一、ShardingSphere产品介绍
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
- 一套开源的分布式数据库中间件解决方案。
- 有三个产品:JDBC、Proxy、Sidecar。
三者的区别如下:
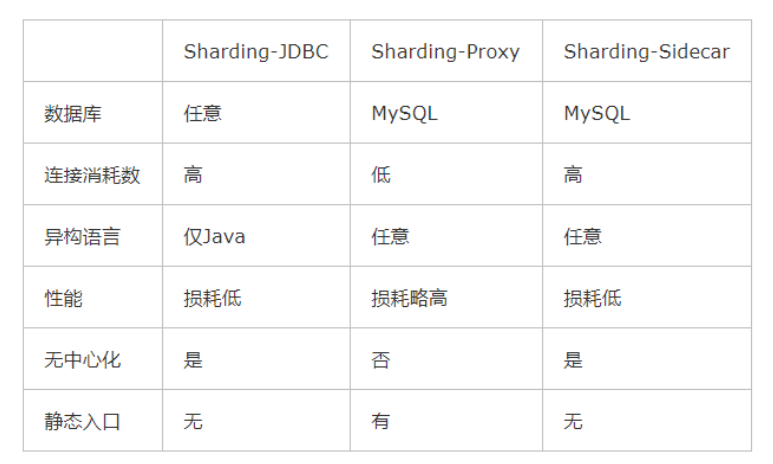
本文重点介绍ShardingJDBC这个组件,该组件从应用层面解决了读写分离、分库分表、分布式事务等一系列问题。
1.ShardingJDBC介绍
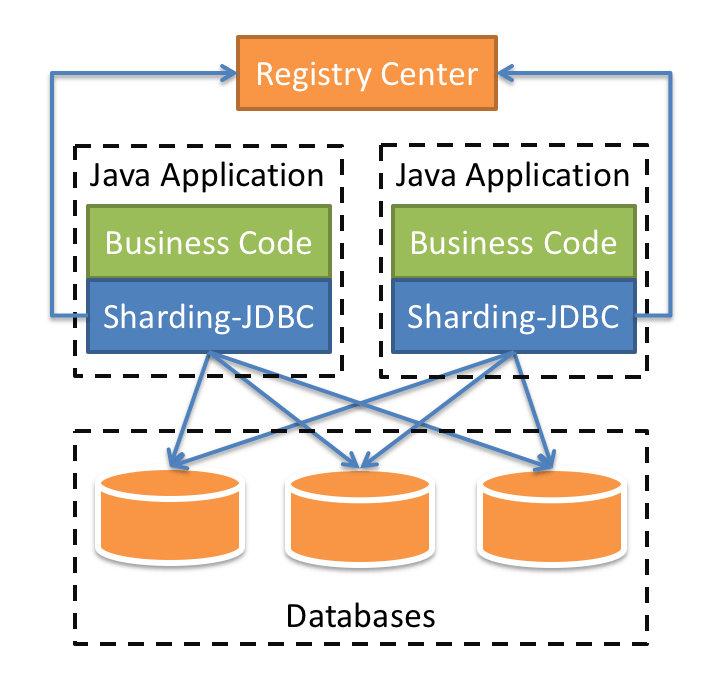
ShardingJDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
二、代码实践
实现功能
通过ShardingJDBC分布分表的功能,能够对一个数据库中的分片表进行读写操作。
开发环境
spring-boot-boot-starter 2.2.11.RELEASE、mybatis-plus-boot-starter 3.0.5、sharding-jdbc-spring-boot-starter 4.0.0-RC1
实现步骤
(1)配置pom依赖。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.11.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.yangnk</groupId>
<artifactId>ShardingJDBCDemo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ShardingJDBCDemo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>(2)配置文件application.properties,主要配置数据源、主键生成策略、分表策略等。
# sharding-jdbc 水平分表策略
# 配置数据源,给数据源起别名
spring.shardingsphere.datasource.names=m1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置数据源的具体内容,包含连接池,驱动,地址,用户名,密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://42.192.46.163:3306/test?serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=777777
# 指定course表分布的情况,配置表在哪个数据库里,表的名称都是什么 m1.course_1,m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
# 指定 course 表里面主键 cid 的生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 配置分表策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到 course_2 表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show=true
spring.shardingsphere.mode.type=Standalone
spring.shardingsphere.mode.repository.type=File
spring.shardingsphere.mode.overwrite=true
orithms.course_tbl_alg.props.algorithm-expression=course_$->{cid%2+1}配置中用到的Groovy表达式。 比如 m$->${0..1}.course_$->{1..2} 和 course_$->{cid%2+1} 。这是ShardingSphere支持的Groovy表达式,在后面会大量接触到这样的表达式。这个表达式中,$->{}部分为动态部分,大括号内的就是Groovy语句。 两个点,表示一个数据组的起点和终点。m$->${0..1}表示m0和m1两个字符串集合。course_$->{1..2}表示course_1和course_2集合。 course_$->{cid%2+1} 表示根据cid的值进行计算,计算的结果再拼凑上course_前缀。
(3)通过MyBatis-plus+MyBatisX插件根据表关系生成Mapper、domain、Service文件,其最后的代码目录为:

创建course表的分片表course_1和course_2,其sql脚本如下:
CREATE TABLE `course_1` (
`cid` bigint NOT NULL,
`cname` varchar(50) COLLATE utf8mb4_cs_0900_ai_ci NOT NULL,
`user_id` bigint NOT NULL,
`status` varchar(10) COLLATE utf8mb4_cs_0900_ai_ci NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_cs_0900_ai_ci;
CREATE TABLE `course_2` (
`cid` bigint NOT NULL,
`cname` varchar(50) COLLATE utf8mb4_cs_0900_ai_ci NOT NULL,
`user_id` bigint NOT NULL,
`status` varchar(10) COLLATE utf8mb4_cs_0900_ai_ci NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_cs_0900_ai_ci;通过创建单元测试类来进行分布分表功能验证,最终的效果是在course_1和course_2表中都有对应记录生成。
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.yangnk.shardingjdbcdemo.domain.Course;
import com.yangnk.shardingjdbcdemo.mapper.CourseMapper;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.util.List;
@SpringBootTest
public class ShardingJdbcDemoApplicationTest {
@Resource
private CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 0; i < 100; i++) {
Course course = new Course();
//cid由我们设置的策略,雪花算法进行生成
course.setCname("Java");
course.setUser_id(100L);
course.setStatus("Normal");
courseMapper.insert(course);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<Course>();
wrapper.eq("cid",1L);
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
} 
参考资料
为什么要分库分表:https://www.cnblogs.com/donleo123/p/17295667.html
使用 ShardingSphere 实操MySQL分库分表实战:https://segmentfault.com/a/1190000038241298
2-ShardingJDBC分库分表实战指南:https://note.youdao.com/ynoteshare/index.html?id=96778e1d8e6349062b4e2548e518c03f&type=note&_time=1696850841023
本文由博客一文多发平台 OpenWrite 发布!




![[MySQL]基础篇](https://img-blog.csdnimg.cn/d1197afd255c428ca50f4f4df6357e79.png)