Copy Mechanism
有时我们并不需要decoder创造一些东西出来,有些内容是可以从encoder复制而来。 最早具有复制能力的模型:Pointer Network
例如:
chat-bot

Summarization
至少要训练百万篇文章
Guided Attention
Monotonic Attention
Location-aware attention
语音识别往往也会犯很多低级的错误,例如语音合成中念短句子时出错。
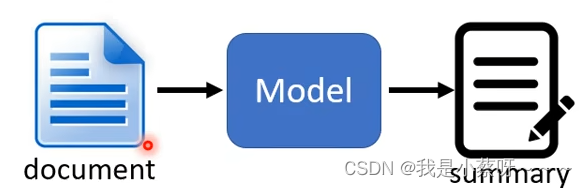
guided attend 要做的事情就是要求机器在做attention的时候有固定的方式。
以语音合成为例:
我们在输入一段文字后,机器显然是应该从左念到右。
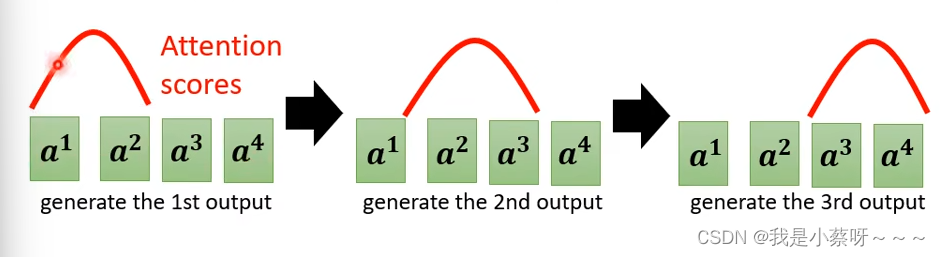
如果机器颠三倒四,显然会出错
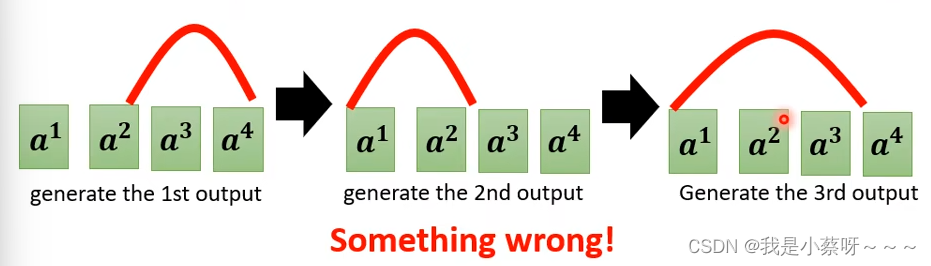
此时Guided Attention所做的事情是强迫Attention的位置是从左到右,直接将这个限制放入training里面,要求机器学到应该由左到右。
Beam Search
Greedy Decoding :每次分数都选最高的一个
但是,red path不一定是最好的方法,例如:
green path最终结果更好
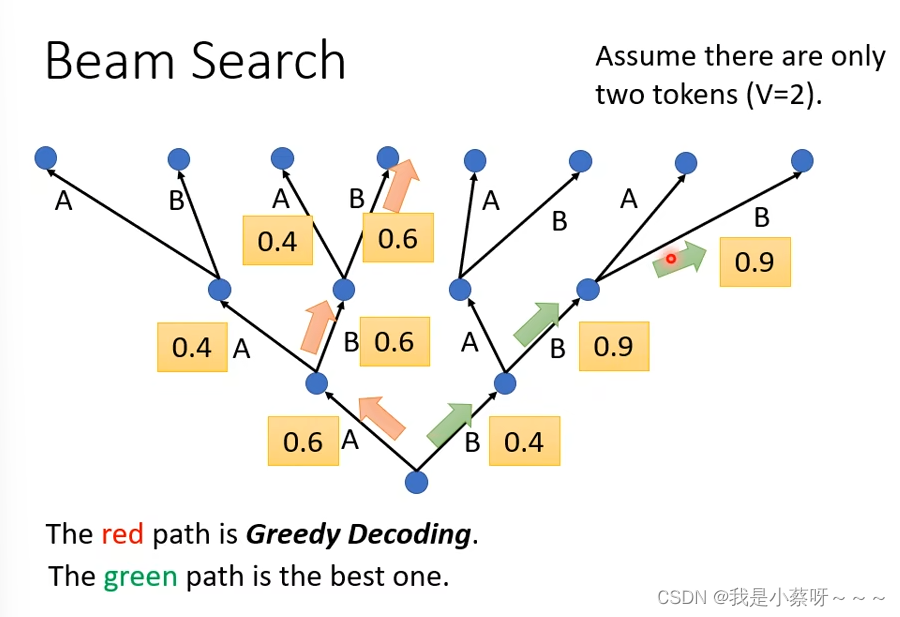
爆搜所有可能,可以找到一条最优路径,但是计算量太大,几乎不可能。
Beam Search是一个比较有效的方法,其每次都保留B个最好的路径。Beam size的大小需要自己去考量的。但是其有时有用,有时候没用。
有时候没有找到最好的路 ,反而结果比较好。具体要看自己任务的特性,比如答案是不是非常明确,以语音辨识来说,一句话只有一个可能,通常beam search会有帮助。需要机器发挥一些创造力,不是只有一个答案时,则beam search则没有太多帮助,并且需要加入一些随机性。例如,在做TTS语音合成的时候decode要加一些noise。
在test的时候考虑bleu score,而不是cross-entropy
为什么我们train的时候考虑cross-entropy而不是bleu score?
因为bleu score无法作微分。
遇到optimization无法解决的问题,可以用RL硬train一发;遇到无法 optimize的Loss function,把它当作是RL的Reward,Decoder当作agent,把它当作RL的问题硬做也是有可能的。

Scheduled Sampling
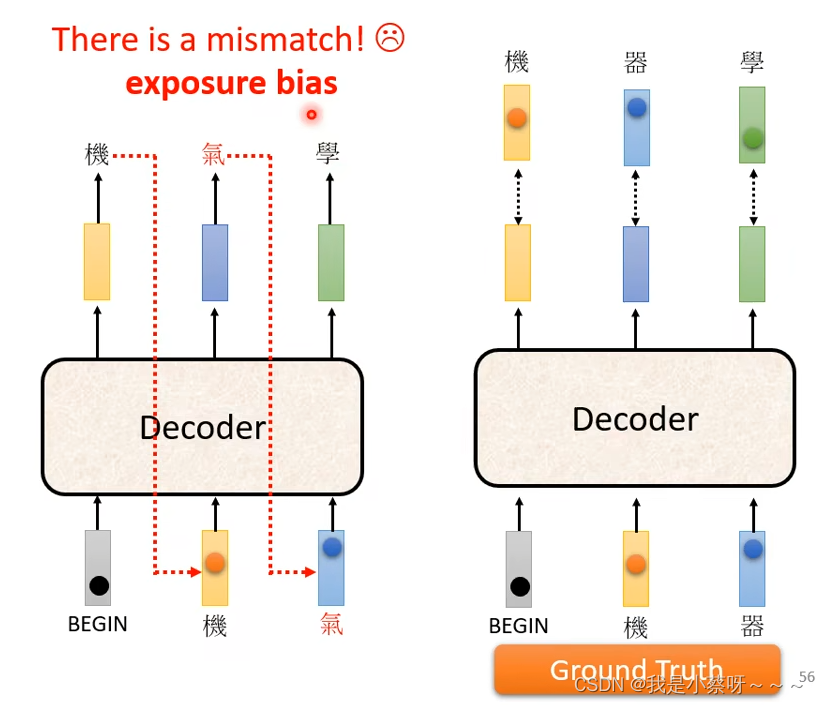
exposure bias:训练时decoder看到的是正确信息,测试时不是。但是如果训练时,decoder只看过正确的东西。则在测试时看到错误的东西的时候可能会导致整个结果坏掉,解决的方向:在训练的时候加入一些错误的东西。