代码:https://github.com/OFA-Sys/Chinese-CLIP/blob/master/deployment.md
文章目录
- 安装环境和onnx推理
- 转换所有模型为onnx
- 测试所有onnx模型的脚本
- onnx cpu方式执行
- docker镜像
安装环境和onnx推理
安装环境,下载权重放置到指定目录,进行onnx转换:
conda create -n clip_cn python=3.8 -y
conda activate clip_cn
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge -y
conda install numpy tqdm six -y
conda install -c conda-forge timm -y
conda install -c anaconda lmdb==1.3.0 -y
cd Chinese-CLIP
pip install -e .
mkdir DATAPATH
export CUDA_VISIBLE_DEVICES=0
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip
export DATAPATH="./DATAPATH"
checkpoint_path=${DATAPATH}/pretrained_weights/clip_cn_vit-b-16.pt # 指定要转换的ckpt完整路径
echo checkpoint_path
echo $checkpoint_path
mkdir -p ${DATAPATH}/deploy/ # 创建ONNX模型的输出文件夹
pip install onnx onnxruntime-gpu onnxmltools
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch ViT-B-16 \
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path ${DATAPATH}/deploy/vit-b-16 \
--convert-text --convert-vision
转换成功后:
Finished PyTorch to ONNX conversion...
>>> The text FP32 ONNX model is saved at ./DATAPATH/deploy/vit-b-16.txt.fp32.onnx
>>> The text FP16 ONNX model is saved at ./DATAPATH/deploy/vit-b-16.txt.fp16.onnx with extra file ./DATAPATH/deploy/vit-b-16.txt.fp16.onnx.extra_file
>>> The vision FP32 ONNX model is saved at ./DATAPATH/deploy/vit-b-16.img.fp32.onnx
>>> The vision FP16 ONNX model is saved at ./DATAPATH/deploy/vit-b-16.img.fp16.onnx with extra file ./DATAPATH/deploy/vit-b-16.img.fp16.onnx.extra_file
可以看到转换好的文件:
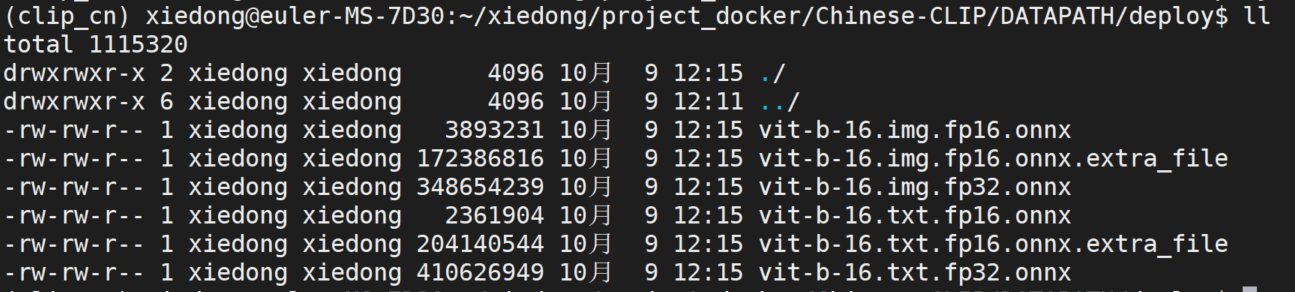
测试是否转换成功的python代码:
# 完成必要的import(下文省略)
import onnxruntime
from PIL import Image
import numpy as np
import torch
import argparse
import cn_clip.clip as clip
from clip import load_from_name, available_models
from clip.utils import _MODELS, _MODEL_INFO, _download, available_models, create_model, image_transform
# 载入ONNX图像侧模型(**请替换${DATAPATH}为实际的路径**)
img_sess_options = onnxruntime.SessionOptions()
img_run_options = onnxruntime.RunOptions()
img_run_options.log_severity_level = 2
img_onnx_model_path="./DATAPATH/deploy/vit-b-16.img.fp16.onnx"
img_session = onnxruntime.InferenceSession(img_onnx_model_path,
sess_options=img_sess_options,
providers=["CUDAExecutionProvider"])
# 预处理图片
model_arch = "ViT-B-16" # 这里我们使用的是ViT-B-16规模,其他规模请对应修改
preprocess = image_transform(_MODEL_INFO[model_arch]['input_resolution'])
# 示例皮卡丘图片,预处理后得到[1, 3, 分辨率, 分辨率]尺寸的Torch Tensor
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0)
# 用ONNX模型计算图像侧特征
image_features = img_session.run(["unnorm_image_features"], {"image": image.cpu().numpy()})[0] # 未归一化的图像特征
image_features = torch.tensor(image_features)
image_features /= image_features.norm(dim=-1, keepdim=True) # 归一化后的Chinese-CLIP图像特征,用于下游任务
print(image_features.shape) # Torch Tensor shape: [1, 特征向量维度]
# 载入ONNX文本侧模型(**请替换${DATAPATH}为实际的路径**)
txt_sess_options = onnxruntime.SessionOptions()
txt_run_options = onnxruntime.RunOptions()
txt_run_options.log_severity_level = 2
txt_onnx_model_path="./DATAPATH/deploy/vit-b-16.txt.fp16.onnx"
txt_session = onnxruntime.InferenceSession(txt_onnx_model_path,
sess_options=txt_sess_options,
providers=["CUDAExecutionProvider"])
# 为4条输入文本进行分词。序列长度指定为52,需要和转换ONNX模型时保持一致(参见转换时的context-length参数)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"], context_length=52)
# 用ONNX模型依次计算文本侧特征
text_features = []
for i in range(len(text)):
one_text = np.expand_dims(text[i].cpu().numpy(),axis=0)
text_feature = txt_session.run(["unnorm_text_features"], {"text":one_text})[0] # 未归一化的文本特征
text_feature = torch.tensor(text_feature)
text_features.append(text_feature)
text_features = torch.squeeze(torch.stack(text_features),dim=1) # 4个特征向量stack到一起
text_features = text_features / text_features.norm(dim=1, keepdim=True) # 归一化后的Chinese-CLIP文本特征,用于下游任务
print(text_features.shape) # Torch Tensor shape: [4, 特征向量维度]
# 内积后softmax
# 注意在内积计算时,由于对比学习训练时有temperature的概念
# 需要乘上模型logit_scale.exp(),我们的预训练模型logit_scale均为4.6052,所以这里乘以100
# 对于用户自己的ckpt,请使用torch.load载入后,查看ckpt['state_dict']['module.logit_scale']或ckpt['state_dict']['logit_scale']
logits_per_image = 100 * image_features @ text_features.t()
print(logits_per_image.softmax(dim=-1)) # 图文相似概率: [[1.2252e-03, 5.2874e-02, 6.7116e-04, 9.4523e-01]]
转换所有模型为onnx

# ["RN50", "ViT-B-16", "ViT-L-14", "ViT-L-14-336", "ViT-H-14"]
checkpoint_path=${DATAPATH}/pretrained_weights/clip_cn_rn50.pt
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch RN50 \
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path ${DATAPATH}/deploy/RN50 \
--convert-text --convert-vision
checkpoint_path=${DATAPATH}/pretrained_weights/clip_cn_vit-b-16.pt
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch ViT-B-16 \
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path ${DATAPATH}/deploy/ViT-B-16 \
--convert-text --convert-vision
checkpoint_path=${DATAPATH}/pretrained_weights/clip_cn_vit-l-14.pt
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch "ViT-L-14"\
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path ${DATAPATH}/deploy/ViT-L-14 \
--convert-text --convert-vision
checkpoint_path=${DATAPATH}/pretrained_weights/clip_cn_vit-l-14-336.pt
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch "ViT-L-14-336"\
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path ${DATAPATH}/deploy/ViT-L-14-336 \
--convert-text --convert-vision
checkpoint_path=${DATAPATH}/pretrained_weights/clip_cn_vit-h-14.pt
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch "ViT-H-14"\
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path ${DATAPATH}/deploy/ViT-H-14 \
--convert-text --convert-vision
测试所有onnx模型的脚本
# 完成必要的import(下文省略)
import onnxruntime
from PIL import Image
import numpy as np
import torch
import argparse
import cn_clip.clip as clip
from clip import load_from_name, available_models
from clip.utils import _MODELS, _MODEL_INFO, _download, available_models, create_model, image_transform
model_list=["RN50", "ViT-B-16", "ViT-L-14", "ViT-L-14-336", "ViT-H-14"]
for model_name in model_list:
print(model_name)
# 载入ONNX图像侧模型(**请替换${DATAPATH}为实际的路径**)
img_sess_options = onnxruntime.SessionOptions()
img_run_options = onnxruntime.RunOptions()
img_run_options.log_severity_level = 2
img_onnx_model_path=f"./DATAPATH/deploy/{model_name}.img.fp16.onnx"
img_session = onnxruntime.InferenceSession(img_onnx_model_path,
sess_options=img_sess_options,
providers=["CUDAExecutionProvider"])
# 预处理图片
model_arch = model_name # 这里我们使用的是ViT-B-16规模,其他规模请对应修改
preprocess = image_transform(_MODEL_INFO[model_arch]['input_resolution'])
# 示例皮卡丘图片,预处理后得到[1, 3, 分辨率, 分辨率]尺寸的Torch Tensor
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0)
# 用ONNX模型计算图像侧特征
image_features = img_session.run(["unnorm_image_features"], {"image": image.cpu().numpy()})[0] # 未归一化的图像特征
image_features = torch.tensor(image_features)
image_features /= image_features.norm(dim=-1, keepdim=True) # 归一化后的Chinese-CLIP图像特征,用于下游任务
print(image_features.shape) # Torch Tensor shape: [1, 特征向量维度]
# 载入ONNX文本侧模型(**请替换${DATAPATH}为实际的路径**)
txt_sess_options = onnxruntime.SessionOptions()
txt_run_options = onnxruntime.RunOptions()
txt_run_options.log_severity_level = 2
txt_onnx_model_path=f"./DATAPATH/deploy/{model_name}.txt.fp16.onnx"
txt_session = onnxruntime.InferenceSession(txt_onnx_model_path,
sess_options=txt_sess_options,
providers=["CUDAExecutionProvider"])
# 为4条输入文本进行分词。序列长度指定为52,需要和转换ONNX模型时保持一致(参见转换时的context-length参数)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"], context_length=52)
# 用ONNX模型依次计算文本侧特征
text_features = []
for i in range(len(text)):
one_text = np.expand_dims(text[i].cpu().numpy(),axis=0)
text_feature = txt_session.run(["unnorm_text_features"], {"text":one_text})[0] # 未归一化的文本特征
text_feature = torch.tensor(text_feature)
text_features.append(text_feature)
text_features = torch.squeeze(torch.stack(text_features),dim=1) # 4个特征向量stack到一起
text_features = text_features / text_features.norm(dim=1, keepdim=True) # 归一化后的Chinese-CLIP文本特征,用于下游任务
print(text_features.shape) # Torch Tensor shape: [4, 特征向量维度]
# 内积后softmax
# 注意在内积计算时,由于对比学习训练时有temperature的概念
# 需要乘上模型logit_scale.exp(),我们的预训练模型logit_scale均为4.6052,所以这里乘以100
# 对于用户自己的ckpt,请使用torch.load载入后,查看ckpt['state_dict']['module.logit_scale']或ckpt['state_dict']['logit_scale']
logits_per_image = 100 * image_features @ text_features.t()
print(logits_per_image.softmax(dim=-1)) # 图文相似概率: [[1.2252e-03, 5.2874e-02, 6.7116e-04, 9.4523e-01]]
onnx cpu方式执行
环境:
conda create -n clip_cn_cpu python=3.8 -y
conda activate clip_cn_cpu
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cpuonly -c pytorch -y
conda install numpy tqdm six -y
conda install -c conda-forge timm -y
conda install -c anaconda lmdb==1.3.0 -y
cd Chinese-CLIP
pip install -e .
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip
pip install onnx onnxruntime onnxmltools
测试脚本:
# 完成必要的import(下文省略)
import onnxruntime
from PIL import Image
import numpy as np
import torch
import argparse
import cn_clip.clip as clip
from clip import load_from_name, available_models
from clip.utils import _MODELS, _MODEL_INFO, _download, available_models, create_model, image_transform
model_list=["RN50", "ViT-B-16", "ViT-L-14", "ViT-L-14-336", "ViT-H-14"]
for model_name in model_list:
print(model_name)
# 载入ONNX图像侧模型(**请替换${DATAPATH}为实际的路径**)
img_sess_options = onnxruntime.SessionOptions()
img_run_options = onnxruntime.RunOptions()
img_run_options.log_severity_level = 2
img_onnx_model_path=f"./DATAPATH/deploy/{model_name}.img.fp16.onnx"
img_session = onnxruntime.InferenceSession(img_onnx_model_path,
sess_options=img_sess_options,
providers=["CPUExecutionProvider"])
# 预处理图片
model_arch = model_name # 这里我们使用的是ViT-B-16规模,其他规模请对应修改
preprocess = image_transform(_MODEL_INFO[model_arch]['input_resolution'])
# 示例皮卡丘图片,预处理后得到[1, 3, 分辨率, 分辨率]尺寸的Torch Tensor
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0)
# 用ONNX模型计算图像侧特征
image_features = img_session.run(["unnorm_image_features"], {"image": image.cpu().numpy()})[0] # 未归一化的图像特征
image_features = torch.tensor(image_features)
image_features /= image_features.norm(dim=-1, keepdim=True) # 归一化后的Chinese-CLIP图像特征,用于下游任务
print(image_features.shape) # Torch Tensor shape: [1, 特征向量维度]
# 载入ONNX文本侧模型(**请替换${DATAPATH}为实际的路径**)
txt_sess_options = onnxruntime.SessionOptions()
txt_run_options = onnxruntime.RunOptions()
txt_run_options.log_severity_level = 2
txt_onnx_model_path=f"./DATAPATH/deploy/{model_name}.txt.fp16.onnx"
txt_session = onnxruntime.InferenceSession(txt_onnx_model_path,
sess_options=txt_sess_options,
providers=["CPUExecutionProvider"])
# 为4条输入文本进行分词。序列长度指定为52,需要和转换ONNX模型时保持一致(参见转换时的context-length参数)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"], context_length=52)
# 用ONNX模型依次计算文本侧特征
text_features = []
for i in range(len(text)):
one_text = np.expand_dims(text[i].cpu().numpy(),axis=0)
text_feature = txt_session.run(["unnorm_text_features"], {"text":one_text})[0] # 未归一化的文本特征
text_feature = torch.tensor(text_feature)
text_features.append(text_feature)
text_features = torch.squeeze(torch.stack(text_features),dim=1) # 4个特征向量stack到一起
text_features = text_features / text_features.norm(dim=1, keepdim=True) # 归一化后的Chinese-CLIP文本特征,用于下游任务
print(text_features.shape) # Torch Tensor shape: [4, 特征向量维度]
# 内积后softmax
# 注意在内积计算时,由于对比学习训练时有temperature的概念
# 需要乘上模型logit_scale.exp(),我们的预训练模型logit_scale均为4.6052,所以这里乘以100
# 对于用户自己的ckpt,请使用torch.load载入后,查看ckpt['state_dict']['module.logit_scale']或ckpt['state_dict']['logit_scale']
logits_per_image = 100 * image_features @ text_features.t()
print(logits_per_image.softmax(dim=-1)) # 图文相似概率: [[1.2252e-03, 5.2874e-02, 6.7116e-04, 9.4523e-01]]
docker镜像
dockerfile
FROM ubuntu:20.04
RUN apt-get update && apt-get install -y wget curl
RUN wget http://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /tmp/conda.sh && \
bash /tmp/conda.sh -b && rm /tmp/conda.sh
WORKDIR /Chinese-CLIP/
COPY ./ /Chinese-CLIP/
RUN cp ./deps/.condarc /root/
ENV DEBIAN_FRONTEND=noninteractive
# 安装 tzdata 包并设置时区为上海(无交互)
RUN apt-get update && \
apt-get install -y tzdata && \
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo "Asia/Shanghai" > /etc/timezone
RUN ~/miniconda3/bin/conda init bash && . ~/.bashrc
RUN apt-get install -y python3-pip
RUN . ~/.bashrc && pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
RUN . ~/.bashrc && conda create -n clip_cn_cpu python=3.8 -y && \
conda activate clip_cn_cpu && \
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cpuonly -c pytorch -y
RUN . ~/.bashrc && conda activate clip_cn_cpu && conda install numpy tqdm six -y
RUN . ~/.bashrc && conda activate clip_cn_cpu && conda install -c conda-forge timm -y
RUN . ~/.bashrc && conda activate clip_cn_cpu && pip install lmdb==1.3.0
RUN . ~/.bashrc && conda activate clip_cn_cpu && pip install onnx onnxruntime onnxmltools fastapi uvicorn python-multipart
RUN . ~/.bashrc && conda activate clip_cn_cpu && cd /Chinese-CLIP && pip install -e .
ENV PYTHONPATH=${PYTHONPATH}:/Chinese-CLIP/cn_clip
COPY ./main_clip_cn.py /Chinese-CLIP/main_clip_cn.py
COPY ./deps/startProject.sh /Chinese-CLIP/deps/startProject.sh
EXPOSE 7863
ENTRYPOINT ["bash", "/Chinese-CLIP/deps/startProject.sh"]
1号进程:
#!/bin/bash
set -u
cd /Chinese-CLIP/ && nohup /root/miniconda3/envs/clip_cn_cpu/bin/python main_clip_cn.py >/log.alg 2>&1 &
echo "----------------------------------------"
echo "running..."
while [ 1 ]
do
echo "sleep"
sleep 3600
done
启动容器服务:
docker run -d -p7863:7863 kevinchina/deeplearning:clip_chinese
访问接口:
import requests
import torch
# 模型可选 ["RN50", "ViT-B-16", "ViT-L-14", "ViT-L-14-336", "ViT-H-14"]
url = "http://home.elvisiky.com:7863/cal_image_feature"
with open("no_text.png", "rb") as f:
files = {"fileb": ("no_text.png", f)} # 将文件字段键设置为 "fileb"
data = {"model_name": "ViT-B-16"} # 传递 model_name 作为表单数据
res1 = requests.post(url=url, files=files, data=data, timeout=None)
print(res1.json())
url = "http://home.elvisiky.com:7863/cal_text_feature"
data = {"text": "夕阳", "model_name": "ViT-B-16"} # 传递 model_name 作为表单数据
res2 = requests.post(url=url, data=data, timeout=None)
print(res2.json())
data = {"text": "怪兽", "model_name": "ViT-B-16"} # 传递 model_name 作为表单数据
res3 = requests.post(url=url, data=data, timeout=None)
print(res3.json())
image_vector = res1.json()["data"]
text_vector = res2.json()["data"] + res3.json()["data"]
vector1 = torch.tensor(image_vector)
vector2 = torch.tensor(text_vector)
inner = vector1 @ vector2.t()
print("一张图片和多个文本的内积", inner)
logits_per_image = 100 * inner
print("换算成softmax概率", logits_per_image.softmax(dim=-1))