1.数据库的三范式是什么?
答:
第一范式(1NF)
强调的是列的原子性,即列不能够再分成其他几列。
第二范式(2NF)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第三范式(3NF)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
2.维度建模当中星型模型和雪花模型的对比?
星型模型:冗余度高,设计简单,可读性高,关联的维度表少,查询效率高,可扩展性低。
雪花模型:去除了冗余,设计复杂,可读性差,关联的维度表多,查询效率低,但是可扩展性好。
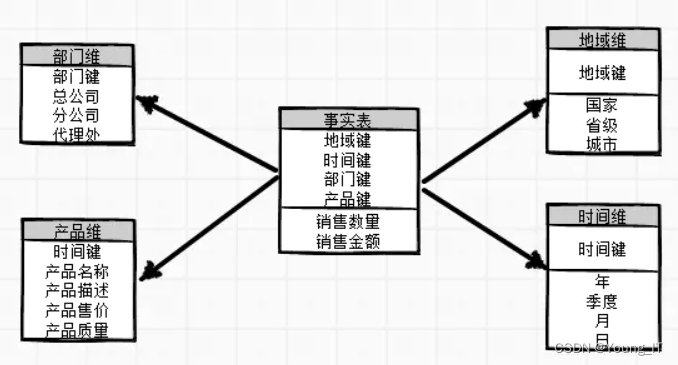
一、星型模型
星型模型:当所有的维度表都是和事实表直接相连的时候,整个图形看上去就像是一个星星,我们称之为星型模型。星型模型是一种非正规化的架构,因为多维数据集的每一个维度都和事实表直接相连,不存在渐变维度,所以有一定的数据冗余,因为有数据的冗余,很多的统计情况下,不需要和外表关联进行查询和数据分析,因此效率相对较高。
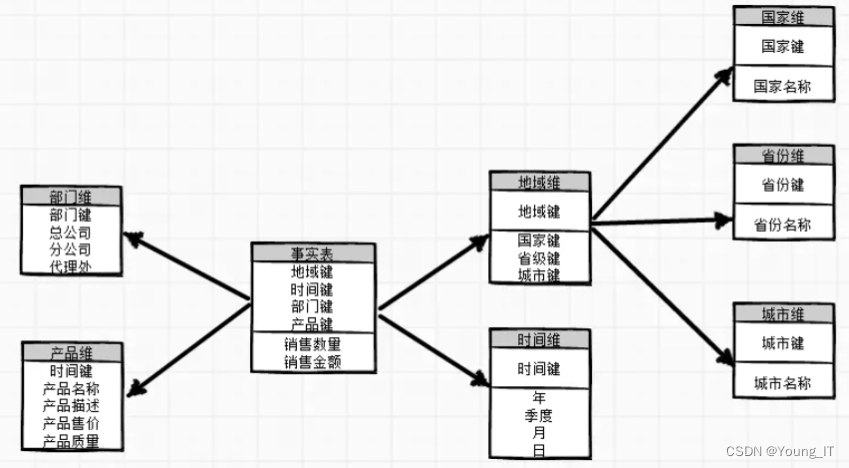
二、雪花模型
雪花模型:当有多个维度表没有直接和事实表相连,而是通过其它的维度表,间接的连接在事实表上,其图形就像是一个雪花,因此我们称之为雪花模型,雪花模型的优点是减少了数据冗余,在进行数据统计或分析的时候,需要和其他的表进行关联。
三、区别
星型模型和雪花模型最根本的区别就是,维度表是直接连接到事实表还是其他的维度表。
1)星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花模型要高。
2)星型模型不用考虑很多正规化的因素,设计和实现都比较简单。
3)雪花模型由于去除了冗余,有些统计就需要通过表的连接才能产生,所以效率不一定有星型模型高。
4)正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
3.维度建模的具体实现?
4.范式建模和维度建模的对比?
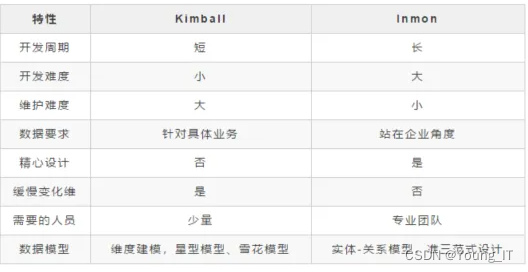
范式建模:通过上一小节的具体例子可以看出范式建模的优点:能够结合业务系统的数据模型,较方便的实现数据仓库的模型;同一份数据只存放在一个地方,没有数据冗余,保证了数据一致性;数据解耦,方便维护。但同时也带来了缺点:表的数量多;查询时关联表较多使得查询性能降低。
维度建模:模型结构简单,面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计,开发周期短,能够快速迭代。缺点就是数据会大量冗余,预处理阶段开销大,后期维护麻烦;还有一个问题就是不能保证数据口径一致性,原因后面有讲解。
我们再来理解下维度建模:数据会抽取为事实-维度模型,维度就是看待问题的角度,从不同的角度看待某个问题,就会得出不同的结论,而要得到这个结论,就需要事实表中的度量,何为度量,就是事实表中数值类型的字段。
例:某公司的各个商品在全国各地市的销售情况,维度就是全国的城市和各个商品,度量就是商品的单价,从不同的维度计算销售额:如查看北京市酸奶的销售额,上海市纯牛奶的销售额,这就是不同的维度组合方式。在限定的维度条件上,计算商品单价的总和,也就是 sum 度量值,即可得到我们想要的结果。
5.数仓构建流程?
可见:数仓构建过程 - 知乎
6.数仓分层方式及各层作用?

具体见文章:一种通用的数据仓库分层方法
【数仓系列】数仓分层的意义价值及如何设计数据分层-CSDN博客
详解数仓中的数据分层:ODS、DWD、DWM、DWS、ADS - 掘金