什么是LM(language model语言模型)?
引例:
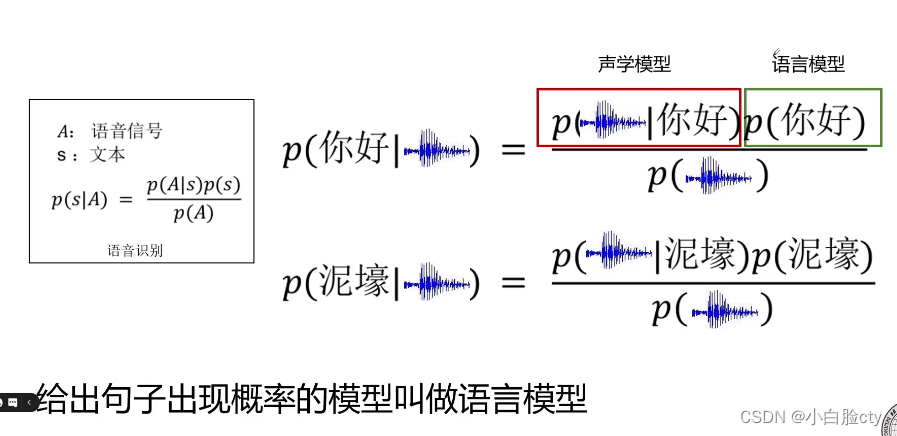
1、统计机器学习时期的语言模型–语音识别

2、贝叶斯公式求P(s|A)——在有了语音信号的前提下是文本的概率
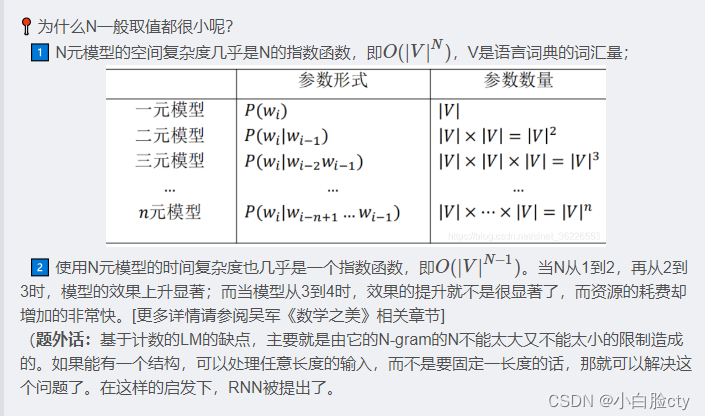
1 n-gram模型概述
n-gram模型是一种统计语言模型,用于建模文本数据中的语言结构。它在机器学习和自然语言处理领域广泛应用。
1.1 n-gram模型的基本思想
马尔科夫假设:假设文本中的每个词(或字符)只依赖于前面的n-1个词(或字符),即条件概率P(w_n|w_1, w_2, …, w_{n-1}),其中w_1, w_2, …, w_n表示文本中的词(或字符)。n-gram模型中的n表示上下文的大小,通常是1、2、3等。
1.2 特点
某个词的出现依赖于其他若干个词;
我们获得的信息越多,预测越准确;
1.3缺点
- 数据稀疏性:词同时出现的情况可能没有,组合阶数高时尤其明显。
改进:smoothing平滑、backoff回退、引入神经网络语言模型 - 上下文局限性: 无法共享具有相同语义的词汇/前缀中的信息
改进:引入词嵌入,由字符表示转向向量表示 - n较大时,模型很容易受到数据中未见的n-gram序列的影响。
也就是说,n越大,需要计算、统计的参数越多,占用的内存空间越大。
改进:马尔科夫假设,限制n大小
随着深度学习技术的发展,神经网络模型如循环神经网络(RNN)和Transformer等逐渐取代了传统的n-gram模型,在自然语言处理任务中取得了更好的性能。这些神经网络模型能够更好地捕捉长距离依赖关系和上下文信息,使它们在许多NLP任务中表现出色。然而,n-gram模型仍然可以用作某些特定任务的基线模型或快速原型开发工具。
1.4n-gram模型步骤
-
数据预处理:将文本数据分割成词语(或字符)序列,并去除不需要的标点符号、停用词等。
-
计算n-gram频率:对于给定的n值,统计文本中所有n-gram序列的出现频率,这些序列可以是单词级别的(如unigram、bigram、trigram)或字符级别的。
-
计算条件概率:对于每个n-gram序列,计算其条件概率,即给定前面的n-1个词(或字符)后,下一个词(或字符)出现的概率。
-
应用模型:使用计算得到的条件概率来进行文本生成、文本分类、语言模型评估等任务。
在n-gram模型中,较小的n值(如1或2)通常用于简单的任务,如文本分类,而较大的n值(如3或4)可以用于更复杂的自然语言处理任务,如语言建模。
2 发展阶段
2.0第0阶段
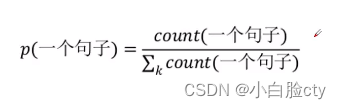
直观,符合直觉,但是效果很差
问题:
①句子不好确定
②很难保证句子能够完全一样地重复出现
2.1第一阶段:Unigram 模型 / 1-gram
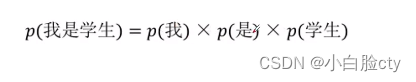
直接把词出现的概率相乘
unigram基本思想
Unigram 模型是一种最简单的统计语言模型,它假设文本中的每个词在上下文中都是独立的,没有考虑其他词的影响。这意味着 Unigram 模型只计算每个单词在文本中出现的概率,而不考虑它与其他单词的关系。
Unigram 模型主要特点
词的独立性假设:Unigram 模型假设文本中的每个词都是相互独立的,因此模型计算一个词出现的概率不受其他词的影响。
词频统计:Unigram 模型通过统计每个词在语料库中的出现次数来计算概率。一般来说,概率与词频成正比。
缺乏上下文考虑:Unigram 模型不考虑词与词之间的关系或上下文信息,因此无法捕捉到词序列的语法结构或语义含义。
尽管 Unigram 模型非常简单,并且在捕捉文本复杂性方面存在严重限制,但它在某些任务上仍然有用。例如,在一些文本分类任务中,Unigram 模型可以作为一个基线模型,快速建立一个最简单的文本分类器。然而,对于更复杂的自然语言处理任务,如机器翻译、语音识别和语言建模等,通常需要更复杂的模型,例如n-gram模型、循环神经网络(RNN)、Transformer等,以更好地捕捉上下文信息和语法结构。
2.2 第二阶段:二元语法模型BLM
Bigram Language Model / 2-gram / bigram / “一阶马尔科夫链”


BLM基本思想
BLM是一种基于统计的语言模型,用于建模文本中词语的序列。与Unigram模型不同,二元语法模型考虑相邻的两个词之间的关系。它基于一个假设,即每个词的出现只受其前面一个词的影响,而与其他词无关。因此,它计算每个词出现的概率,考虑了前一个词。
具体来说,对于一个文本序列w_1, w_2, w_3, …,二元语法模型计算每个词的条件概率,即P(w_i | w_{i-1}),表示在给定前一个词w_{i-1}的情况下,词w_i出现的概率。

要做的工作就是在语料库中统计各个词语出现的词频,同时要计算出给定的语句的先验概率,这个先验概率是基于2-gram的
BLM主要特点
上下文窗口:它仅考虑前一个词,因此上下文窗口大小为1,即只关注相邻的两个词。
参数估计:为了估计概率,需要统计训练数据中每个词对的出现次数,并根据这些统计信息计算条件概率。
简化模型:与更高阶的n-gram模型相比,二元语法模型更加简化,但仍可以在某些自然语言处理任务中表现良好。
虽然二元语法模型比Unigram模型更加复杂,可以捕捉到词序列中的一些局部信息,但它仍然有限制,无法捕捉到较远距离的依赖关系或语义含义。在实际应用中,二元语法模型通常用于一些简单的自然语言处理任务,例如文本生成、拼写检查和词性标注等。对于更复杂的任务,如机器翻译或语音识别,通常需要更高阶的n-gram模型或深度学习模型,以更好地处理上下文信息和语法结构。
2.3 第三阶段:3-gram / trigram / "二阶马尔科夫链” ……n-gram
3 原理
3.1数学原理

3.2 n-gram原理
假设句子S是有词序列w1,w2,w3…wn组成,用公式表示N-Gram语言模型如下(每一个单词wi都要依赖于从第一个单词w1到它之前一个单词wi−1的影响):
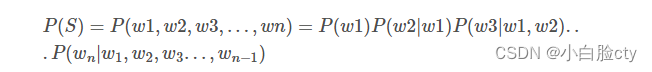
3.3 原概率公式弊端及解决办法:
3.3.1 参数空间过大问题——最大似然估计

-
根据大数定理,只要统计量足够,相对频度就等于概率。
-
通常用相对频率作为概率的估计值。这种估计概率值的方法称为最大似然估计。
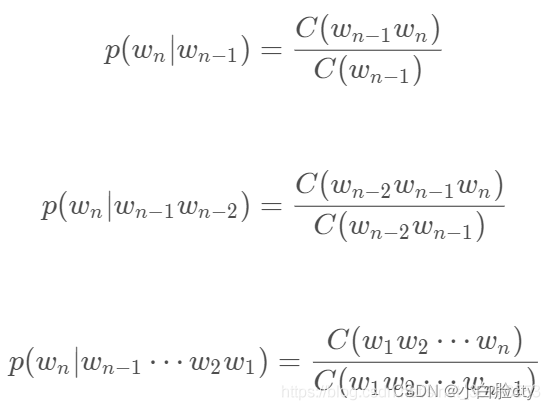
为了解决第二个问题,我们通常会使用平滑法(如:拉普拉斯平滑、add-k 平滑) 或者回退法(backoff)。
3.3.2 稀疏问题——平滑法和回插法
N-gram的N越大,模型 Perplexity 越小,表示模型效果越好。
依赖的词越多,我们获得的信息量越多,对未来的预测就越准确。然而,语言是有极强的创造性的,当N变大时,更容易出现这样的状况:某些n-gram从未出现过,这就是稀疏问题。
N-gram最大的问题就是稀疏问题(Sparsity)。例如,在bi-gram中,若词库中有2万个词,那么两两组合就有近4亿个组合。其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的。
法1:数据平滑data Smoothing)
- 数据平滑的目的
使所有的N-gram概率之和为1;
使所有的n-gram概率都不为0; - 本质
重新分配整个概率空间,使已经出现过的n-gram的概率降低,补充给未曾出现过的n-gram。
“平滑”处理的基本思想是“劫富济贫”,即提高低概率(如零概率),降低高概率,尽量使概率分布趋于均匀。
补充:
① 古德-图灵估计的原理:对于没有看见的事件,我们不能认为它发生的概率就是零,因此我们从概率的总量中,分配一个很小的比例给予这些没有看见的事件,因此需要将所有看见的事件概率调小一点。至于小多少,要根据“越是不可信的统计折扣越多”的方法进行。
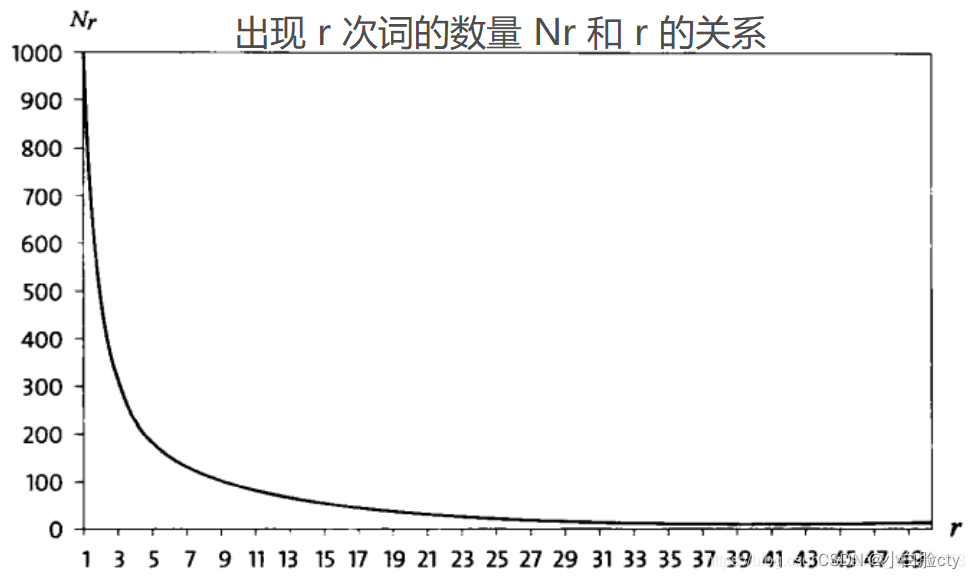
② Zipf 定律:一般来说,出现一次的词的数量要比出现两次的多,出现两次的比出现三次的多。
法2:回退(backoff)和 插值(interpolation)
当我们没有足够的数据使用高阶n元模型时,我们会“退回”到低阶n元模型,如:我们无法计算P(C | A,B),我们仍然可以依赖于bigram概率P(C | B),甚至是unigram概率P©,然后通过插值(如:线性插值)混合各种n元模型,赋予它们不同的权重来估计P(C | A, B):
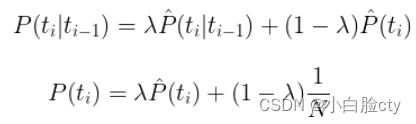
4 n-gram应用
4.1 评估句子是否合理
1-gram
每个词都是独立分布的
P(A,B,C) 其中A,B,C互相之间没有交集.
所以P(A,B,C) = P(A)P(B)P©
例子
“猫跳上椅子” ,分词后得到:“猫/跳上/椅子”
P(“猫”,“跳上”,“椅子”) = P(“猫”)P(“跳上”)P(“椅子”);
假设其中各个词的数量数语料库中统计的数量如下表所示(语料库词汇量为M):

句子的合理的概率.
P(A,B,C) = P(A)P(B)P© =13/M * 16/M * 23/M
2-gram
每个词都与它左边的最近的一个词有关联
P(A,B,C) = P(A)P(B|A)P(C|B)
例子
“猫,跳上,椅子” ,P(A=“猫”,B=“跳上”,C=“椅子”) = P(“猫”)P(“跳上”|“猫”)P(“椅子”|“跳上”);其中各个词的数量数语料库中统计的数量

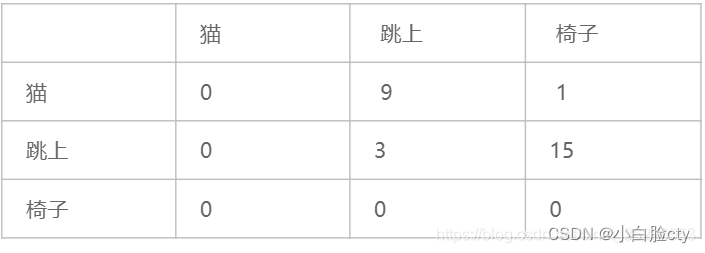
“猫”后面是“跳上”的频数:9
句子的合理的概率.
P(A,B,C) = P(A)P(B|A)P(C|B) = 13/M * 9/13 * 15/16
//评估
对于一个训练好的模型,我们需要评估模型的好坏。
法1:外部评估(extrinsic evaluation)
评估一个模型的最佳方法是将其嵌入到应用程序中,并衡量应用程序的改进程度,这种方法叫外部评估(extrinsic evaluation),很消耗资源;
法2:内部评估(intrinsic evaluation)
把数据集分为训练集和测试集,评估测试集的结果。内部评估模型的指标称为复杂度perplexity (有时缩写成PP)
##### 计算 PP
***法1:***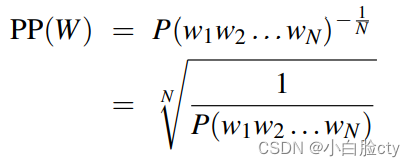
例子

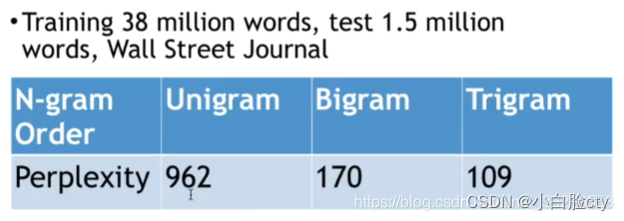
①单词序列的条件概率越高,复杂度越低。因此,对于语言模型,最小化复杂度等价于最大化测试集概率。
②2-gram比1-gram的复杂度值要小,而复杂度值越小说明模型越好。
法2:
计算任何单词后面可能出现的下一个单词的数量(一个模型的复杂度越小,每个位置的词就越确定,模型越好)
4.2 评估两个字符串之间的差异程度!
公式

例子

Gn(s):词①的分词数
Gn(t):词②的分词数
Gn(s)∩Gn(t):词①和词②重复的分词数
因此距离:8+9-2*4=9
字符串之间的距离越小,它们就越接近。当两个字符串完全相等的时候,它们之间的距离就是0。
4.3其他
输入法、分词算法、语音识别、机器翻译等
- 用N—gram模型进行中文分词
首先根据词典(可以是从训练语料中抽取出来的词典,也可以是外部词典)对句子进行简单匹配,找出所有可能的词典词。将它们和所有单个字作为结点,构造n元切分词图,利用n-gram求出所有可能分词路径的权值,利用动态规划思想求得最佳分词路径。

链接:语言模型与应用https://blog.csdn.net/weixin_40056628/article/details/89364456?spm=1001.2014.3001.5502
参考
自然语言处理NLP中的N-gram模型
简单理解 n-gram
语言模型(N-Gram
N-gram的简单的介绍
N-Gram语言模型
语言模型(LM)和循环神经网络(RNNs
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT
【研究前沿】神经网络语言模型综述_单词
NLP:n-gram模型