论文:Segment Anything
代码:https://github.com/facebookresearch/segment-anything
上一篇:【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Image Encoder
本篇示例依然采用上一篇的狗狗图像运行代码,预测部分代码如下:
input_point = np.array([[1300, 800]]) # 输入point的坐标
input_label = np.array([1]) # label=1表示前景, label=0表示背景
# 输入box的坐标,(700,400)为左上角坐标, (1900,1100)为右下角坐标
input_box = np.array([[700, 400, 1900, 1100]])
# 调用预测函数
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box,
multimask_output=True,
)
1. Mask预测过程
(1)predict函数
位置:【segment_anything/predictor.py --> SamPredictor类 -->predict函数】
作用: 使用给定的prompt,调用predict_torch,预测mask与iou
def predict(
self,
point_coords: Optional[np.ndarray] = None,
point_labels: Optional[np.ndarray] = None,
box: Optional[np.ndarray] = None,
mask_input: Optional[np.ndarray] = None,
multimask_output: bool = True,
return_logits: bool = False,
) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
if not self.is_image_set:
raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")
# Transform input prompts
coords_torch, labels_torch, box_torch, mask_input_torch = None, None, None, None
# 若prompt为point
if point_coords is not None:
assert (
point_labels is not None
), "point_labels must be supplied if point_coords is supplied."
# 原始point_coords:[x,y]给定的坐标点=(1300,800)
# self.original_size原始图像大小=(1365,2048)
# 由于图像缩放为1024, 给定坐标应随之变换, 变换后point_coords:[X,Y]=(650, 400.29)
point_coords = self.transform.apply_coords(point_coords, self.original_size)
# 将变换后的坐标[650, 400.29]以及前景与背景的标签转化为tensor
coords_torch = torch.as_tensor(point_coords, dtype=torch.float, device=self.device)
labels_torch = torch.as_tensor(point_labels, dtype=torch.int, device=self.device)
# 加一个维度使得coords_torch.size():[1,1,2], labels_torch.size():[1,1]
coords_torch, labels_torch = coords_torch[None, :, :], labels_torch[None, :]
# 若prompt为box
if box is not None:
# 同样对box坐标进行变换, (700, 400, 1900, 1100)->(350, 200.1465, 950, 500.4029)
box = self.transform.apply_boxes(box, self.original_size)
# 转换为tensor, box_torch.size():[1,4]
box_torch = torch.as_tensor(box, dtype=torch.float, device=self.device)
box_torch = box_torch[None, :] # 加一个维度使得box_torch.size():[1,1,4]
# 若prompt为mask
if mask_input is not None:
mask_input_torch = torch.as_tensor(mask_input, dtype=torch.float, device=self.device)
mask_input_torch = mask_input_torch[None, :, :, :]
# masks.size():[1,3,1365,2048], iou_predictions.size():[1,3], low_res_masks.size():[1,3,256,256]
masks, iou_predictions, low_res_masks = self.predict_torch(
coords_torch,
labels_torch,
box_torch,
mask_input_torch,
multimask_output,
return_logits=return_logits,
)
masks_np = masks[0].detach().cpu().numpy()
iou_predictions_np = iou_predictions[0].detach().cpu().numpy()
low_res_masks_np = low_res_masks[0].detach().cpu().numpy()
return masks_np, iou_predictions_np, low_res_masks_np
apply_coords函数: 对输入point进行坐标变换,将图像 [ H , W ] {[H, W]} [H,W]给定坐标位置 [ x , y ] {[x, y]} [x,y],映射到变换图像 [ H ∗ 1024 / W , 1024 ] {[H*1024/W, 1024]} [H∗1024/W,1024]上的位置 [ X , Y ] {[X, Y]} [X,Y]
def apply_coords(self, coords: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
old_h, old_w = original_size # [H, W]
new_h, new_w = self.get_preprocess_shape(
original_size[0], original_size[1], self.target_length
) # [H*1024/W, 1024]
coords = deepcopy(coords).astype(float) # 输入坐标[x, y]
# 将给定坐标位置[x, y]映射到变换图像[H*1024/W, 1024]上的位置[X, Y]
coords[..., 0] = coords[..., 0] * (new_w / old_w)
coords[..., 1] = coords[..., 1] * (new_h / old_h)
return coords
apply_boxes函数: 调用 apply_coords函数进行box的坐标变换
def apply_boxes(self, boxes: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
boxes = self.apply_coords(boxes.reshape(-1, 2, 2), original_size)
return boxes.reshape(-1, 4)
(2)predict_torch函数
位置:【segment_anything/predictor.py --> SamPredictor类 -->predict_torch函数】
作用: 调用prompt_encoder实现prompt嵌入编码,调用mask_decoder实现mask预测
def predict_torch(
self,
point_coords: Optional[torch.Tensor],
point_labels: Optional[torch.Tensor],
boxes: Optional[torch.Tensor] = None,
mask_input: Optional[torch.Tensor] = None,
multimask_output: bool = True,
return_logits: bool = False,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
if not self.is_image_set:
raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")
if point_coords is not None:
points = (point_coords, point_labels)
else:
points = None
# Embed prompts
sparse_embeddings, dense_embeddings = self.model.prompt_encoder(
points=points,
boxes=boxes,
masks=mask_input,
) # sparse_embeddings.size():[1,2,256], dense_embeddings.size():[1,256,64,64]
# Predict masks
low_res_masks, iou_predictions = self.model.mask_decoder(
image_embeddings=self.features,
image_pe=self.model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
# Upscale the masks to the original image resolution
masks = self.model.postprocess_masks(low_res_masks, self.input_size, self.original_size)
if not return_logits:
masks = masks > self.model.mask_threshold
return masks, iou_predictions, low_res_masks
2. Prompt Encoder代码解析
(1)PromptEncoder类
位置:【segment_anything/modeling/prompt_encoder.py -->PromptEncoder类】
作用: 实现prompt输入嵌入编码
先看PromptEncoder的 _ _ i n i t _ _ {\_\_init\_\_} __init__ 初始化函数和 f o r w a r d {forward} forward 函数:
class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
super().__init__()
self.embed_dim = embed_dim # 嵌入维度256
self.input_image_size = input_image_size # 输入图像大小[1024, 1024]
# 图像嵌入大小[64, 64] image_encoder编码器输出为[1,256,64,64]
self.image_embedding_size = image_embedding_size
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2) # embed_dim // 2 = 128
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners 有4个点
# 4个点的嵌入向量 point_embeddings为4个Embedding(1, 256)
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
self.point_embeddings = nn.ModuleList(point_embeddings) # 4个点的嵌入向量添加到网络
self.not_a_point_embed = nn.Embedding(1, embed_dim) # 不是点的嵌入向量
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1]) # mask输入尺寸(256, 256)
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2), # 四倍下采样
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1), # 最后通道也是256
)
self.no_mask_embed = nn.Embedding(1, embed_dim) # 没有mask时的嵌入向量
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
bs = self._get_batch_size(points, boxes, masks) # batch size = 1
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device()) # 空tensor
# ------------sparse_embeddings-----------
if points is not None:
coords, labels = points # coords=(650, 400.29), labels=1表示前景
# 坐标点[X, Y]嵌入, point_embeddings.size():[1, 2, 256]
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None)) # 没有输入框的时候pad=True
# sparse_embeddings.size():[1, 2, 256]
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
# ------------sparse_embeddings-----------
# ------------dense_embeddings------------
if masks is not None:
dense_embeddings = self._embed_masks(masks) # 有mask采用mask嵌入向量
else:
# 没有mask输入时采用 nn.Embedding 预定义嵌入向量
# [1,256]->[1,256,1,1]->[1, 256, 64, 64]
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
) # dense_embeddings.size():[1, 256, 64, 64]
# ------------dense_embeddings------------
return sparse_embeddings, dense_embeddings
传送门:torch.nn.Embedding函数用法图解
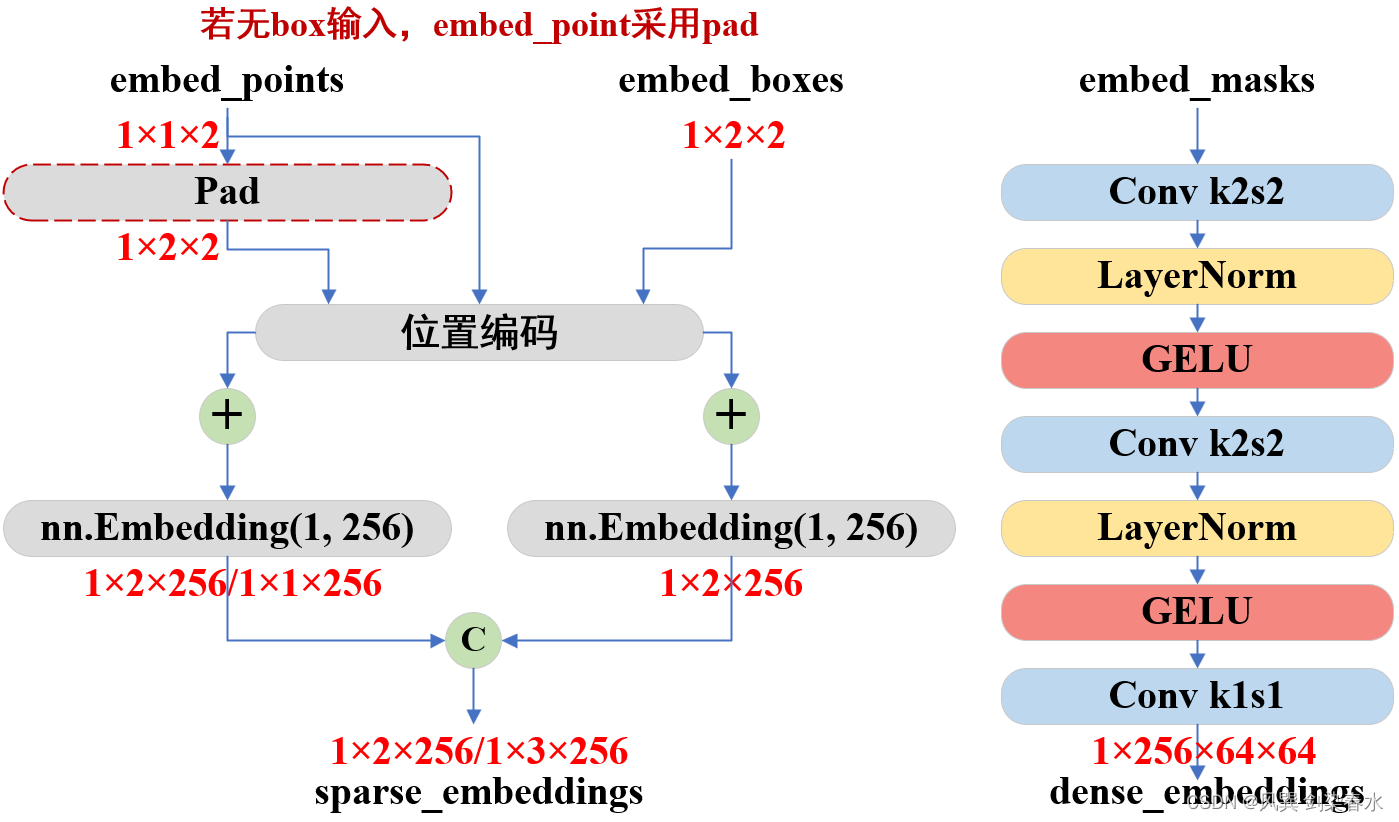
f o r w a r d {forward} forward 的过程中主要完成了sparse_embeddings(由point和box嵌入向量组成)和dense_embeddings(由mask嵌入向量组成)两种向量嵌入。
① _embed_points函数:输入的坐标点 [ x , y ] {[x, y]} [x,y]= ( 1300 , 800 ) {(1300, 800)} (1300,800) 经过映射变换后为 [ X , Y ] {[X, Y]} [X,Y]= ( 650 , 400.29 ) {(650, 400.29)} (650,400.29), ( 650 , 400.29 ) {(650, 400.29)} (650,400.29)由 s e l f . _ e m b e d _ p o i n t s {self.\_embed\_points} self._embed_points 函数完成嵌入:
def _embed_points(
self,
points: torch.Tensor, # [[[650, 400.29]]]
labels: torch.Tensor, # [[1]]
pad: bool, # false
) -> torch.Tensor:
points = points + 0.5 # Shift to center of pixel 移到像素中心=(650.5, 400.79)
# 当没有box输入时, pad=ture
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device) # size():[1,1,2]
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device) # 是负数,size():[1,1]
points = torch.cat([points, padding_point], dim=1) # [1, 2, 2]
labels = torch.cat([labels, padding_label], dim=1) # [1, 2]
# self.pe_layer = PositionEmbeddingRandom(embed_dim // 2) = PositionEmbeddingRandom(128)
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size) # 点嵌入[1,2,256]
# -------------------------------------------------------------------------------------
# self.point_embeddings中预设四个点的可学习嵌入向量,分别为前景点,背景点,box的左上角和右下角坐标点
# -------------------------------------------------------------------------------------
# 当labels=-1, 输入点是非标记点, 设为非标记点, 加上非标记点权重
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
# 当labels=0, 输入点是背景点, 加上背景点权重
point_embedding[labels == 0] += self.point_embeddings[0].weight
# 当labels=1, 输入点是目标点, 加上目标点权重
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
② _embed_boxes函数:box的左上角与右下角点 ( 700 , 400 , 1900 , 1100 ) {(700, 400, 1900, 1100)} (700,400,1900,1100)经过映射变换后为 ( 350 , 200.1465 , 950 , 500.4029 ) {(350, 200.1465, 950, 500.4029)} (350,200.1465,950,500.4029),由 s e l f . _ e m b e d _ b o x e s {self.\_embed\_boxes} self._embed_boxes 函数完成嵌入:
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
# (350, 200.1465, 950, 500.4029)->(350.5000, 200.6465, 950.5000, 550.9030)
boxes = boxes + 0.5 # Shift to center of pixel size()=[1,1,4]
coords = boxes.reshape(-1, 2, 2) # [1,1,4]->[1,2,2]
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size) # [1,2,256]
# 目标框起始点的和末位点分别加上权重
corner_embedding[:, 0, :] += self.point_embeddings[2].weight # 左上角点
corner_embedding[:, 1, :] += self.point_embeddings[3].weight # 右下角点
return corner_embedding
③_embed_masks函数:若有mask输入,由 s e l f . _ e m b e d _ m a s k s {self.\_embed\_masks} self._embed_masks 函数完成嵌入:
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
self.mask_downscaling结构:
(mask_downscaling): Sequential(
(0): Conv2d(1, 4, kernel_size=(2, 2), stride=(2, 2))
(1): LayerNorm2d()
(2): GELU(approximate='none')
(3): Conv2d(4, 16, kernel_size=(2, 2), stride=(2, 2))
(4): LayerNorm2d()
(5): GELU(approximate='none')
(6): Conv2d(16, 256, kernel_size=(1, 1), stride=(1, 1))
)
结束了么,家人们!是不是在疑惑,还有最后一步了(ง •_•)ง,在 _embed_points函数 和 _embed_boxes函数 中均调用了随机位置嵌入PositionEmbeddingRandom类,以进行point的位置编码。可以理解为,每一个point的向量嵌入都由point的位置编码和可学习nn.Embedding预设权重相加组成。
(2)PositionEmbeddingRandom类
位置:【segment_anything/modeling/prompt_encoder.py -->PositionEmbeddingRandom类】
作用: 调用forward_with_coords将point归一化到[0,1],调用_pe_encoding完成位置编码
class PositionEmbeddingRandom(nn.Module):
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().__init__()
if scale is None or scale <= 0.0:
scale = 1.0
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)), # 生成随机数, 满足标准正态分布
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
# coords: [X/1024, Y/1024]=(0.6353, 0.3914)
# 映射至[-1,1],适应三角函数. coords=(0.2705, -0.2172) size():[1,1,2]
coords = 2 * coords - 1
# self.positional_encoding_gaussian_matrix是随机生成的: [2, 128]
coords = coords @ self.positional_encoding_gaussian_matrix # 矩阵乘法[1, 1, 128] / [64, 64, 128]
coords = 2 * np.pi * coords # 2*Π*R [1, 1, 128]
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1) # [1, 1, 256] / [64, 64, 256]
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size # 64, 64
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones((h, w), device=device, dtype=torch.float32) # [64, 64]的全1矩阵
y_embed = grid.cumsum(dim=0) - 0.5 # [64, 64] 列逐累加
x_embed = grid.cumsum(dim=1) - 0.5 # [64, 64] 行逐累加
y_embed = y_embed / h
x_embed = x_embed / w
# torch.stack([x_embed, y_embed], dim=-1)->size(): [64, 64, 2]
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1)) # [64, 64, 256]
return pe.permute(2, 0, 1) # C x H x W [256, 64, 64]
def forward_with_coords(
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
) -> torch.Tensor:
"""Positionally encode points that are not normalized to [0,1]."""
coords = coords_input.clone() # [X+0.5, Y+0.5]=(650.5, 400.79)
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
# 除以1024,归一化到[0,1]->[X/1024, Y/1024]=(0.6353, 0.3914)
return self._pe_encoding(coords.to(torch.float)) # B x N x C
奇怪的是,PositionEmbeddingRandom类自身的forward似乎并没有用上,也不知道干啥滴哩~
3. Prompt Encoder结构绘制
(1)结构打印
PromptEncoder(
(pe_layer): PositionEmbeddingRandom()
(point_embeddings): ModuleList(
(0-3): 4 x Embedding(1, 256)
)
(not_a_point_embed): Embedding(1, 256)
(mask_downscaling): Sequential(
(0): Conv2d(1, 4, kernel_size=(2, 2), stride=(2, 2))
(1): LayerNorm2d()
(2): GELU(approximate='none')
(3): Conv2d(4, 16, kernel_size=(2, 2), stride=(2, 2))
(4): LayerNorm2d()
(5): GELU(approximate='none')
(6): Conv2d(16, 256, kernel_size=(1, 1), stride=(1, 1))
)
(no_mask_embed): Embedding(1, 256)
)
(2)结构绘制











![[安洵杯 2019]easy_web - RCE(关键字绕过)+md5强碰撞+逆向思维](https://img-blog.csdnimg.cn/d0ff84da22ea4f94aed095be3ef40e27.png)