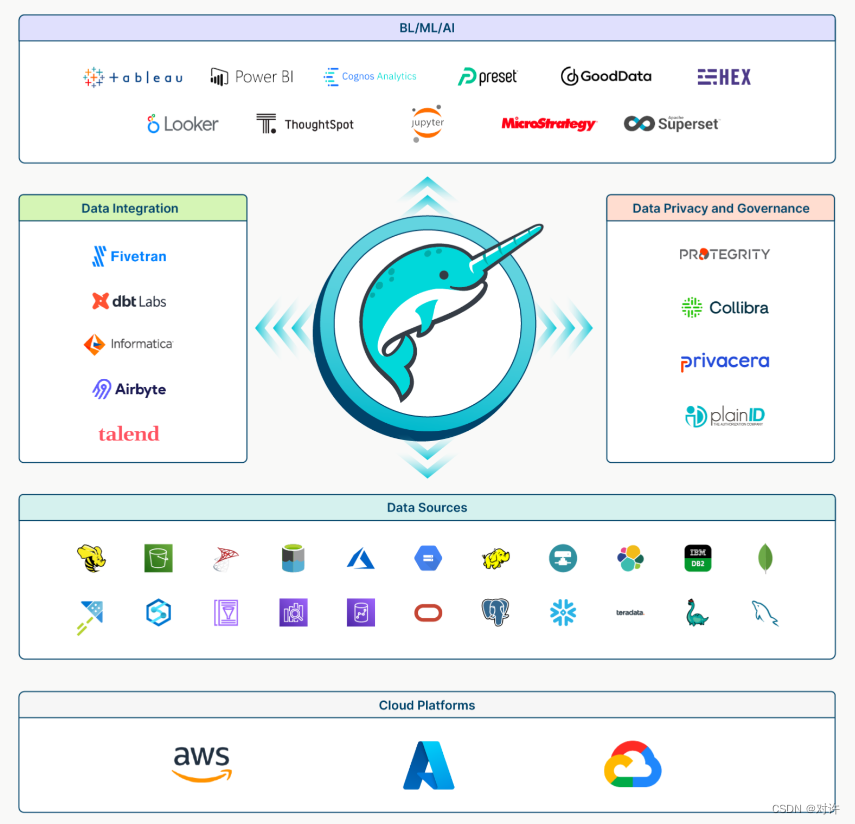
Dremio数据湖引擎
- 1、什么是Dremio
- 2、什么是数据湖仓
- 2.1、数据湖仓的历史和演变
- 3、Dremio查询引擎(Dremio Sonar)
- 3、Dremio特点
- 1、唯一具有自助式SQL分析功能的数据湖仓
- 2、数据完全开放,无锁定
- 3、亚秒级性能,云数据仓库成本的1/10
1、什么是Dremio
Dremio是唯一具有自助式SQL分析功能的数据湖仓
Dremio是一个开放式数据湖仓,可为您的所有数据提供自助式分析、数据仓库性能和功能以及数据湖灵活性
Dremio是唯一一家为数据工程师和分析师提供易于使用的自助式SQL分析的数据湖仓
Dremio是新一代的数据湖引擎,Dremio是一款完整的产品,Dremio通过界面化的SQL输入查询数据湖的数据
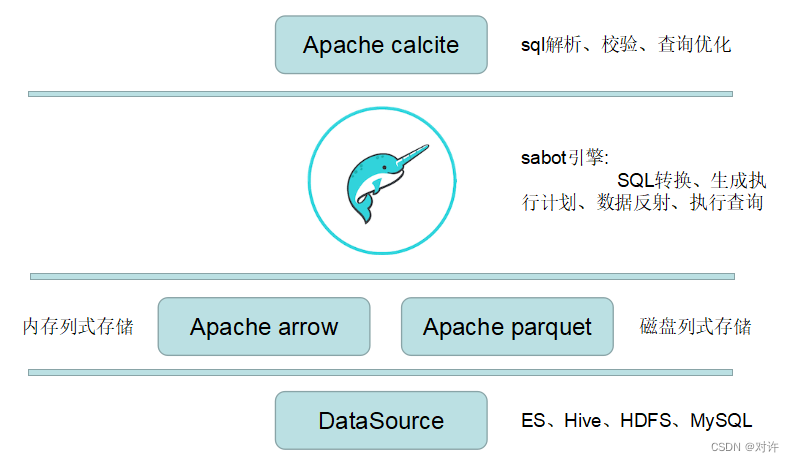
Dremio是一款基于Apache Calcite、Apache Arrow和Apache Parquet3个开源框架构建、核心引擎为Sabot的DaaS(Data-as-a-Service)数据即服务平台
Dremio是一款DaaS(Data-as-a-Service)数据即服务平台;可对接多类数据源来进行BI分析;数据可视化依托于Tableau、Power BI和Qlik sense三类产品
Dremio不是一个传统的数据仓库产品,而是一个湖仓(Lakehouse)查询引擎、湖仓分析平台,自身不面向客户提供任何存储资源和计算资源
使用Dremio的客户,需要自己提供计算资源,Dremio只是帮你把计算资源更灵活的管理起来,并提供了托管MetaData的能力,以及完备的提供:数据接入、权限管理、分析负载管理、计算资源调度、查询加速等能力

Dremio架构:

2、什么是数据湖仓
数据湖仓将数据仓库的性能、功能和治理与数据湖的可扩展性和成本优势相结合
借助数据湖仓,引擎可以直接从数据湖存储访问和操作数据,而无需使用ETL管道将数据复制到昂贵的专有系统中
数据湖仓架构结合了数据湖和数据仓库。虽然它不仅仅是两者之间的集成,但这个想法是充分利用两种架构:数据仓库的可靠事务和数据湖的可扩展性和低成本
在过去十年中,企业一直在大力投资其数据战略,以便能够推断出相关见解并将其用于关键决策。这有助于他们降低运营成本、预测未来销售并采取战略行动
湖仓是一种新型的数据平台架构,它提供数据仓库的数据管理功能,并利用数据湖的可扩展性和敏捷性
2.1、数据湖仓的历史和演变
开发者Dremio(迪潘卡尔·马宗达尔)聊什么是数据湖仓

数据湖仓是大数据架构中一个相对较新的术语,近年来发展迅速。它结合了两全其美的优势:数据湖的可扩展性和灵活性,以及数据仓库的可靠性和性能。
数据湖于 2010 年代初首次引入,为存储大量原始非结构化数据提供了一个集中式存储库。另一方面,数据仓库已经存在了更长的时间,旨在存储结构化数据,以便快速有效地进行查询和分析。但是,数据仓库的设置可能既昂贵又复杂,并且通常需要大量的数据转换和清理才能加载和分析数据。创建数据湖仓是为了应对这些挑战,并为大数据管理提供更具成本效益和可扩展性的解决方案。
随着企业生成的数据量的不断增加以及对快速高效数据处理的需求,对数据湖仓的需求大幅增长。因此,许多公司采用了这种新方法,该方法已发展成为组织中所有类型数据的中央存储库
近年来,越来越多的公司正在从传统数据仓库迁移,转向 Data Lake 和 Lakehouse 架构,以实现数据访问的民主化并使数据更易于访问。借助这些开放式架构,组织可以通过云原生服务获得敏捷性、可扩展性和可用性,并享受灵活性且不受供应商锁定。Dremio 支持直接对 Lake/Lakehouse 内的数据进行真正的交互式 SQL 查询和 BI,并且 Dremio 很高兴成为开源 Delta Sharing 计划的启动合作伙伴,为用户提供有关通过 Delta Sharing 服务器可用的数据的交互式 SQL
数据湖更像是数据仓库的进化,比传统数据仓库涉及面更广。但这并不是说数据湖能直接代替数据仓库,两者可以互补,大量案例显示,数据仓库作为数据湖的一类“数据应用”存在,协同工作
众所周知,传统数据仓库都是由数据库发展而来,因此,无论是传统的还是新型数据仓库(分布式、云原生数仓),主要应用于结构化数据。而数据湖是多结构数据的存储库,无论是结构化、非结构化或半结构化数据,都能以其原始格式存储,不需要进行初始转换过程,因此,更加灵活,并且存储与计算是分离的,数据存储在便宜的对象存储中,如Hadoop或Amazon S3,能更好的优化成本,而各种工具和服务(如Apache Presto、Elasticsearch和Amazon Athena)可以用来查询这些数据
数据湖的产生,源于大数据时代企业面临的一系列挑战,例如:数据孤岛,分析各种数据集的难度,数据管理,数据安全等。而云计算、人工智能则是推动数据湖发展的重要因素,云计算提供了快速查询、海量存储的能力,而机器学习需要原始数据做分析,而用到的数据,也不止于结构化数据,用户的评论、图像这些非结构化数据,也都可以应用到机器学习中
虽然数据湖的概念已经存在一段时间了,但许多组织在部署它们时却步履蹒跚,因为管理这种规模的 PB 数据已被证明太具有挑战性。例如,基于 Hadoop 的数据湖通常会随着添加更多数据而迅速变成数据沼泽
Dremio 正在通过在其平台中嵌入一系列 SQL 加速和数据管理工具来解决这个问题,以优化基于云计算环境中随时可用的对象存储系统跨数据湖的查询。现在的挑战是说服历来依赖传统数据仓库的组织重新考虑基于平台的数据湖方法,该方法有望简化访问云中 PB 级数据的过程
为什么开放数据对数据湖和湖库很重要
各行各业的公司都在寻求通过数据访问的民主化来从他们的数据中获得更多价值。为此,公司正在从传统和孤立的企业数据仓库迁移,转向数据湖和湖库,以使整个组织的数据更易于访问,并能够从数据中快速发现和产生价值。
Data Lakes 和 Lakehouses 的一个关键属性是数据以开源文件和表格格式存储,为开放数据生态系统奠定了基础。在现代数据湖架构中,公司可以自由地为给定的任务或工作负载选择正确的技术。与数据仓库(无论是在本地还是在云中)相比,这是一种相反的设计理念,数据仓库是垂直集成和专有的,将组织限制为一个供应商提供的功能,并在供应商的专有堆栈中创建数据孤岛。
云数据湖和 Lakehouse 架构的开放性提供了三个关键优势:
- 灵活地为任何任务使用最佳引擎、服务或工具
公司可以自由地为每个用例选择正确的技术。这包括使用不同存储系统、文件格式、表格式、处理引擎(例如 SQL 引擎)或目录(例如 Delta Sharing)的能力。例如,Dremio 的许多客户将 Databricks 用于某些工作负载(例如,数据处理、机器学习),将 Dremio 用于湖上的其他工作负载(例如,BI)。在 Dremio,我们鼓励公司始终为工作选择合适的工具,因为这会产生最成功和最具成本效益的解决方案,并且公司经常同时使用 Databricks 和 Dremio 来构建成功的项目。 - 没有供应商锁定
Data Lake 和 Lakehouse 架构的一个关键属性是,可以随着需求的发展和工作负载的变化随时更改单个组件,而无需启动到新系统的迁移项目或复制大量数据。这种灵活性对于寻求从数据中获取价值的组织而言至关重要。 - 面向未来的
开放性使新技术能够轻松地融入现有的数据湖和 Lakehouse 部署中,使组织能够快速利用新的创新和发展,并与行业最佳实践保持同步。
数据湖应该具备哪些能力?
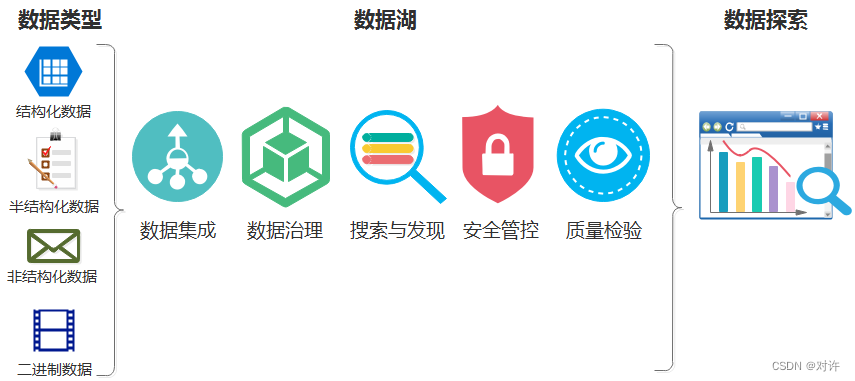
- 数据集成能力:
需要具备把各种数据源接入集成到数据湖中的能力。数据湖的存储也应该是多样的,比如HDFS、HIVE、HBASE等等。 - 数据治理能力:治理能力的核心是维护好数据的元数据(metadata)。强制要求所有进入数据湖的数据必须提供相关元数据,应该作为最低限度的治理管控。没有元数据,数据湖就面临成为数据沼泽的风险。更丰富的功能还包括:
• 自动提取元元数据,并根据元数据对数据进行分类,形成数据目录。
• 自动对数据目录进行分析,可以基于AI和机器学习的方法,发现数据之间的关系。
• 自动建立数据之间血缘关系图。
• 跟踪数据的使用情况,以便将数据作为产品,形成数据资产。 - 数据搜索和发现能力:
如果把整个互联网想象成一个巨大的数据湖。那么,之所以人们可以这么有效的利用这个湖中的数据,就是因为有了Google这样的搜索引擎。人们可以通过搜索,方便地找到他们想要的数据,进而进行分析。搜索能力是数据湖的十分重要的能力。 - 数据安全管控能力:
对数据的使用权限进行管控,对敏感数据进行脱敏或加密处理,也是数据湖能商用所必须具备的能力。 - 数据质量检验能力:
数据质量是分析正确的关键。因此必须对进入数据湖中的数据的质量情况进行检验。及时发现数据湖中数据质量的问题。为有效的数据探索提供保障。 - 自助数据探索能力:应该具备一系列好用的数据分析工具,以便各类用户可以对数据湖中的数据进行自助探索。包括:
• 支持对流、NoSQL、图等多种存储库的联合分析能力
• 支持交互式的大数据SQL分析
• 支持AI、机器学习分析
• 支持类似OLAP的BI分析
• 支持报表的生成
数据湖仓有什么作用?
数据湖仓在数据架构领域解决了四个关键问题:
通过提供用于存储和管理大量结构化和非结构化数据的集中式存储库,解决与数据孤岛相关的问题。
消除了对复杂且耗时的数据移动的需求,减少了与在系统之间移动数据相关的延迟。
使组织能够执行快速高效的数据处理,从而可以根据数据快速分析和做出决策。
最后,数据湖仓为存储大量数据提供了一种可扩展且灵活的解决方案,使组织能够随着需求的增长轻松管理和访问其数据。
数据仓库旨在帮助组织管理和分析大量结构化数据。
数据湖仓如何工作?
数据湖仓通过利用多层架构来运营,该架构集成了数据湖和数据仓库的优势。它首先将大量原始数据(包括结构化和非结构化格式)引入数据湖组件。这些原始数据以其原始格式存储,使组织能够保留所有信息而不会丢失任何细节。
从那里,可以使用Apache Spark和Apache Hive等工具进行高级数据处理和转换。然后对处理后的数据进行组织和优化,以便在数据仓库组件中进行高效查询,从而可以使用基于 SQL 的工具轻松分析数据。
其结果是一个用于大数据管理的集中式存储库,支持快速灵活的数据探索、分析和报告。数据湖仓的可扩展基础架构和处理各种数据类型的能力使其成为寻求释放大数据全部潜力的组织的一项宝贵资产。
数据湖仓的元素
数据湖仓具有一系列元素来支持组织的数据管理和分析需求。
一个关键要素是存储和处理各种数据类型的能力,包括结构化、半结构化和非结构化数据。
它们提供了一个用于存储数据的集中存储库,允许组织将所有数据存储在一个地方,从而更易于管理和分析。
数据管理层支持根据需要对数据进行治理、保护和转换。
数据处理层提供分析和机器学习功能,使组织能够快速有效地分析其数据并做出数据驱动的决策。
数据湖仓的另一个重要元素是提供实时处理和分析的能力,这使组织能够快速响应不断变化的业务条件
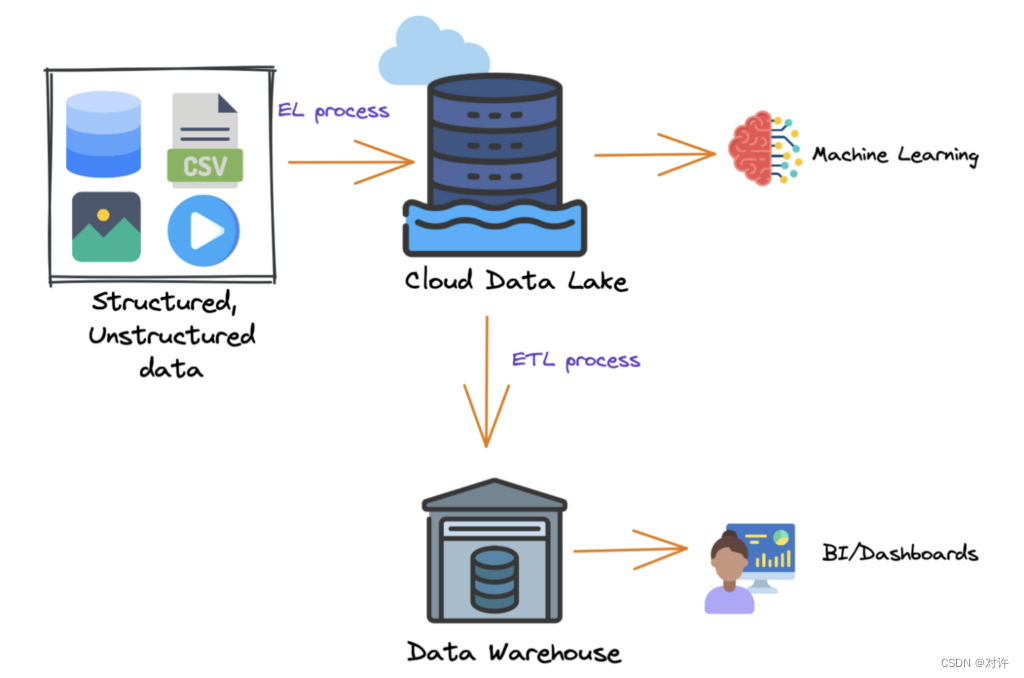
云数据湖
数据湖仓通常与云数据湖和云数据仓库结合使用。随着基于云的解决方案的日益普及,许多组织已转向云数据湖来构建其数据平台。
云数据湖为组织提供了独立扩展存储和计算组件的灵活性,从而优化其资源并提高其整体成本效率。通过分离存储和计算,组织可以以开放文件格式(如Apache Parquet)存储任意数量的数据,然后使用计算引擎来处理数据。此外,云数据湖的弹性使工作负载(如机器学习)能够直接在数据上运行,而无需将数据移出数据湖。
尽管云数据湖有很多好处,但也有一些潜在的缺点:
一个挑战是确保湖中数据的质量和治理,特别是随着湖中存储的数据量和多样性的增加。
另一个挑战是需要将数据从数据湖移动到下游应用程序(如商业智能工具),这通常需要额外的数据拷贝,并可能导致作业失败和其他下游问题。
此外,由于数据以原始格式存储并由许多不同的工具和作业写入,因此文件可能并不总是针对查询引擎和低延迟分析应用程序进行优化。
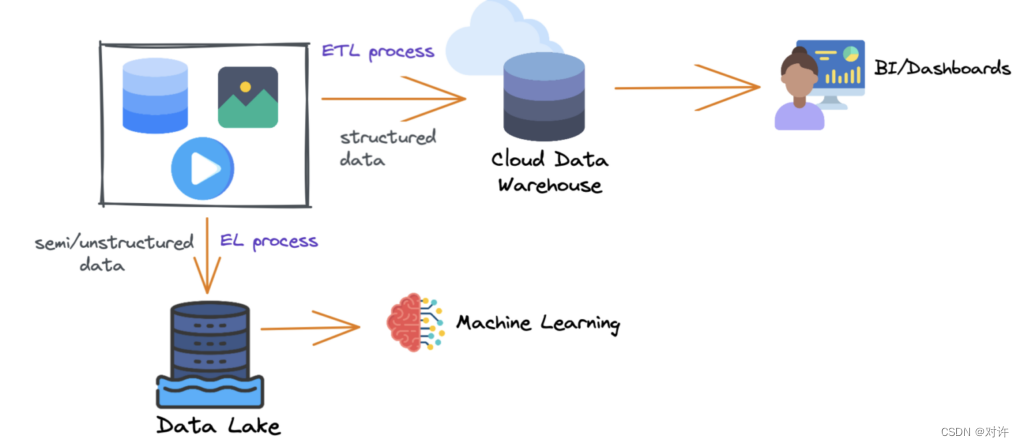
云数据仓库
第一代本地数据仓库使企业能够从多个数据源获取历史见解。但是,此解决方案需要在成本和基础架构管理方面进行大量投资。为了应对这些挑战,下一代数据仓库利用基于云的解决方案来解决这些限制。
云数据仓库的主要优势之一是能够分离存储和计算,允许每个组件独立扩展。此功能有助于优化资源并降低与本地物理服务器相关的成本。
但是,使用云数据仓库也存在一些潜在的缺点:
虽然它们确实降低了一些成本,但它们仍然相对昂贵。
此外,运行性能很重要的任何工作负载通常需要在处理之前将数据复制到数据仓库中,这可能会导致额外的成本和复杂性。
此外,云数据仓库中的数据通常以供应商特定的格式存储,从而导致锁定/锁定问题,尽管某些云数据仓库确实提供了将数据存储在外部存储中的选项。
最后,对多个分析工作负载的支持,特别是与机器学习等非结构化数据相关的工作负载,在某些云数据仓库中仍然不可用。
数据湖仓的未来
在讨论数据湖仓、它们的元素以及它们的作用时,很自然地会看到这项技术向前发展的影响。随着越来越多的组织采用大数据,以及对灵活、可扩展且经济高效的解决方案的需求持续增长,未来看起来非常有希望。
在未来几年,预计数据湖仓的采用率将增加,各种规模和所有行业的组织都认识到它们在提供统一平台来管理和分析大数据方面的价值。
此外,预计数据湖仓技术将持续创新和进步,例如改进的数据处理和转换功能,增强的安全性和治理功能,以及与其他数据管理工具和技术的扩展集成。
机器学习和人工智能的兴起将推动对灵活且可扩展的大数据平台的需求,这些平台可以支持这些高级分析模型的开发和部署。
数据湖仓的未来也将受到数据隐私和安全日益重要性的影响,我们可以期待看到数据湖仓不断发展以满足这些新要求,包括更好的数据屏蔽和数据加密功能。总体而言,数据湖仓的未来看起来很光明,它们可能会在帮助组织从大数据中提取价值方面发挥越来越重要的作用。
3、Dremio查询引擎(Dremio Sonar)
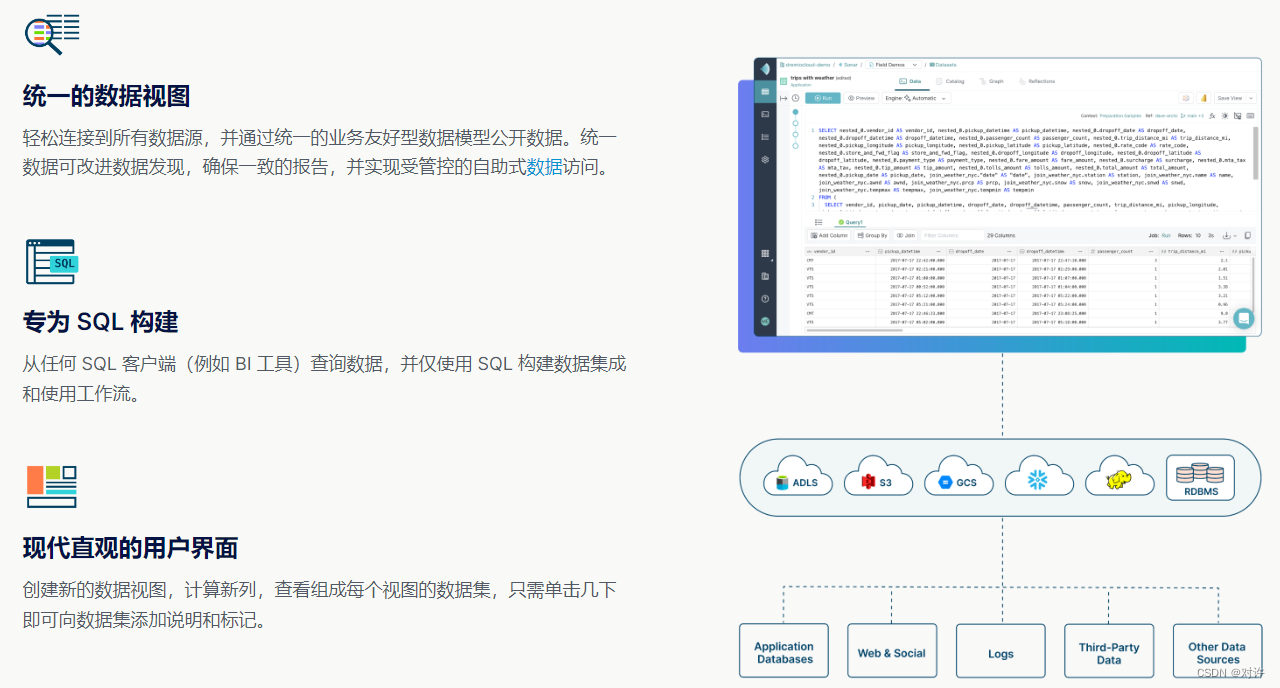
Dremio Sonar是一个具有内置语义层和直观用户界面的SQL查询引擎。借助Dremio Sonar,可以快速访问所需的数据、跨数据源查询、创建视图以及使用数据操作语言(DML)更新Apache Iceberg表
Dremio Sonar是一个适用于开放平台的SQL引擎,提供数据仓库级别的性能和能力,可在数据湖上使用,并提供自助式体验,使数据易于消费和协作
Dremio Sonar旨在更自由的访问更多数据并做出更好的业务决策
1)适用于所有SQL工作负载
支持所有SQL工作负载,从任务关键型BI仪表盘到即席/探索性工作负载,引擎可直接在湖仓上提供仓库性能和功能(包括DML操作)
通过透明的查询优化和加速,提供无缝的终端用户体验
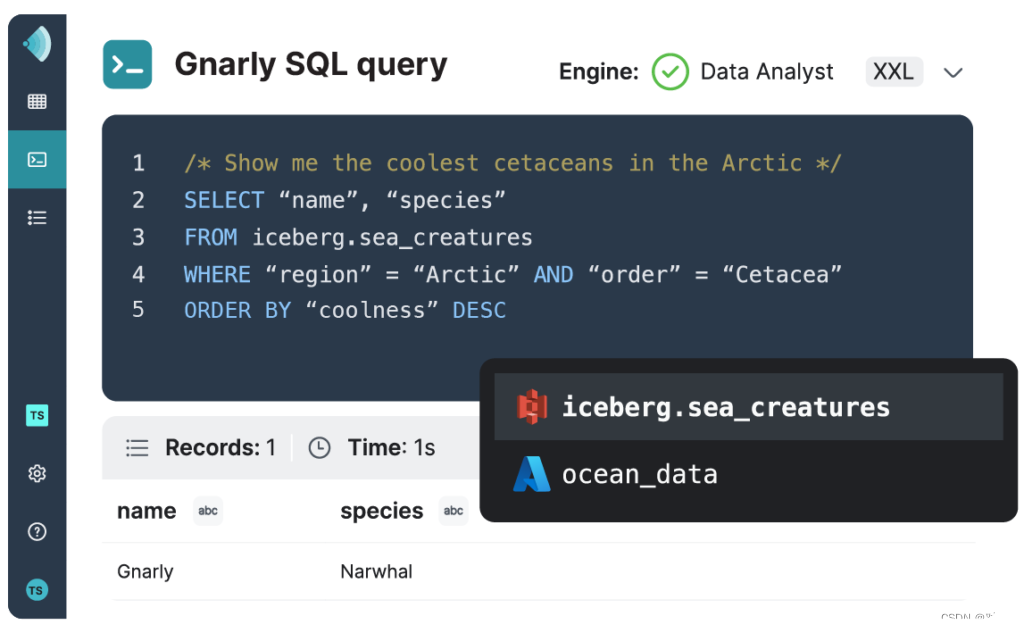
2)任何位置的任何数据
使用连接器连接到各种外部数据库,使用尚未在湖中的数据丰富您的分析
在数据所在的位置实现数据民主化,并通过统一的数据视图实现各种用例,而无需数据副本
3)一致的协作数据
定义可供任何下游应用程序利用的数据和业务指标的一致且安全的视图
构建更简单的数据模型,无需将数据导出到Tableau数据提取/Power BI导入、多维数据集和其他优化的数据结构中
以自助方式策划、分析和共享数据集。使用最合乎逻辑的数据视图,而无需了解预先优化、预先聚合的物理表
4)一流的体验
通过为理解和喜爱SQL的分析师提供无缝集成体验,与数据进行交互
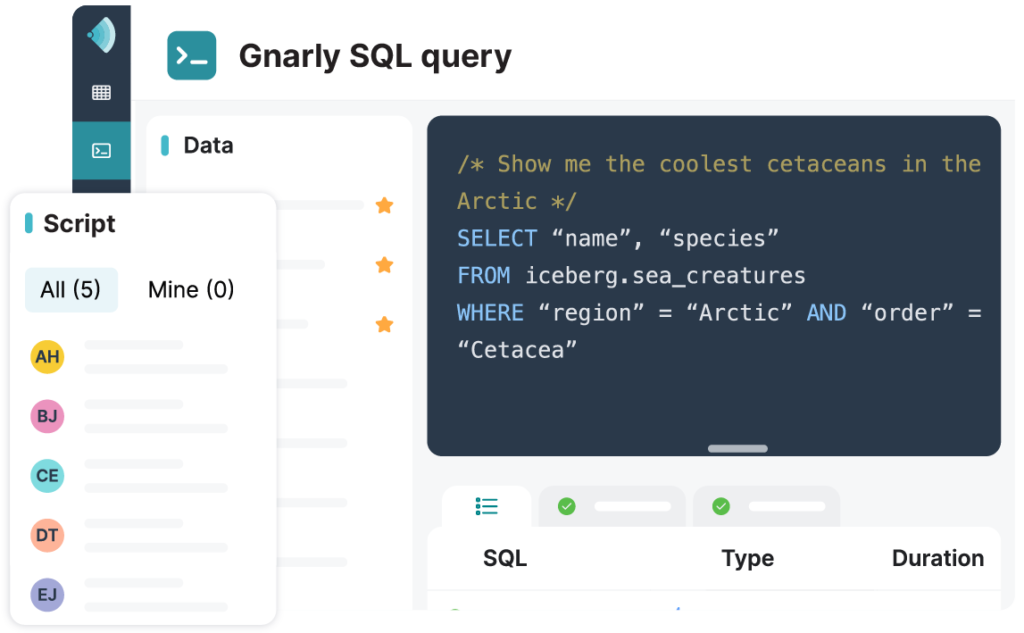
使用Sonar的SQL Runner查询您的湖仓数据,这是一款面向分析师的一流IDE,包括自动完成、多语句执行以及保存和共享SQL脚本的功能
使用Sonar的SQL Profiler探查器理解和优化查询性能,并使用Sonar的Data Map数据映射可视化数据集使用和沿袭
5)无摩擦的BI和数据科学集成
BI团队可以无缝连接到Dremio Sonar,并使用您喜爱的BI工具可视化数据,这些工具具有与Tableau和Power BI的本机连接器,包括对基于OAuth 2.0的SSO的支持
数据科学团队受益于高吞吐量数据连接。借助Apache Arrow Flight,使用Python、R和Jupyter Notebook轻松使用查询结果
3、Dremio特点
Apache Iceberg: 开放数据湖仓的基础技术
Apache Iceberg:数据湖上的数据仓功能、性能和可扩展性
为什么Apache Iceberg是实施开放数据湖屋的基础技术?
Apache Iceberg提供的功能、性能、可扩展性和成本节省,实现了开放数据湖仓承诺的功能

官网首页下载:
https://www.dremio.com/
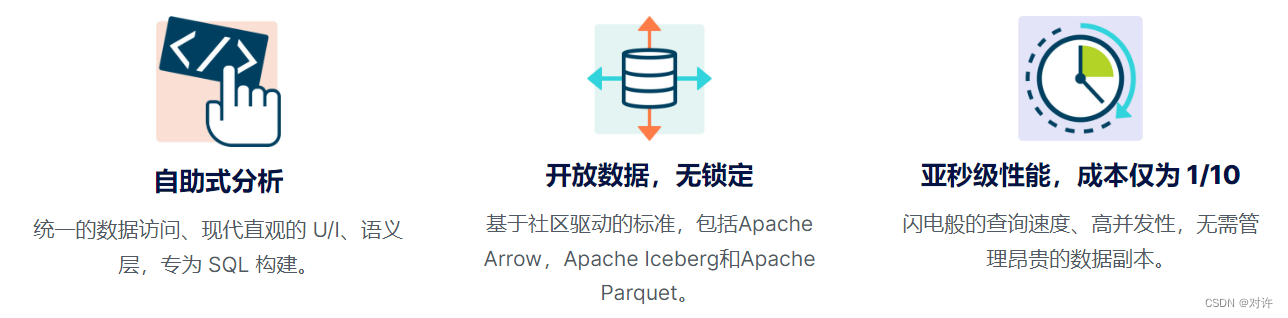
1、唯一具有自助式SQL分析功能的数据湖仓
Dremio提供自助式SQL分析的功能
语义层(搜索|血缘|内置目录)
直观的SQL和无代码用户界面
数据源连接器
BI连接器
仅使用SQL的数据集成和使用工作流
易于配置的安全性和访问控制
Dremio Sonar的共享语义层
Dremio支持所有用户和工具的共享语义层,Dremio支持数据分析师和数据科学家自助访问数据,同时集中安全性和治理
1)受管控的自助式数据访问
为什么要等待数周才能创建所需的仪表板,以便从数据中获取价值?
Dremio的语义层使数据分析师和数据科学家能够以自助服务方式发现、策划、分析和共享数据集
2)所有用户和工具的数据视图一致
为什么要在团队无法使用的单个BI工具中定义数据、计算字段和虚拟数据集的隔离定义?
您可以使用Dremio的语义层来创建任何下游应用程序都可以利用的数据集定义、计算字段和安全规则
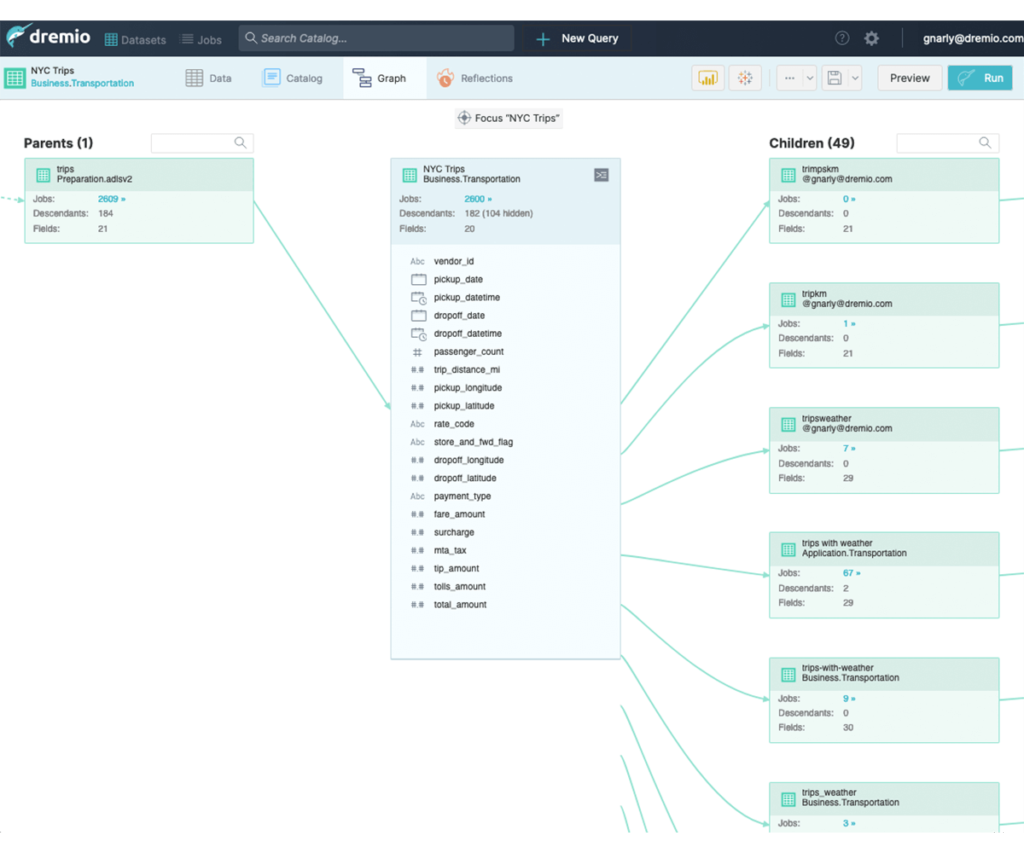
3)透明查询加速
不确定应将仪表板连接到哪个数据视图以获得所需的性能?
借助Dremio的语义层,您不必担心连接到各种物化视图,从而使仪表板快速运行。只需在您想要的表上创建仪表板和报告,Dremio查询优化器将在幕后工作以加速您的查询
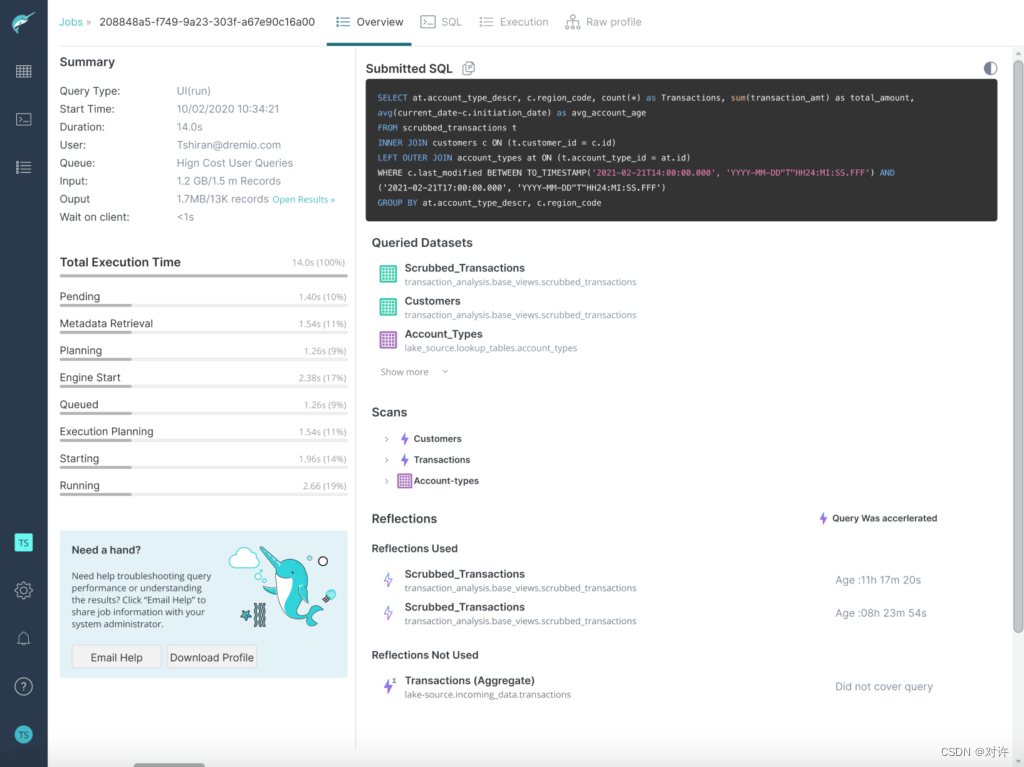
2、数据完全开放,无锁定
基于社区驱动标准(如Apache Parquet,Apache Iceberg和Apache Arrow)的开放数据湖仓使组织能够使用一流的处理引擎并消除供应商锁定

Dremio与开放数据标准的深度集成是一个巨大的优势。当您决定更改数据的基础结构时,您无需影响报表层。拥有一个开放和独立的数据湖仓使我们能够使用不同的解决方案,我们可以优化成本、上市时间并轻松地来回移动数据。所有这些都可以在后端完成,而不会影响业务
Dremio的核心是利用高性能的柱状存储和执行,由Apache Arrow(内存中的柱状存储)和Gandiva(基于LLVM的执行内核)、Apache Arrow Flight(高速分布式协议)和Apache Parque
Dremio在高性能分析方面有着深厚的知识和经验,是Apache Arrow、Gandiva和Arrow Flight项目的共同创建者和维护者
Apache Parquet、Apache Iceberg和Apache Arrow(同Impala)是Dremio支持的开放数据项目

3、亚秒级性能,云数据仓库成本的1/10
Dremio在数据湖仓上为客户提供了BI的亚秒级SQL查询,这是其他引擎无法比拟的。Dremio超越了世界上最苛刻和最大的企业的性能和规模要求,其中包括财富5强中的10家
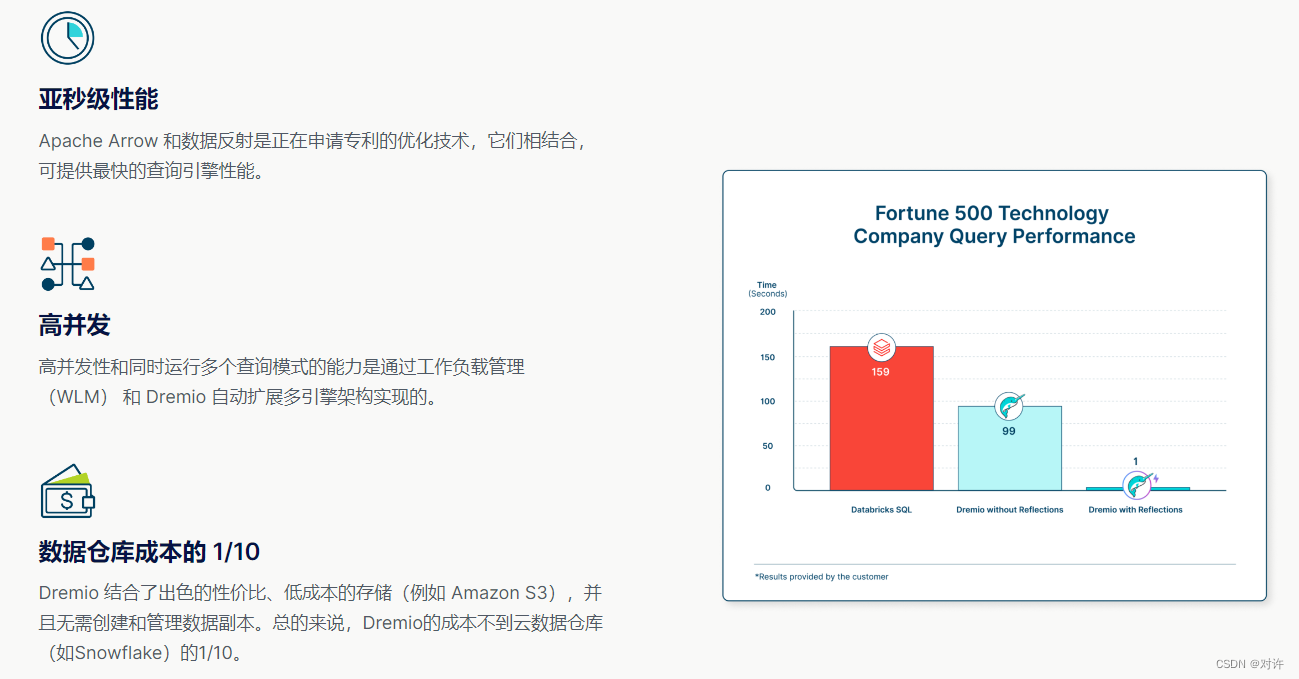
Dremio Sonar查询引擎最快的原因:

Reflections(多表关联与预聚合)
Arrow Inside
C3缓存(DAS上的列式数据缓存)
基于成本的优化器
精细修剪
最快的JDBC、ODBC和ADBC驱动程序
多引擎架构
工作负载管理
产品符合 改善自助服务、性能、和治理
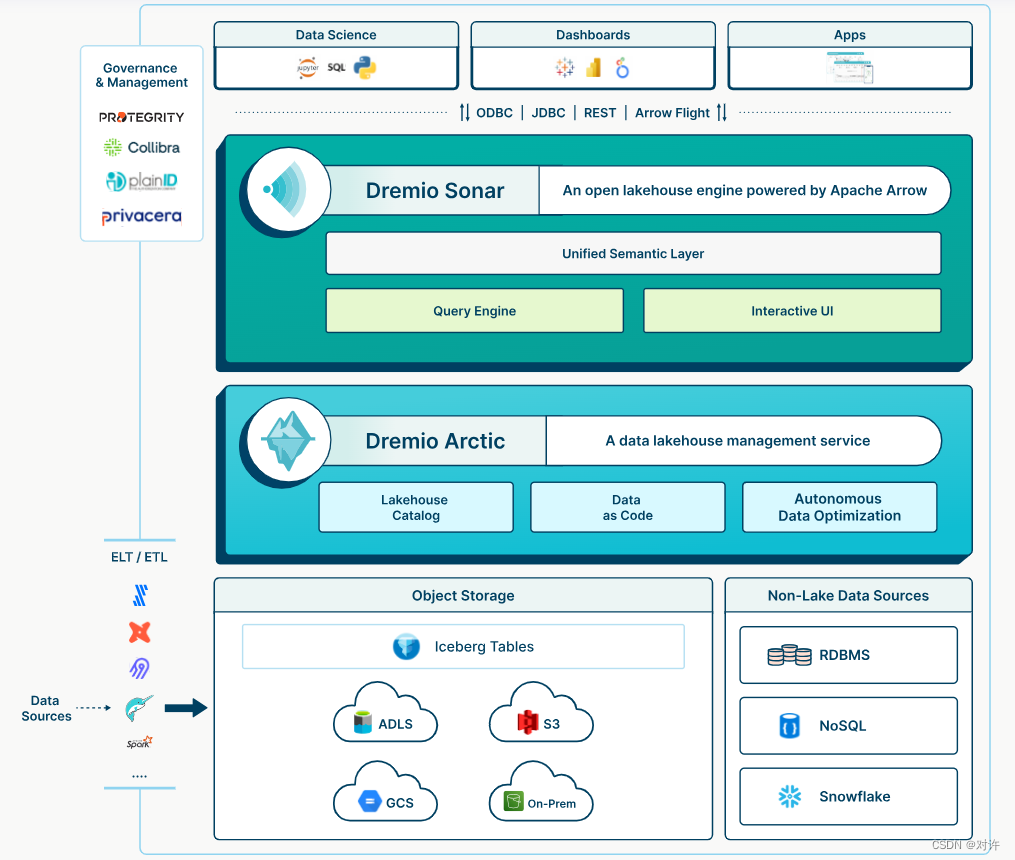
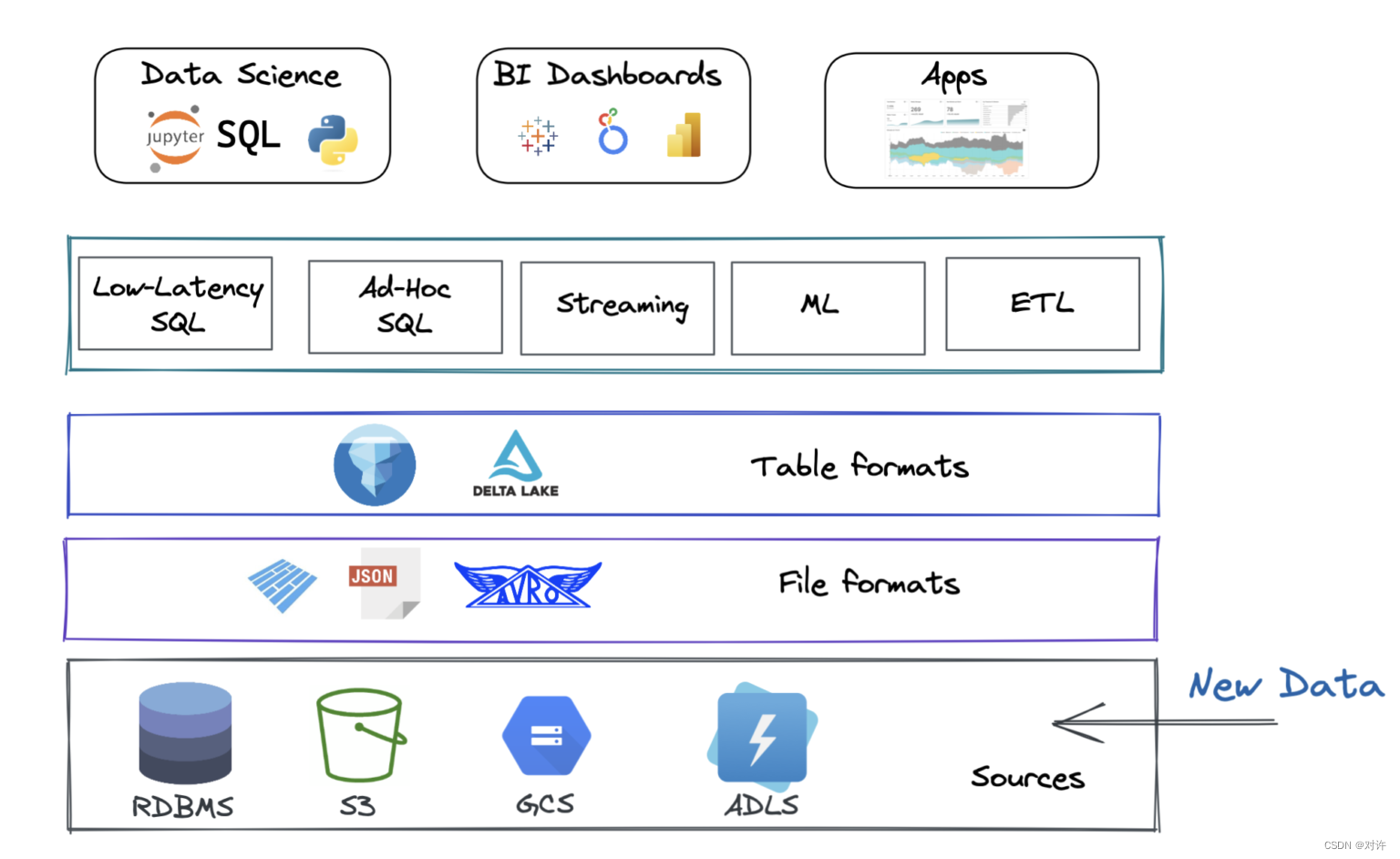
Dremio数据湖仓生态系统