前言:
Bash:是一个命令处理器,运行在文本窗口中,并能执行用户直接输入的命令。
Bash还能从文件中读取Linux命令,称之为脚本。
Bash支持通配符,管道,命令替换,条件判断等逻辑控制语句。
快捷命令:
history--历史命令
ctrl + a 移动到行首
ctrl + e 移动到行尾
ctrl +u 删除光标之前的字符
ctrl + k 删除光标之后的字符
ctrl + L 清空屏幕终内容,同于clear
Linux三剑客简介
文本处理工具,均支持正则表达式引擎
grep:文本过滤工具,(模式: pattern) 工具
sed: stream editor,流编辑器;文本编辑工具
awk: Linux的文本报告生成器 (格式化文本),Linux上是gawk
Linux 三剑客主要分两类:
基本正则表达式 BRE :
扩展正则表达式:ERE:
基本正则表达式
 扩展正则表达式
扩展正则表达式
 linux--grep:
linux--grep:
作用 文本搜索工具,根据用户指定的模式(过滤条件)对目标文本逐行进行匹配检查,打印匹配到的行。
模式:由正则表达式的元字符及文本字符所编写出的过滤条件。
 以下是测试用例:
以下是测试用例:
cat /etc/passwd > ./pwd.txt 打开文件放到当前目录下的文件中,没有则生成。
:set nu 显示行号
Grep ‘root’ a.txt 查找 文件中查找root
Grep ‘root’ a.txt -n 显示行号
Grep ‘root’ a.txt -n -I 忽略大小写
grep -i 'root' ./pwd.txt -n -c 带有root的有多少行。
grep '^$' luffy.txt -n 找到所用空行并显示行号
grep '^$' luffy.txt -n -v 反转,不要空行
grep '^#' luffy.txt -v | grep '^$' -n -v 取出没有注释的行,没有空行的行
grep -i '^i' luffy.txt -n 找出所有以i开头的行,忽略大小写了
grep '\.$' luffy.txt 找出所有的以点结尾的行
grep -n '/bin/bash$' pwd.txt 找出所有以 结尾的行
grep '.' luffy.txt 找出所有的非空行
grep 'i*' luffy.txt 没有i的也会匹配出来,因为是0次
grep 'i*' luffy.txt -o 找到每行含有i的次数 o是只显示要匹配的字符
grep 'i*' luffy.txt 全字符串匹配
grep '.*e' luffy.txt 贪婪匹配不管前面有什么,以e结尾就好了,
grep '[a-z]' luffy.txt 找出所有的小写英文字母
grep '[a-z0-9]' luffy.txt 找出所以的小写加数字
正则表达式扩展
egrep等价于 grep -E
+号表示匹配一个字符1次或者多次,必须使用grep -E 扩展正则
grep 'i+' luffy.txt -E 匹配所有带i的行,没有的不显示,和上面不一样
? 符 匹配前一个字符0次或者一次
grep 'go?d' test1.txt -E 找出gd 或者god
| 符号:
find /root -name '*.txt' 找出所有这个文件夹下面的txt结尾的文件
find /root -name '*.txt' | grep -E 'b|c' 再次过滤只要b或者c的
{} 将一个或者多个字符捆绑在一起,当作一个整体进行处理
grep -E 'g(oo|la)d' test1.txt 找出good或者glad
grep -E ‘(l..e).*\1’ a.txt 找出两个love或者like的,前后要一致
grep -E ‘y{2,4}’ a.txt -o 匹配y字符最少两次,最多4次
linux--sed
对文件或者数据流进行加工处理。是操作过滤和转换文本内容的强大工具。
sed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(patternspace ),接着用sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i。
功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作


sed '2,3p' luffycity.txt 打印23行,这样会全部输出
sed -n '2,3p' luffycity.txt 打印23行,
sed '2,+3p' luffycity.txt
sed '2,+3p' luffycity.txt -n 第二行,和下面的三行打印
sed '/linux/p' luffycity.txt 找出带有linux命令的行,这里会全部打印
sed '/linux/p' luffycity.txt -n 找出带有linux命令的行
sed '/game/d' luffycity.txt -n 删除带有game的行 这样是在内存中删除,文件没有删除。
sed '/game/d' luffycity.txt -I 在文件中删除
sed '5,$d' luffycity.txt -I 删除五行和之后的数据
sed 's/My/I/g' luffycity.txt 把my换成I 全部替换,这里只是在内存中更改,并不会写入到磁盘。
sed 's/My/I/g' luffycity.txt -I 替换
sed -e 's/I/My/g' -e 's/324324/100/g' luffycity.txt -I 替换两次文本内容
sed '2a woshinibabab' luffycity.txt -I 在第二行后面加一句话
sed '2i woshinibabab' luffycity.txt -I 在第二行前面加一句话
sed '2a woshinibabab.\nreerer' luffycity.txt -I 在第二行后面加2句话 ,注意没有空格
sed 'a --------' luffycity.txt -I 在每一行下面加上--------
ifconfig ens33 | sed '2p' -n | sed 's/^.*inet//' | sed 's/net.*$//' 只取出IP地址
# ifconfig ens33 | sed -e '2s/^.*inet//' -e '2s/net.*$//p' -n 只取出IP地址
,这里用的是替换
Linux--Awk
更适合编辑,处理匹配到的文本内容。是一个强大的Linux命令,有强大的文本格式华的能力,好比将一些文本数据格式化成专业的excel表的样式。更是一门编程语言,支持条件判断,数组,循环等功能。

awk '{print $0}' chaoge.txt 取出所有的列
awk '{print $1}' chaoge.txt 取出第一列
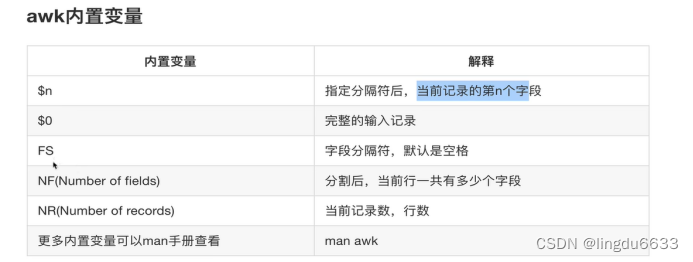
我们执行的命令是 awk ‘{print $2}’ 没有是使用参数,$2表示输出文本的第二列信息,
Awk默认以空格为分隔符,且多个空格也识别为一个空格,作为分隔符。
Awk是按行处理文件,一行处理完毕,处理下一行,根据用户指定的分隔符去工作,没有指定就是默认空格,制定了分隔符后,awk把每一行切割后的数据对应到内置变量。
awk '{print $1,$3,$4}' chaoge.txt 打印三列,逗号代表空格,不加就连在一起了。
awk '{print "第一列: " $1,$2}' chaoge.txt 前面加个标识,一定要用引号括起来

awk 'NR==5{print $0}' chaoge.txt 找到第几行
awk 'NR==1,NR==2{print $0}' chaoge.txt 找到两行,行数不能变
awk '{print NR, $0}' chaoge.txt NR 必须大写,带行号显示
awk '{print $1,$(NF-1)}' chaoge.txt 打印第一列和倒数第二列
awk '{print $1,NF}' chaoge.txt 打印第一列和列数
awk 'NR==2,NR==4{print $1}' a.txt 第1列的2-4行
ifconfig ens33 | awk 'NR==2{print $2}' 取出IP地址
输入分隔符:
awk -F ':' '{print $1}' pwd.txt 把该文件按照:分割开来取第一列
awk -F ':' '{print $1,$NF}' pwd.txt 取出第一列和最后一列
输出分隔符:
awk -F ':' '{print $1,$NF}' pwd.txt 取出第一列和最后一列,这里的逗号默认转换为空格
awk -F ':' -v OFS='====' '{print $1,$NF}' pwd.txt 按照:分隔开,输出之间用====

awk '{print NR,$0}' a.txt luffy.txt 当成一个文件输出 且显示行号
awk '{print FNR,$0}' a.txt luffy.txt 当成两个文件输出且显示行号
awk -v RS=' ' '{print NR,$0}' a.txt 以空格为换行符来打印
awk -v ORS='------ ' '{print NR,$0}' a.txt 每行后面输出的时候加上-----
awk '{print FILENAME,$0}' a.txt 带文件名打印输出
awk 'BEGIN{print "aaaa"} {print $0}' a.txt 打印之前先输出aaaa
awk 'BEGIN{print "aaaa"} {print ARGV[1],$0}' a.txt 括号里面0代表awk命令,1代表文件名
awk -v myname='aaa' 'BEGIN{print "wode mingizshi ",myname}' 自定义变量,然后输出
awk ‘{print $0}’ a.txt 等价于下面:
awk ‘{printf “%s\n”,$0}” a.txt