教程一、Websocket获取B站直播间弹幕教程 — 哔哩哔哩直播开放平台
1、封包
我们连接上B站Websocket成功后,要做两件事情:
- 第一、发送鉴权包。
- 第二、发送心跳包,每30秒一次,维持websocket连接。
这两个包不是直接发送过去,而是要创建byte数组,将一些数据 按B站协议格式 用大端序写入到byte数组。
协议

- 1、(4 byte)Packet Length:整个Packet的长度,包含Header。
- 2、(2 byte)Header Length:Header的长度,固定为16。
- 3、(2 byte)Version:
- 如果Version=0,Body中就是实际发送的数据。
- 如果Version=2,Body中是经过压缩后的数据,请使用zlib解压,然后按照Proto协议去解析。
- 4、(4 byte)Operation:消息的类型:
- Operation == 2,客户端发送的心跳包(30秒发送一次)
- Operation == 3 ,服务器收到心跳包的回复
- Operation == 5 ,服务器推送的弹幕消息包
- Operation == 7 ,客户端发送的鉴权包(客户端发送的第一个包)
- Operation == 8 ,服务器收到鉴权包后的回复
- 5、(4 byte)Sequence ID:保留字段,可以忽略。
- 6、(? byte)Body:消息体
- body为json格式字符串 --> 转Byte数组
- 如果是心跳包body就为空
例子
这边以JAVA代码为例。
代码依赖了FastJson2,用于将Json(Map)转Json字符串。
public static byte[] pack(String jsonStr, short code){
byte[] contentBytes = new byte[0];
//如果是鉴权包,那一定带有jsonStr
if(7 == code){
contentBytes = jsonStr.getBytes();
}
try(ByteArrayOutputStream data = new ByteArrayOutputStream();
DataOutputStream stream = new DataOutputStream(data)){
stream.writeInt(contentBytes.length + 16);//封包总大小
stream.writeShort(16);//头部长度 header的长度,固定为16
stream.writeShort(0);//Version, 客户端一般发送的是普通数据。
stream.writeInt(code);//操作码(封包类型)
stream.writeInt(1);//保留字段,可以忽略。
if(7 == code){
stream.writeBytes(jsonStr);
}
return data.toByteArray();
}
}
这样封包的方法就写好了,jsonStr为要发的数据,code为包的类型。
定义生成鉴权包的方法:
public byte[] generateAuthPack(String jsonStr) throws IOException {
return pack(jsonStr, 7);
}
如果你是非官方开放API接口调用,那jsonStr得自己生成。
public byte[] generateAuthPack(String uid, String buvid,String token, int roomid){
JSONObject jo = new JSONObject();
jo.put("uid", uid);
jo.put("buvid", buvid);
jo.put("roomid", roomid);
jo.put("protover", 0);
jo.put("platform", "web");
jo.put("type", 2);
jo.put("key", token);
return pack(jo.toString(), 7);
}
- 参数
- uid : 你Cookie的DedeUserID
- buvid : 你Cookie的buvid3
- token : 鉴于是否登录token
- roomid : 直播间ID
如何获取Token?
----> 【JAVA版本】最新websocket获取B站直播弹幕——非官方API
定义生成心跳包的方法:
public static byte[] generateHeartBeatPack() throws IOException {
return pack(null, 2);
}
2、解包
成功鉴权后,我们获取到B站数据也都是byte数组,格式跟上面一样,按上面的格式来读取就行了。
不过如果是Zip包那稍微麻烦点。
获得zip包的body后还得进行解压。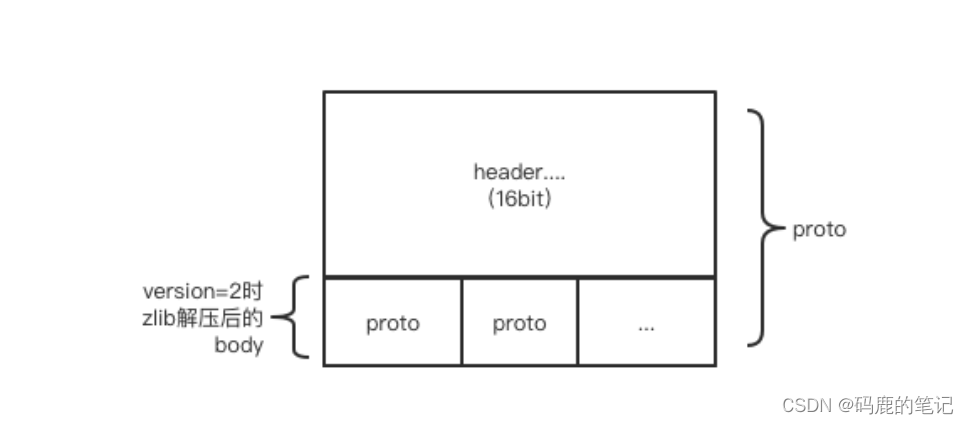
先来个流程图
代码实现
同样以JAVA代码为例
代码依赖了hutool-core,用于zip数组解压。
public static void unpack(ByteBuffer byteBuffer){
int packageLen = byteBuffer.getInt();
short headLength = byteBuffer.getShort();
short protVer = byteBuffer.getShort();
int optCode = byteBuffer.getInt();
int sequence = byteBuffer.getInt();
if(3 == optCode){
System.out.println("这是服务器心跳回复");
}
byte[] contentBytes = new byte[packageLen - headLength];
byteBuffer.get(contentBytes);
//如果是zip包就进行解包
if(2 == protVer){
unpack(ByteBuffer.wrap(ZipUtil.unZlib(contentBytes)));
return;
}
String content = new String(contentBytes, StandardCharsets.UTF_8);
if(8 == optCode){
//返回{"code":0}表示成功
System.out.println("这是鉴权回复:"+content);
}
//真正的弹幕消息
if(5 == optCode){
System.out.println("真正的弹幕消息:"+content);
// todo 自定义处理
}
//只存在ZIP包解压时才有的情况
//如果byteBuffer游标 小于 byteBuffer大小,那就证明还有数据
if(byteBuffer.position() < byteBuffer.limit()){
unpack(byteBuffer);
}
}




![[CSAWQual 2019]Web_Unagi - 文件上传+XXE注入(XML编码绕过)](https://img-blog.csdnimg.cn/1673e5642a6c4070afa10c73179fcde2.png)