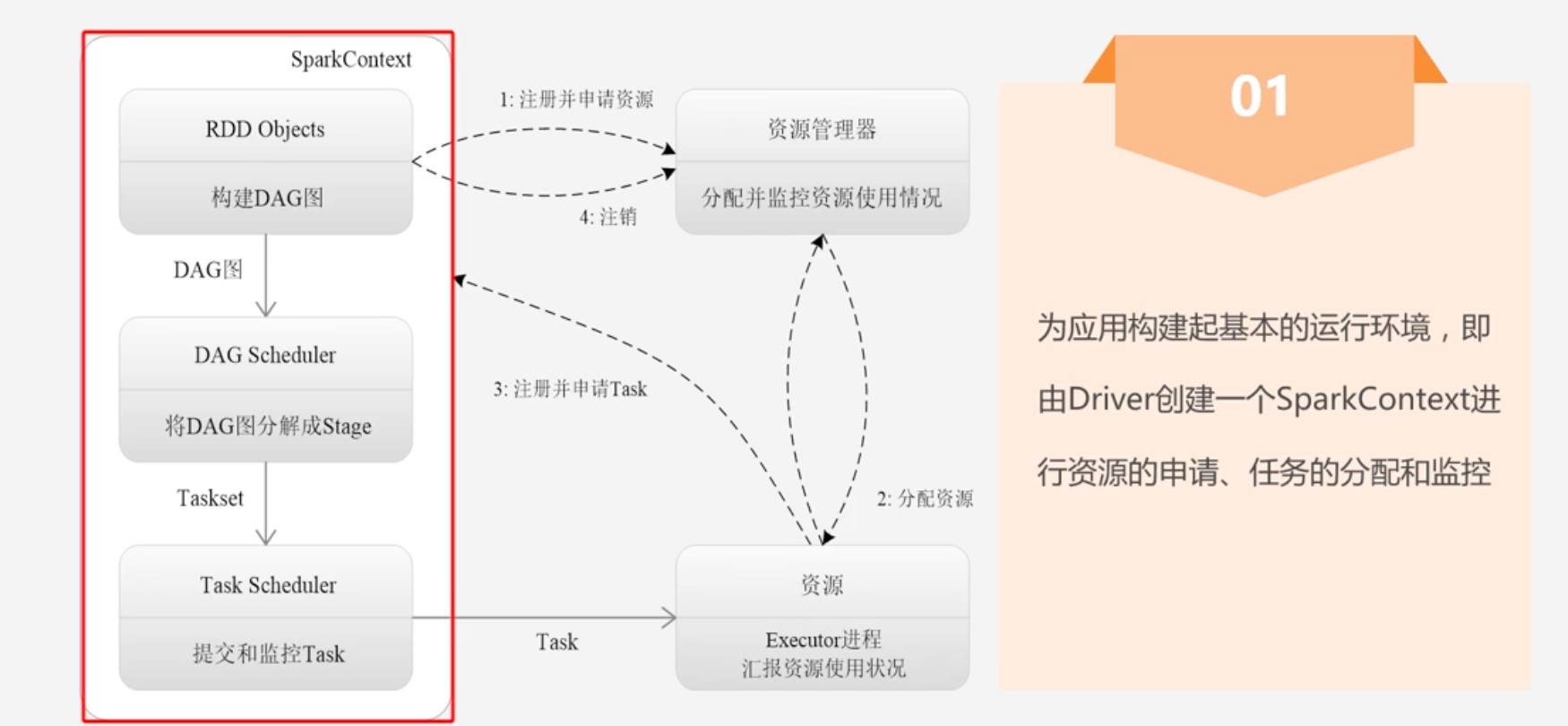
-
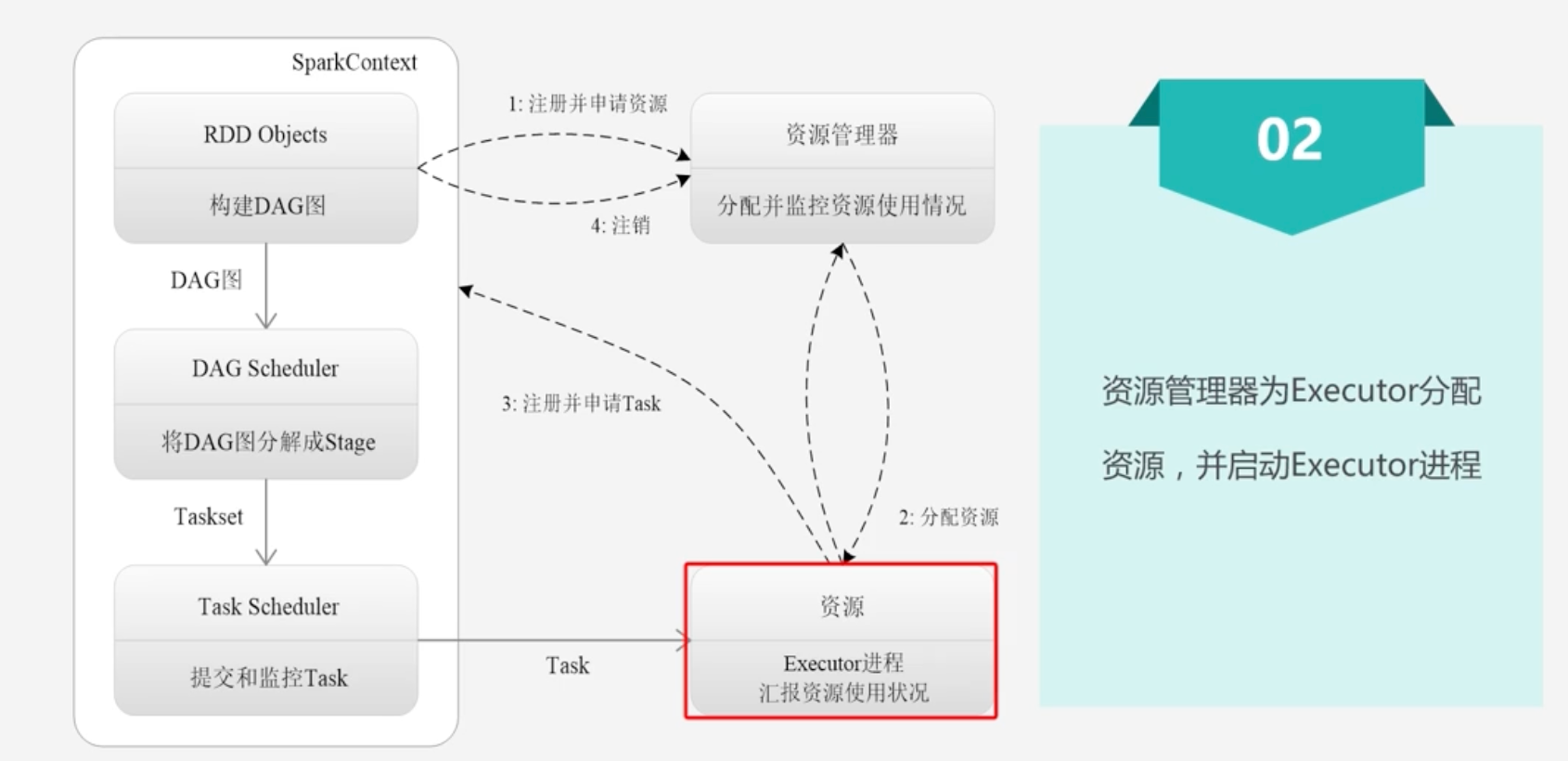
2.为Executor分配资源
- Executor启动之后,会不断的向资源管理器汇报资源的使用情况
-
3.注册并申请Task
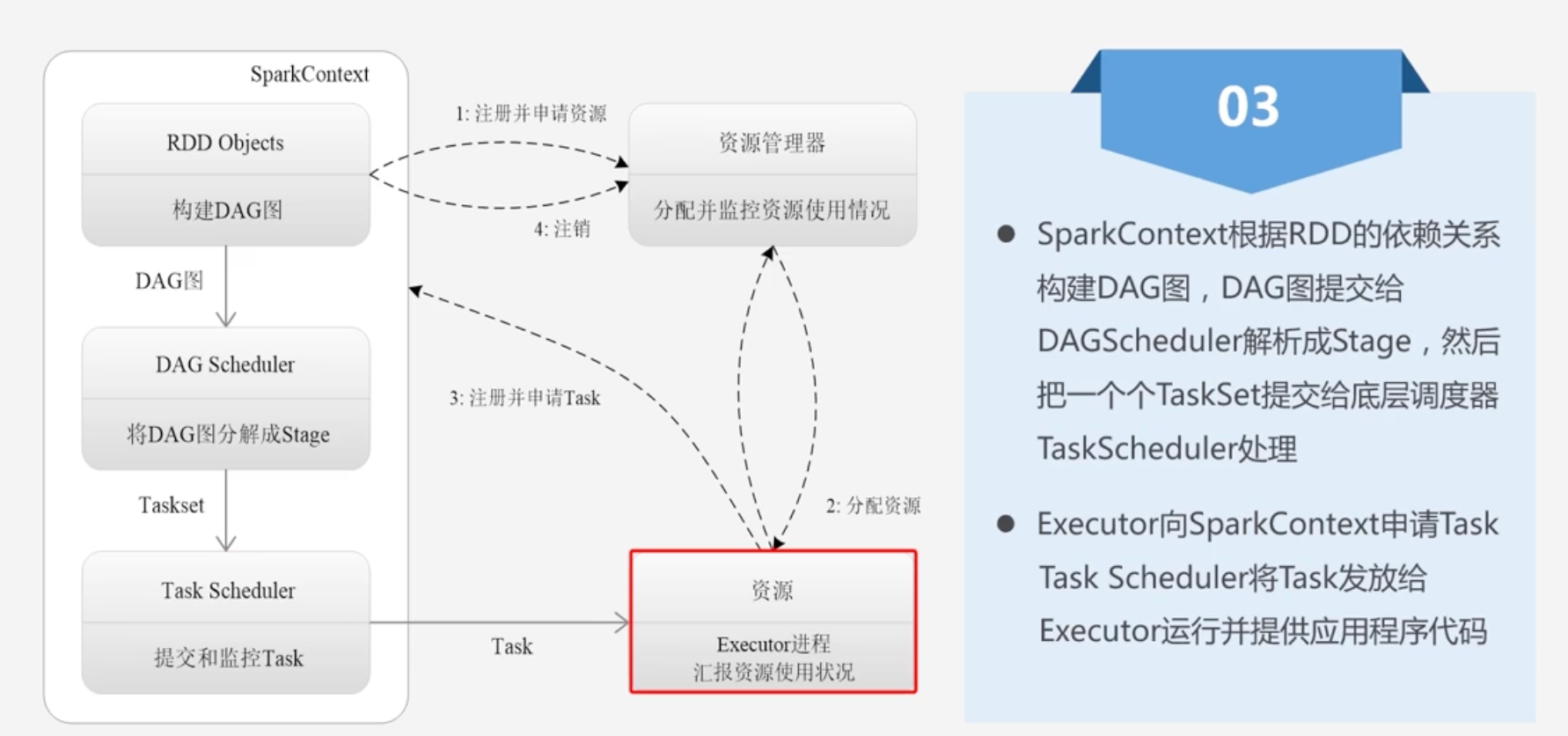
-
4.反馈结果并注销
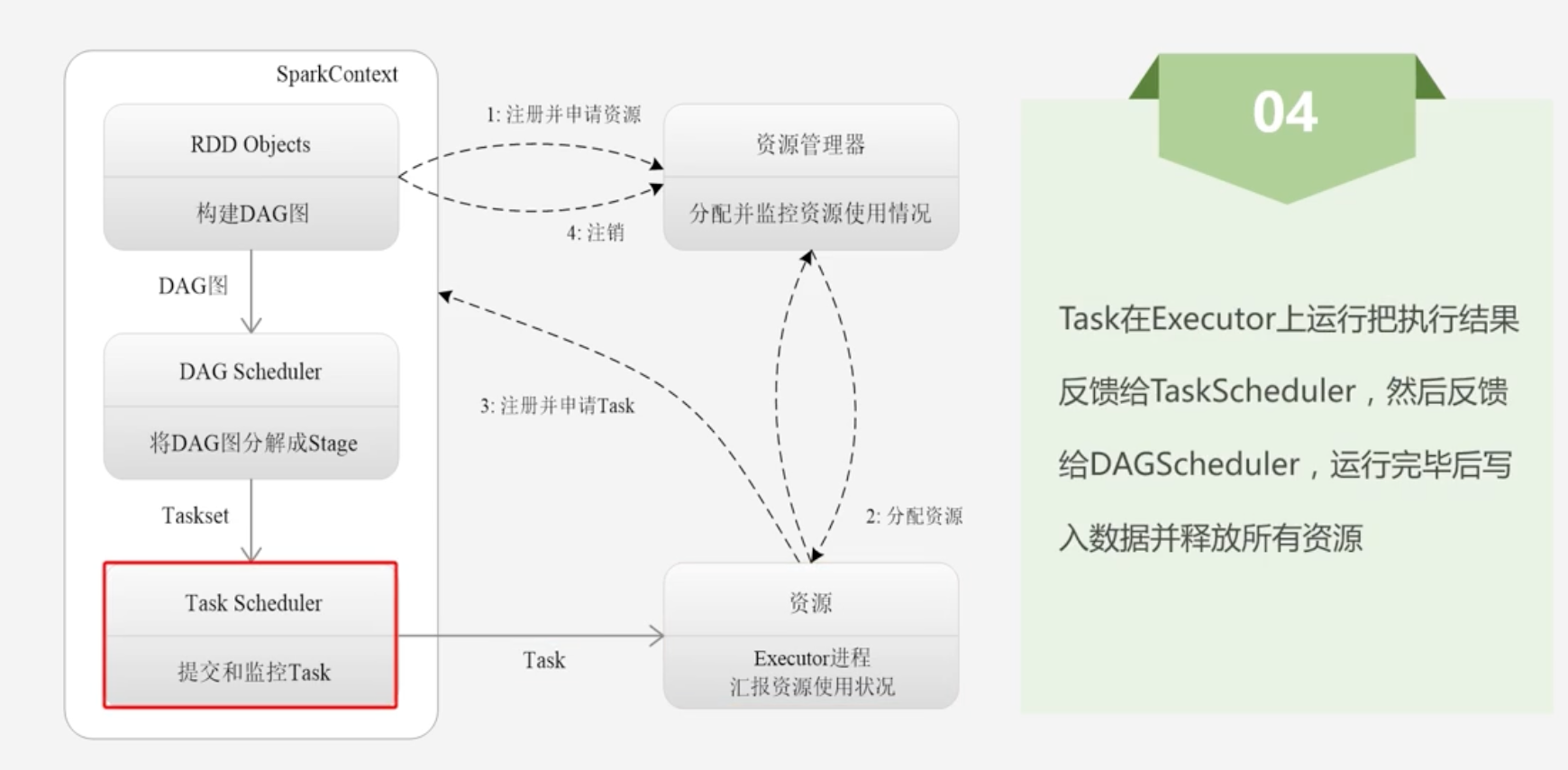
-
-
Spark运行架构特点
- 每个Application都有自己专属的Executor进程,井且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task。
- Spark运行过程与资源管理器无关,只要能够获取Executor进程井保持通信即可
- Task采用了数据本地性和推测执行等优化机制
- 数据本地性:计算向数据靠拢,Task靠近数据所在地方运行
- 推测执行:假设运行Task节点的数据节点已经有其他Task任务运行,并且占据资源;它会自动推测是继续等到上个Task释放资源,还是数据移动到其他数据节点所消耗的时间更少
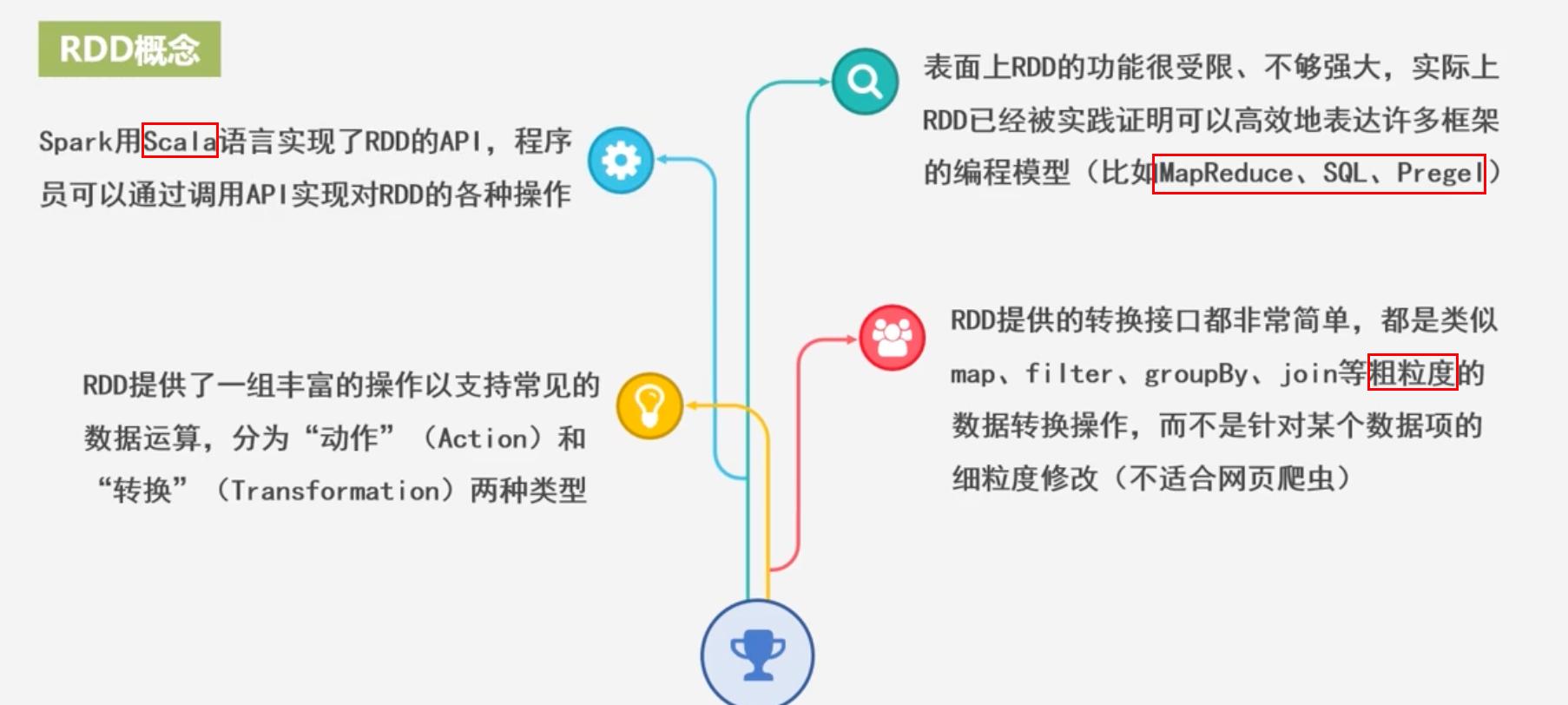
10.3.3 RDD概念
-
设计背景

- RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据结构
- 我们不必担心底层数据的分布式特性、只需要将具体的应用逻辑表达为一系列转换处理
- 不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
-
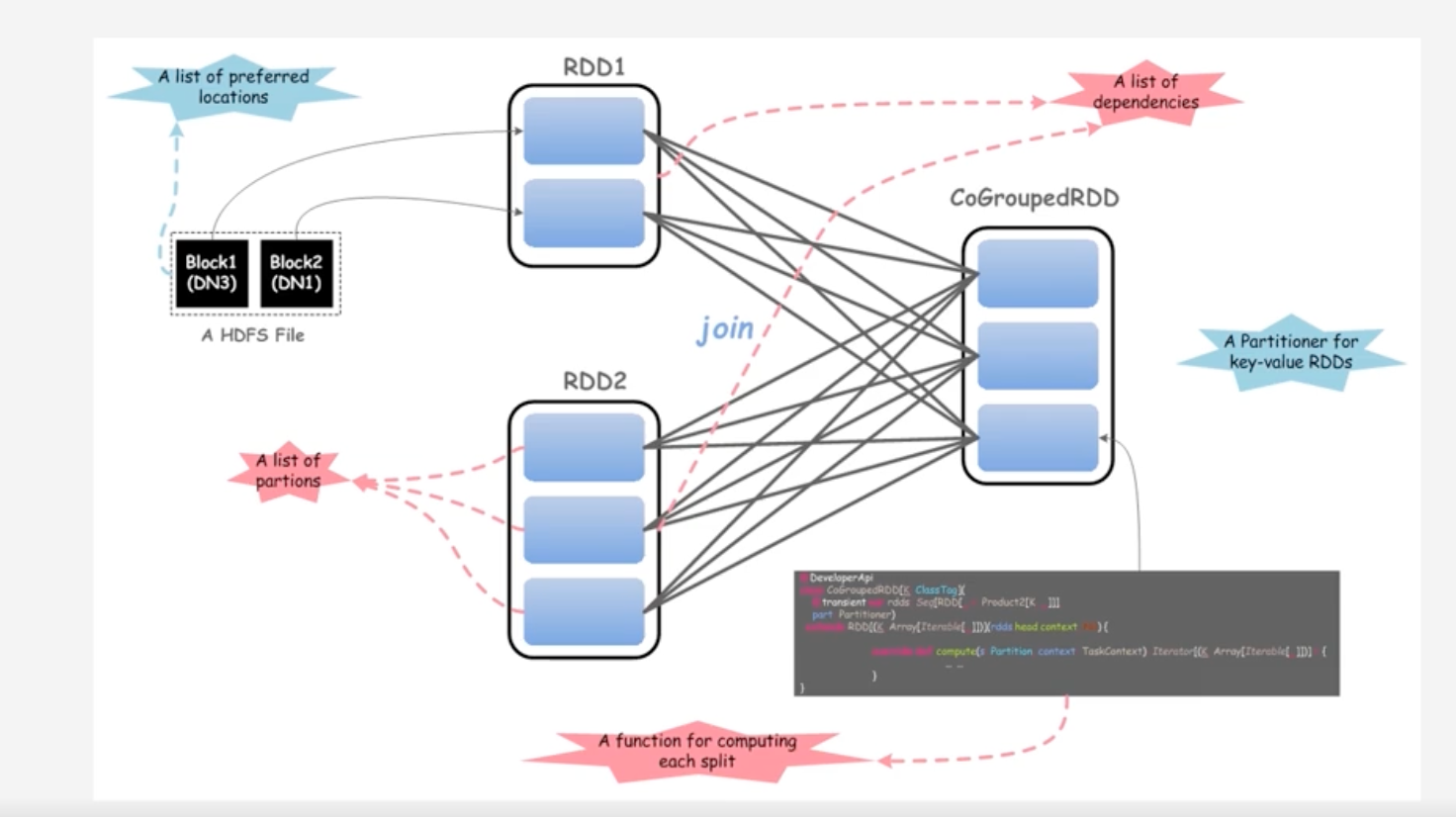
RDD概念
-
一个RDD就是一个分布式对象集合,本质上是一个
只读的分布记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以保存到集群中不同节点上,从而可以在集群中的不同节点上进行并行计算 -
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join、和group by)而创建得到新的RDD
-
RDD的典型执行过程如下

-
RDD执行过程实例
-
RDD最后一步Action操作才会生成具体结果
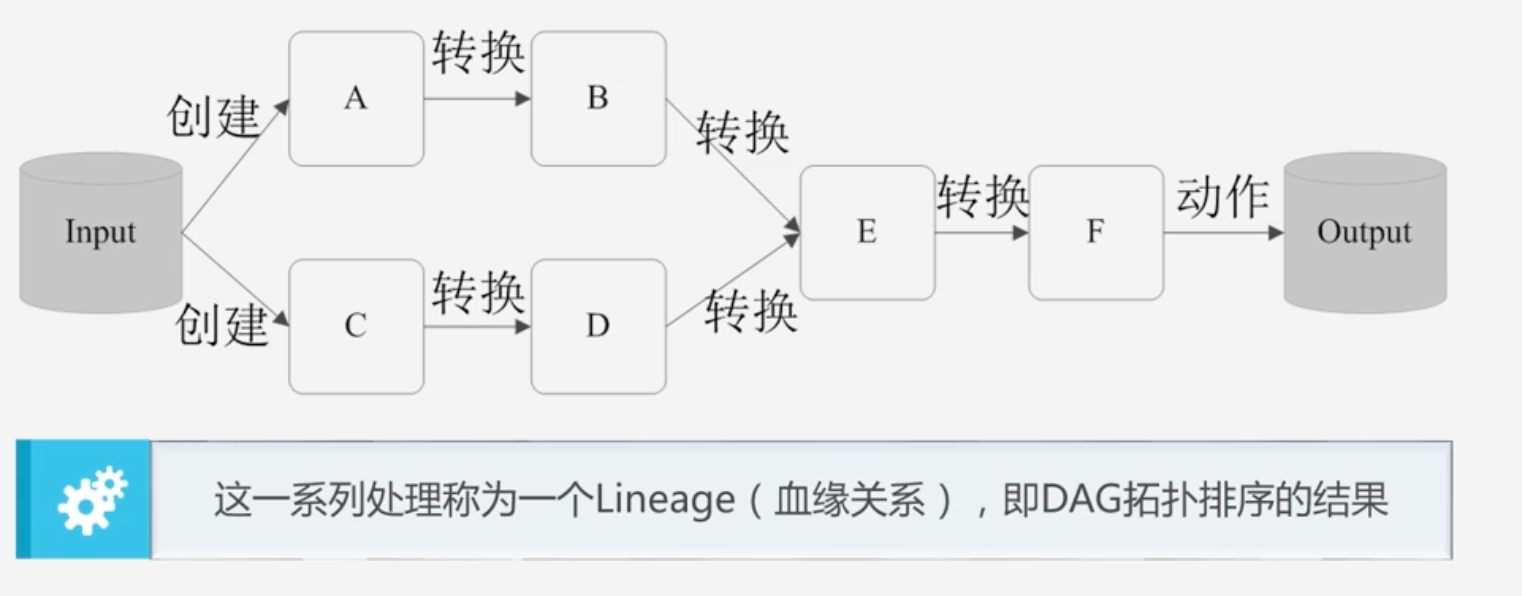
优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、每次操作变得简单
-
-
10.3.4 RDD特性
-
Spark采用RDD以后能够实现高效计算的原因
-
现有容错机制:数据复制或者记录日志;在数据密集型任务中,采用这种方式进行容错的代价昂贵
-
RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只计算粗粒度的操作,具有高效的容错性
-
RDD执行构成有向无环图,若是某个RDD出故障,只需要从它的父RDD重新计算恢复即可
-
中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销
-
存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
-
-
10.3.5 RDD的依赖关系和运行过程
-
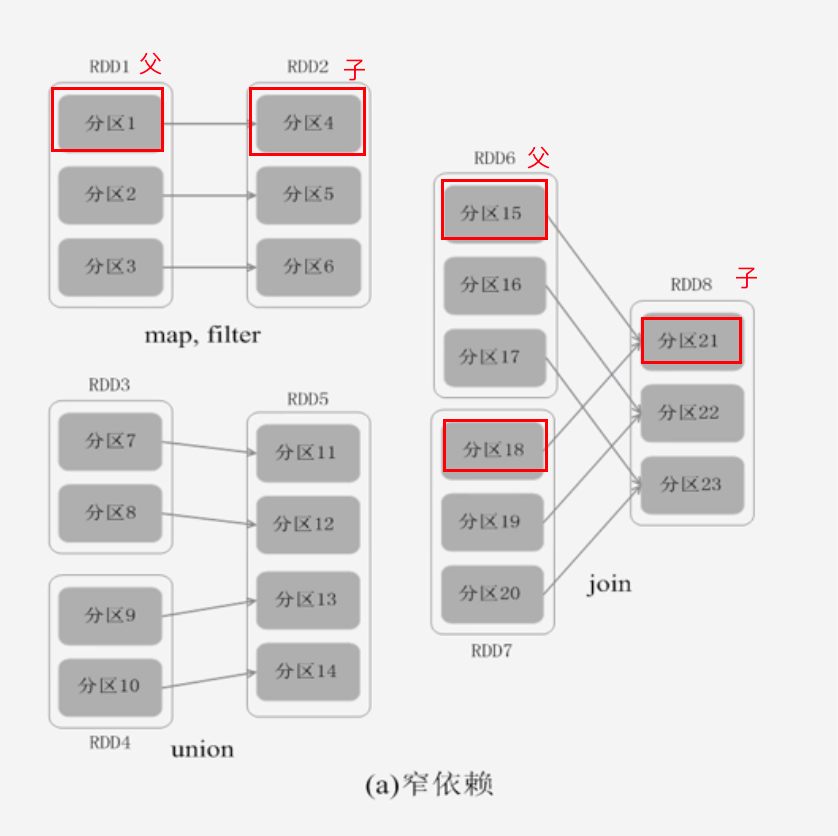
RDD之间的依赖关系(宽依赖、窄依赖)是划分Stage的依据
- 窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区,或者多个父RDD的分区对应于一个子RDD的分区
-
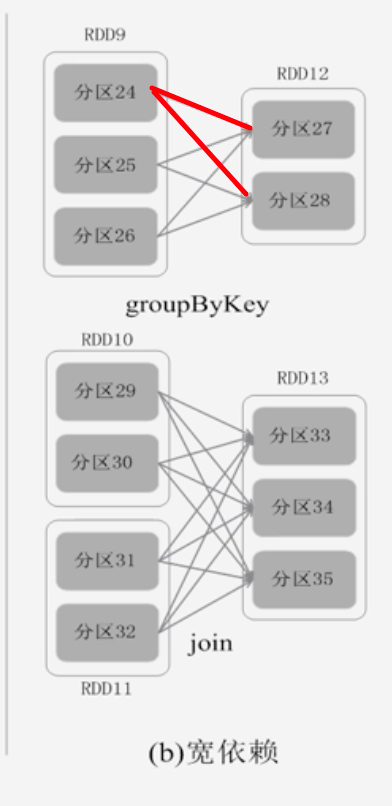
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区
-
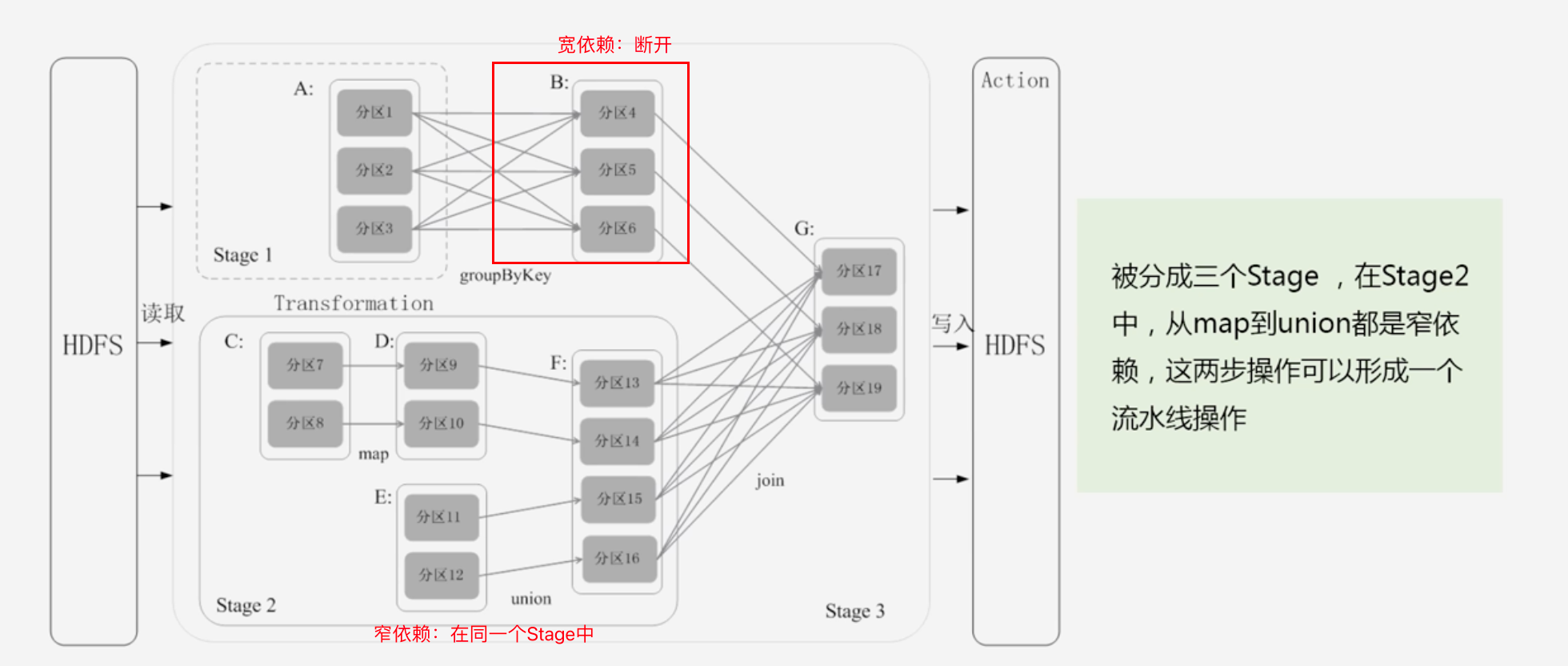
Stage的划分:Spark通过分析各个RDD的依赖关系生成DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage
-
具体划分方法:
- 在DAG中进行反向解析,遇到宽依赖就断开
- 遇到窄依赖就把当前的RDD加入到Stage中
- 将窄依赖尽量划分在同一个Stage中,可以实现流水线计算,从而使得数据可以直接在内存中进行交换,避免了磁盘IO开销
-
Stage划分举例:
-
Stage类型:
- ShuffleMapStage
- 他不是最终的Stage,在它之后还有其他Stage,所以,它的输出一定需要经过Shffle过程,并作为后续Stage的输入
- 这种Stage是以Shuffle为输出边界,其输入边界可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出,其输出可以是另一个Stage的开始
- 在一个Job里可以包含该类型的Stage,也可能没有该类型的Stage
- ResultStage
- 最终的Stage,没有输出,而是直接产生结果或存储
- 这种Stage是直接输出结果,其输入边界可以是从外部获取数据,也可以是另外一个ShuffleMapStage的输出
- 在一个Job里必定有该类型的Stage
- 因此,一个Job含有一个或者多个Stage,其中至少含有一个ResultStage
- ShuffleMapStage
-
-
RDD运行过程:
10.4 Spark SQL
-
Shark(
Hive on Spark)

-
其执行步骤只在生成执行计划时有区别,其可能带来的问题:
-
执行计划优化完全依赖于Hive,不方便添加新的优化策略
-
Spark是线程级的并行,而MapReduce是进程级并行,因此Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支
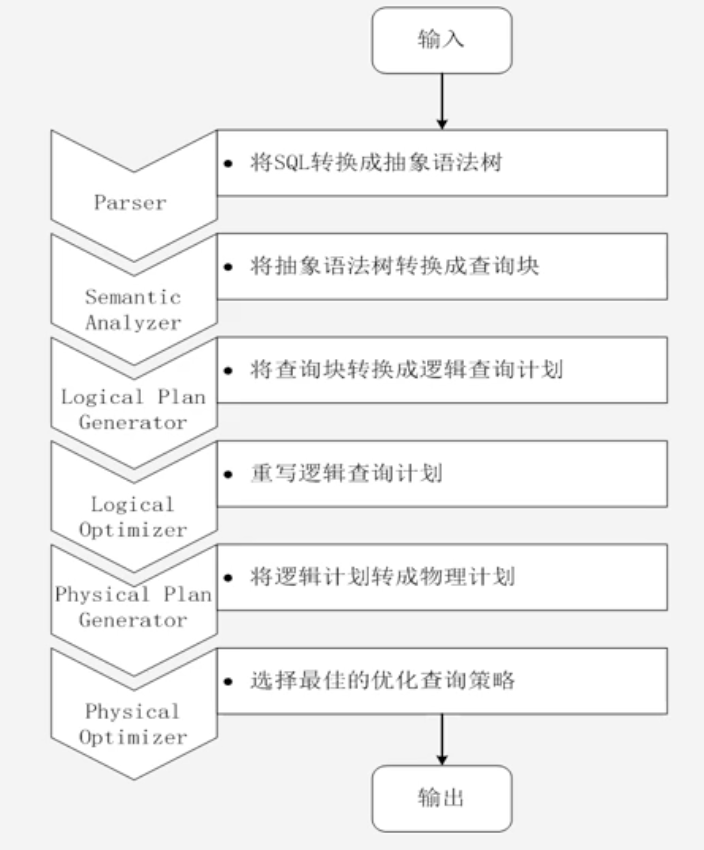
因此Shark被停止开发
-
-
Spark SQL架构
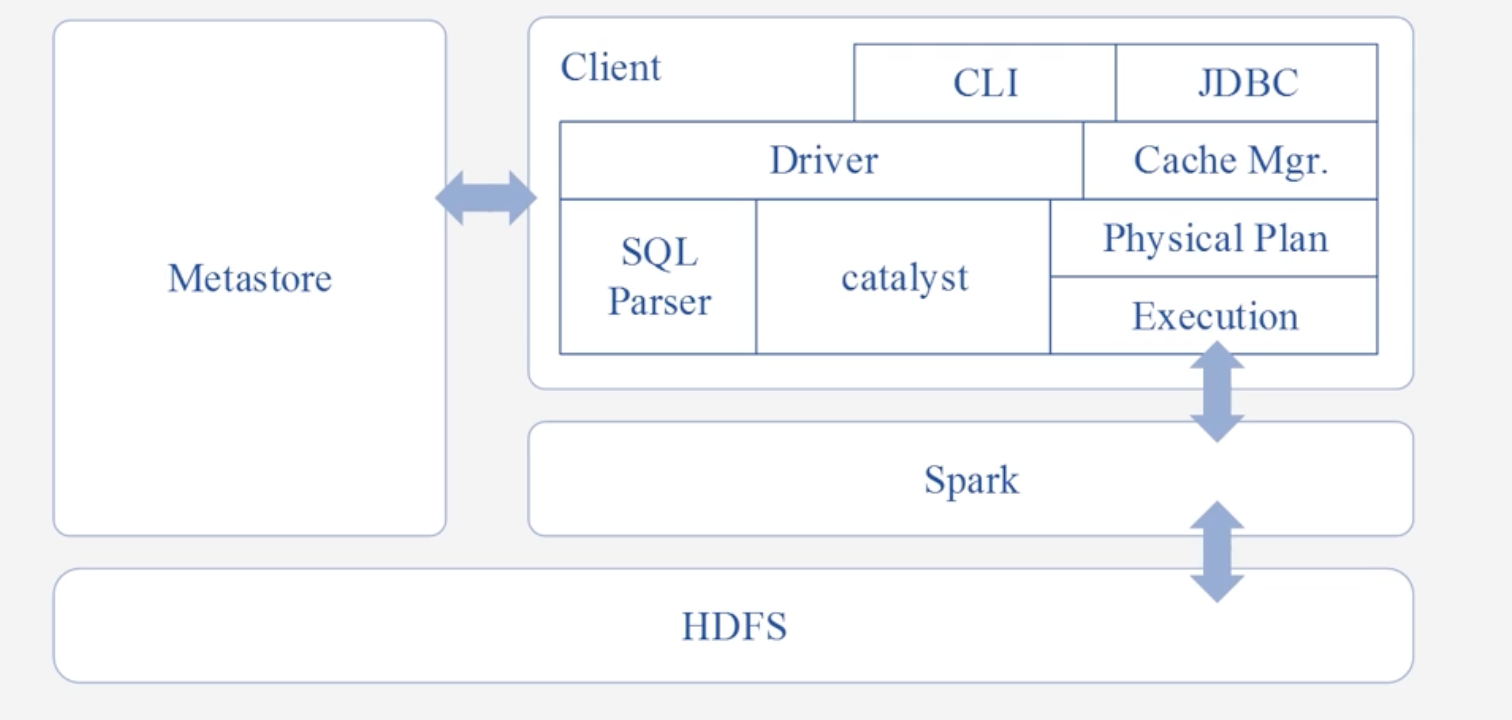
- Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据。即从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
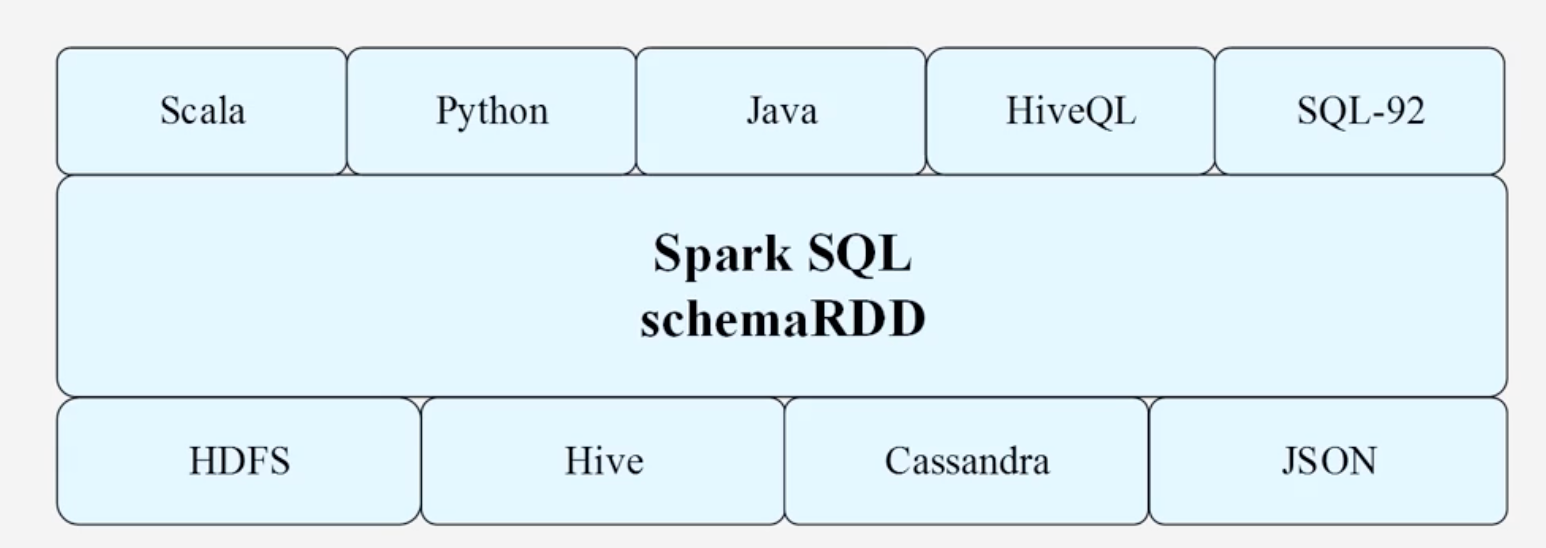
- Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句
- 它允许在SchemaRDD中封装多种数据源数据:Hive、HDFS、Cassandra、JSON
-
Spark SQL目前支持Scala、Java、Python三种语言、支持SQL-92规范
10.5 Spark的部署和应用方式
-
Spark三种部署方式
-
Standalone:类似于MapReduce1.0,slot为资源分配单位
-
Spark on Mesos:Mesos也是一个资源管理框架,它和Spark有一定的亲缘关系
-
Spark on Yarn:

-
-
企业部署大数据分析平台的案例
- 这个架构部署较为繁琐
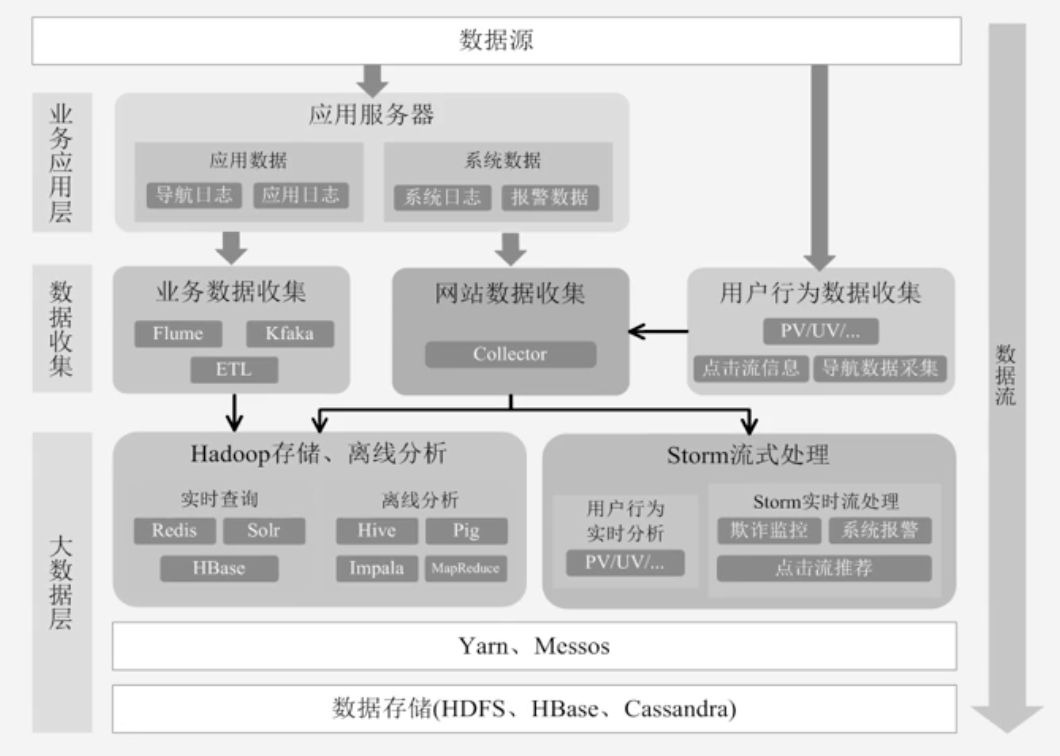
-
而用Spark架构可以同时满足批处理和流处理需求:
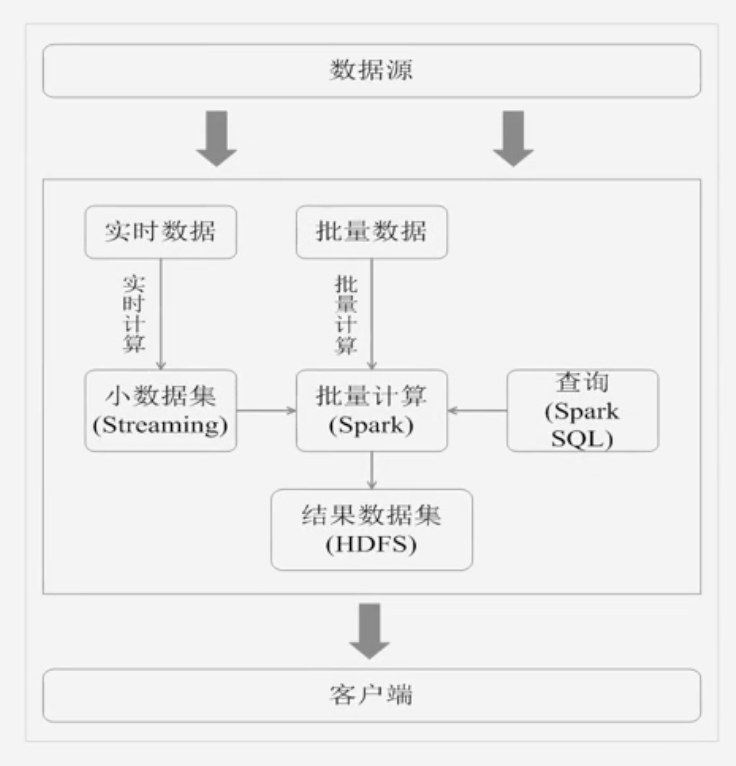
注意,Spark Streaming无法实现毫秒级别的流计算,因此,对于需要毫秒级别实时响应的企业应用而言,仍然需要采用流计算框架(如Storm)
-
用Spark架构的优点:
- 实现一键式安装和配置、线程级别的任务监控和告警
- 降低硬件集群、软件维护、任务监控和应用开发难度
- 便于做成统一的硬件、计算平台资源池
-
企业采用Hadoop和Spark统一部署的原因
-
由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代
-
现有的Hadoop组件开发的应用,完全转移到Spark上需要一定的成本

-
不同的计算框架统一运行在YARN中,可以带来如下好处
- 计算资源按需伸缩
- 不同负载应用混搭,集群利用率高
- 共享底层存储(HDFS),避免数据跨集群迁移
-
10.6 Spark安装和编程实践
10.6.1 安装Spark
见:Spark安装和编程实践(Spark3.4.0)_厦大数据库实验室博客 (xmu.edu.cn)
10.6.2 Spark RDD基本操作
-
基本步骤

-
示例
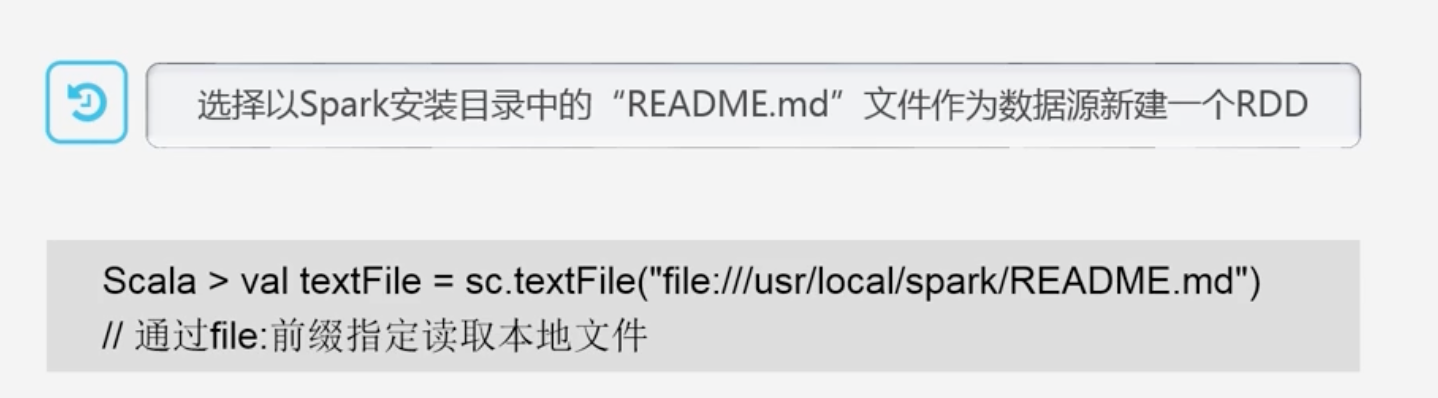
-
Spark RDD支持的两种类型操作
- 动作(action):在数据集上进行运算,返回计算值
- 转换(transformation):基于现有的数据集创建一个新的数据集
-
Spark常用API介绍
-
常用Action API:动作API得到的是一个结果,而不是RDD
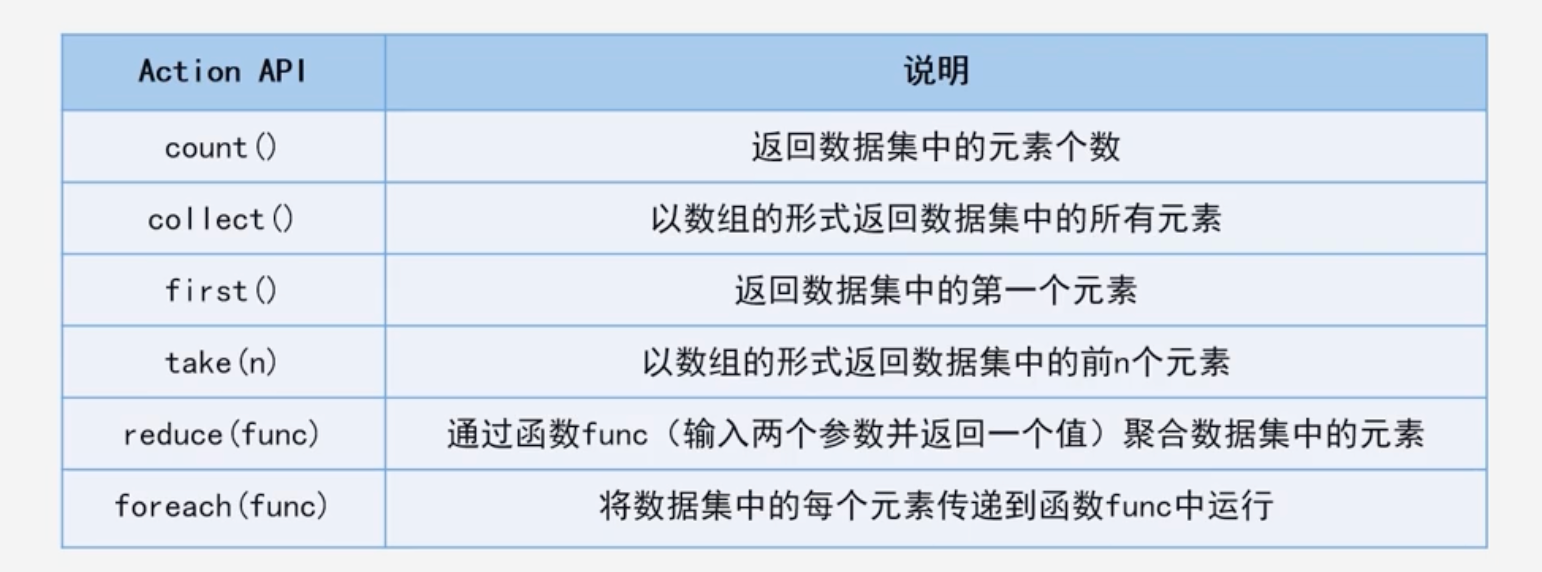
-
常用Transformation API介绍:转换API得到的是RDD的中间结果

-
常用API举例

-
API可以使用链式操作进行连续计算,可以让Spark代码更加简洁

-
Spark属于MapReduce计算模型,因此也可以实现MapReduce的计算过程

10.6.3 使用Maven编译打包Java程序
见:Spark安装和编程实践(Spark3.4.0)_厦大数据库实验室博客 (xmu.edu.cn)
10.6.4 使用sbt编译打包Scala程序
-