1、作用:
用于存在父子,祖孙,上下级等层级关系的数据表进行层级查询。
2、语法
SELECT ...
FROM ....
START WITH cond1
CONNECT BY cond2
WHERE cond3;
2.1、说明
start with: 指定起始节点的条件
connect by: 指定父子行的条件关系
prior: 查询父行的限定符,格式: prior column1 = column2 or column1 = prior column2 and … ,
nocycle: 若数据表中存在循环行,那么不添加此关键字会报错,添加关键字后,便不会报错,但循环的两行只会显示其中的第一条
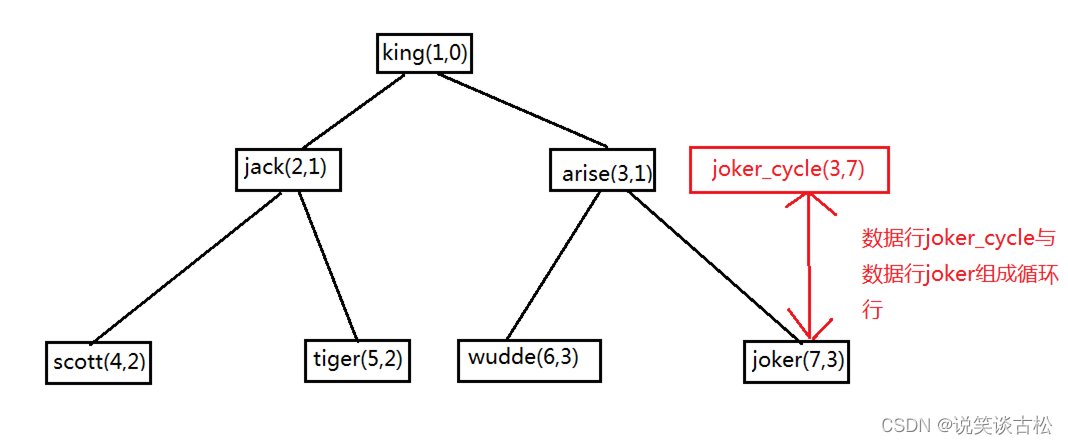
循环行: 该行只有一个子行,而且子行又是该行的祖先行
connect_by_iscycle: 前置条件:在使用了nocycle之后才能使用此关键字,用于表示是否是循环行,0表示否,1 表示是
connect_by_isleaf: 是否是叶子节点,0表示否,1 表示是
level: level伪列,表示层级,值越小层级越高,level=1为层级最高节点
3、构造数据
-- 创建表
create table employee(
emp_id number(18),
lead_id number(18),
emp_name varchar2(200),
salary number(10,2),
dept_no varchar2(8)
);
-- 添加数据
insert into employee values('1',0,'king','1000000.00','001');
insert into employee values('2',1,'jack','50500.00','002');
insert into employee values('3',1,'arise','60000.00','003');
insert into employee values('4',2,'scott','30000.00','002');
insert into employee values('5',2,'tiger','25000.00','002');
insert into employee values('6',3,'wudde','23000.00','003');
insert into employee values('7',3,'joker','21000.00','003');
4、查询jack下的所有子节点
select * from employee start with emp_name='jack' connect by prior emp_id=lead_id;
emp_id | lead_id | emp_name | salary | dept_no
--------+---------+----------+--------+---------
2 | 1 | jack | 50500 | 002
4 | 2 | scott | 30000 | 002
5 | 2 | tiger | 25000 | 002
(3 rows)
5、查询jack和arise下的所有子节点
select * from employee start with emp_name in ('jack', 'arise') connect by prior emp_id=lead_id;
emp_id | lead_id | emp_name | salary | dept_no
--------+---------+----------+--------+---------
2 | 1 | jack | 50500 | 002
4 | 2 | scott | 30000 | 002
5 | 2 | tiger | 25000 | 002
3 | 1 | arise | 60000 | 003
6 | 3 | wudde | 23000 | 003
7 | 3 | joker | 21000 | 003
(6 rows)
6、查询jack的祖先节点
select * from employee start with emp_name='jack' connect by prior lead_id=emp_id;
emp_id | lead_id | emp_name | salary | dept_no
--------+---------+----------+---------+---------
2 | 1 | jack | 50500 | 002
1 | 0 | king | 1000000 | 001
(2 rows)
7、查询一个节点的叔叔伯父节点
--查看emp_id为6的节点的叔叔伯父节点
with temp as (
select employee.*,
prior emp_name,
level le
from employee
start with lead_id = 0
connect by lead_id=prior emp_id
)
select *
from temp t
left join temp tt
on tt.emp_id=6 --此处需要限定
where t.le = (tt.le-1)
and t.emp_id not in (tt.lead_id);
emp_id | lead_id | emp_name | salary | dept_no | ?column? | le | emp_id | lead_id | emp_name | salary | dept_no | ?column? | le
--------+---------+----------+--------+---------+----------+----+--------+---------+----------+--------+---------+----------+----
2 | 1 | jack | 50500 | 002 | king | 2 | 6 | 3 | wudde | 23000 | 003 | arise | 3
(1 row)
8、查询族兄
--查看employee id是6的节点的族兄节点
with temp as (
select employee.*,
prior emp_name,
level le
from employee
start with lead_id=0
connect by lead_id= prior emp_id
)
select t.*
from temp t
left outer join temp tt
on tt.emp_id=6 --此处需要条件限制
where t.le=tt.le
and t.emp_id<>6; --此处需要条件限制
emp_id | lead_id | emp_name | salary | dept_no | ?column? | le
--------+---------+----------+--------+---------+----------+----
4 | 2 | scott | 30000 | 002 | jack | 3
5 | 2 | tiger | 25000 | 002 | jack | 3
7 | 3 | joker | 21000 | 003 | arise | 3
(3 rows)
9、level伪列的使用,格式化层级
select lpad(' ',level*2,' ')||emp_name as name,emp_id,lead_id,salary,level
from employee
start with lead_id=0
connect by prior emp_id=lead_id; -- level数值越低级别越高
name | emp_id | lead_id | salary | level
-------------+--------+---------+---------+-------
king | 1 | 0 | 1000000 | 1
jack | 2 | 1 | 50500 | 2
scott | 4 | 2 | 30000 | 3
tiger | 5 | 2 | 25000 | 3
arise | 3 | 1 | 60000 | 2
wudde | 6 | 3 | 23000 | 3
joker | 7 | 3 | 21000 | 3
(7 rows)
10、connect_by_root 查找根节点
select connect_by_root emp_name,emp_name,lead_id,salary
from employee
start with lead_id=1
connect by prior emp_id = lead_id;
connect_by_root | emp_name | lead_id | salary
-----------------+----------+---------+--------
jack | jack | 1 | 50500
jack | scott | 2 | 30000
jack | tiger | 2 | 25000
arise | arise | 1 | 60000
arise | wudde | 3 | 23000
arise | joker | 3 | 21000
(6 rows)
-- 注意: connect_by_root关键字后面跟着字段,表示根节点对应记录的某一字段的值,
-- 如 connect_by_root emp_name表示根节点的员工名,connect_by_root salary表示根节点的工资
11、connect_by_isleaf 是否是叶子节点
select emp_id,emp_name,lead_id,salary,connect_by_isleaf
from employee
start with lead_id=0
connect by nocycle prior emp_id=lead_id;
emp_id | emp_name | lead_id | salary | connect_by_isleaf
--------+----------+---------+---------+-------------------
1 | king | 0 | 1000000 | 0
2 | jack | 1 | 50500 | 0
4 | scott | 2 | 30000 | 1
5 | tiger | 2 | 25000 | 1
3 | arise | 1 | 60000 | 0
6 | wudde | 3 | 23000 | 1
7 | joker | 3 | 21000 | 1
(7 rows)
-- 叶节点指的是没有子节点的节点,那些是既是父节点又是子节点的节点不属于叶节点
12、使用connect by rownum生成序列
ROWNUM是一个伪列,即先查到结果集之后再加上去的一个列,它的取值从1开始排依次递增。ROWNUM其实是oracle数据库从数据文件或缓冲区中读取数据的顺序。取得第一条记录则rownum值为1,第二条为2,依次类推。
connect by rownum是通过递归迭代第一行生成一个序列。格式如下:
select ***
from dual
connect by rownum<=n;
举例:
12.1 生成1-5之间的一个序列
select rownum
from dual
connect by rownum<=5;
rownum
--------
1
2
3
4
5
(5 rows)
12.2 生成10个60到100之间的随机整数
select rownum No,ROUND(DBMS_RANDOM.VALUE(60,100),0) Value
from dual
connect by rownum<=10;
no | value
----+-------
1 | 77
2 | 64
3 | 67
4 | 86
5 | 82
6 | 77
7 | 94
8 | 89
9 | 61
10 | 93
(10 rows)
12.3 生成连续的日期值
select rownum No,sysdate+rownum MyDate
from dual
connect by rownum<=10;
no | mydate
----+---------------------
1 | 2023-10-12 15:45:39
2 | 2023-10-13 15:45:39
3 | 2023-10-14 15:45:39
4 | 2023-10-15 15:45:39
5 | 2023-10-16 15:45:39
6 | 2023-10-17 15:45:39
7 | 2023-10-18 15:45:39
8 | 2023-10-19 15:45:39
9 | 2023-10-20 15:45:39
10 | 2023-10-21 15:45:39
(10 rows)