关于感知机
感知机(Perceptron)和神经网络(Neural Network)之间有一定的关系,可以说感知机是神经网络的一个基本组成单元。
-
感知机:
- 感知机是一种简单的二分类线性分类器。
- 它接受多个输入,对每个输入施加权重,然后将它们相加。这个总和会经过一个激活函数(通常是阶跃函数)得到输出。
- 如果输出超过某个阈值,它将被分类为一类,否则分类为另一类。
- 感知机可以用于解决线性可分的问题,但不能解决线性不可分的问题。
感知机有两部分,一是线性函数,二是激活函数:

其中线性函数如果在二维中就是一条直线f=wx+b把两种类别分开,在三维就是一个平面...


单个感知机能处理与或非但不能处理异或:

因为异或可以用与或非表示出来,故要处理异或问题可以用多层感知机:

-
神经网络:
- 神经网络是一个更加复杂的模型,由许多层次的神经元组成。
- 每个神经元接受多个输入,并为每个输入分配一个权重。然后将所有加权输入相加,通过激活函数处理得到输出。
- 神经网络可以包含多个层(输入层、隐藏层、输出层),其中隐藏层其实就是多层感知机,可以处理更加复杂的非线性关系。
关于损失函数
最小二乘法
假设是真实结果,
是预测结果,最直观的想法就是去求它们之间的差值,让差值尽可能的小,即让预测结果尽可能接近真实结果。

但是用这个绝对值可能会不可导,故采用平方的形式衡量这种差距,“最小”即min“二乘”即二次方。

极大似然估计法
知道结果,由结果去反推造成结果的概率模型时的估计方法。
比如10每硬币抛出来7个正面3个反面,如果算出的概率模型有0.1:0.9、0.7:0.3和0.8:0.2,其中0.7:0.3的概率模型下发生这件事的概率为0.7^5*0.3^3,概率是最大的即“似然”,那么就“估计”这种概率模型就是真实抛硬币的概率模型。

如果事件只有两种情况,那么符合伯努利分布。


交叉熵
熵
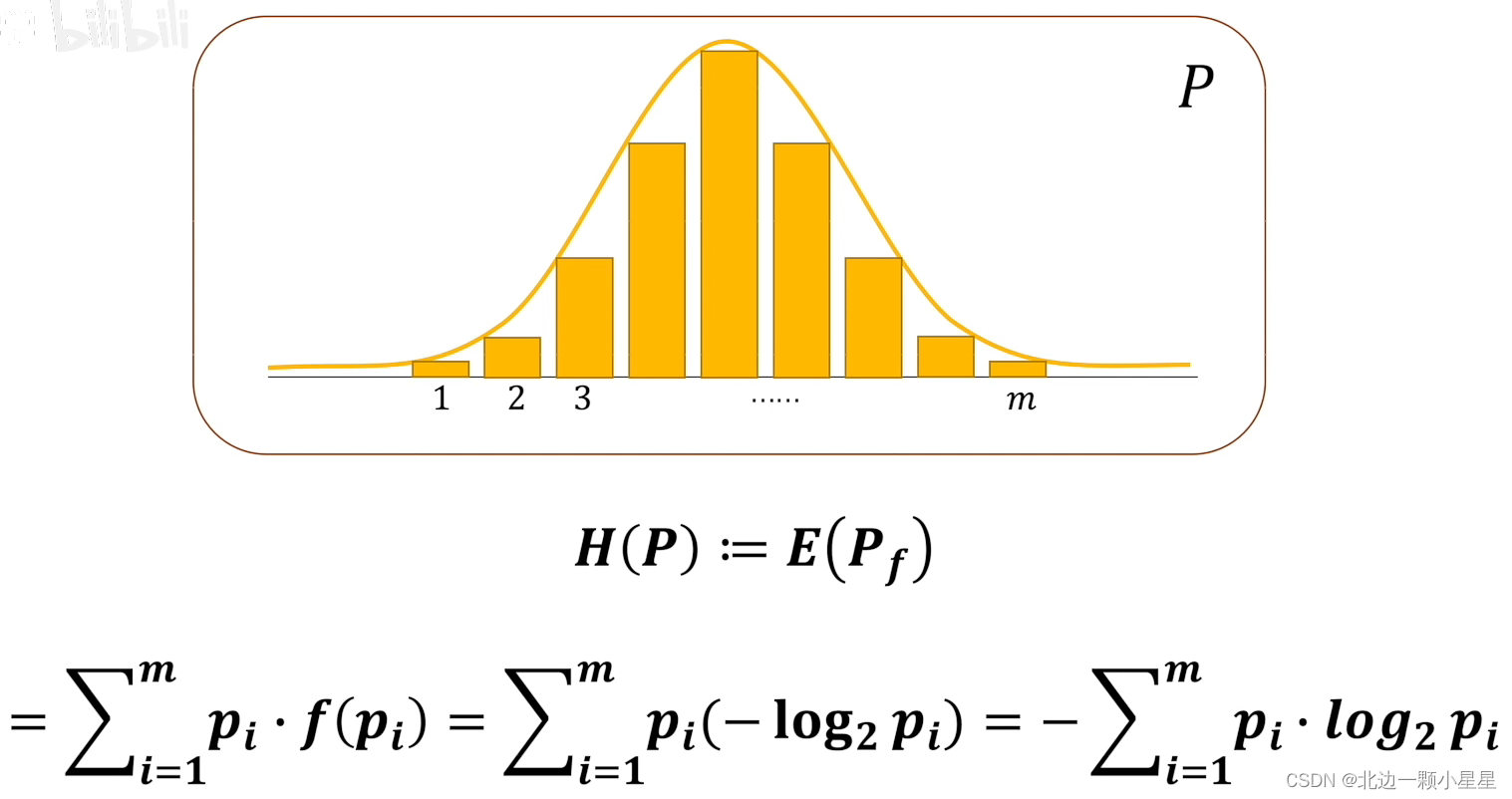
熵是衡量一个系统不确定性的多少即信息量。
假如有一个概率系统P,那么它的熵就是对这个系统的信息量求期望。
KL散度
KL散度即相对熵,相对指的是两个概率系统。

D(P||Q)和D(Q||P)是不等价的,D(P||Q)表示以P为基准,它们信息量相差多少。
由整理的结果可见,第一项是交叉熵;第二项是P的系统熵,是定值。
引理:KL散度大于等于0,当P=Q时为0。
要让两个概率系统接近,即最小化交叉熵->损失函数。
由于P的熵是定值求梯度(即函数偏导)为0,故其实KL散度作损失函数等价于交叉熵作损失函数。
假设事件只有两种情况,交叉熵可写为:

可以发现,交叉熵和极大似然估计法的式子形式一样(含义不同)。
关于梯度下降
调整参数(比如权重w和偏置b)的策略是反向传播,梯度下降是反向传播的一种方法,除此之外还有牛顿法、冲量法...
正向传播就是信息在一层层的感知机下传递下去。
反向传播就是把偏差传递到各个参数上,根据参数对偏差的“贡献”大小作相应的调整多少。
(蕴含的贪心思想:优先调整那些对最后结果有重大影响的参数)
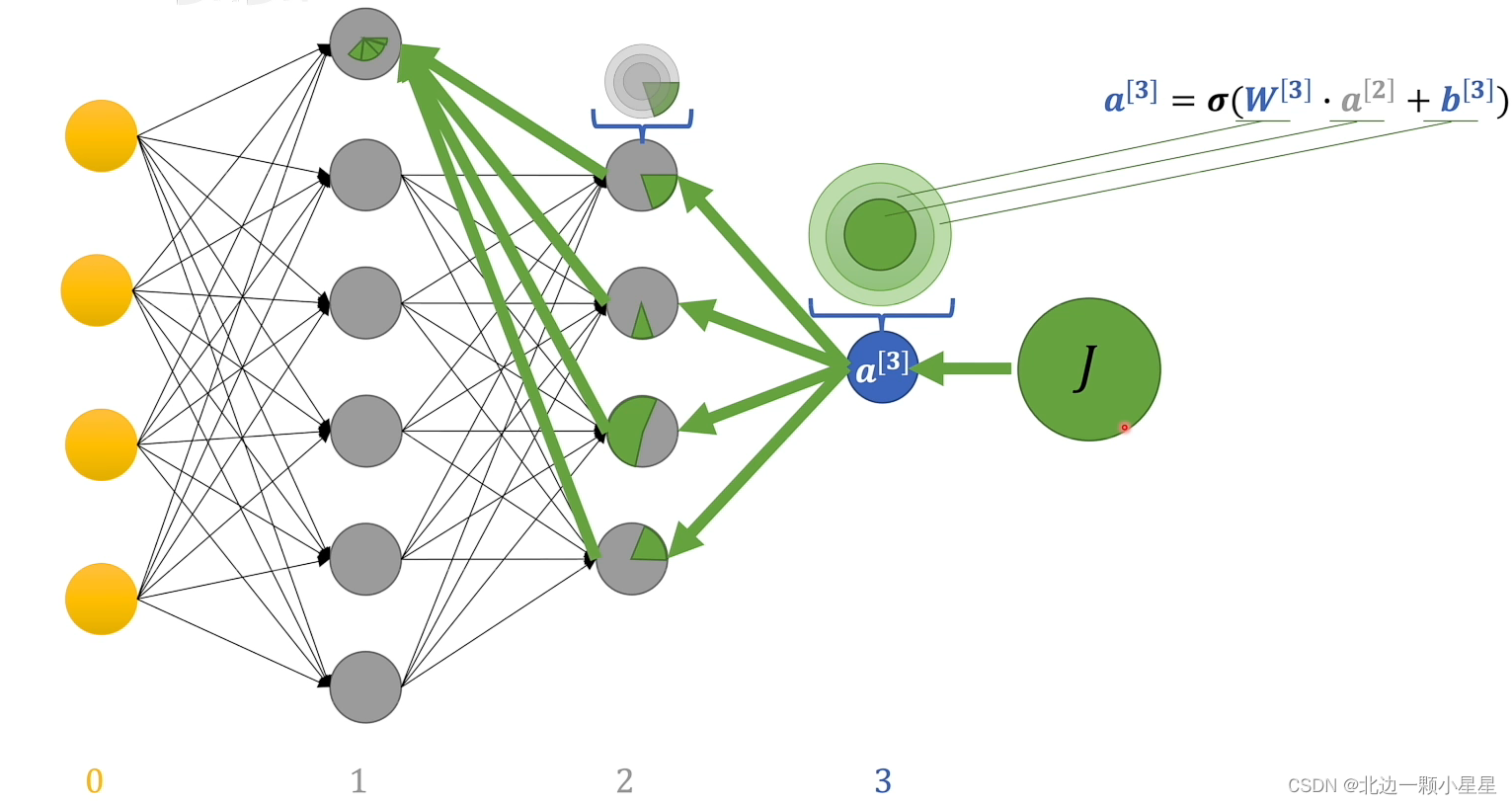
其中J表示由损失函数算出来的偏差,绿色部分代表该感知机因对最后结果的“贡献”大小所承担的“责任”的多少(浅绿部分是参数,深绿部分是上一层造成的偏差,回传给上一层)。
上面直观的理解图的偏差是用数值加法,实际是用向量的加法进行分配,由于偏差值是没有方向的,所以还需要找到一个确定的方向->梯度的方向就是向量的方向。准确来说是梯度的反方向,因为梯度的方向是数值增加最快的方向,其反方向才是数值减小最快的方向。


![[CSAWQual 2019]Web_Unagi - 文件上传+XXE注入(XML编码绕过)](https://img-blog.csdnimg.cn/1673e5642a6c4070afa10c73179fcde2.png)