前言
说起网络爬虫,很多人第一时间想到python,但爬虫并非只能用python实现,虽然网上大部分爬虫文章都在说python爬虫,但对于前端程序员来说,我觉得js才是最屌的(对于简单爬取任务来说,复杂的我暂时没碰到~),下面说说我的经验(是的,仅限本人经验),希望能给各位前端程序员带来一点新视角。
前置条件
- 熟悉常用的js bom dom api
- 会用chrome devtool
什么是爬虫
简单点,字面意思,爬虫就是用来爬取数据(文本、图片、视频等等)的代码脚本;
在第一次听爬虫的时候,感觉这个词碉堡了,学会了一定很酷!这也是我以前入坑python的主要原因。但搜索下科普文章/百科等等,还是有点云里雾里的感觉。其实我觉得了解一个概念从实际的需求出发更加容易理解,毕竟概念是人造的,没有概念前呢?下面根据真实事件改编:
需求一:获取豆瓣评分电影Top250的详细信息
需要获取以下表头信息,并存到本地/数据库/…
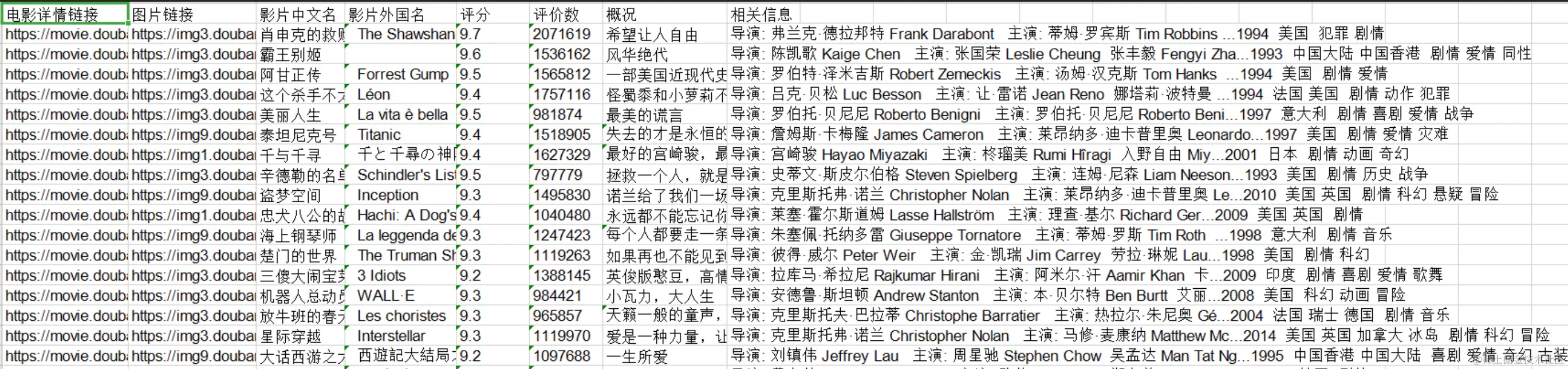 先不说怎么做到,但只要你用代码实现了这个需求,那你就是写了一个爬虫。
先不说怎么做到,但只要你用代码实现了这个需求,那你就是写了一个爬虫。
js爬虫思路实践
从哪里开始呢?首先,你要爬数据,就得先有目标,一般目标是一个网页,网页上有你想要的数据,一般网页数据多的时候都会分页请求数据,那必然就有规律!
1. 分析页面请求,找到数据来源,分析接口规律
简单分析下第一页/第二页接口请求,发现数据是以下接口返回的:
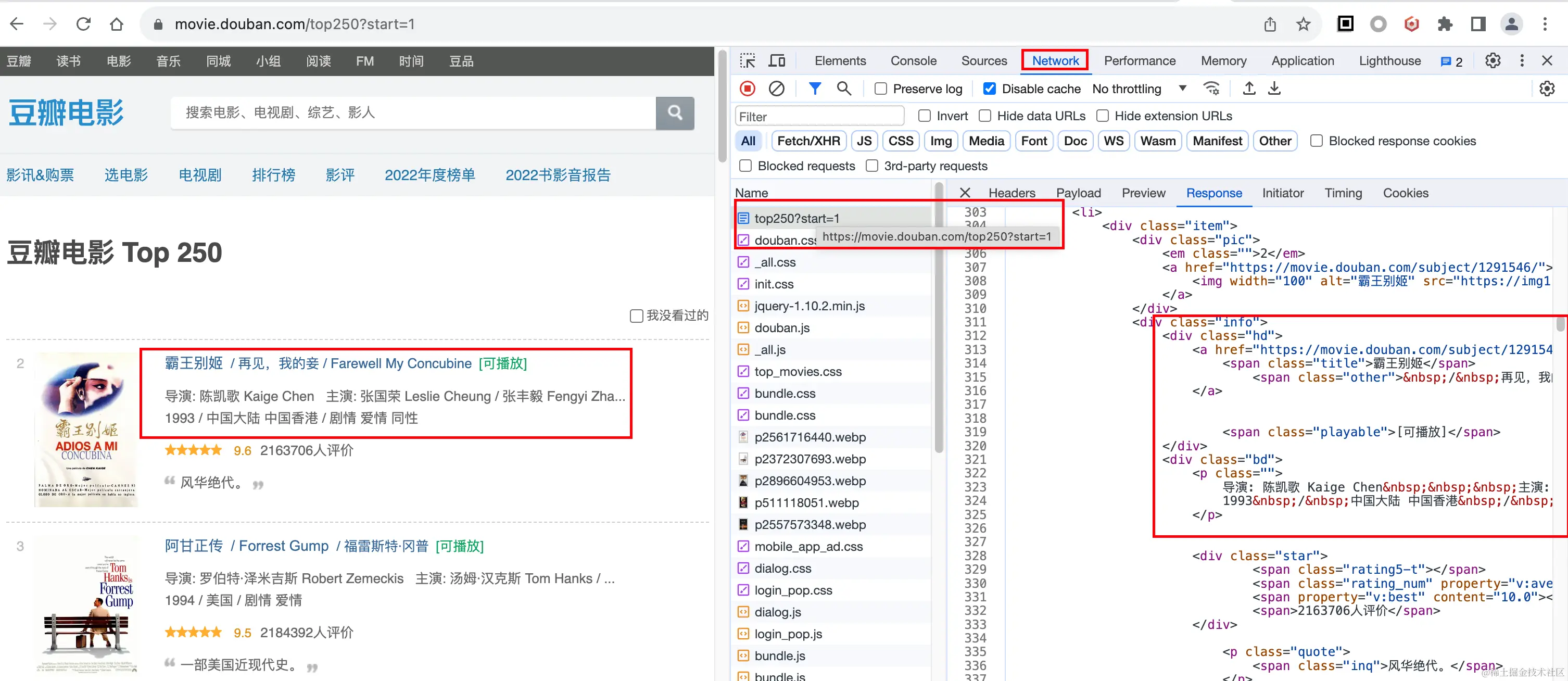
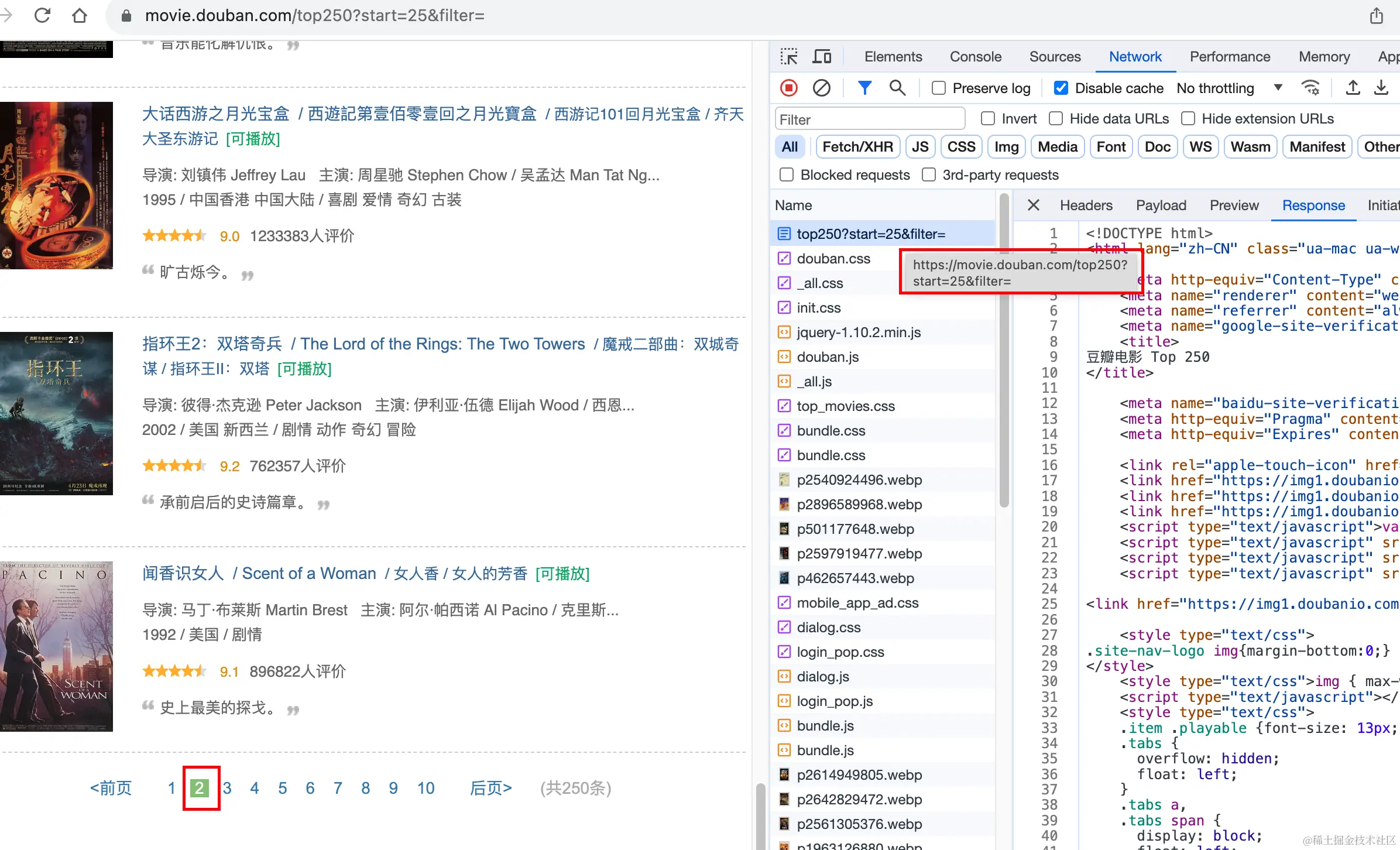
- 第一页接口路径:movie.douban.com/top250?star…
- 第二页接口路径:movie.douban.com/top250?star…
依此类推,第几页只是start参数不一样
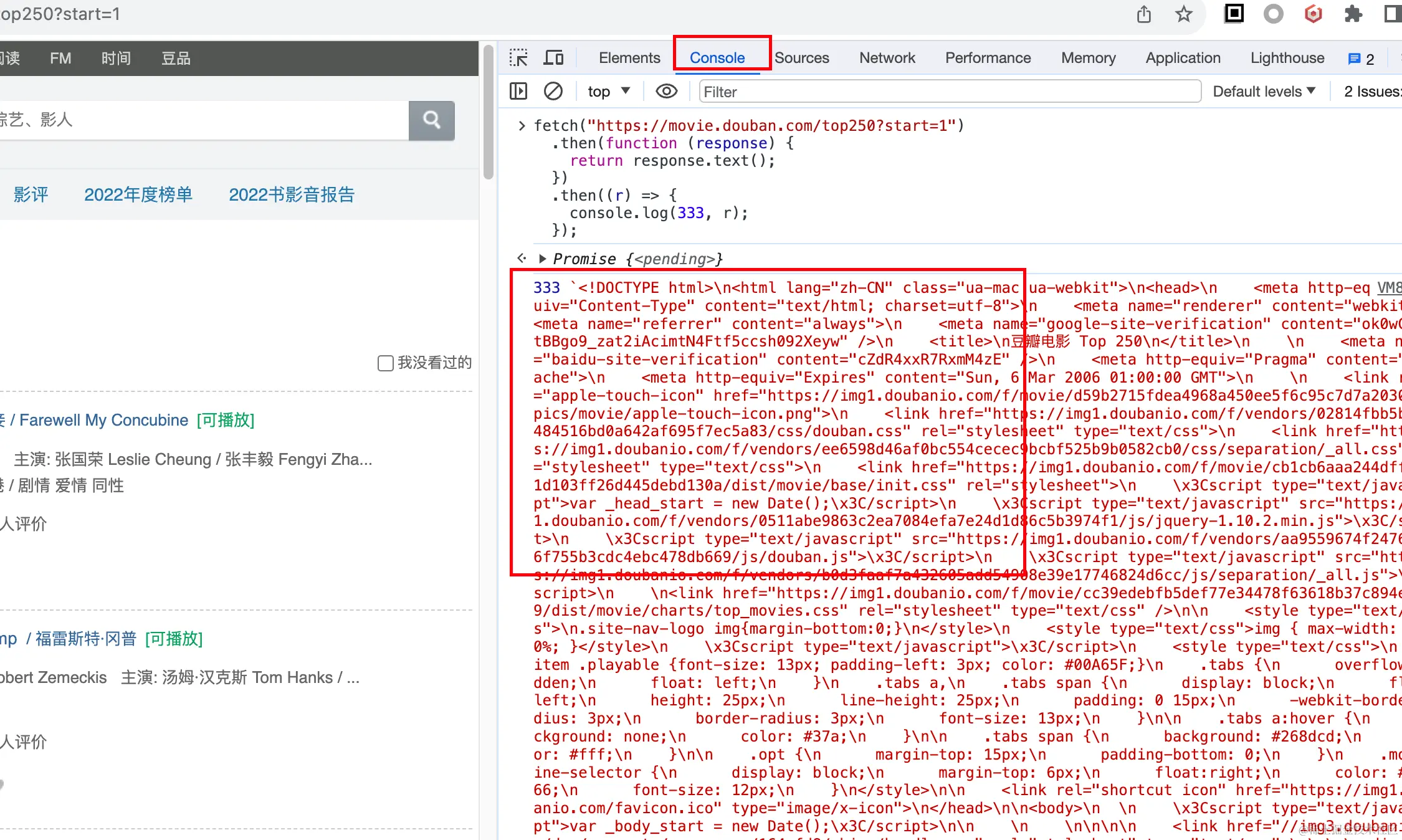
2. 用代码模拟获取接口数据
代码模拟获取接口数据?那不就是调接口吗,这我熟,于是axios/fetch一顿撸,如下:
fetch("https://movie.douban.com/top250?start=1")
.then(function (response) {
return response.text();
})
.then((r) => {
console.log(333, r);
});
放到console下跑下,数据不就拿到了!
3. 过滤处理提取数据
返回json数据还好处理,但这返回的是一个html文档啊,怎么过滤获取我们想要的数据呢?我们换个思路,对于处理html文档,dom api再合适不过了,但怎么用document对象方法呢,用iframe!
const iframe = document.createElement("iframe");
iframe.onload = () => {
console
![2023年中国自动化微生物样本处理系统竞争现状及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/8a992190ec65e1fdaf8ba53927d8de0f.png)



![2023年中国医学影像信息系统市场规模、竞争格局及行业趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/9f501667599b3c205a2af1891e2b6b00.png)
![[读博随笔] 系统安全和论文写作的那些事——不忘初心,江湖再见](https://img-blog.csdnimg.cn/5e583568830047c7a9c42db1ed0a4f3c.png#pic_center)
