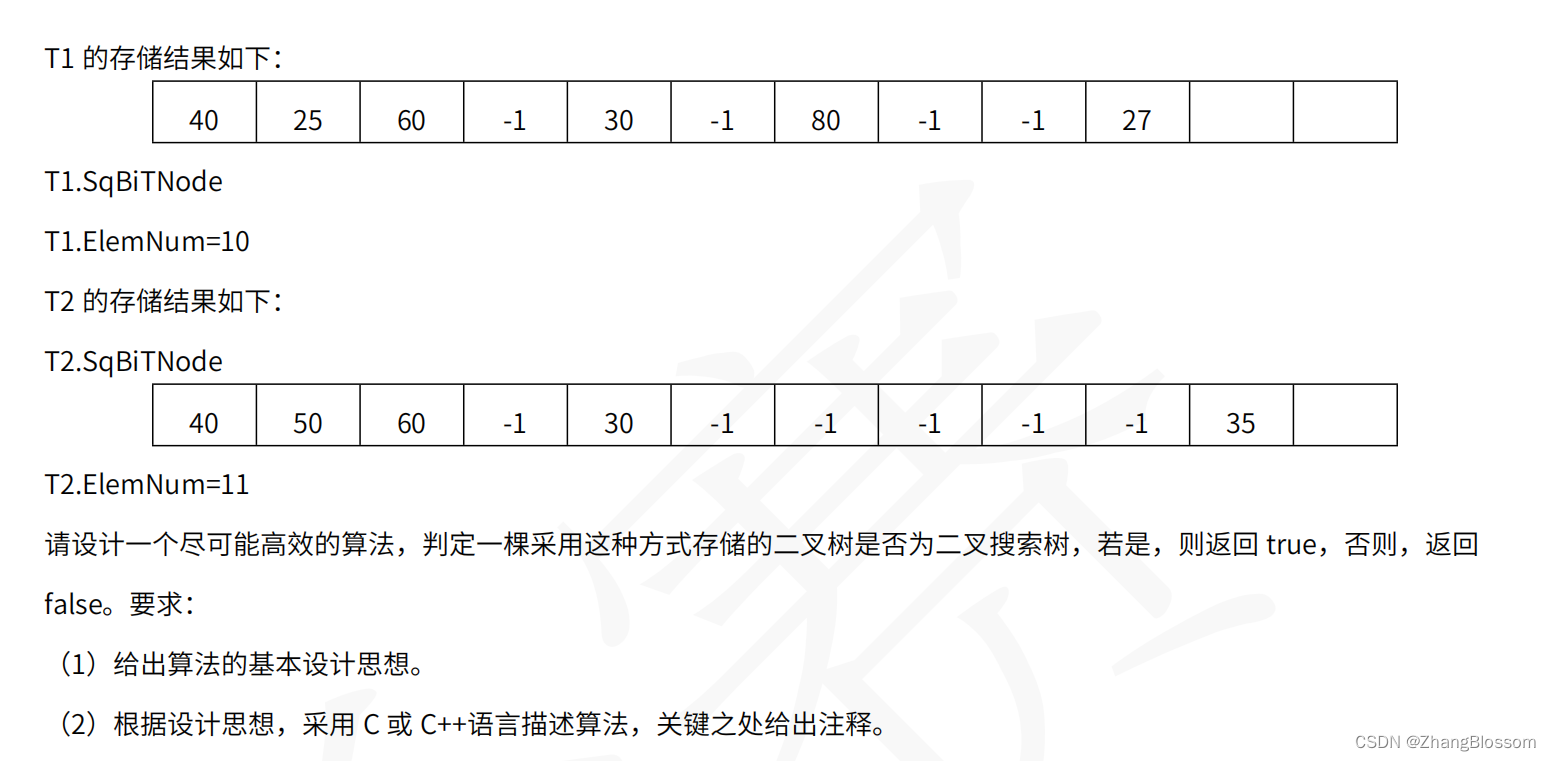
文章目录
- 多线程的使用
- 1. 导入线程模块
- 2. 线程类Thread参数说明
- 3. 启动线程
- 4. 多线程完成多任务的代码
- 5. 小结
- 线程执行带有参数的任务
- 1. 线程执行带有参数的任务的介绍
- 2. args参数的使用
- 3. kwargs参数的使用
- 4. 小结
- 线程的注意点
- 1. 线程的注意点介绍
- 2. 线程之间执行是无序的
- 3. 主线程会等待所有的子线程执行结束再结束
- 3. 线程之间共享全局变量
- 4. 线程之间共享全局变量数据出现错误问题
- 5. 小结
- 进程和线程的对比
- 1. 进程和线程的对比的三个方向
- 2. 关系对比
- 2. 区别对比
- 3. 优缺点对比
- 4. 小结
多线程的使用
学习目标
- 能够使用多线程完成多任务
1. 导入线程模块
#导入线程模块
import threadingCopy
2. 线程类Thread参数说明
Thread([group [, target [, name [, args [, kwargs]]]]])
- group: 线程组,目前只能使用None
- target: 执行的目标任务名
- args: 以元组的方式给执行任务传参
- kwargs: 以字典方式给执行任务传参
- name: 线程名,一般不用设置
3. 启动线程
启动线程使用start方法
4. 多线程完成多任务的代码
import threading
import time
# 唱歌任务
def sing():
# 扩展: 获取当前线程
# print("sing当前执行的线程为:", threading.current_thread())
for i in range(3):
print("正在唱歌...%d" % i)
time.sleep(1)
# 跳舞任务
def dance():
# 扩展: 获取当前线程
# print("dance当前执行的线程为:", threading.current_thread())
for i in range(3):
print("正在跳舞...%d" % i)
time.sleep(1)
if __name__ == '__main__':
# 扩展: 获取当前线程
# print("当前执行的线程为:", threading.current_thread())
# 创建唱歌的线程
# target: 线程执行的函数名
sing_thread = threading.Thread(target=sing)
# 创建跳舞的线程
dance_thread = threading.Thread(target=dance)
# 开启线程
sing_thread.start()
dance_thread.start()Copy
执行结果:
正在唱歌...0
正在跳舞...0
正在唱歌...1
正在跳舞...1
正在唱歌...2
正在跳舞...2Copy
5. 小结
- 导入线程模块
- import threading
- 创建子线程并指定执行的任务
- sub_thread = threading.Thread(target=任务名)
- 启动线程执行任务
- sub_thread.start()
线程执行带有参数的任务
学习目标
- 能够写出线程执行带有参数的任务
1. 线程执行带有参数的任务的介绍
前面我们使用线程执行的任务是没有参数的,假如我们使用线程执行的任务带有参数,如何给函数传参呢?
Thread类执行任务并给任务传参数有两种方式:
- args 表示以元组的方式给执行任务传参
- kwargs 表示以字典方式给执行任务传参
2. args参数的使用
示例代码:
import threading
import time
# 带有参数的任务
def task(count):
for i in range(count):
print("任务执行中..")
time.sleep(0.2)
else:
print("任务执行完成")
if __name__ == '__main__':
# 创建子线程
# args: 以元组的方式给任务传入参数
sub_thread = threading.Thread(target=task, args=(5,))
sub_thread.start()Copy
执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行中..
任务执行中..
任务执行完成Copy
3. kwargs参数的使用
示例代码:
import threading
import time
# 带有参数的任务
def task(count):
for i in range(count):
print("任务执行中..")
time.sleep(0.2)
else:
print("任务执行完成")
if __name__ == '__main__':
# 创建子线程
# kwargs: 表示以字典方式传入参数
sub_thread = threading.Thread(target=task, kwargs={"count": 3})
sub_thread.start()Copy
执行结果:
任务执行中..
任务执行中..
任务执行中..
任务执行完成Copy
4. 小结
-
线程执行任务并传参有两种方式:
- 元组方式传参(args) :元组方式传参一定要和参数的顺序保持一致。
- 字典方式传参(kwargs):字典方式传参字典中的key一定要和参数名保持一致。
线程的注意点
学习目标
- 能够说出线程的注意点
1. 线程的注意点介绍
- 线程之间执行是无序的
- 主线程会等待所有的子线程执行结束再结束
- 线程之间共享全局变量
- 线程之间共享全局变量数据出现错误问题
2. 线程之间执行是无序的
import threading
import time
def task():
time.sleep(1)
print("当前线程:", threading.current_thread().name)
if __name__ == '__main__':
for _ in range(5):
sub_thread = threading.Thread(target=task)
sub_thread.start()Copy
执行结果:
当前线程: Thread-1
当前线程: Thread-2
当前线程: Thread-4
当前线程: Thread-5
当前线程: Thread-3Copy
说明:
- 线程之间执行是无序的,它是由cpu调度决定的 ,cpu调度哪个线程,哪个线程就先执行,没有调度的线程不能执行。
- 进程之间执行也是无序的,它是由操作系统调度决定的,操作系统调度哪个进程,哪个进程就先执行,没有调度的进程不能执行。
3. 主线程会等待所有的子线程执行结束再结束
假如我们现在创建一个子线程,这个子线程执行完大概需要2.5秒钟,现在让主线程执行1秒钟就退出程序,查看一下执行结果,示例代码如下:
import threading
import time
# 测试主线程是否会等待子线程执行完成以后程序再退出
def show_info():
for i in range(5):
print("test:", i)
time.sleep(0.5)
if __name__ == '__main__':
sub_thread = threading.Thread(target=show_info)
sub_thread.start()
# 主线程延时1秒
time.sleep(1)
print("over")Copy
执行结果:
test: 0
test: 1
over
test: 2
test: 3
test: 4Copy
说明:
通过上面代码的执行结果,我们可以得知: 主线程会等待所有的子线程执行结束再结束
假如我们就让主线程执行1秒钟,子线程就销毁不再执行,那怎么办呢?
- 我们可以设置守护主线程
守护主线程:
- 守护主线程就是主线程退出子线程销毁不再执行
设置守护主线程有两种方式:
- threading.Thread(target=show_info, daemon=True)
- 线程对象.setDaemon(True)
设置守护主线程的示例代码:
import threading
import time
# 测试主线程是否会等待子线程执行完成以后程序再退出
def show_info():
for i in range(5):
print("test:", i)
time.sleep(0.5)
if __name__ == '__main__':
# 创建子线程守护主线程
# daemon=True 守护主线程
# 守护主线程方式1
sub_thread = threading.Thread(target=show_info, daemon=True)
# 设置成为守护主线程,主线程退出后子线程直接销毁不再执行子线程的代码
# 守护主线程方式2
# sub_thread.setDaemon(True)
sub_thread.start()
# 主线程延时1秒
time.sleep(1)
print("over")Copy
执行结果:
test: 0
test: 1
overCopy
3. 线程之间共享全局变量
需求:
- 定义一个列表类型的全局变量
- 创建两个子线程分别执行向全局变量添加数据的任务和向全局变量读取数据的任务
- 查看线程之间是否共享全局变量数据
import threading
import time
# 定义全局变量
my_list = list()
# 写入数据任务
def write_data():
for i in range(5):
my_list.append(i)
time.sleep(0.1)
print("write_data:", my_list)
# 读取数据任务
def read_data():
print("read_data:", my_list)
if __name__ == '__main__':
# 创建写入数据的线程
write_thread = threading.Thread(target=write_data)
# 创建读取数据的线程
read_thread = threading.Thread(target=read_data)
write_thread.start()
# 延时
# time.sleep(1)
# 主线程等待写入线程执行完成以后代码在继续往下执行
write_thread.join()
print("开始读取数据啦")
read_thread.start()Copy
执行结果:
write_data: [0, 1, 2, 3, 4]
开始读取数据啦
read_data: [0, 1, 2, 3, 4]Copy
4. 线程之间共享全局变量数据出现错误问题
需求:
- 定义两个函数,实现循环100万次,每循环一次给全局变量加1
- 创建两个子线程执行对应的两个函数,查看计算后的结果
import threading
# 定义全局变量
g_num = 0
# 循环一次给全局变量加1
def sum_num1():
for i in range(1000000):
global g_num
g_num += 1
print("sum1:", g_num)
# 循环一次给全局变量加1
def sum_num2():
for i in range(1000000):
global g_num
g_num += 1
print("sum2:", g_num)
if __name__ == '__main__':
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动线程
first_thread.start()
# 启动线程
second_thread.start()Copy
执行结果:
sum1: 1210949
sum2: 1496035Copy
注意点:
多线程同时对全局变量操作数据发生了错误
错误分析:
两个线程first_thread和second_thread都要对全局变量g_num(默认是0)进行加1运算,但是由于是多线程同时操作,有可能出现下面情况:
- 在g_num=0时,first_thread取得g_num=0。此时系统把first_thread调度为”sleeping”状态,把second_thread转换为”running”状态,t2也获得g_num=0
- 然后second_thread对得到的值进行加1并赋给g_num,使得g_num=1
- 然后系统又把second_thread调度为”sleeping”,把first_thread转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
- 这样导致虽然first_thread和first_thread都对g_num加1,但结果仍然是g_num=1
全局变量数据错误的解决办法:
线程同步: 保证同一时刻只能有一个线程去操作全局变量 同步: 就是协同步调,按预定的先后次序进行运行。如:你说完,我再说, 好比现实生活中的对讲机
线程等待的示例代码:
import threading
# 定义全局变量
g_num = 0
# 循环1000000次每次给全局变量加1
def sum_num1():
for i in range(1000000):
global g_num
g_num += 1
print("sum1:", g_num)
# 循环1000000次每次给全局变量加1
def sum_num2():
for i in range(1000000):
global g_num
g_num += 1
print("sum2:", g_num)
if __name__ == '__main__':
# 创建两个线程
first_thread = threading.Thread(target=sum_num1)
second_thread = threading.Thread(target=sum_num2)
# 启动线程
first_thread.start()
# 主线程等待第一个线程执行完成以后代码再继续执行,让其执行第二个线程
# 线程同步: 一个任务执行完成以后另外一个任务才能执行,同一个时刻只有一个任务在执行
first_thread.join()
# 启动线程
second_thread.start()Copy
执行结果:
sum1: 1000000
sum2: 2000000Copy
5. 小结
-
线程执行执行是无序的
-
主线程默认会等待所有子线程执行结束再结束,设置守护主线程的目的是主线程退出子线程销毁。
-
线程之间共享全局变量,好处是可以对全局变量的数据进行共享。
-
线程之间共享全局变量可能会导致数据出现错误问题,可以使用线程同步方式来解决这个问题。
- 线程等待(join)
进程和线程的对比
学习目标
- 能够知道进程和线程的关系
1. 进程和线程的对比的三个方向
- 关系对比
- 区别对比
- 优缺点对比
2. 关系对比
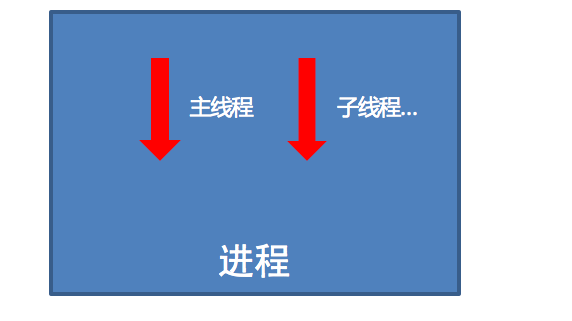
- 线程是依附在进程里面的,没有进程就没有线程。
- 一个进程默认提供一条线程,进程可以创建多个线程。
2. 区别对比
- 进程之间不共享全局变量
- 线程之间共享全局变量,但是要注意资源竞争的问题,解决办法: 线程同步
- 创建进程的资源开销要比创建线程的资源开销要大
- 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
- 线程不能够独立执行,必须依存在进程中
- 多进程开发比单进程多线程开发稳定性要强
3. 优缺点对比
- 进程优缺点:
- 优点:可以用多核
- 缺点:资源开销大
- 线程优缺点:
- 优点:资源开销小
- 缺点:不能使用多核
4. 小结
- 进程和线程都是完成多任务的一种方式
- 多进程要比多线程消耗的资源多,但是多进程开发比单进程多线程开发稳定性要强,某个进程挂掉不会影响其它进程。
- 多进程可以使用cpu的多核运行,多线程可以共享全局变量。
- 线程不能单独执行必须依附在进程里面