文章目录
- 概念
- 常见的索引
- 1.B树索引
- 2.哈希索引
- 3.全文索引
- 4.空间索引
- 5.聚集索引
- 如何设计合理?
- 1.明确索引需求
- 2.选择索引列
- 3.选择索引类型
- 4.考虑索引维护开销
- 5.设计联合索引
- 6.删除不必要索引
- 7.关注索引统计信息
- 8.测试查询效果
- 常见不生效场景
- 1.全表扫描
- 2.索引列计算
- 3.模糊查询未用前置匹配
- 4.复合索引条件次序错误
- 5.or条件索引无效
- 6.子查询或关联查询inner side未用索引
- 7.数据分布严重不均匀
- 8.返回未命中索引覆盖字段
- 9.索引统计信息没有及时更新
- 总结
- 写在最后

概念
索引是数据库管理系统中一个重要的优化结构,目的是提高数据库查询和操作的速度。
索引的工作原理是对数据库表中的一列或多列的值进行预排序,然后存储该列值与数据行的地址映射,在查询时可以直接查找到数据,而无需全表扫描。
常见的索引
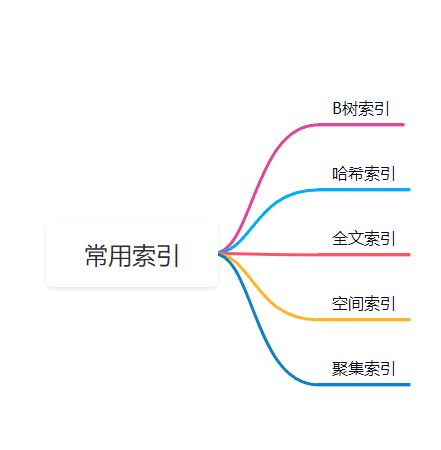
1.B树索引
最常见的索引类型,可以对一个或多个列创建索引。
2.哈希索引
通过哈希函数直接定位到数据行。查找速度极快,但只支持等值查询。
3.全文索引
可以对文本中的关键词创建索引,支持模糊查询。
4.空间索引
用于空间数据类型的索引,可以优化空间计算。
5.聚集索引
索引结构和数据结构相结合,只能有一个聚集索引。
如何设计合理?
1.明确索引需求
分析查询语句和业务场景,确定需要创建索引的列,以优化查询性能。
2.选择索引列
选择区分度高、查询频繁的列作为索引列。避免冗余和相关列的索引。
3.选择索引类型
根据查询方式选择合适的索引类型,如B树索引、哈希索引、全文索引等。
4.考虑索引维护开销
写入操作会增加索引维护开销。权衡查询优化与维护成本。
5.设计联合索引
多个列的联合索引可以覆盖更多查询,但要注意索引列顺序。
6.删除不必要索引
清理冗余和未使用的索引,减少维护损耗。
7.关注索引统计信息
分析索引的使用情况,优化设计。
8.测试查询效果
不同场景测试索引设计的查询性能,验证索引有效性。
常见不生效场景
1.全表扫描
SQL语句中没有对索引列进行过滤条件限定,导致全表扫描,索引不生效。
下面是一个全表扫描导致索引失效的例子:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
KEY idx_age (age)
);
SELECT * FROM users WHERE name = 'John';
上面创建了users表,并在age列上创建了索引idx_age。但在查询时,条件是name列,而没有使用索引列age进行限定,这会导致全表扫描,idx_age索引不会生效。如果查询改为:
SELECT * FROM users WHERE age = 30 AND name = 'John';
先用索引列age进行过滤,再联合name一起查找,这样可以利用到idx_age索引,避免全表扫描,提高查询效率。
2.索引列计算
对索引列进行算数运算、函数转换、类型转换等,结果索引不再生效。
下面是一个索引列计算导致索引失效的例子:
CREATE TABLE users (
id INT PRIMARY KEY,
age INT,
KEY idx_age (age)
);
SELECT * FROM users WHERE age + 3 = 33;
上面在age列上创建了索引idx_age。但查询条件中对age进行了计算,将age+3进行比较。这导致索引idx_age无法起到作用。因为计算后age的值已经改变,无法直接用于索引查找。改写为不计算age的形式:
SELECT * FROM users WHERE age = 30;
直接比较age的值,这样可以充分利用idx_age索引,避免表扫描,提高查询效率。
3.模糊查询未用前置匹配
like语句的模糊匹配没有用%放在查询条件后面,索引的优势无法利用。
下面是一个模糊查询未用前置匹配导致索引失效的例子:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
KEY idx_name (name)
);
SELECT * FROM users WHERE name LIKE '%John';
上面在name列上创建了索引idx_name。但模糊查询中,使用了%John方式,没有指明前置匹配。这种情况下,idx_name索引很难发挥作用,执行会变成全表扫描。改为使用前置匹配的形式:
SELECT * FROM users WHERE name LIKE 'John%';
指明 name 以John开头的条件,这样可以利用索引idx_name进行前置匹配优化,避免全表扫描。
4.复合索引条件次序错误
复合索引的条件没有按索引建立的顺序使用,导致部分索引无法生效。
下面是一个复合索引条件次序错误导致部分索引失效的示例:
CREATE TABLE users (
id INT PRIMARY KEY,
last_name VARCHAR(50),
first_name VARCHAR(50),
KEY idx_name (last_name, first_name)
);
SELECT * FROM users WHERE first_name = 'John' AND last_name = 'Smith';
上面在last_name和first_name上创建了复合索引idx_name。但是查询条件的顺序是first_name在前,last_name在后。这与索引次序相反,导致索引只能生效于first_name条件,但无法生效于last_name条件。如果调整查询为:
SELECT * FROM users WHERE last_name = 'Smith' AND first_name = 'John';
保持与索引次序一致,那么idx_name索引可以完全生效,避免表扫描,提高查询效率。
5.or条件索引无效
or条件使得索引无法正确限定范围,无法利用索引进行筛选。
or条件导致索引失效的示例如下:
CREATE TABLE users (
id INT PRIMARY KEY,
age INT,
name VARCHAR(50),
KEY idx_age (age),
KEY idx_name (name)
);
SELECT * FROM users WHERE age = 30 OR name = 'John';
上面在age和name列上分别创建了单列索引。但是查询条件使用了or进行连接,这导致索引无法正确限定范围进行过滤。因为age=30的记录和name='John’的记录可能是两组没有交集的记录。使用or时就需要扫描更大范围,索引效率下降。可以改写为:
SELECT * FROM users WHERE age = 30
UNION
SELECT * FROM users WHERE name = 'John';
将or拆分为两个查询语句,每个查询只有一个条件,可以独立利用原有的索引,避免全表扫描。所以or条件往往会导致合理利用不到索引,需要特别注意。
6.子查询或关联查询inner side未用索引
子查询或关联查询的内层查询没有用到合的索引。
一个子查询或者关联查询inner side未使用索引导致外层索引失效的示例如下:
SELECT * FROM users
WHERE id IN (
SELECT user_id FROM orders WHERE order_date = '2020-01-01'
);
外层查询在users表上根据id进行了索引查询。但是子查询orders表的查询没有使用索引,会全表扫描orders表来做IN查询。这会导致外层users表的id索引无效。可以这样修改:
SELECT * FROM users
WHERE id IN (
SELECT user_id FROM orders
WHERE order_date = '2020-01-01'
INDEX (order_date)
);
在子查询orders表查询中,添加order_date列的索引,这样子查询可以利用索引进行筛选。外层的id索引也随之生效,避免全表扫描users表。所以要注意嵌套查询的内层查询也要注意索引的使用,否则容易导致外层索引失效。
7.数据分布严重不均匀
当索引列数据分布严重不均匀时,比如大量重复数据,索引效率会下降。
数据分布不均匀导致索引失效的一个典型例子如下:
CREATE TABLE users (
id INT PRIMARY KEY,
gender CHAR(1) DEFAULT 'm',
KEY idx_gender (gender)
);
INSERT INTO users(id) VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10);
上面在gender列创建了索引idx_gender。但是数据插入时,gender列都是默认值’m’,分布完全不均匀。此时如果查询:
SELECT * FROM users WHERE gender = 'm';
索引idx_gender实际上无法生效,因为几乎全表数据都匹配条件。会走全表扫描,而无法利用到索引的优点。这种数据分布极不均匀的情况下,对应的索引效果会大打折扣。要避免这种情况,应该在创建索引时注意对应数据的分布情况,对已存在索引的表也要定期分析数据分布,避免索引失效。
8.返回未命中索引覆盖字段
查询需要返回的字段没有完全被复合索引覆盖。
一个复合索引覆盖字段未命中导致索引失效的示例如下:
CREATE TABLE users (
id INT PRIMARY KEY,
last_name VARCHAR(50),
first_name VARCHAR(50),
age INT,
KEY idx_name_age (last_name, first_name, age)
);
SELECT id, last_name FROM users WHERE last_name='Smith';
这里在last_name,first_name和age上创建了复合索引idx_name_age。查询语句的where条件可以利用这个复合索引。但是SELECT返回的字段id和last_name不完全被idx_name_age索引覆盖。这种情况下,查询还是需要回表去寻找id字段的数据,idx_name_age索引就未能完全生效。解决方法是创建覆盖需要返回的所有字段的索引:
CREATE INDEX idx_name_id ON users (last_name, first_name, id);
或者将查询需要的所有字段都放入复合索引中。所以复合索引的字段覆盖也需要注意,否则索引的利用效率会大打折扣。
9.索引统计信息没有及时更新
导致查询优化器误判查询成本,选择了非最优索引。
示例如下:
CREATE TABLE users (
id INT PRIMARY KEY,
age INT,
phone VARCHAR(15),
KEY idx_age(age),
KEY idx_phone(phone)
);
INSERT INTO users VALUES
(1, 35, '13800000000'),
(2, 40, '13800000001'),
(3, 25, '13800000002');
ANALYZE TABLE users; -- 统计信息默认采样扫描表
EXPLAIN SELECT * FROM users WHERE age = 40;
开始我们对users表做analyze,收集表的统计信息,包括索引的基数估算等。但analyze默认就是对表做抽样扫描,如果表数据发生大量变更,索引统计信息就会失效。explain显示的结果可能是based on idx_phone, 而不是最优的idx_age索引。这就导致了选择错误索引的问题。解决方法是及时收集更新统计信息:
ANALYZE TABLE users UPDATE INDEXES;
或者在重要SQL语句前强制绑定使用的索引:
SELECT * FROM users FORCE INDEX(idx_age) WHERE age = 40;
所以及时更新统计信息和合理使用optimizer hints都可以避免这类问题。
总结
了解索引的机制和原理,合理设置索引,可以使查询效率大大提升,从而提升后端的运行效率
写在最后
感谢您的支持和鼓励! 😊🙏
如果大家对相关文章感兴趣,可以关注公众号"架构殿堂",会持续更新AIGC,java基础面试题, netty, spring boot, spring cloud等系列文章,一系列干货随时送达!