在之前的文章中 FiBiNet&FiBiNet++模型,阐述了微博在CTR特征(Embedding)重要性建模方面的一些实践方向,今天再来学习下这个方面的两个相关研究:致力于特征和特征交互精炼(refine)的ContextNet和MaskNet,其中MaskNet也是Twitter(推特)使用的精排模型底座。
ContextNet
论文:ContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding
地址:https://arxiv.org/pdf/2107.12025.pdf
受NLP领域的启发,如ELMO和BERT,word embedding是可以通过上下文的句子信息进行动态精炼(refine)的,这延伸到CTR任务,这种方法是否仍然可行呢?
如果可行的话,那么我们就能够通过这个方式来高效地捕获有用的特征交互。基于这个动机,论文提出了ContextNet的框架,依靠输入的上下文信息来对feature embedding进行一层一层地动态提炼,从而完成隐式的高阶特征交互。
ContextNet包含两个关键的组件:
- contextual embedding module: 从输入实例为每个特征聚合上下文的信息
- ContextNet block: 一层一层地维持feature embedding的同时,将上下文的高阶交叉信息合并到feature embedding,从而实现特征动态提炼。
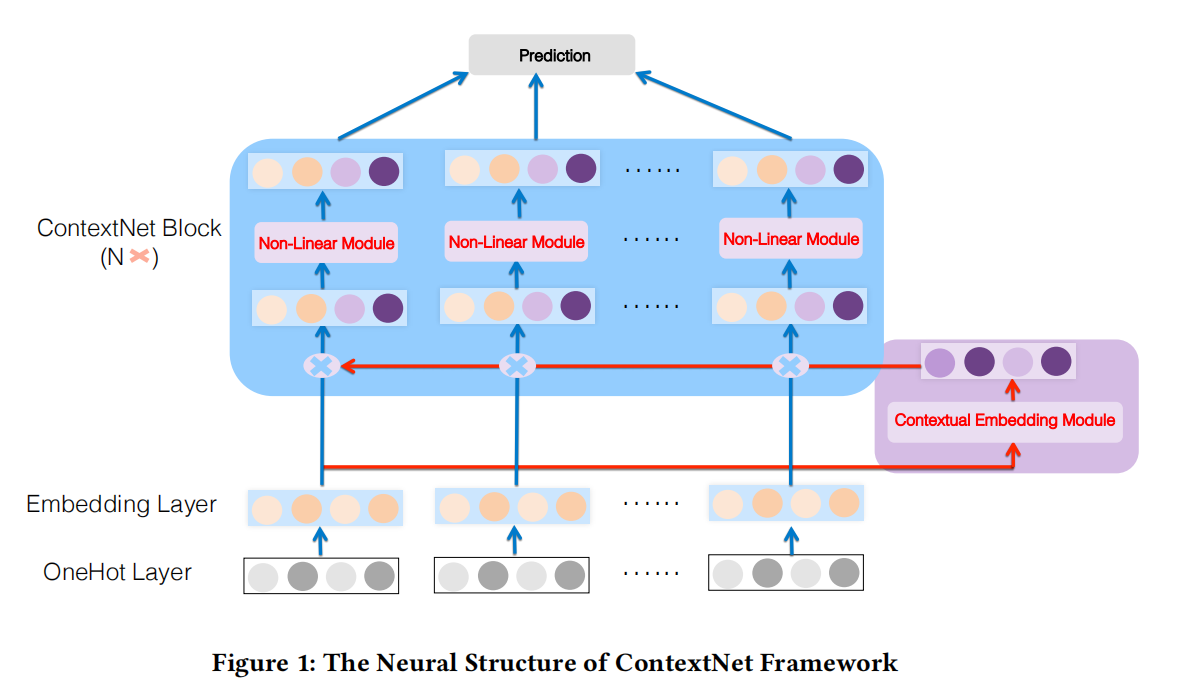
ContextNet结构如上图所示。
Embedding Layer.
最底层的feature embedding layer仍然是常规的做法:离散特征输入经过one-hot,然后经过Embedding Layer映射到低维的embedding,而数值特征输入则是与对应的field embedding相乘。
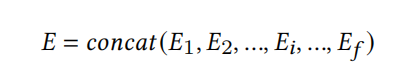
Contextual Embedding
如上所述,Contextual Embedding模块有两个目标:为每个特征聚合上下文信息、将汇聚的上下文信息映射到feature embedding所在的低维向量空间,这个过程可以表达为下式:
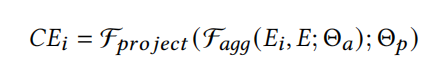
- C E i ∈ R k CE_i \in \mathbb{R}^k CEi∈Rk代表第i个特征 E i E_i Ei的contextual embedding,k是field embedding的维度大小。
- F a g g ( E i , E ; Θ a ) \mathcal{F}_{agg}(E_i,E;\Theta_a) Fagg(Ei,E;Θa)是第i个特征的上下文信息聚合函数,即aggregation model,使用了Embedding Layer的输出E和feature embedding E i E_i Ei作为输入;
- F p r o j e c t ( F a g g ; Θ p ) \mathcal{F}_{project}(\mathcal{F}_{agg};\Theta_p) Fproject(Fagg;Θp) 则则是一个映射函数,即projection model,将聚合后的上下文信息 F a g g \mathcal{F}_{agg} Fagg投影到feature embedding所在的低维空间。
- Θ a , Θ p \Theta_a,\Theta_p Θa,Θp分别是aggregation model和projection model的参数。

如上图,论文采用了两层的前馈网络来分别作为聚合函数 F a g g ( E i , E ; Θ a ) \mathcal{F}_{agg}(E_i,E;\Theta_a) Fagg(Ei,E;Θa)和映射函数 F p r o j e c t ( F a g g ; Θ p ) \mathcal{F}_{project}(\mathcal{F}_{agg};\Theta_p) Fproject(Fagg;Θp),称为two-layer contextual embedding network (TCE),可以表达为下式:

其中, E ∈ R m = f × k E \in \mathbb{R}^{m=f \times k} E∈Rm=f×k,并假定特征 E i E_i Ei属于field d:
- 第一层前馈网络即全连接网络(FC layers)是聚合网络,是一个相对更宽的网络层,为了能够更好从Embedding Layer收集到上下文信息,其参数为 W d a ∈ R t × m W_d^a \in \mathbb{R}^{t \times m} Wda∈Rt×m;
- 第二层FC layers是映射网络,将上下文信息投影到feature embedding所在的低维空间,其参数为 W d p ∈ R k × t W_d^p \in \mathbb{R}^{k \times t} Wdp∈Rk×t
为了平衡模型的能力和复杂度,论文使用了这样的参数策略:所有特征共享聚合网络的参数A,而映射网络则是每个特征独享自己的参数P,因为聚合网络是比较宽的网络层,其计算复杂度是比较高的。这也是根据实验结果选择的最优策略:
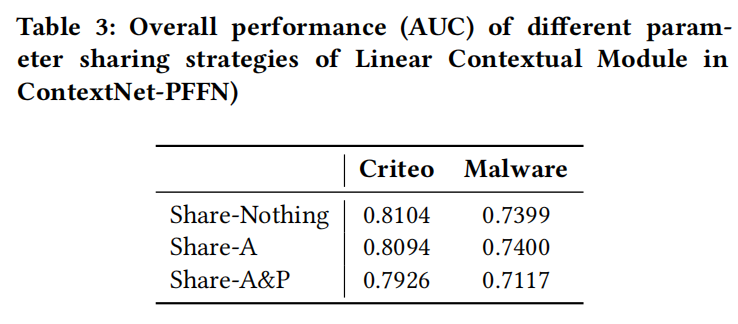
ContextNet Block
ContextNet Block是为了动态提炼每个feature embedding来达到隐式捕获高阶特征交互,通过合并特征的contextual embedding的方式。
如上图[ContextNet结构],ContextNet block包括两个步骤:merge embedding和non-linear transformations。并且ContextNet block是多层的,可以一个block接着一个block堆起来,即上一个block的输出是下一个block的输入,可以表达为下式:
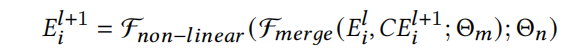
-
E
i
l
E^l_i
Eil代表第i个特征在第
l
l
l层block的输出,
C
E
i
l
+
1
CE^{l+1}_i
CEil+1代表第i个特征在第
l
+
1
l+1
l+1层block的由TCE
计算得到的contextual embedding - E i l + 1 ∈ R k E^{l+1}_i \in \mathbb{R}^k Eil+1∈Rk则是通过第 l + 1 l+1 l+1层ContextNet block微调之后的第i个特征的feature embedding,k是field embedding的维度大小
- F m e r g e ( E i l , C E i l + 1 ; Θ m ) \mathcal{F}_{merge}(E^l_i,CE^{l+1}_i;\Theta_m) Fmerge(Eil,CEil+1;Θm)是一个合并函数,使用上一层block的输出 E i l E^l_i Eil和contextual embedding C E i l + 1 CE^{l+1}_i CEil+1作为输入,论文使用了没有参数 Θ m \Theta_m Θm的Hadamard product(阿达玛积),如下式:
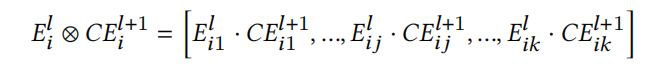
而 F n o n − l i e a n r ( F m e r g e ; Θ n ) \mathcal{F}_{non-lieanr}(\mathcal{F}_{merge};\Theta_n) Fnon−lieanr(Fmerge;Θn)则是一个映射函数,对merge embedding进行了non-linear transformation,从而更深入捕获第i个特征的高阶交互。论文提出了两种形式point-wise feed-forward network、single-layer feed-forward network,如下图所示:
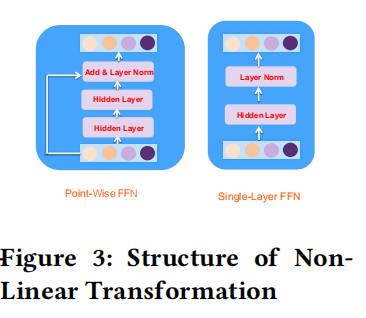
Point-Wise FFN
如上图[Non-Linear Transformation]左边的Point-Wise FFN所示,其实就是由两层FC layers+残差连接+layer normalization(LN),如下式:

其中, W 1 , W 2 ∈ R k × k W^1,W^2 \in \mathbb{R}^{k \times k} W1,W2∈Rk×k,并且在整个FFN网络中是共享的参数。
Single-Layer FFN
如上图[Non-Linear Transformation]左边的Single-Layer FNN,也正如它的名字,是一层单层网络的版本,即一层FC layers+layer normalization(LN),如下式:
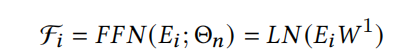
同样, W 1 ∈ R k × k W^1 \in \mathbb{R}^{k \times k} W1∈Rk×k,在整个FFN网络中也是共享的参数。
MaskNet
论文:MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask
地址:https://arxiv.org/pdf/2102.07619.pdf
一些研究如Alex Beutel et.al证明了加法的(addictive)特征交互,比如标准的feed-forward neural networks即DNN,在捕获通用(common)的特征交互方面是低效的。
为了解决这个问题,论文通过instance-guided mask,引入了乘法(multiplicative)操作:
- 它对feature embedding和feed-foward layers都应用了element-wise product;
- 利用从输入实例收集的全局信息,以统一范式来动态地强调feature embedding和隐藏层中含有有用信息的elements;
- 同时,通过输入实例的指导,它属于一种有效的bit-wise attention,能够削弱feature embedding和MLP layers的噪声影响。
MaskBlock将feed-forward layer转化为加法和乘法混合的特征交叉:结合instance-guided mask的同时,仍然保留feed-forward layer和layer normalization。
Embedding Layer.
底层的feature embedding layer仍是常规做法,与ContextNet一致,不再赘述。
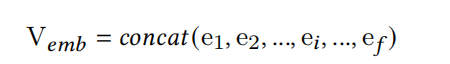
Instance-Guided Mask
如上所述,论文实现了利用从输入实例收集的全局信息,来动态地强调feature embedding和隐藏层中含有有用信息的elements,而关键就是这个输入实例指导的掩码(mask):
- 对于feature embedding,mask会强调那些含有更多信息的关键elements,以此来更高效地表征每个特征;
- 对于隐藏层,mask会帮助那些重要的特征交互更为突出即更被重视。
如下图所示,论文使用了与上面contextual embedding相同的结构来计算这个mask:总共两层的FC layers,一层较宽的聚合网络+一层降维的投影网络。
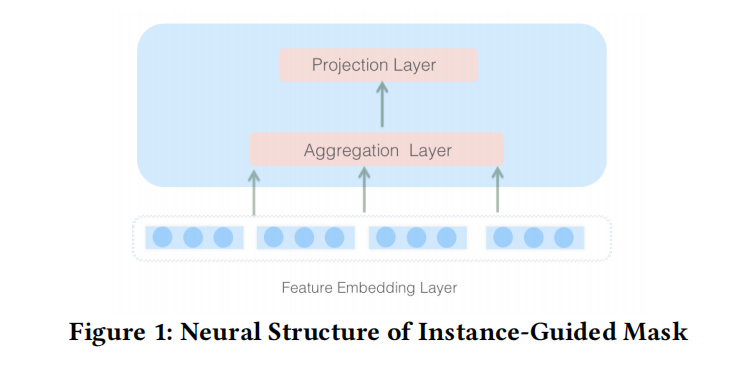

其中, V e m b ∈ R m = f × k , W d 1 ∈ R t × m , W d 2 ∈ R z × t V_{emb} \in \mathbb{R}^{m=f \times k},W_{d1} \in \mathbb{R}^{t \times m},W_{d2} \in \mathbb{R}^{z \times t} Vemb∈Rm=f×k,Wd1∈Rt×m,Wd2∈Rz×t。并且定义超参数reduction ratio r = t / z r=t/z r=t/z。
得到mask之后,就可以增强feature embedding和隐藏层中那些重要的elements,使用的方法是点积element-wise product,更重要的elements,mask对应位置的数值就会更大:
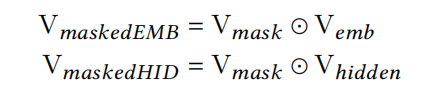
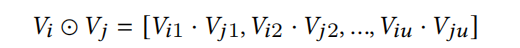
从上述表达式,确实可以理解为一种bit-wise attention,并且feature embedding和隐藏层拥有各自的实例指导mask。
MaskBlock
为了克服feed-forward layer捕获复杂的特征交互低效问题,提出了MaskBlock这种基础组件,如下如所示,MaskBlock包含了:
- 有利于模型训练优化的layer normalization
- 为feed-forward layer引入乘法操作的instance-guided mask
- 聚合masked的信息,来更好地捕获重要特征交互的feed-forward layer
Layer Normalization
这里可以重温下layer normalization的知识,如下式:
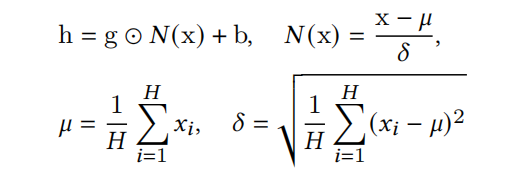
让 x = ( x 1 , x 2 , . . . , x H ) x=(x_1,x_2,...,x_H) x=(x1,x2,...,xH)是size为H的向量表征。h是LN的输出, ⊙ \odot ⊙是点积操作(element-wise product), μ \mu μ和 δ \delta δ是输入x的均值和标准差。bias b b b和gain g g g则是需要学习的参数。
应用到feature embedding和隐藏层则分别对应以下:
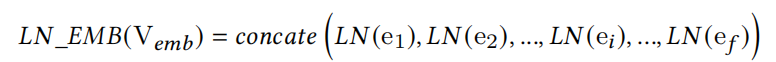
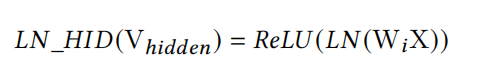
对于MLP隐藏层的LN,其实是有两个可选位置的:非线性操作(即ReLU)之前和非线性操作之后,选择放在ReLU是因为其实验效果更佳的。
MaskBlock结构
MaskBlock也可以像普通的MLP或者Transformer那样堆叠更加深度的网络,因此MaskBlock跟ContextNet一样,即可以接收feature embedding作为输入,也可以接收上一层MaskBlock的输出。
前面也提到,MaskBlock包含了三个关键的组件:layer normalization、instance-guided mask、feed-forward layer,也正是因为这三个关键的操作,才能将只含加法操作的标准DNN转化为加法混合乘法操作的特征交互。
MaskBlock on Feature Embedding.
接收feature embedding作为输入的MaskBlock当然也不例外,如下图所示:

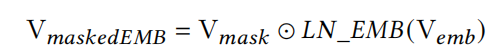
MaskBlock利用instance-guided mask V m a s k V_{mask} Vmask来重点突出 V e m b V_{emb} Vemb中更富含信息的元素,通过点积的方式element-wise product即 ⊙ \odot ⊙ 。
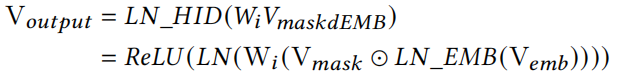
接着,再引入一个feed-forward layer和LN操作,来更好聚合masked之后的信息。其中 W i ∈ R q × n W_i \in \mathbb{R}^{q \times n} Wi∈Rq×n表示第i层MaskBlock中的feed-forward layer参数,n是 V m a s k e d E M B V_{maskedEMB} VmaskedEMB是维度,q是feed-forward layer的神经元数量,即隐藏层的输出维度。
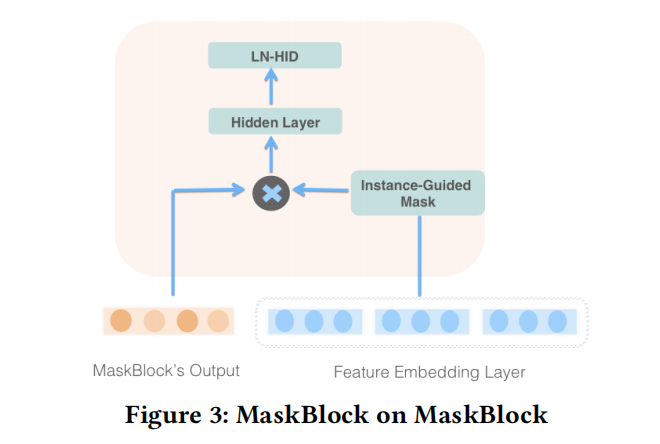
MaskBlock on MaskBlock.
而进行堆叠的MaskBlock结构(即MaskBlock on MaskBlock)基本与MaskBlock on Feature Embedding一样:
- 先通过instance-guided mask V m a s k V_{mask} Vmask来highlight上一层MaskBlock输出中重要的特征交互,
- 然后再引入一个feed-forward layer和LN操作来更好地捕获特征交互。
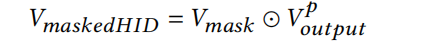

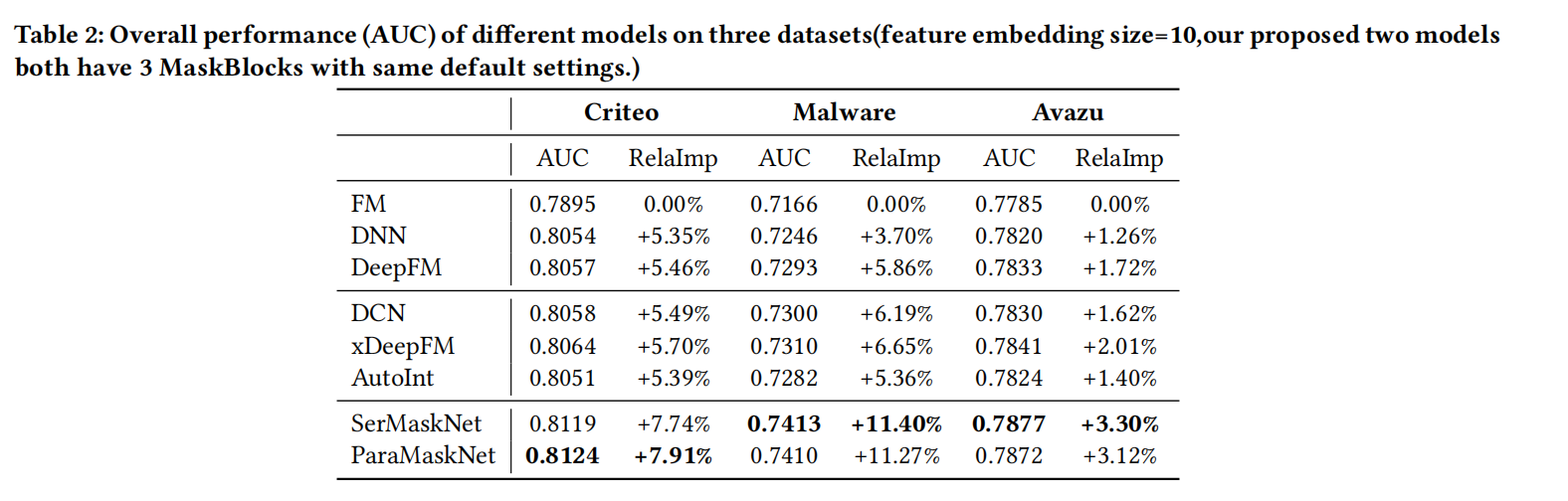
串行和并行结构
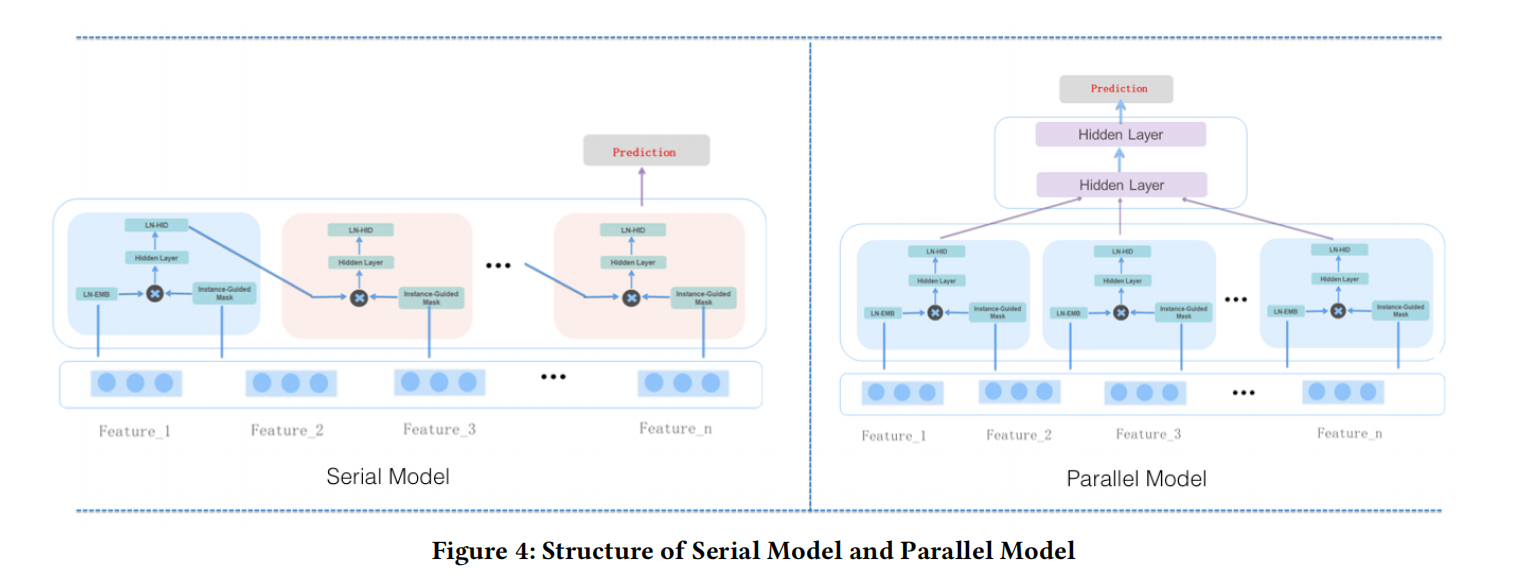
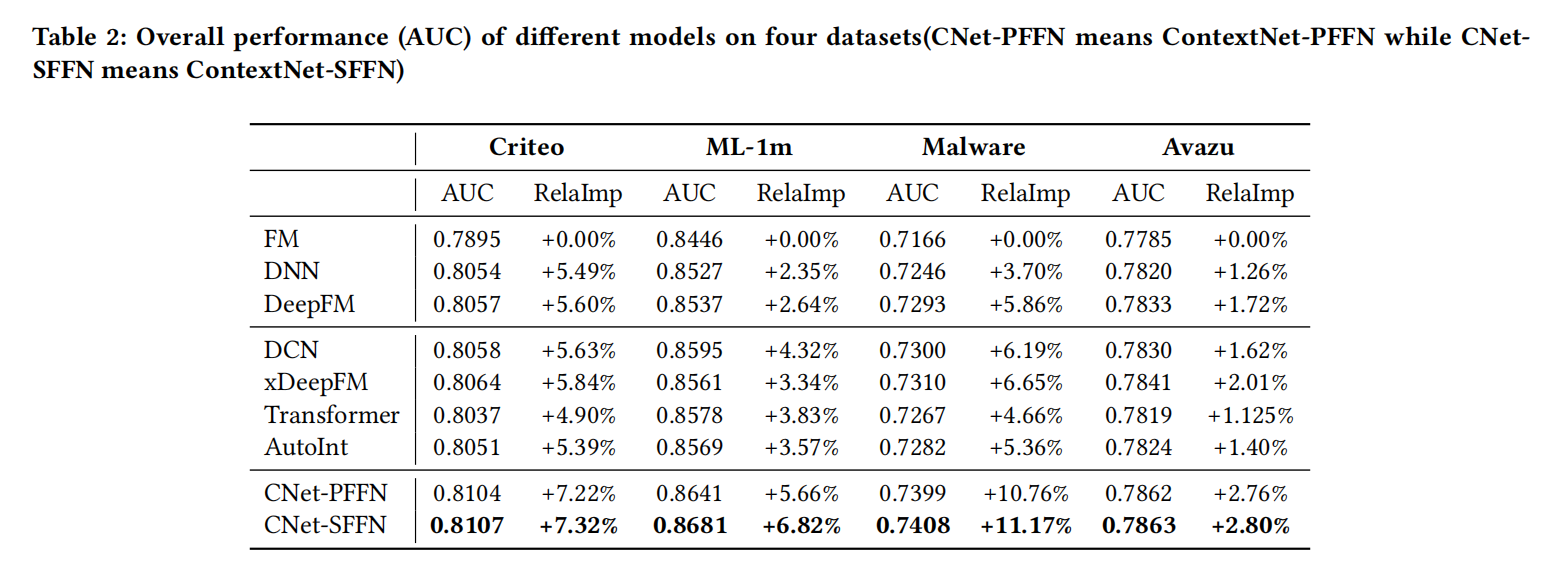
如上图所示,论文提出了两种不同结构的MaskNet:串行(Serial) MaskNet和并行(Parallel) MaskNet。
Serial MaskNet则是像上述提到的堆叠起来的MaskBlock:
- 第一层是MaskBlock on feature embedding即接收feature embedding作为输入的MaskBlock
- 后面的其他层则是都是接收上一层MaskBlock输出作为输入的MaskBlock on MaskBlock
- 但是所有层的MaskBlock的instance-guided mask都是通过feature embedding计算而来
- 其结构类似于每个time step都共享输入的RNN模型
Parallel MaskNet则是像MMoe结构,共享feature embedding layer,多个MaskBlock像多个Expert一样,关注各自不同类型的特征交互,然后再汇聚多个MaskBlock的输出,如下式:
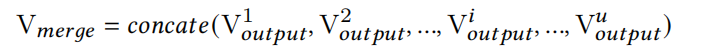
V o u t p u t i ∈ R q V^i_{output} \in \mathbb{R}^q Voutputi∈Rq对应第i个MaskBlock的输出。
为了更深入地合并每个expert即MaskBlock捕获的特征交互,后面再引入多个feed-forward layer。令 H 0 = V m e r g e H_0=V_{merge} H0=Vmerge,其输出如下式:
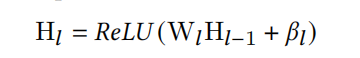
后面的Prediction Layer则与常规的CTR模型无异。
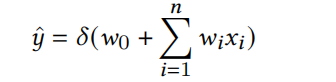
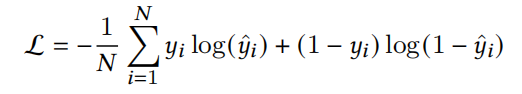
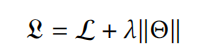
总结
受NLP领域(如ELMO和BERT)的启发,word embedding可以通过上下文的句子信息进行动态精炼(refine)的,这种思想可以延伸到CTR任务,通过输入的上下文信息来指导每一层网络的特征交互捕获。
- ContextNet使用Contextual Embedding作为指导,将高阶交叉信息合并进去feature embedding;
- ContextNet更像BERT或Transformer,一层一层地维护和精炼(refine)feature embedding;
- MaskNet则是使用Instance-Guided Mask作为指导,但不同的是MaskNet致力于指导highlight每一层中重要的特征交互,每一层都进行深度的特征交互捕获,而不是refine feature embedding;
- 并且MaskNet还提出了类似MMoE并行的结构,即共享feature embedding layer,多个MaskBlock承担多个expert的角色同时计算各自的部分。
代码实现
git:ContextNet、MaskNet