我们是否可以通过气象图来预测降水量呢?今天我们来使用CNN和LSTM进行一个有趣的实验。
我们这里使用荷兰皇家气象研究所(也称为KNMI)提供的开放数据集和公共api,来获取数据集并且构建模型预测当地的降水量。
数据收集
KNMI提供的数据集,我们假设气象雷达产生的信号在反射时会被降水(雨、雪、冰雹等)反射。由雷达捕获的反射信号的强度称为反射率(以 dBZ 计算),我们可以粗略认为它与该点的降水强度成正比。当通过根据信号强度映射色标将此反射率数据转换为图像时(默认情况下,KNMI 提供的色标为“viridis”,紫色/深蓝色表示较低值,黄色表示较高值)产生 图像就像下图显示的那样。我们每 5 分钟通过 API 以原始格式获取这些数据。但是API 有一个配额,每小时只能获取 100 张图像。

定义问题
最原始的也是最简单的预测视频中的下一帧的内容的方法是使用CNN和LSTM。我们是否可以将预测天气雷达的下一个捕获信号的问题简化为预测视频中的下一帧的问题呢(雷达的讯号也是图像序列)。所以我收集了一些图像序列,并开始实验各种架构的卷积LSTM神经网络。每个训练数据点由36个连续的雷达原始文件(对应于间隔5分钟的3小时的测量)组成。然后将每个数据点分成两部分。前18帧用作“特征”(x),后18帧是神经网络在给定前18帧的情况下试图预测的内容(y)。在天气预报方面,给定过去1.5小时的降水数据,未来1.5小时的降水情况(帧间隔为5分钟,因此18帧对应1.5小时)。
为什么是卷积LSTM
如果你对神经网络和深度学习有点熟悉,你可能知道卷积神经网络(CNN)在涉及分析或发现图像中的特定特征和形状的任务上表现非常好。而长短期记忆(LSTM)神经网络在涉及时间维度(如时间序列预测)和数据序列(如图像序列、特定时间范围内的信号序列等)的任务上表现非常好。这主要是因为它们有能力学习数据中的长期依赖关系。因此,研究人员在2015年首次提出了一种结合卷积和LSTM层的架构,这样可以预测一系列图像中的下一个图像(他们对其进行基准测试的应用之一是降水预测),所以本文中也是用类似的模型。
数据预处理
我们使用了近160个连续的36次雷达扫描序列,我们使用h5py 库可以读取并轻松处理原始数据(如从 KNMI 接收的数据是这个格式)并对它们进行预处理。数据点是从 01-01-2019 到现在的随机日期和时间中挑选的。由于生成的图像的原始尺寸太大,所以将的图像从原始尺寸(700x765)缩小到(315x344)。这是模型可以在合理的时间内训练的最高分辨率,并且在过程中不会有任何的内存溢出问题。然后将每个序列分成两个相等的部分。前18帧用作“特征”(x),后18帧是神经网络试图预测的帧(y)(给定前18帧)。最后,我将数据集分成两个单独的数据集,分别用于训练(80%)和验证(20%)。
执行上述所有任务的代码如下面的代码片段所示:
def create_dataset_from_raw(directory_path, resize_to):
resize_width = resize_to[0]
resize_height = resize_to[1]
batch_names = [directory_path + name for name in os.listdir(directory_path) if os.path.isdir(os.path.join(directory_path, name))]
dataset = np.zeros(shape=(len(batch_names),36,resize_height,resize_width)) # (samples, filters, rows = height, cols = width)
for batch_idx,batch in enumerate(batch_names):
files = [x for x in os.listdir(batch) if x != '.DS_Store']
files.sort()
crn_batch = np.zeros(shape=(36, resize_height, resize_width))
for (idx,raster) in enumerate(files):
fn = batch + '/' + raster
img = h5py.File(fn)
original_image = np.array(img["image1"]["image_data"]).astype(float)
img = Image.fromarray(original_image)
# note that here it is (width, heigh) while in the tensor is in (rows = height, cols = width)
img = img.resize(size=(resize_width, resize_height))
original_image = np.array(img)
original_image = original_image / 255.0
crn_batch[idx] = original_image
dataset[batch_idx] = crn_batch
print("Importing batch:" + str(batch_idx+1))
return dataset
def split_data_xy(data):
x = data[:, 0 : 18, :, :]
y = data[:, 18 : 36, :, :]
return x, y
dataset = create_dataset_from_raw('./data/raw/', resize_to=(315,344))
dataset = np.expand_dims(dataset, axis=-1)
dataset_x, dataset_y = split_data_xy(dataset)
X_train, X_val, y_train, y_val = sk.train_test_split(dataset_x,dataset_y,test_size=0.2, random_state = 42)
模型
我使用Tensorflow和Keras框架进行开发。模型基本上是一个自编码器。自编码器是一种神经网络,它试图降低训练数据的维度,对数据进行压缩,然后可以从压缩后潜在空间的分布的近似值中采样,以生成“新”数据。
我们的模型看起来像这样:
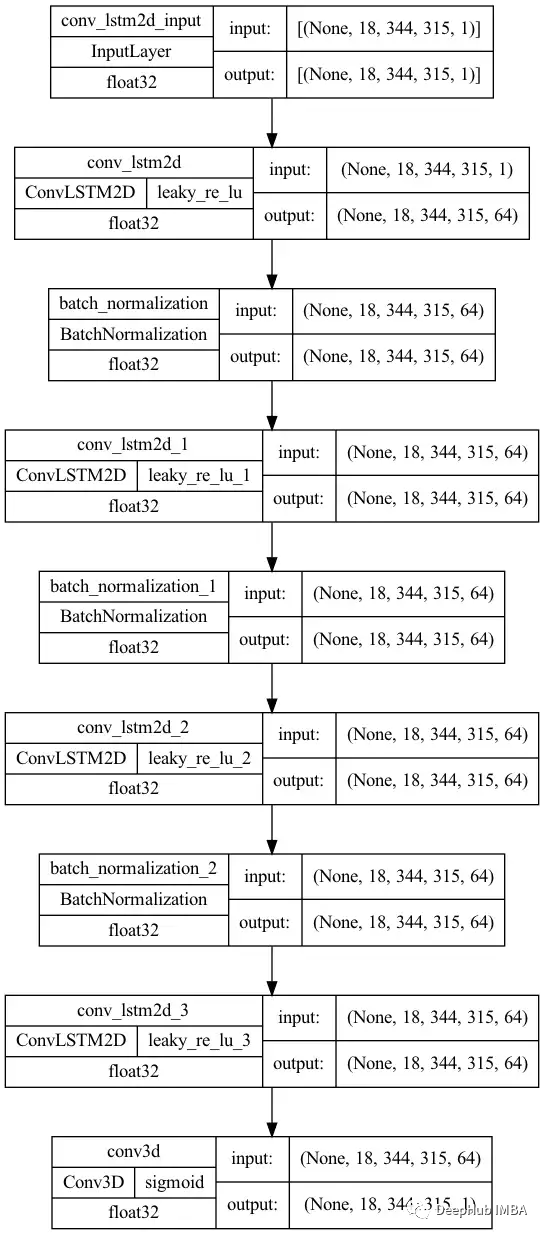
模型共包含9层(输入、输出和7个隐藏层)。隐藏层在ConvLSTM2D层和BatchNormalization层之间交换。ConvLSTM2D层就像简单的LSTM层,但是它们的输入和循环转换卷积。ConvLSTM2D层在保留输入维度的同时,随着时间的推移执行卷积运算。你可以把它想象成一个简单的卷积层,它的输出被压平,然后作为输入传递到一个简单的LSTM层。ConvLSTM2D层接收形式为(samples, time, channels, rows, cols)的张量作为输入,输出形式(samples, timesteps, filters, new_rows, new_cols)。所以它们在一段时间内对一系列帧进行运算。
ConvLSTM2D层之间的BatchNormalization层进行归一化操作
对于所有的层(除了输出层),都使用LeakyRelu激活函数,他比ReLu好一些,并且和ReLu一样快。
该模型采用二元交叉熵损失函数和Adadelta梯度下降优化器进行拟合。由于数据的高维数,Adadelta会比经典Adam优化器有更好的结果。模型训练了25个epoch(之后开始过拟合)。
模型的代码如下所示:
def create_model():
model = Sequential()
model.add(ConvLSTM2D(filters=64, kernel_size=(7, 7),
input_shape=(18,344,315,1),
padding='same',activation=LeakyReLU(alpha=0.01), return_sequences=True))
model.add(BatchNormalization())
model.add(ConvLSTM2D(filters=64, kernel_size=(5, 5),
padding='same',activation=LeakyReLU(alpha=0.01), return_sequences=True))
model.add(BatchNormalization())
model.add(ConvLSTM2D(filters=64, kernel_size=(3, 3),
padding='same',activation=LeakyReLU(alpha=0.01), return_sequences=True))
model.add(BatchNormalization())
model.add(ConvLSTM2D(filters=64, kernel_size=(1, 1),
padding='same',activation=LeakyReLU(alpha=0.01), return_sequences=True))
model.add(Conv3D(filters=1, kernel_size=(3, 3, 3),
activation='sigmoid',
padding='same', data_format='channels_last'))
return model
model = create_model()
model.compile(loss='binary_crossentropy', optimizer='adadelta')
keras.utils.plot_model(model, to_file="model.png", show_dtype=True, show_layer_activations=True, show_shapes=True)
print(model.summary())
epochs = 25
batch_size = 1
#Fit the model
model.fit(
X_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_val, y_val),
verbose=1,
)
结果
在训练模型之后,使用来自验证数据集的示例数据进行测试。模型的输入是18个连续的帧(对应于雷达捕捉到的近1.5小时的信号),它返回下一个18个预测帧(对应于接下来的1.5小时)。
# pick a random index from validation dataset
random_index = np.random.choice(range(len(X_val)), size=1)
test_serie_X = X_val[random_index[0]]
test_serie_Y = y_val[random_index[0]]
first_frames = test_serie_X
original_frames = test_serie_Y
# predict the next 18 fames
new_prediction = model.predict(np.expand_dims(first_frames, axis=0))
new_prediction = np.squeeze(new_prediction, axis=0)
fig, axes = plt.subplots(2, 18, figsize=(20, 4))
# Plot the ground truth frames.
for idx, ax in enumerate(axes[0]):
ax.imshow(np.squeeze(original_frames[idx]), cmap="viridis")
ax.set_title(f"Frame {idx + 18}")
ax.axis("off")
# Plot the predicted frames.
for idx, ax in enumerate(axes[1]):
ax.imshow((new_prediction[idx]).reshape((344,315)), cmap="viridis")
ax.set_title(f"Frame {idx + 18}")
ax.axis("off")
plt.show()
将预测的帧与实际情况进行比较,结果如下图所示。

真实帧与预测帧非常接近。这种可视化并没有清楚地呈现降水系统移动的时间维度和方向,因此下面的两个GIF动画可以更好地解释模型的输出。
下面是真值的GIF

下面是预测GIF

两个动画也非常接近,模型正确地捕捉到了降水系统的移动方向和强度(黄色更强烈,紫色/深蓝色强度较低)。
总结
ConvLSTM将深度学习的两个核心概念结合起来,并获得了很好的效果。本文的完整项目的代码在这里:
https://avoid.overfit.cn/post/da7a8bd23ec14fc6870e1e4b54e85283
作者:Petros Demetrakopoulos