一、说明
TensorFlow 2发布已经接近5年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。3大设计原则:简化概念,海纳百川,构建生态.这是本系列的第三部分,我们将创建代价函数并在 TensorFlow 2 中使用它们。
二、关于代价函数
神经网络学习将训练数据中的一组输入映射到一组输出。它通过使用某种形式的优化算法来实现这一点,例如梯度下降、随机梯度下降、AdaGrad、AdaDelta 或一些最近的算法,例如 Adam、Nadam 或 RMSProp。梯度下降中的“梯度”指的是误差梯度。每次迭代后,网络都会将其预测输出与实际输出进行比较,然后计算“误差”。通常,对于神经网络,我们寻求最小化错误。因此,用于最小化误差的目标函数通常称为成本函数或损失函数,并且由“损失函数”计算的值简称为“损失”。各种问题中使用的典型损失函数 –
A。均方误差
b. 均方对数误差
C。二元交叉熵
d. 分类交叉熵
e. 稀疏分类交叉熵
在Tensorflow中,这些损失函数已经包含在内,我们可以如下所示调用它们。
1 损失函数作为字符串
model.compile(损失='binary_crossentropy',优化器='adam',指标=['准确性'])
或者,
2. 损失函数作为对象
从tensorflow.keras.losses导入mean_squared_error
model.compile(损失=mean_squared_error,优化器='sgd')
将损失函数作为对象调用的优点是我们可以在损失函数旁边传递参数,例如阈值。
从tensorflow.keras.losses导入mean_squared_error
model.compile(损失=均方误差(参数=值),优化器='sgd')
三、使用函数创建自定义损失:
为了使用函数创建损失,我们需要首先命名损失函数,它将接受两个参数,y_true(真实标签/输出)和y_pred(预测标签/输出)。
def loss_function(y_true, y_pred):
***一些计算***
回波损耗
四、创建均方根误差损失 (RMSE):
损失函数名称 — my_rmse
目的是返回目标 (y_true) 和预测 (y_pred) 之间的均方根误差。
RMSE 公式:
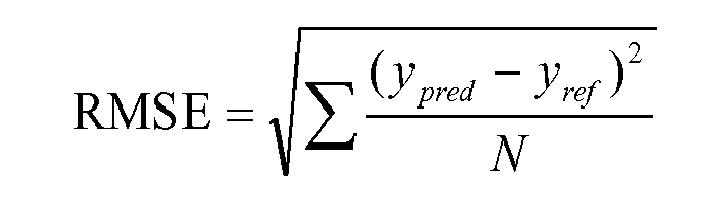
- 误差:真实标签和预测标签之间的差异。
- sqr_error:误差的平方。
- mean_sqr_error:误差平方的平均值
- sqrt_mean_sqr_error:误差平方均值的平方根(均方根误差)。
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import backend as K
#defining the loss function
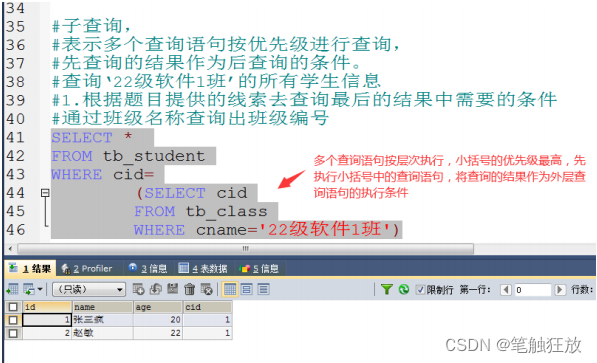
def my_rmse(y_true, y_pred):
#difference between true label and predicted label
error = y_true-y_pred
#square of the error
sqr_error = K.square(error)
#mean of the square of the error
mean_sqr_error = K.mean(sqr_error)
#square root of the mean of the square of the error
sqrt_mean_sqr_error = K.sqrt(mean_sqr_error)
#return the error
return sqrt_mean_sqr_error
#applying the loss function
model.compile (optimizer = 'sgd', loss = my_rmse)五、创建 Huber 损失

Huber损失的公式:
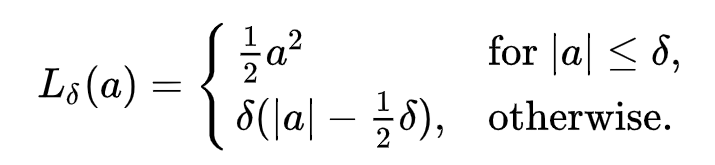
这里,
δ是阈值,
a是误差(我们将计算 a ,标签和预测之间的差异)
所以,当|a| ≤δ,损失= 1/2*(a)²
当|a|>δ 时,损失 = δ(|a| — (1/2)*δ)
代码:
# creating the Conv-Batch Norm block
def conv_bn(x, filters, kernel_size, strides=1):
x = Conv2D(filters=filters,
kernel_size = kernel_size,
strides=strides,
padding = 'same',
use_bias = False)(x)
x = BatchNormalization()(x)
return x解释:
首先我们定义一个函数 - my huber loss,它接受 y_true 和 y_pred
接下来我们设置阈值 = 1。
接下来我们计算误差 a = y_true-y_pred
接下来我们检查误差的绝对值是否小于或等于阈值。is_small_error返回一个布尔值(True 或 False)。
我们知道,当|a| ≤δ,loss = 1/2*(a)²,因此我们将small_error_loss计算为误差的平方除以2 。
否则,当|a| >δ,则损失等于 δ(|a| — (1/2)*δ)。我们在big_error_loss中计算这一点。
最后,在return语句中,我们首先检查is_small_error是true还是false,如果是true,函数返回small_error_loss,否则返回big_error_loss。这是使用 tf.where 完成的。
然后我们可以使用下面的代码编译模型,
model.compile(optimizer='sgd', loss=my_huber_loss)在前面的代码中,我们始终使用阈值1。
但是,如果我们想要调整超参数(阈值)并在编译期间添加新的阈值,该怎么办?然后我们必须使用函数包装,即将损失函数包装在另一个外部函数周围。我们需要一个包装函数,因为默认情况下任何损失函数只能接受 y_true 和 y_pred 值,并且我们不能向原始损失函数添加任何其他参数。
5.1 使用包装函数的 Huber 损失
包装函数代码如下所示:
import tensorflow as tf
#wrapper function which accepts the threshold parameter
def my_huber_loss_with_threshold(threshold):
def my_huber_loss(y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) <= threshold
small_error_loss = tf.square(error) / 2
big_error_loss = threshold * (tf.abs(error) - (0.5 * threshold))
return tf.where(is_small_error, small_error_loss, big_error_loss)
return my_huber_loss在这种情况下,阈值不是硬编码的。相反,我们可以在模型编译期间通过阈值。
model.compile(optimizer='sgd', loss=my_huber_loss_with_threshold(threshold=1.5))5.2 使用类的 Huber 损失 (OOP)
import tensorflow as tf
from tensorflow.keras.losses import Loss
class MyHuberLoss(Loss): #inherit parent class
#class attribute
threshold = 1
#initialize instance attributes
def __init__(self, threshold):
super().__init__()
self.threshold = threshold
#compute loss
def call(self, y_true, y_pred):
error = y_true - y_pred
is_small_error = tf.abs(error) <= self.threshold
small_error_loss = tf.square(error) / 2
big_error_loss = self.threshold * (tf.abs(error) - (0.5 * self.threshold))
return tf.where(is_small_error, small_error_loss, big_error_loss)MyHuberLoss是类名。在类名之后,我们从tensorflow.keras.losses继承父类'Loss'。所以MyHuberLoss继承为Loss。这允许我们使用 MyHuberLoss 作为损失函数。
__init__从类中初始化对象。
从类实例化对象时执行的调用函数
init 函数获取阈值,call 函数获取我们之前出售的 y_true 和 y_pred 参数。因此,我们将阈值声明为类变量,这允许我们给它一个初始值。
在 __init__ 函数中,我们将阈值设置为 self.threshold。
在调用函数中,所有阈值类变量将由 self.threshold 引用。
以下是我们如何在 model.compile 中使用这个损失函数。
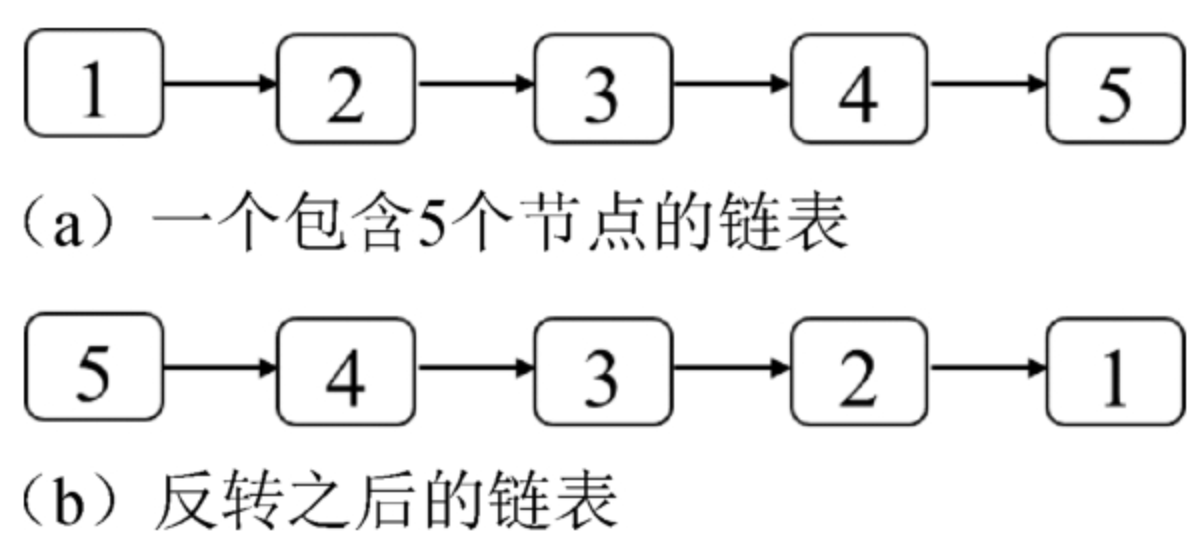
model.compile(optimizer='sgd', loss=MyHuberLoss(threshold=1.9))六、创建对比损失(用于暹罗网络):
![]()
连体网络比较两个图像是否相似。对比损失是暹罗网络中使用的损失函数。
在上面的公式中,
Y_true 是图像相似度细节的张量。如果图像相似,它们就是 1,如果不相似,它们就是 0。
D 是图像对之间的欧几里德距离的张量。
边距是一个常量,我们可以用它来强制它们之间的最小距离,以便将它们视为相似或不同。
如果Y_true =1,则方程的第一部分变为 D²,第二部分变为零。因此,当 Y_true 接近 1 时,D² 项具有更大的权重。
如果Y_true = 0,则方程的第一部分变为零,第二部分产生一些结果。这为最大项赋予了更大的权重,而为 D 平方项赋予了更少的权重,因此最大项在损失的计算中占主导地位。
使用包装函数的对比损失
def contrastive_loss_with_margin(margin):
def contrastive_loss(y_true, y_pred):
square_pred = K.square(y_pred)
margin_square = K.square(K.maximum(margin - y_pred, 0))
return K.mean(y_true * square_pred + (1 - y_true) * margin_square)
return contrastive_loss七、结论
Tensorflow 中不可用的任何损失函数都可以使用函数、包装函数或以类似的方式使用类来创建。阿琼·萨卡