一. 主从复制
1. 含义
在分布式系统中,为了解决单点问题,通常会把数据复制多个副本到其它机器,满足故障恢复和负载均衡等要求,Redis也是如此,提供了主从复制功能。(redis第一代架构)
实质:一个主服务器(master)对应多个从服务器(slave),主从之间实现数据同步,主服务器负责【写】,从服务器负责【读】,另外从服务器通常会配置只支持读,不支持写(replica‐read‐only yes)。
PS:主从复制是redis高可用的基础,后面的Sentinel和Cluster都是在主从复制的基础上进行升级实现高可用的。
如图:

2. 常用操作
(1). 建立主从复制
A. 在从节点在配置文件中加入 replicaof {masterHost} {masterPort},随redis启动生效。 【配置文件】
B. 在redis-server启动命令后加入 -slaveof {masterHost} {masterPort} 生效。 【指令】
C. 直接使用命令:slaveof {masterHost}{masterPort} 生效 【指令】
PS:查看复制信息 info replication
(2). 断开复制
从节点执行指令:slave of no one来断开与主节点复制关系。
A. 断开与主节点复制关系。
B. 从节点晋升为主节点。
PS:从节点断开复制后不会抛弃原有数据,只是无法在获取主节点的数据变化了。
(3). 切换主节点
从节点执行命令:slaveof {newMasterIp}{newMasterPort}命令即可
A.断开与旧主节点的复制关系。
B.与新主节点建立复制关系。
C.删除从节点当前所有数据。
D.对新主节点进行复制操作。
注:线上操作一定要小心,因为切主后会清空之前所有的数据。
分享主从的配置文件:
主服务器不需要做特别配置,正常启动即可,假设主服务器的地址为: 192.168.0.1:6379 ,下面分享从服务器的配置文件,然后正常启动即可。
# 实际上就两句话 replicaof 192.168.0.1 6379 # 从本机6379的redis实例复制数据 replica‐read‐only yes #配置从服务器只读
3. 主从复制的原理
详见:https://www.cnblogs.com/yaopengfei/p/13879077.html
4. 弊端分析
主从模式下,master主节点一旦发生故障,则不能提供服务,需要人工修改从节点的配置进行干预,将从节点晋升为主节点(主从架构不能没有选举功能!!),同时还需要修改客户端配置(redis链接地址改为原先从节点的地址),非常不友好。
基于此背景,Redis2.8发布了一个稳定版本Sentinel机制(Redis2.6最早推出Sentinel,但存在一些问题)
二.Sentinel 哨兵
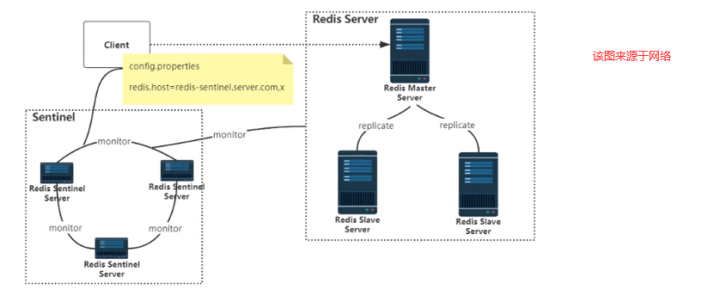
1. 含义
Sentinel架构解决redis主从架构人工干预的问题。
Sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息)
2. 运行原理
可以在一个架构中运行多个Sentinel进程,这些进程采用流言协议(gossip protocols)来接受关于主服务器是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行故障迁移,以及选择哪个从服务器作为新的主服务器。
Redis的Sentinel系统用于管理多个Redis实例(服务器),该系统执行以下三个任务:
(1). 监控
Sentinel会不断的定期检查你的主服务器和从服务器是否运作正常。
(2). 提醒
当被监控的某个Redis服务器出现问题的时候,Sentinel可以通过API向管理员或者其它应用程序发送通知。
(3).自动故障迁移
当一个主服务器不能正常工作的时候,Sentinel会开始一次自动故障迁移工作,它会将失效的主服务器的其中一个从服务器升级为新的主服务器,并让其它的从服务器改为复制新的主服务器;当客户端试图链接失效的的主服务器的时候,集群会向客户端返回新的主服务器的地址,使得集群可以适用新主服务器代替失效服务器。
总结:Redis Sentinel是一个分布式架构,其中包含N个Sentinel节点和N个Redis数据节点,每个Sentinel节点会对数据节点和其它的Sentinel节点进行监控,当发现节点不可用时,会对该节点做下线标识,如果被标识的是主节点,他还会和其它的Sentinel进行“协商”,当大多数节点都认为主节点不可用时候,会选举出来一个Sentinel节点来完成自动故障转移工作,同时会将这个变化实时通知给redis客户端,整个过程是自动的,不需要人工干预,有效的解决了redis高可用的问题。
如下图:
3. 代码配置
#1.复制一份sentinel.conf文件
cp sentinel.conf sentinel‐26379.conf
#2.将相关配置修改为如下值:
port 26379
daemonize yes
pidfile "/var/run/redis‐sentinel‐26379.pid"
logfile "26379.log"
dir "/usr/local/redis‐5.0.3/data"
# sentinel monitor <master‐name> <ip> <redis‐port> <quorum>
# quorum是一个数字,指明当有多少个sentinel认为一个master失效时(值一般为:sentinel总数/2 +1),master才算真正失效 (此处的ip和port都要对应redis的master的地址)
sentinel monitor mymaster 192.168.0.60 6379 2
#3.启动sentinel哨兵实例
src/redis‐sentinel sentinel‐26379.conf
#4.查看sentinel的info信息,可以看到Sentinel的info里已经识别出了redis的主从
src/redis‐cli ‐p 26379
info
#5.可以自己再配置两个sentinel,端口26380和26381,注意上述配置文件里的对应数字都要修改4. 分析
优势:
当主节点出现故障时,redis sentinel能自动完成故障发现和故障转移,并通知客户端从而实现真正的高可用。
设置多个Sentinel节点的好处:①对节点的故障判断是由多个节点完成的,可以有效的防止误判。 ② 多个Sentinel节点,即使出现了个别节点不可用,也不会影响客户端的访问。
弊端:
(1). 配置相对复杂。
(2). 虽然解决了第一代中主挂全挂的问题,但所有的写压力都在一个master上,且宕机的时候,slave顶上去的这个切换期间,整个服务停止,从而影响项目的正常运行。而且就一个master,单个节点的极限并发也就10万左右了。
从而引出Redis第三代架构,Redis Cluster,多个master节点,且无中心节点,可以尽情的横向扩展。
5. 哨兵leader选举流程
当一个master服务器被某sentinel视为客观下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进行故障转移工作。每个发现master服务器进入客观下线的sentinel都可以要求其他sentinel选自己为sentinel的leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。
哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。
不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似。
更多C++后台开发技术点知识内容包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,流媒体,音视频开发,Linux内核,TCP/IP,协程,DPDK多个高级知识点。
C/C++Linux服务器开发高级架构师/C++后台开发架构师免费学习地址
【文章福利】另外还整理一些C++后台开发架构师 相关学习资料,面试题,教学视频,以及学习路线图,免费分享有需要的可以点击领取
三. Redis Cluster
1. 前言
在Redis Cluster出现之前,业界普遍使用的Redis多实例集群的方式主要是以下两类方案:
(1). 客户端分片方案
A. 哈希取模:hash(key)% N,hash代表一种散列算法,N代表redis服务器的数量。这种算法实现起来非常简单,但是缺点也是非常明显的,当服务器数量N增加或者减少的时候,原先的缓存数据定位几乎失效,缓存数据定位失效意味着要到数据库重新查询,这对于高并发的系统来说是致命的。
B. 一致性哈希算法:将key和server都进行hash,分配在闭环上,采用临近原则,key 找 离它最近的server节点进行存储。 详细参考:https://blog.csdn.net/maihilton/article/details/81979361
剖析:客户端分片的方案,优点是分区逻辑可控;缺点是需要自己处理数据路由、高可用、故障转移等,而且即使采用一致性哈希算法,还是会存在少量key匹配不到丢失的情况,需要做键值的迁移。
客户端分区 和 服务端分区对比:
客户端sharding技术其优势在于服务端的Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。其不足之处在于:
由于sharding处理放到客户端,规模进步扩大时给运维带来挑战。 服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。连接不能共享,当应用规模增大时,资源浪费制约优化。
服务端sharding的Redis Cluster其优势在于服务端Redis集群拓扑结构变化时,客户端不需要感知,客户端像使用单Redis服务器一样使用Redis集群,运维管理也比较方便。
(2). 代理方案
使用代理中间件:twemproxy
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。该方案很好的解决了单个Redis实例承载能力的问题。当然,Twemproxy本身也是单点,需要用Keepalived做高可用方案。通过Twemproxy可以使用多台服务器来水平扩张redis服务,可以有效的避免单点故障问题。虽然使用Twemproxy需要更多的硬件资源和在redis性能有一定的损失(twitter测试约20%),但是能够提高整个系统的HA也是相当划算的。不熟悉twemproxy的同学,如果玩过nginx反向代理或者mysql proxy,那么你肯定也懂twemproxy了。其实twemproxy不光实现了redis协议,还实现了memcached协议,什么意思?换句话说,twemproxy不光可以代理redis,还可以代理memcached。
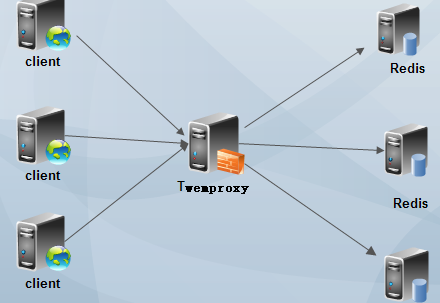
参考:https://www.cnblogs.com/gomysql/p/4413922.html
https://www.cnblogs.com/kuncy/p/9903482.html
2. Redis Cluster介绍
该模式是由多个主从节点群组成的分布式服务集群,它具有复制、高可用和分片特性。Redis Cluster不需要Sentinel-哨兵也能完成节点移除和故障转移工作。需要将每个节点设置成集群模式,这种集群没有中心节点,可水平扩展,根据官方文档成可以线性扩展到1000个节点,redis集群的性能和高可用性均优于之前的哨兵模式,且集群的配置非常简单。
如图:
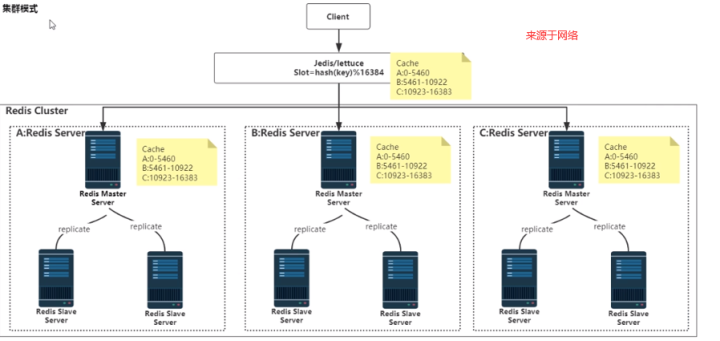
剖析:
多个master平行节点,分摊了写的压力,且无论是master还是slave水平都可以扩展很多。
但也有弊端,假设1个master和下面的slave全部挂掉,那么分配在该master节点中的槽位对应的key将失效,无法获取,新的请求进来,经过 crc16(key) % 16384 计算,如果slot在这个挂掉的master上,则写入操作也无法进行。(此处的演示详见cluster搭建章节 https://www.cnblogs.com/yaopengfei/p/13856347.html)
3. Redis Cluster通信流程
总结一句话:集群中的每个节点都会单独开辟一个Tcp通道,用于节点之间通信,通信端口为:原基础端口+10000,比如redis的端口为6379,那么他的通信端口就是16379。
(1). 在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据指:节点负责哪些数据,是否出现故障灯状态信息,redis集群采用Gossip(流言)协议,Gossip协议工作原理就是节点彼此不断交换信息,一段时间后,所有的节点都会知道集群的完整信息,类似流言传播。
通信过程如下:
A. 集群中的每个节点都会单独开辟一个Tcp通道,用于节点之间通信,通信端口为:原基础端口+10000,比如redis的端口为6379,那么他的通信端口就是16379
B. 每个节点在固定周期内通过特定规则选择结构节点发送ping消息
C. 接收到ping消息的节点用pong消息作为响应。集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只有这些节点彼此可以正常通信,最终才会达成一致的状态,当节点出现故障,新节点介入,主角色变化等,它能够不断的ping/pong消息,从而达到同步的目的。
(2). Gossip协议详解
Gossip协议的职责就是信息交换,信息交换的载体就是节点之间彼此发送的Gossip消息。常见的Gossip消息分为:ping pong meet fail等
A. meet消息:用于通知新节点的加入,消息发送者通知接收者加入当前集群,mmet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong信息交换。
B. ping消息:集群内部交换最频繁的消息,集群内每个节点每秒都向多个其它节点发送ping消息,用于检测节点是否在线和彼此交换信息。
C. pong消息:当接收到ping、meet消息时,作为响应消息回复给发送发确认消息可以正常通信,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新。
D. fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其它节点收到fail消息猴,把对应节点更新为下线状态。
如下图:

4. Redis Cluster路由机制
(1). Moved重定向
A. 普通连接
如果指令在这个node上,则处理指令;如果不在这个node上,则redis会返回给客户端MOVED重定向错误,通知客户端重新请求正确的node,这个过程称为MOVED重定向。
重定向信息中包含了key, slot,node的地址,根据这些信息,客户端就可以去请求正确的node,流程图如下:
./redis-cli -h 192.168.137.201 -p 6380 -a 123456
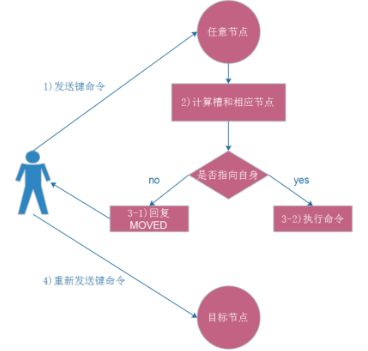
测试:在已经搭建好的redis cluster下,6379、6380、6381是master节点,下面通过普通连接(没有-c),连接到6380端口上,进行数据的写入命令,

(2).集群的模式连接
在使用redis-cli时,可以加入 -c 参数,支持自动重定向,简化手动发起重定向的操作,这里redis-cli自动帮我们连接到了正确的node, 这个过程是redis-cli内部维护的,他先收到了MOVED信息,然后向新node发起请求。
./redis-cli -c -h 192.168.137.201 -p 6380 -a 123456
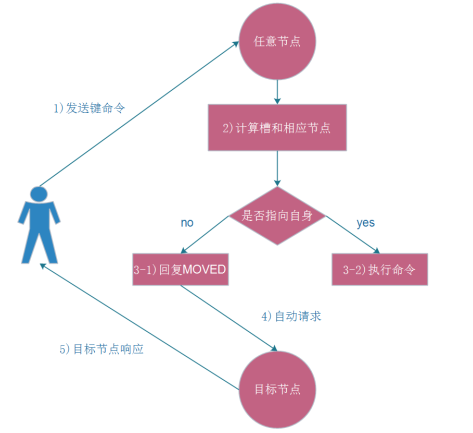
测试:在已经搭建好的redis cluster下,6379、6380、6381是master节点,下面通过集群的连接方式,连接到6380端口上,进行数据的写入命令,

(2). ASK重定向
redis cluster除了moved重定向,还有ask重定向。ask重定向代表的状态比较特别,它是当slot处于迁移状态时才会发生。例如:一个slot存在三个key,分别为k1、k2、k3,假设此时slot正在处于迁移状态,k1已经迁移到了目标节点,此时如果在源节点获取k1,则会报出ask重定向错误。
5. Redis Cluster 分片机制
在Redis Cluster中,Redis 为了更好的分配存储数据,引入槽位的概念(slot),Redis Cluster共有16384个槽位,在创建集群的时候,这些槽位会平均分给每个master节点,当key进来的时候,会对key进行一定处理,计算出slot值,然后分配到该值对应16384个slot中的某个slot所在的redis的master节点上,这里采用的hash算法为:CRC16(key) % 16384,这就是Redis Cluster的分片机制。
如图:

注意:分片机制是一种Redis服务端的路由规则,是为了解决Redis分布式部署下Key的分配存储位置问题,为了分摊高并发下写的压力,并不是1个槽位只能存1个key,槽位与能存储Key的个数没有任何关系,Redis Cluster是一种服务器端分片的技术。
测试:已经搭建好redis cluster,6379 6380 6381是三个master节点,6382 6383 6384 分别是三个master对应slave节点。
(1). 查看slots分配情况

(2). 查看写入数据时候的跳转机制,自动匹配对应的槽位,进行写操作

(3). 连接从节点,获取数据,还是会重定向到主节点进行获取。

注:redis cluster中的slave节点上没有slot槽位,不对外提供服务,只是为了备份数据,当master宕机的时候,slave会顶替上去成为master节点,即使客户端访问从节点(读或写),redis内部也会重定向到主节点。
6. 集群选举原理分析
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
(1). slave发现自己的master变为FAIL
(2). 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
(3). 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
(4). 尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
(5). slave收到超过半数master的ack后变成新Master (这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)
(6). 广播Pong消息通知其他集群节点。
补充:
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票
•延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK:表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。
7. 灵魂拷问
(1). 网络抖动的解决方案?
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项cluster-node-timeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
(2). 集群是否完整才能对外提供服务 ?
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
(3). Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
原文链接:第五节:Redis架构演变之主从、Sentinel哨兵、Cluster(通信、分片、路由等机制) - Yaopengfei - 博客园











![[Java实战]Squaretest单元测试生成利器...一天生成所有简单单元测试...[新手开箱可用]](https://img-blog.csdnimg.cn/63768885cc8343d18794a954a6c61892.png)