👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🔥 进步or毁灭:Nature 调研显示 1600+ 科学家对AI的割裂态度

国际顶级期刊 Nature 最近一项调研很有意思,全球 1600 多名科研人员对AI工具的态度非常「割裂」:部分认为AI对科研帮助颇多,另一部分人则充满深深的忧虑;部分人的日常工作已经离不开AI,有些则完全不使用。这其实也是社会公众对AI工具的观点缩影。
例如,AI带来的积极影响被广泛认可,比如更快地处理数据、加速海量计算能力、节约时间和经费;但是负面影响也让科研人员们警惕,比如导致了依赖模式识别而不是深刻理解、在数据中强化偏见或歧视、增加欺诈概率、研究无法重现等等。更多组的数据分析可以前往 ⋙ 阅读原文

🏆 PICO 2023 首届 XR 开发者挑战赛

https://www.picoxr.com/cn/2023picodevjam
PICO 2023 首届 XR 开发者大赛,是 PICO 公司举办的内容生态开发者大赛,通过比赛形式以促进 PICO MR/VR 内容生态繁荣,以及拉动更多开发者关注 MR/VR 领域。
本次比赛面向消费者&行业,提供了开发工具、指导、投资机会、面试直通、获奖激励等多方位的支持。以下是比赛关键时间节点,感兴趣可以前往主页了解更多信息:
9月25日:系统开放报名
10月2日:作品提报开启
11月10日:作品提报截止
11月13日-30日:评委评选
12月5日:颁奖仪式

🧩 LLM for GamePlay:LLM 大模型驱动玩法设计的福与祸

这是一位AI游戏一线研发者的半年度总结,从技术应用的角度拆解了 LLM for gameplay 课题,是一篇非常真实朴素的行业实践分享,有很多金句和闪光的观点。
从最初的兴奋或无限遐想,到现在感受到的骨感现实,「屠龙刀并不一定合适所有的舞台」逐步成为行业新共识。以下是文章核心观点,推荐读一读原文,所有行业的发展都会经历这样U型转弯的过程:
LLM 是万能的映射,而非万能的生成:LLM 并不能带来无限的游戏表现力,除文本外它依旧几乎完全依赖于资产开发本身
LLM 尝试理解一切,但游戏无法包含一切:只有当游戏内状态的复杂度到一定规模,且能比较自然地转译 (encode) 成语义表达,LLM 的屠龙技才算是有用武之地
LLM 正在努力变得万能,但游戏不一定需要万能:LLM 的映射能力也有侧重点,可量化的最优化问题也许其他AI技术会是更合理的选型

作者还分享了一个系统架构图,来讨论 LLM 如何用于构建角色和赋能场景:
Humanity:建模角色的人格、思维过程、情绪认知等脑内信息和过程
Speaker:建模角色的对话行为,也包括角色的心理活动、剧情旁白等文字表现
Evolver:角色对外界的行为决策及其具体执行 (action),和对应结果的结算 (resolving) ⋙ 阅读原文

👀 大模型有能力打穿「智能音箱/硬件」的市场壁垒么?

2023年上半年,国内智能音箱市场由小度、小米和天猫精灵三强鼎立,并先后宣布接入大模型。正当智能音箱又一轮激烈竞争来临之际,百度系却临阵换帅,景鲲辞职创业为这个「AGI产品必争之地」的战争再添变数。
为什么智能音箱是 AGI 产品路线图上的兵家必争之地?大模型能撑起来智能硬件这个巨大的想象空间么?我们距离智能印象打穿应用壁垒还有多长时间? 这篇文章给出了详细的解释和预判 ⋙ 阅读原文

👩💻 出海注册经验分享,搞定英国公司、Wise银行账号、苹果开发者和Stripe

这是一篇即刻上的经验分享贴,作者 @Junping1 全程在国内搞注册好了英国公司、Wise银行账号,Stripe和苹果开发者,并分享了非常详细的操作攻略。总体来说,操作成本不高、流程也不复杂,总共花费不到两千人民币,用时两三周。
扫码即可前往星球查看全部分享内容,以及操作建议帖的链接,也可以前往作者账号评论区互动 ⋙ 即刻@Junping1

📚 如何使用 LoRA 微调 Llama 2

这是一篇技术分享贴,讨论了使用LoRA 对大语言模型 Llama 2进行微调的过程,以及微调的好处。以下是文章要点,可以定位感兴趣的内容并前往阅读原文:
为什么微调:大语言模型微调后可以减少幻觉,使模型适应于特定的用例,并去除不希望的行为或者或添加希望的行为
微调与提示工程:微调比提示工程的成本更低,因为在硬件加速方面没有前期成本,还可以在微调过程中将更多数据适应到模型
大语言模型微调策略:已经提出了几种用于微调大语言模型的方法,其中之一就是 LoRA
使用LoRA微调大语言模型:LoRA 的工作原理是冻结语言模型的权重,并在变压器层中引入新的矩阵,从而减少了可训练参数的数量,并使得在较少的GPU计算下进行微调成为可能
LoRA的好处:通过交换 LoRA 权重,可以使用同一模型进行不同的任务,从而减少了存储不同模型所需的存储空间;并且只有LoRA矩阵正在优化,因此能训练得更快 ⋙ 阅读原文

📋 通过 LLMs 实现需求的背后逻辑
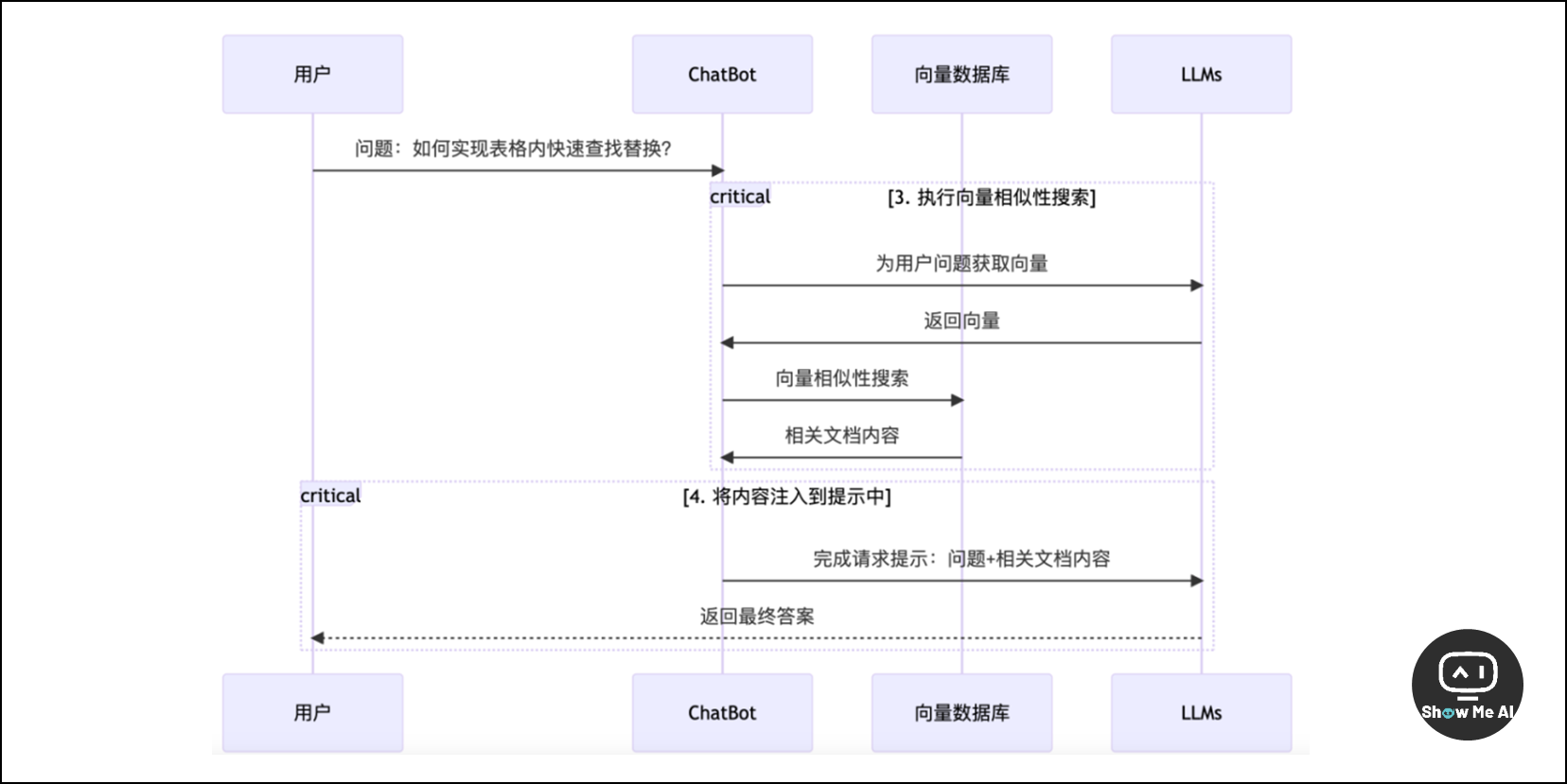
这篇文章以「通过 LangChain 实现文档问答机器人」示例,清楚地说了使用 AI 构建一个应用背后的逻辑。不同于一般的实战教程分享,这篇内容对于我们思考和设计AI产品会非常有帮助。
当然作者并没有回避技术方向的信息,如果感兴趣可以跟随作者提供的链接前往了解更多代码、框架等内容。以下是文章的关键知识点,可以阅读全文查看作者更详细的解释:
LangChain是基于大语言模型的应用框架,降低了开发成本,减少了单一模型对产品的风险
使用LangChain可以实现文档问答机器人,包括数据清洗、向量存储和LLMs的优化
向量是降低AI使用费用的工具,常用的向量数据库有Pincone、Redis、Chroma、PostgreSQL等
微调是让GPT模型更好理解特定领域内容的技术,需要大量训练文本,训练文本越多,微调的价格越高
OpenAI的API更新新增了函数调用功能,让GPT根据用户问题匹配函数并准备入参,降低了应用构建的成本 ⋙ 阅读原文

📺 昇思 MindSpore技术公开课第二期,大模型专题即将开始

https://xihe.mindspore.cn/course/foundation-model-v2/introduction
昇思MindSpore技术公开课大模型专题第二期课程来了!自10月14日起,每双周六14:00-15:30在B站 @MindSpore官方 账号直播开课。本期课程紧跟「大模型」技术热点,并且手把手教你构建大模型,讲师团也非常强大。

这是课程安排,有感兴趣的话题,可以在官网报名,当然可以关注 ShowMeAI 社区通知,记得一起来听课:
[课前学习] MindSpore Transformers大模型套件:架构讲解与使用入门:介绍 MindSpore Transformers 大模型套件现状,讲解套件架构及高阶接口设计,走读工程架构模块代码,学习基本使用方式
ChatGLM:介绍技术公开课整体课程安排;ChatGLM模型结构,走读代码演示ChatGLM推理部署
多模态遥感智能解译基础模型:介绍多模态遥感智能解译基础模型的原理、训推等相关技术,以及模型相关行业应用
ChatGLM2:介绍ChatGLM2模型结构,走读代码演示ChatGLM推理部署
文本生成解码原理:介绍Beam search和采样的原理及代码实现
LLAMA:介绍LLAMA模型结构,走读代码演示推理部署,介绍Alpaca
LLAMA2:介绍LLAMA2模型结构,走读代码演示LLAMA2 chat部署
CPM:介绍CPM-Bee预训练、推理、微调及代码现场演示
高效参数微调:介绍Lora、(P-Tuning)原理及代码实现
量化:介绍低比特量化等相关模型量化技术
框架LangChain模块解析:解析Models、Prompts、Memory、Chains、Agents、Indexes、Callbacks模块,及案例分析
LangChain对话机器人综合案例:MindSpore Transformers本地模型与LangChain框架组合使用,通过LangChain框架管理向量库并基于向量库对MindSpore Transformers本地模型问答进行优化 ⋙ 了解更多
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!