分类目录:《深入理解强化学习》总目录
为什么我们关注强化学习,其中非常重要的一个原因就是强化学习得到的模型可以有超人类的表现。 有监督学习获取的监督数据,其实是人来标注的,比如ImageNet的图片的标签都是人类标注的。因此我们可以确定监督学习算法的上限(Upper Bound)就是人类的表现,标注结果决定了它的表现永远不可能超越人类。但是对于强化学习,它在环境里面自己探索,有非常大的潜力,它可以获得超越人类的能力的表现,比如DeepMind的AlphaGo这样一个强化学习的算法可以把人类顶尖的棋手打败。下面就给大家举一些在现实生活中强化学习的例子:
- 在自然界中,羚羊其实也在做强化学习。它刚刚出生的时候,可能都不知道怎么站立,然后它通过试错,一段时间后就可以跑得很快,可以适应环境。
- 我们也可以把股票交易看成强化学习的过程。我们可以不断地买卖股票,然后根据市场给出的反馈来学会怎么去买卖可以让我们的奖励最大化。
- 玩雅达利游戏或者其他电脑游戏,也是一个强化学习的过程,我们可以通过不断试错来知道怎么 玩才可以通关。
如下图所示为强化学习的一个经典例子,即雅达利的Pong游戏。游戏中右边的选手把球拍到左边, 然后左边的选手需要把球拍到右边。训练好的强化学习智能体和正常的选手有区别:强化学习的智能体会一直做无意义的振动,而正常的选手不会做出这样的动作。
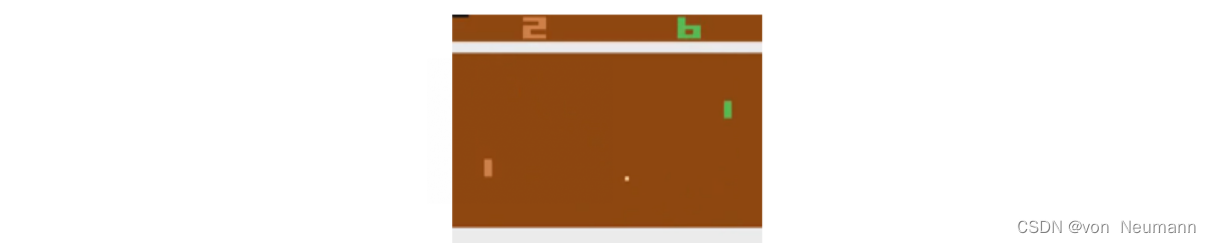
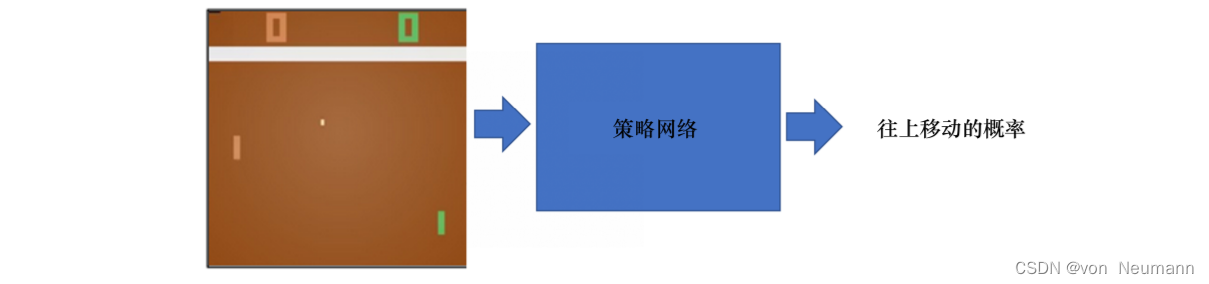
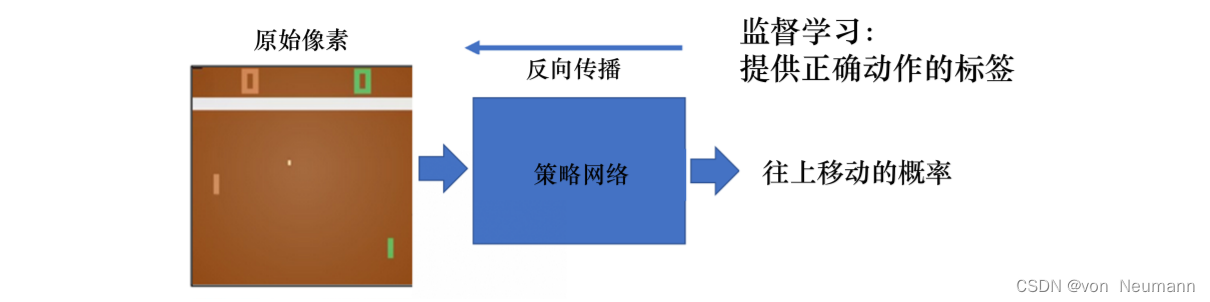
在Pong游戏里面,其实只有两个动作:往上或者往下。如下图所示,如果强化学习通过学习一个策略网络来进行分类,那么策略网络会输入当前帧的图片,输出所有决策的可能性,比如往上移动的概率。
如下图所示,对于监督学习,我们可以直接告诉智能体正确动作的标签是什么。但在 Pong 游戏中, 我们并不知道它的正确动作的标签是什么。
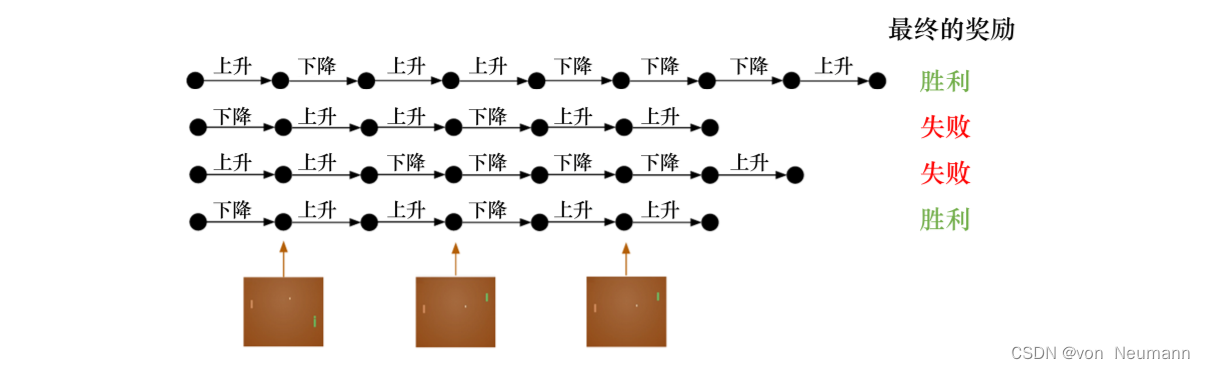
在强化学习里面,我们让智能体尝试玩Pong游戏,对动作进行采样,直到游戏结束,然后对每个动作进行惩罚。下图所示为预演(Rollout)的一个过程。预演是指我们从当前帧对动作进行采样,生成很多局游戏。我们将当前的智能体与环境交互,会得到一系列观测。每一个观测可看成一个轨迹(Trajectory)。 轨迹就是当前帧以及它采取的策略,即状态和动作的序列:
τ
=
(
s
0
,
a
0
,
s
1
,
a
1
,
⋯
)
\tau=(s_0, a_0, s_1, a_1, \cdots)
τ=(s0,a0,s1,a1,⋯)
最后结束时,我们会知道到底有没有把这个球拍到对方区域,对方有没有接住,我们是赢了还是输了。我们可以通过观测序列以及最终奖励(Eventual Reward)来训练智能体,使它尽可能地采取可以获得最终奖励的动作,一场游戏称为一个回合(Episode)或者试验(Trial)。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022