在 Spring Boot 中进行分布式追踪
分布式系统中的应用程序由多个微服务组成,它们可以位于不同的服务器、容器或云中。当出现问题时,如性能瓶颈、错误或延迟,了解问题的根本原因变得至关重要。分布式追踪是一种用于跟踪和分析分布式应用程序性能和行为的工具。本文将介绍如何在Spring Boot应用程序中进行分布式追踪,以及如何使用Spring Cloud Sleuth和Zipkin来实现这一目标。

什么是分布式追踪?
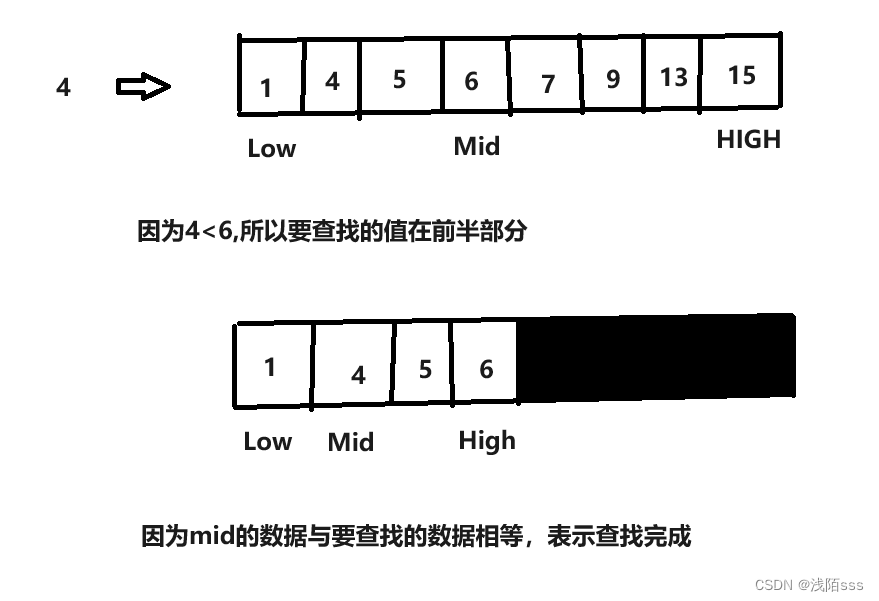
分布式追踪是一种监视分布式系统的方法,通过追踪和分析请求在不同服务之间的传递路径和时间来帮助诊断性能问题。分布式追踪通常包括以下主要组件:
-
跟踪器(Tracer):用于在请求进入和离开应用程序时创建唯一的跟踪标识符,并记录事件和时间戳。
-
跟踪(Trace):代表一次请求的完整生命周期,包括多个服务和操作。
-
跨度(Span):代表一次操作或事件,跨度通常包含有关操作的信息,如名称、持续时间和标签。
-
采样(Sampling):用于确定哪些请求应该记录并进行跟踪,以防止数据过于庞大。
使用 Spring Cloud Sleuth 进行分布式追踪
Spring Cloud Sleuth是Spring Cloud的一部分,它提供了在Spring Boot应用程序中进行分布式追踪的支持。Spring Cloud Sleuth集成了Zipkin,一个开源的分布式追踪系统,用于收集、存储和查询跟踪数据。以下是如何在Spring Boot应用程序中使用Spring Cloud Sleuth的步骤:
步骤1:添加依赖项
在您的Spring Boot项目的pom.xml文件中添加Spring Cloud Sleuth的依赖项:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
步骤2:配置应用程序名称
您可以配置应用程序的名称,以便在分布式追踪中标识不同的应用程序。在application.properties或application.yml文件中添加以下配置:
spring.application.name=my-service
步骤3:启动 Zipkin 服务器
要使用Spring Cloud Sleuth,您需要启动一个Zipkin服务器。您可以使用Docker、Java应用程序或其他方法来启动Zipkin服务器。以下是使用Docker启动Zipkin服务器的示例命令:
docker run -d -p 9411:9411 openzipkin/zipkin
步骤4:运行应用程序
运行您的Spring Boot应用程序。Spring Cloud Sleuth将自动为每个请求创建唯一的跟踪标识符,并记录相关的跟踪和跨度。
步骤5:查看追踪数据
打开浏览器并访问Zipkin服务器的Web界面(默认端口9411)。您将能够查看和分析应用程序的分布式追踪数据。
使用 Spring Cloud Sleuth 进行手动追踪
除了自动追踪外,Spring Cloud Sleuth还允许您手动创建和记录跟踪数据。这对于记录自定义事件或特定操作非常有用。以下是一个示例代码,演示如何在Spring Boot应用程序中手动创建跟踪:
import org.springframework.cloud.sleuth.annotation.NewSpan;
import org.springframework.stereotype.Service;
@Service
public class MyService {
@NewSpan("custom-span-name")
public void performCustomOperation() {
// 在这里执行自定义操作
}
}
在上述示例中,我们使用@NewSpan注解来创建一个新的跨度,您可以为跨度指定名称。然后,您可以在performCustomOperation方法中执行自定义操作,该操作将被记录到分布式追踪中。
使用 Sleuth 的 Trace 和 Span
在代码中,您可以通过 Tracer 和 Span 来访问当前跟踪和跨度信息。以下是更多关于如何使用 Tracer 和 Span 的示例代码,演示了它们的一些常见用法:
import org.springframework.cloud.sleuth.Tracer;
import org.springframework.cloud.sleuth.annotation.NewSpan;
import org.springframework.stereotype.Service;
@Service
public class MyService {
private final Tracer tracer;
public MyService(Tracer tracer) {
this.tracer = tracer;
}
@NewSpan("custom-span-name")
public void performCustomOperation() {
// 访问当前跨度
Span currentSpan = tracer.currentSpan();
// 访问当前跟踪
Trace currentTrace = tracer.currentTrace();
// 创建一个自定义的子跨度
Span customSpan = tracer.nextSpan().name("custom-subspan").start();
try {
// 在子跨度内执行操作
// ...
// 设置子跨度的标签
customSpan.tag("custom-tag", "tag-value");
} finally {
// 完成子跨度
customSpan.finish();
}
}
}
在上述示例中,我们注入了 Tracer 对象,它允许我们访问当前跟踪和跨度。我们还创建了一个自定义的子跨度,并在其中执行操作。最后,我们通过调用 finish() 方法来完成子跨度。您可以为跨度设置标签以添加有关操作的额外信息。
高级配置和自定义
Spring Cloud Sleuth 提供了丰富的配置选项和自定义功能,以适应不同的追踪需求。您可以配置要记录的采样率、设置追踪信息的导出方式,甚至将追踪数据发送到不同的追踪系统。
以下是一些高级配置示例:
配置采样率
您可以配置采样率以决定哪些请求应该记录和追踪。以下是一个示例配置,将采样率设置为50%:
spring.sleuth.sampler.probability=0.5
自定义导出
如果您想将追踪数据导出到不同的追踪系统,例如Jaeger或AWS X-Ray,您可以配置自定义的 SpanReporter。这需要一些额外的编程工作,但允许您集成其他追踪工具。
配置 Zipkin
如果您希望将追踪数据发送到 Zipkin 服务器之外的其他地方,您可以配置 Zipkin 发送器的类型。以下是一个示例配置,将追踪数据发送到自定义的远程服务器:
spring.zipkin.sender.type=web
spring.zipkin.base-url=http://custom-zipkin-server:9411/
结论
在分布式系统中进行追踪是确保应用程序性能和可用性的重要组成部分。Spring Cloud Sleuth 提供了一种方便而强大的方式来实现分布式追踪,它集成了 Zipkin,使您能够轻松查看和分析跟踪数据。通过使用 Spring Cloud Sleuth,您可以更好地了解应用程序的行为,快速诊断性能问题,并提高系统的可维护性。
本文介绍了如何在 Spring Boot 应用程序中集成 Spring Cloud Sleuth,并使用自动追踪、手动追踪、Trace 和 Span 来记录和分析分布式应用程序的性能数据。希望这篇文章对您有所帮助,让您更好地理解如何在 Spring Boot 应用程序中进行分布式追踪。通过使用 Spring Cloud Sleuth,您可以建立一个更可观察和可管理的分布式系统,提供更好的用户体验。